深度学习实战之车牌识别项目
车牌识别项目
不经常上线,既然有人想要代码,现在我将它发出来,不过需要你们下载,具体下载方法,我想你们都懂得。
https://download.csdn.net/download/weixin_43648821/11423543
本博客关于深度学习完成后,做的有一个小项目,基本已完成。环境配置:Win7、Python3.7、Opencv4.10。作本项目,一是为总结,二是方便以后的回顾。
车牌图像处理原理
一、是读取图像,对图像进行预处理,包括(具有先后顺序):压缩图像、转换为灰度图像、灰度拉伸、开运算(去噪声)、将灰度图像和开运算后图像取差分图、整张图像二值化、canny边缘检测、闭运算、开运算、再次开运算(这三步是为了保留车牌区域,并消除其他区域)、定位车牌位置(找轮廓、画轮廓、取前三个轮廓进行排序、找出最大的区域);
二、是框处车牌号;
三、分割车牌号和背景,分割包括:创建掩膜、创建背景和前景、分割;
四、将分割出来的车牌进行二值化,生成黑白图像;
五、分割出车牌号码中的文字、数字和字母,放入特定的文件夹;
六、对分割出来的文字、数字和字母图像尺寸进行处理,以方便后面测试。
测试所用图像
下面是相关代码
主函数
def carimg_make(img):
# 预处理图像
rect, afterimg = preprocessing(img) # 其实包括了对车牌定位
print("rect:", rect)
# 框出车牌
cv2.rectangle(afterimg, (rect[0], rect[1]), (rect[2], rect[3]), (0, 255, 0), 2)
cv2.imshow('afterimg1', afterimg)
# 分割车牌与背景
cutimg = cut_license(afterimg, rect)
cv2.imshow('cutimg', cutimg)
# 二值化生成黑白图
thresh = lice_binarization(cutimg)
cv2.imshow('thresh', thresh)
cv2.waitKey(0)
# 分割字符
'''
判断底色和字色
'''
# 记录黑白像素总和
white = [] # 记录每一列的白色像素总和
black = [] # 记录每一列的黑色像素总和
height = thresh.shape[0] # 263
width = thresh.shape[1] # 400
white_max = 0 # 仅保存每列,取列中白色最多的像素总数
black_max = 0 # 仅保存每列,取列中黑色最多的像素总数
# 计算每一列的黑白像素总和
for i in range(width):
line_white = 0 # 这一列白色总数
line_black = 0 # 这一列黑色总数
for j in range(height):
if thresh[j][i] == 255:
line_white += 1
if thresh[j][i] == 0:
line_black += 1
white_max = max(white_max, line_white)
black_max = max(black_max, line_black)
white.append(line_white)
black.append(line_black)
print('white_max', white_max)
print('black_max', black_max)
# arg为true表示黑底白字,False为白底黑字
arg = True
if black_max < white_max:
arg = False
# 分割车牌的数字
n = 1
start = 1
end = 2
s_width = 28
s_height = 28
temp = 1
while n < width - 2:
n += 1
# 判断是白底黑字还是黑底白字 0.05参数对应上面的0.95 可作调整
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):#这点没有理解透彻
start = n
end = find_end(start, arg, black, white, width, black_max, white_max)
n = end
print("start" + str(start))
print("end" + str(end))
# 思路就是从左开始检测匹配字符,若宽度(end - start)小与20则认为是左侧白条 pass掉 继续向右识别,否则说明是
# 省份简称,剪切,压缩 保存,还有一个当后五位有数字 1 时,他的宽度也是很窄的,所以就直接认为是数字 1 不需要再
# 做预测了(不然很窄的 1 截切 压缩后宽度是被拉伸的),shutil.copy()函数是当检测
# 到这个所谓的 1 时,从样本库中拷贝一张 1 的图片给当前temp下标下的字符
# if end - start > 5:
# print("end - start" + str(end - start))
if end - start > 5:
cj = thresh[1:height, start:end]
print("result/%s.jpg" % (n))
cv2.imwrite('img/{0}.bmp'.format(n), cj)
#对分割出的数字、字母进行裁剪
b_img = cv2.resize(cj, None, fx=5, fy=3)
contours, hierarchy = cv2.findContours(b_img.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
block = []
for c in contours:
# 找出轮廓的左上点和右下点,由此计算它的面积和长度比
r = find_rectangle(c) # 里面是轮廓的左上点和右下点
a = (r[2] - r[0]) * (r[3] - r[1]) # 面积
s = (r[2] - r[0]) / (r[3] - r[1]) # 长度比
block.append([c, r, a, s])
block1 = sorted(block, key=lambda block: block[2])[-1:]
# rect = cv2.minAreaRect(block2)
# box1 = np.int0(cv2.boxPoints(rect))
box = block1[0][1]
y_mia = box[0] # y_mia
x_min = box[1] # x_min
y_max = box[2] # y_max
