深度学习模型测试方法总结
深度学习模型测试的方法和标准整理
深度学习模型测试,是指系统性地对深度学习算法的可靠性、可移植性、效率进行评估。简单来说,算法测试主要做的是三件事:收集测试数据,思考需要什么样的测试数据以及数据的标注;跑测试数据,编写测试脚本批量运行;查看数据结果,统计正确和错误的个数,计算准确率等相关指标,查看错误数据中是否有共同的特征。
1相关术语
1.1Accuracy(准确率)、Precision(精确率)、Recall(召回率)
对于二值分类器,或者说分类算法,如分类猫和狗,分类性别男和女。TP、FP、TN、FN,即:True Positive, False Positive, True Negative, False Negative。预测值与真实值相同,记为T(True);预测值与真实值相反,记为F(False);预测值为正例,记为P(Positive);预测值为反例,记为N(Negative)。具体组合见图1.1的分类结果混淆矩阵:
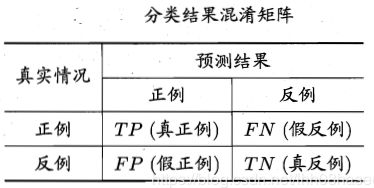
图1.1分类结果混淆矩阵
根据分类结果混淆矩阵可得:
- 准确率:Accuracy = (TP+TN)/(P+N) ,预测正确的样本(TP和TN)在所有样本中占的比例。在各类样本不均衡时,准确率不能很好表示模型性能,因为会出现大类准确率高,而少数类准确率低。这样情况下,需要对每一类样本单独观察。
- 精确率(查准率): Precision = TP/(TP+FP),即所有被预测为正例的样本中,多少比例是真的正例。
- 召回率(查全率): Recall = TP/(TP+FN),即所有真的正例中,多少比例被模型预测出来了。
不同的问题中,有的侧重精确率,有的侧重召回率。对于推荐系统,更侧重于精确率。即推荐的结果中,用户真正感兴趣的比例。因为给用户展示的窗口有限,必须尽可能的给用户展示他真实感兴趣的结果。对于医学诊断系统,更侧重与召回率。即疾病被发现的比例。因为疾病如果被漏诊,则很可能导致病情恶化。精确率和召回率是一对矛盾的度量。一般来说精确率高时召回率往往偏低,而召回率高时精确率往往偏低。
1.2 F1 Score
精确率和召回率的调和平均。F1认为精确率和召回率同等重要。计算公式为:
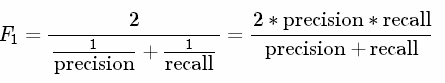
图1.2 F1 Score 计算公式
1.3 可靠性 (reliability)、可靠性评估(reliability assessment)
可靠性指在规定的条件下和规定的时间内,深度学习算法正确完成预期功能,且不引起系统失效或异常的能
力。
可靠性评估指确定现有深度学习算法的可靠性所达到的预期水平的过程。
1.4 响应时间 response time
在给定的软硬件环境下,深度学习算法对给定的数据进行运算并获得结果所需要的时间。
2深度学习算法的可靠性指标体系
基于深度学习算法可靠性的内外部影响考虑,结合用户实际的应用场景,深度学习算法的可靠性评估指标体系如图2.1所示,包含7个一级指标和20个二级指标。在实施评估过程中,应根据可靠性目标选取相应指标。
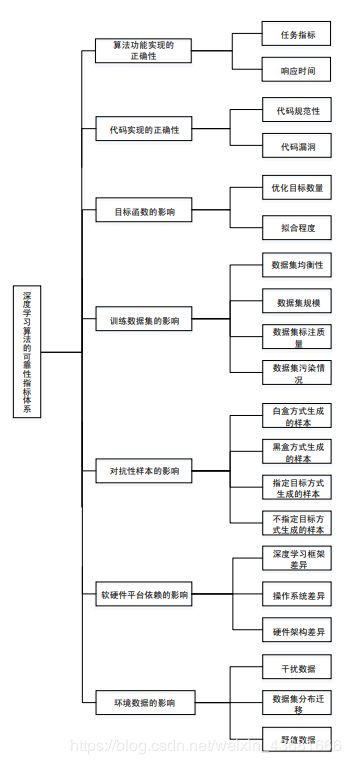
图2.1 深度学习算法的可靠性评估指标体系
2.1 算法功能实现的正确性
用于评估深度学习算法实现的功能是否满足要求,应包括但不限于下列内容:
a) 任务指标:用户可以根据实际的应用场景选择任务相关的基本指标,用于评估算法完成功能的能力;
示例:分类任务中的查准率、查全率、准确率等;语音识别任务中的词错误率、句错误率等;目标检测任务中的平均正确率等;算法在使用中错误偏差程度带来的影响等。
b) 响应时间。
2.2 代码实现的正确性
用于评估代码实现功能的正确性,应包括下列内容:
a) 代码规范性:代码的声明定义、版面书写、指针使用、分支控制、跳转控制、运算处理、函数