x_max = box[3] # x_max
cropImg = b_img[x_min:x_max, y_mia:y_max] # crop the image
cv2.imwrite('img_test/{0}.bmp'.format(n), cropImg)
cv2.imshow('cutlicense', cj)
cv2.imshow("charecter",cropImg)
cv2.waitKey(0)
cv2.waitKey(0)
cv2.destroyAllWindows()
预处理函数
def preprocessing(img):
'''
预处理函数
'''
m=400 * img.shape[0] / img.shape[1]
#压缩图像
img=cv2.resize(img,(400,int(m)),interpolation=cv2.INTER_CUBIC)
#BGR转换为灰度图像
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
print('gray_img.shape',gray_img.shape)
#灰度拉伸
#如果一幅图像的灰度集中在较暗的区域而导致图像偏暗,可以用灰度拉伸功能来拉伸(斜率>1)物体灰度区间以改善图像;
# 同样如果图像灰度集中在较亮的区域而导致图像偏亮,也可以用灰度拉伸功能来压缩(斜率<1)物体灰度区间以改善图像质量
stretchedimg=stretching(gray_img)#进行灰度拉伸,是因为可以改善图像的质量
print('stretchedimg.shape',stretchedimg.shape)
'''进行开运算,用来去除噪声'''
r=15
h=w=r*2+1
kernel=np.zeros((h,w),np.uint8)
cv2.circle(kernel,(r,r),r,1,-1)
#开运算
openingimg=cv2.morphologyEx(stretchedimg,cv2.MORPH_OPEN,kernel)
#获取差分图,两幅图像做差 cv2.absdiff('图像1','图像2')
strtimg=cv2.absdiff(stretchedimg,openingimg)
cv2.imshow("stretchedimg",stretchedimg)
cv2.imshow("openingimg1",openingimg)
cv2.imshow("strtimg",strtimg)
cv2.waitKey(0)
#图像二值化
binaryimg=allbinaryzation(strtimg)
cv2.imshow("binaryimg",binaryimg)
cv2.waitKey(0)
#canny边缘检测
canny=cv2.Canny(binaryimg,binaryimg.shape[0],binaryimg.shape[1])
cv2.imshow("canny",canny)
cv2.waitKey(0)
'''保留车牌区域,消除其他区域,从而定位车牌'''
#进行闭运算
kernel=np.ones((5,23),np.uint8)
closingimg=cv2.morphologyEx(canny,cv2.MORPH_CLOSE,kernel)
cv2.imshow("closingimg",closingimg)
#进行开运算
openingimg=cv2.morphologyEx(closingimg,cv2.MORPH_OPEN,kernel)
cv2.imshow("openingimg2",openingimg)
#再次进行开运算
kernel=np.ones((11,6),np.uint8)
openingimg=cv2.morphologyEx(openingimg,cv2.MORPH_OPEN,kernel)
cv2.imshow("openingimg3",openingimg)
cv2.waitKey(0)
#消除小区域,定位车牌位置
rect=locate_license(openingimg,img)#rect包括轮廓的左上点和右下点,长宽比以及面积
return rect,img
车牌定位函数
def locate_license(img,afterimg):
'''
定位车牌号
'''
contours,hierarchy=cv2.findContours(img,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
img_copy = afterimg.copy()
img_cont = cv2.drawContours(img_copy,contours,-1,(255,0,0),6)
cv2.imshow("img_cont",img_cont)
cv2.waitKey(0)
#找出最大的三个区域
block=[]
for c in contours:
#找出轮廓的左上点和右下点,由此计算它的面积和长度比
r=find_rectangle(c)#里面是轮廓的左上点和右下点
a=(r[2]-r[0])*(r[3]-r[1]) #面积
s=(r[2]-r[0])/(r[3]-r[1]) #长度比
block.append([r,a,s])
#选出面积最大的3个区域
block=sorted(block,key=lambda b: b[1])[-3:]
#使用颜色识别判断找出最像车牌的区域
maxweight,maxindex=0,-1
for i in range(len(block)):#len(block)=3
b=afterimg[block[i][0][1]:block[i][0][3],block[i][0][0]:block[i][0][2]]
#BGR转HSV
hsv=cv2.cvtColor(b,cv2.COLOR_BGR2HSV)
lower=np.array([100,50,50])
upper=np.array([140,255,255])
#根据阈值构建掩膜
mask=cv2.inRange(hsv,lower,upper)
#统计权值
w1=0
for m in mask:
w1+=m/255
w2=0
for n in w1:
w2+=n
#选出最大权值的区域
if w2>maxweight:
maxindex=i
maxweight=w2
return block[maxindex][0]
灰度拉伸函数
def stretching(img):
'''
图像拉伸函数
'''
maxi=float(img.max())
mini=float(img.min())
for i in range(img.shape[0]):
for j in range(img.shape[1]):
img[i,j]=(255/(maxi-mini)*img[i,j]-(255*mini)/(maxi-mini))
return img
整个图像的二值化函数
def allbinaryzation(img):
'''
二值化处理函数
'''
maxi=float(img.max())
mini=float(img.min())
x=maxi-((maxi-mini)/2)
#二值化,返回阈值ret 和 二值化操作后的图像thresh
ret,thresh=cv2.threshold(img,x,255,cv2.THRESH_BINARY)
# thresh = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,5,2)
#返回二值化后的黑白图像
return thresh
图像分割函数
def cut_license(afterimg,rect):
'''
图像分割函数
'''
#转换为宽度和高度
rect[2]=rect[2]-rect[0]
rect[3]=rect[3]-rect[1]
rect_copy=tuple(rect.copy())#tuple是一个元组
print("rect_copy",rect_copy)
rect=[0,0,0,0]
#创建掩膜
mask=np.zeros(afterimg.shape[:2],np.uint8)
#创建背景模型 大小只能为13*5,行数只能为1,单通道浮点型
bgdModel=np.zeros((1,65),np.float64)
#创建前景模型
fgdModel=np.zeros((1,65),np.float64)
#分割图像
cv2.grabCut(afterimg,mask,rect_copy,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2=np.where((mask==2)|(mask==0),0,1).astype('uint8')
img_show=afterimg*mask2[:,:,np.newaxis]
return img_show
车牌区域图像的二值化函数
def lice_binarization(licenseimg):
'''
车牌图片二值化
'''
#车牌变为灰度图像
gray_img=cv2.cvtColor(licenseimg,cv2.COLOR_BGR2GRAY)
#均值滤波 去除噪声
kernel=np.ones((3,3),np.float32)/9
gray_img=cv2.filter2D(gray_img,-1,kernel)
#二值化处理
ret,thresh=cv2.threshold(gray_img,120,255,cv2.THRESH_BINARY)
return thresh
分割图像
def find_end(start,arg,black,white,width,black_max,white_max):
end=start+1
for m in range(start+1,width-1):
if (black[m] if arg else white[m])>(0.95*black_max if arg else 0.95*white_max):
end=m
break
return end
矩形轮廓
def find_rectangle(contour):
'''
寻找矩形轮廓
'''
y,x=[],[]
for p in contour:
y.append(p[0][0])
x.append(p[0][1])
return [min(y),min(x),max(y),max(x)]
结果展示
1、下图是车牌图像处理各个过程的输出:
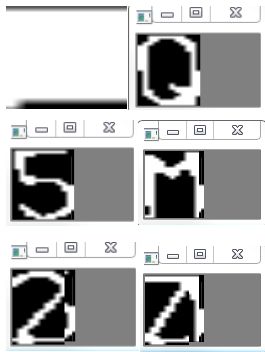
2、车牌号分割图像所示

3、对分割后的图像进行裁剪,结果表明,对于汉字的裁剪效果不是理想,原因是分割后的汉字“鲁”,上下出现分离,导致在裁剪时,误判最上面的白色部分面积最大,从而出现失误,有待改进。
卷积神经网络进行训练和测试
一、定义卷积层;
二、定义全连接层;
三、创建模型和权重参数的文件夹;
五、再次遍历图片文件夹,生成图片输入数据和标签;
六、构建训练模型,该模型包括两个卷积层和一个全连接层,采用Adam梯度下降优化算法;
七、创建图,进行迭代训练;
八、通过tensorflow提供的API接口tf.train.Saver()来保存训练好的模型以及权重参数等;
九、将分割出来的文字、数字和字母图像,通过训练模型和权重进行测试。
训练函数
# !/usr/bin/python3.7
# -*- coding: utf-8 -*-
import sys
import os
import time
import random
from PIL import Image
import numpy as np
import tensorflow as tf
SIZE = 1280
WIDTH = 32
HEIGHT = 40
NUM_CLASSES = 34
iterations = 50
#存放模型和权重参数的文件夹
SAVER_DIR = "train-saver_me/digits/"
LETTERS_DIGITS = (
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P",
"Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z")
license_num = ""
time_begin = time.time()
# 定义输入节点
x = tf.placeholder(tf.float32, shape=[None, SIZE])
y_ = tf.placeholder(tf.float32, shape=[None, NUM_CLASSES])
x_image = tf.reshape(x, [-1, WIDTH, HEIGHT, 1])
# 定义卷积函数
def conv_layer(inputs, W, b, conv_strides, kernel_size, pool_strides, padding):
L1_conv = tf.nn.conv2d(inputs, W, strides=conv_strides, padding=padding)
L1_relu = tf.nn.relu(L1_conv + b)
return tf.nn.max_pool(L1_relu, ksize=kernel_size, strides=pool_strides, padding='SAME')