调用、语句使用、循环控制、类型转换、初始化、比较判断和变量使用等是否符合相关标准或
规范中的编程要求;
b) 代码漏洞:指代码中是否存在漏洞。
示例:栈溢出漏洞、堆栈溢出漏洞、整数溢出、数组越界、缓冲区溢出等。
2.3 目标函数的影响
用于评估计算预测结果与真实结果之间的误差,应包括下列内容:
a) 优化目标数量:包括优化目标不足或过多。优化目标过少容易造成模型的适应性过强,优化目标过多容易造成模型收敛困难;
b) 拟合程度:包括过拟合或欠拟合。过拟合是指模型对训练数据过度适应,通常由于模型过度地学习训练数据中的细节和噪声,从而导致模型在训练数据上表现很好,而在测试数据上表现很差,也即模型的泛化性能变差。欠拟合是指模型对训练数据不能很好地拟合,通常由于模型过于简单造成,需要调整算法使得模型表达能力更强。
2.4 训练数据集的影响
用于评估训练数据集带来的影响,应包括下列内容:
a) 数据集均衡性:指数据集包含的各种类别的样本数量一致程度和数据集样本分布的偏差程度;
b) 数据集规模:通常用样本数量来衡量,大规模数据集通常具有更好的样本多样性;
c) 数据集标注质量:指数据集标注信息是否完备并准确无误;
d) 数据集污染情况:指数据集被人为添加的恶意数据的程度。
2.5 对抗性样本的影响
用于评估对抗性样本对深度学习算法的影响,应包括下列内容:
a) 白盒方式生成的样本:指目标模型已知的情况下,利用梯度下降等方式生成对抗性样本;
b) 黑盒方式生成的样本:指目标模型未知的情况下,利用一个替代模型进行模型估计,针对替代模型使用白盒方式生成对抗性样本;
c) 指定目标生成的样本:指利用已有数据集中的样本,通过指定样本的方式生成对抗性样本;
d) 不指定目标生成的样本:指利用已有数据集中的样本,通过不指定样本(或使用全部样本)的方式生成对抗性样本。
2.6 软硬件平台依赖的影响
用于评估运行深度学习算法的软硬件平台对可靠性的影响,应包括下列内容:
a) 深度学习框架差异:指不同的深度学习框架在其所支持的编程语言、模型设计、接口设计、分布式性能等方面的差异对深度学习算法可靠性的影响;
b) 操作系统差异:指操作系统的用户可操作性、设备独立性、可移植性、系统安全性等方面的差异对深度学习算法可靠性的影响;
c) 硬件架构差异:指不同的硬件架构及其计算能力、处理精度等方面的差异对深度学习算法可靠性的影响。
2.7 环境数据的影响
用于评估实际运行环境对算法的影响,应包括下列内容:
a) 干扰数据:指由于环境的复杂性所产生的非预期的真实数据,可能影响算法的可靠性;
b) 数据集分布迁移:算法通常假设训练数据样本和真实数据样本服从相同分布,但在算法实际使用中,数据集分布可能发生迁移,即真实数据集分布与训练数据集分布之间存在差异性;
c) 野值数据:指一些极端的观察值。在一组数据中可能有少数数据与其余的数据差别比较大,也称为异常观察值。
3执行测试
该部分主要考虑如何具体进行测试,
3.1 测试用例的选择
选择测试用例时,要考虑以下问题:
- 项目落地实际使用场景,根据场景思考真实的数据情况,倒推进行测试数据收集。
- 模型的训练数据有多少,训练数据的分布情况,训练数据的标注是否准确。
- 模型的输入和输出,图片,csv还是文本,语音等等。
- 算法的实现方式。
- 选择模型评价指标。
- 评价指标的上线要求。
- 项目的流程,数据流。
- 算法外的业务逻辑。
3.2 测试中可能出现的一些问题
实际项目中不仅是有算法相关代码还会有工程代码。如模型加载,入参的处理,异常判断,数据库相关,日志相关等等。所以项目测试,还会有工程代码功能的测试。
举例一些常见的:
1,有的依赖包在不同环境版本不一致,导致结果不一样。
2,科学计算错误
3,工程代码问题
4,模型效果差
科学计算即数值计算,是指应用计算机处理科学研究和工程技术中所遇到的数学计算问题。比如图像处理、机器学习、深度学习等很多领域都会用到科学计算。