# 定义全连接层函数
def full_connect(inputs, W, b):
return tf.nn.relu(tf.matmul(inputs, W) + b)
# 定义训练网络
def carnum_train():
iterations = 50
time_begin = time.time()
# 第一次遍历图片文件夹是为了获取图片总数
input_count = 0
for i in range(0, NUM_CLASSES):
dir = './train_images/training-set/%s/' % i # 这里可以改成你自己的图片文件夹
for rt, dirs, files in os.walk(dir):
for filename in files:
input_count += 1
# 定义对应维数和各维长度的数组
input_images = np.array([[0] * SIZE for i in range(input_count)])
input_labels = np.array([[0] * NUM_CLASSES for i in range(input_count)])
# 第二次遍历图片文件夹是为了生成图片数据和标签,里面都是一堆0和1,因为都是二值化图像
index = 0
for i in range(0, NUM_CLASSES):
dir = './train_images/training-set/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
filename = dir + filename
img = Image.open(filename)
width = img.size[0]
height = img.size[1]
for h in range(0, height):
for w in range(0, width):
# 通过这样的处理,使数字的线条变细,有利于提高识别准确率
if img.getpixel((w, h)) > 230: # img.getpixel遍历一张图像的所有像素点
input_images[index][w + h * width] = 0
else:
input_images[index][w + h * width] = 1
input_labels[index][i] = 1
index += 1
# 第一次遍历图片目录是为了获取图片总数
val_count = 0
for i in range(0, NUM_CLASSES):
dir = './train_images/validation-set/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
val_count += 1
# 定义对应维数和各维长度的数组
val_images = np.array([[0] * SIZE for i in range(val_count)])
val_labels = np.array([[0] * NUM_CLASSES for i in range(val_count)])
# 第二次遍历图片目录是为了生成图片数据和标签
index = 0
for i in range(0, NUM_CLASSES):
dir = './train_images/validation-set/%s/' % i # 这里可以改成你自己的图片目录,i为分类标签
for rt, dirs, files in os.walk(dir):
for filename in files:
filename = dir + filename
img = Image.open(filename)
width = img.size[0]
height = img.size[1]
for h in range(0, height):
for w in range(0, width):
# 通过这样的处理,使数字的线条变细,有利于提高识别准确率
if img.getpixel((w, h)) > 230:
val_images[index][w + h * width] = 0
else:
val_images[index][w + h * width] = 1
val_labels[index][i] = 1
index += 1
with tf.Session() as sess:
# 第一个卷积层
W_conv1 = tf.Variable(tf.truncated_normal([8, 8, 1, 16], stddev=0.1), name="W_conv1")
b_conv1 = tf.Variable(tf.constant(0.1, shape=[16]), name="b_conv1")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 16, 32], stddev=0.1), name="W_conv2")
b_conv2 = tf.Variable(tf.constant(0.1, shape=[32]), name="b_conv2")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = tf.Variable(tf.truncated_normal([16 * 20 * 32, 512], stddev=0.1), name="W_fc1")
b_fc1 = tf.Variable(tf.constant(0.1, shape=[512]), name="b_fc1")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = tf.Variable(tf.truncated_normal([512, NUM_CLASSES], stddev=0.1), name="W_fc2")
b_fc2 = tf.Variable(tf.constant(0.1, shape=[NUM_CLASSES]), name="b_fc2")
# 定义优化器和训练op
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
# 求交叉熵
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# Adam优化
train_step = tf.train.AdamOptimizer((1e-4)).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 运行整个网络
sess.run(tf.global_variables_initializer())
time_elapsed = time.time() - time_begin
print("读取图片文件耗费时间:%d秒" % time_elapsed)
time_begin = time.time()
print("一共读取了 %s 个训练图像, %s 个标签" % (input_count, input_count))
# 设置每次训练op的输入个数和迭代次数,这里为了支持任意图片总数,定义了一个余数remainder,
# 譬如,如果每次训练op的输入个数为60,图片总数为150张,则前面两次各输入60张,最后一次输入30张(余数30)
batch_size = 60
iterations = iterations
batches_count = int(input_count / batch_size)
remainder = input_count % batch_size
print("训练数据集分成 %s 批, 前面每批 %s 个数据,最后一批 %s 个数据" % (batches_count + 1, batch_size, remainder))
# 执行训练迭代
for it in range(iterations):
# 这里的关键是要把输入数组转为np.array
for n in range(batches_count): # n是从0到72
train_step.run(feed_dict={x: input_images[n * batch_size:(n + 1) * batch_size],
y_: input_labels[n * batch_size:(n + 1) * batch_size], keep_prob: 0.5})
if remainder > 0:
start_index = batches_count * batch_size
train_step.run(feed_dict={x: input_images[start_index:input_count - 1],
y_: input_labels[start_index:input_count - 1], keep_prob: 0.5})
# 每完成五次迭代,判断准确度是否已达到100%,达到则退出迭代循环
iterate_accuracy = 0
if it % 5 == 0:
iterate_accuracy = accuracy.eval(feed_dict={x: val_images, y_: val_labels, keep_prob: 1.0})
print('第 %d 次训练迭代: 准确率 %0.5f%%' % (it, iterate_accuracy * 100))
if iterate_accuracy >= 0.9999 and it >= iterations:
break
print('完成训练!')
time_elapsed = time.time() - time_begin
print("训练耗费时间:%d秒" % time_elapsed)
time_begin = time.time()
# 保存训练结果
if not os.path.exists(SAVER_DIR):
print('不存在训练数据保存目录,现在创建保存目录')
os.makedirs(SAVER_DIR)
# 初始化saver
saver = tf.train.Saver() # 这是tensorflow提供的API接口,用来保存和还原一个神经网络
saver_path = saver.save(sess, "%smodel.ckpt" % (SAVER_DIR))
测试函数
def carnum_test():
license_num = ""
saver = tf.train.import_meta_graph("%smodel.ckpt.meta" % (SAVER_DIR))
with tf.Session() as sess:
model_file = tf.train.latest_checkpoint(SAVER_DIR)
saver.restore(sess, model_file)
# 第一个卷积层
W_conv1 = sess.graph.get_tensor_by_name("W_conv1:0") # sess.graph.get_tensor_by_name获取模型训练过程中的变量和参数名
b_conv1 = sess.graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = sess.graph.get_tensor_by_name("W_conv2:0")
b_conv2 = sess.graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = sess.graph.get_tensor_by_name("W_fc1:0")
b_fc1 = sess.graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = sess.graph.get_tensor_by_name("W_fc2:0")
b_fc2 = sess.graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
for n in range(3, 8):
path = "test_images/%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * SIZE for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(NUM_CLASSES):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
license_num = license_num + LETTERS_DIGITS[max1_index]
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
LETTERS_DIGITS[max1_index], max1 * 100, LETTERS_DIGITS[max2_index], max2 * 100,
LETTERS_DIGITS[max3_index],
max3 * 100))
print("车牌编号是: 【%s】" % license_num)
测试结果
车牌号是: 01672Q