一张图片输入,卷积神经网络顺序通常为:输入-卷积层-池化层-全连接层-输出。深度学习预测的过程就有大量的数值计算。可能就会碰到一些边界数值情况,导致计算出错。
3.3 模型结果评估
3.3.1单个标签分类的问题
对于单个标签分类的问题,评价指标主要有Accuracy,Precision,Recall,F-score,PR曲线,ROC和AUC。
如果对于每一类,若想知道类别之间相互误分的情况,查看是否有特定的类别之间相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,混淆矩阵很清晰的反映出各类别之间的错分概率,如下图:
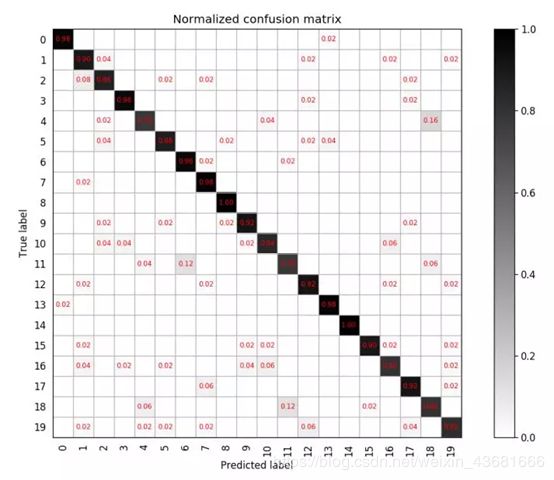
图3.1 分类结果混淆矩阵
上图表述的是一个包含20个类别的分类任务,混淆矩阵为20*20的矩阵,其中第i行第j列,表示第i类目标被分类为第j类的概率,越好的分类器对角线上的值更大,其他地方应该越小。
3.3.2 ROC曲线与AUC指标
以上的准确率Accuracy,精确度Precision,召回率Recall,F1 score,混淆矩阵都只是一个单一的数值指标,如果想观察分类算法在不同的参数下的表现情况,就可以使用一条曲线,即ROC曲线,全称为receiver operating characteristic。
ROC曲线可以用于评价一个分类器在不同阈值下的表现情况。在ROC曲线中,每个点的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR),描绘了分类器在True Positive和False Positive间的平衡,两个指标的计算如下:
TPR=TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
FPR=FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例,FPR越大,预测正类中实际负类越多。
ROC曲线通常如下
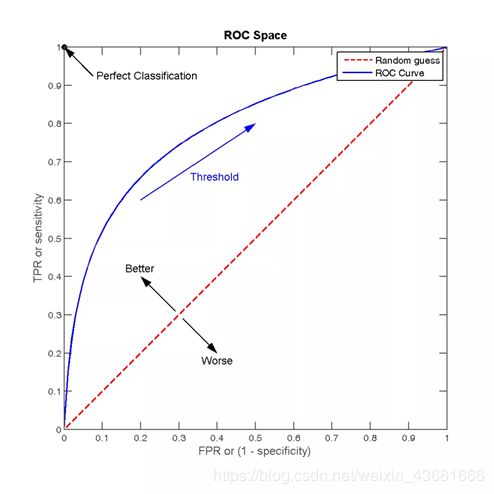
图 3.2 ROC曲线
3.3.3 图像生成评价指标
当需要评估一个生成模型的性能的时候,有2个最重要的衡量指标。
(1) 确定性:生成模型生成的样本一定属于特定的类别,也就是真实的图像,而且必须要是所训练的图片集,不能用人脸图像训练得到了手写数字。
(2) 多样性:样本应该各式各样,如果用mnist进行训练,在没有条件限制的条件下,应该生成0,1,2,3…,而不是都是0,生成的各个数字也应该具有不同的笔触,大小等。除此之外,还会考虑分辨率等。
4参考资料
1、也许这有你想知道的人工智能 (AI) 测试.https://blog.csdn.net/lhh08hasee/article/details/100534862
2、《人工智能深度学习算法评估规范》,中国人工智能开源软件发展联盟标准http://www.cesi.cn/images/editor/20180703/20180703174359294.pdf
3、深度学习模型评估指标,https://www.cnblogs.com/tectal/p/10870064.html
4、模型评估与调优,https://machine-learning-from-scratch.readthedocs.io/zh_CN/latest/%E6%A8%A1%E5%9E%8B%E8%AF%84%E4%BC%B0%E4%B8%8E%E6%A8%A1%E5%9E%8B%E8%B0%83%E4%BC%98.html#header-n408
5、AI模型的黑盒测试与白盒测试实践,http://mini.eastday.com/mobile/190924064408433.html