TensorFlow实现FCN分割图片(使用自己的数据集)
一、复现FCN
1、在github上下载fcn的tensorflow版本实现 https://github.com/shekkizh/FCN.tensorflow
2、代码的实现有四个python文件,分别是FCN.py、BatchDatasetReader.py、TensorFlowUtils.py、read_MITSceneParsingData.py,将这四个文件放在一个当前目录下。
3、然后下载VGG网络的权重参数,下载好后的文件路径为./Model_zoo/imagenet-vgg-verydeep-19.mat.
网址:http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat
4、然后下载训练会用到的数据集,并解压到路径: ./Data_zoo/MIT_SceneParsing/ADEChallengeData2016。
网址:http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
5、训练时把FCN.py中的全局变量mode该为“train”,运行该文件。测试时改为“visualize”运行即可。
二、 制作自己的训练数据
- 做标签安装
下载网址:https://github.com/wkentaro/labelme#ubuntu
我的环境ubuntu18+py36.
# Python3
sudo apt-get install python3-pyqt5 # PyQt5
sudo pip3 install labelme
2.标注:运行labelme打开取名标注即可,点击Save后会生成改图片对应的json文件
首先看一下标准数据格式

annotation文件夹放的是train和valid的label文件,具体形式是图片(png),image文件夹放的是原照片(jpg),两个文件夹的内容除了图片格式有区别外,文件名等必须一一对应。
ok,所以我们的第一步应该是制作自己数据的label,运行labelme打开取名标注即可,点击Save后会生成改图片对应的json文件.
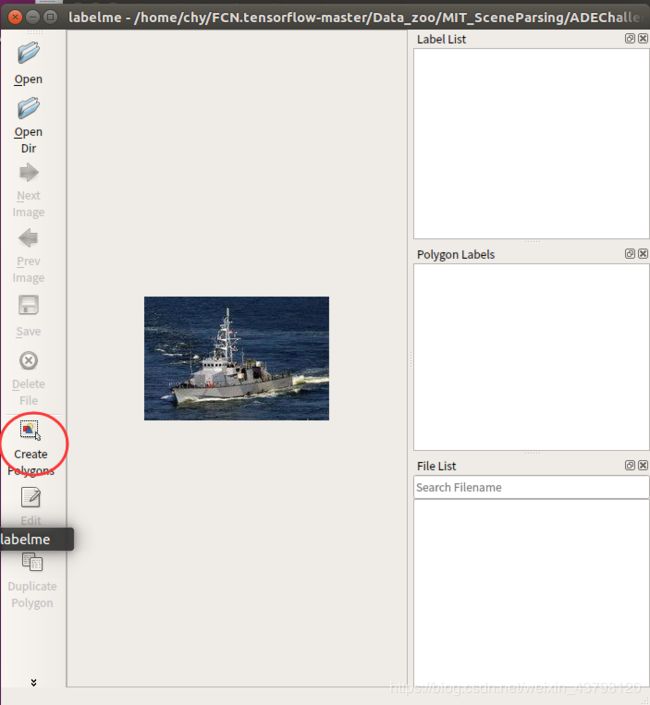
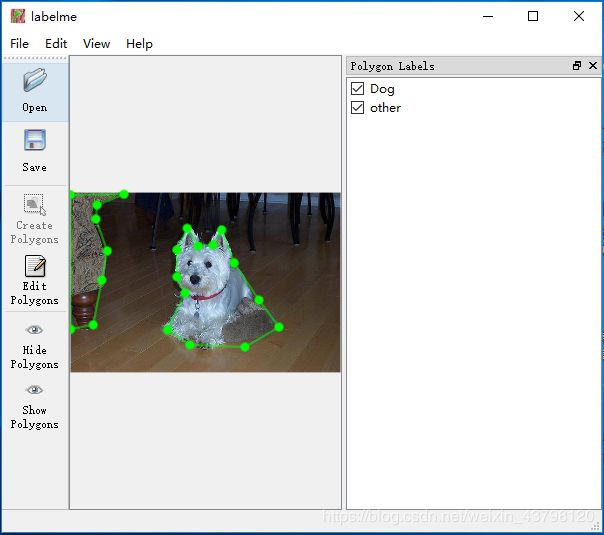
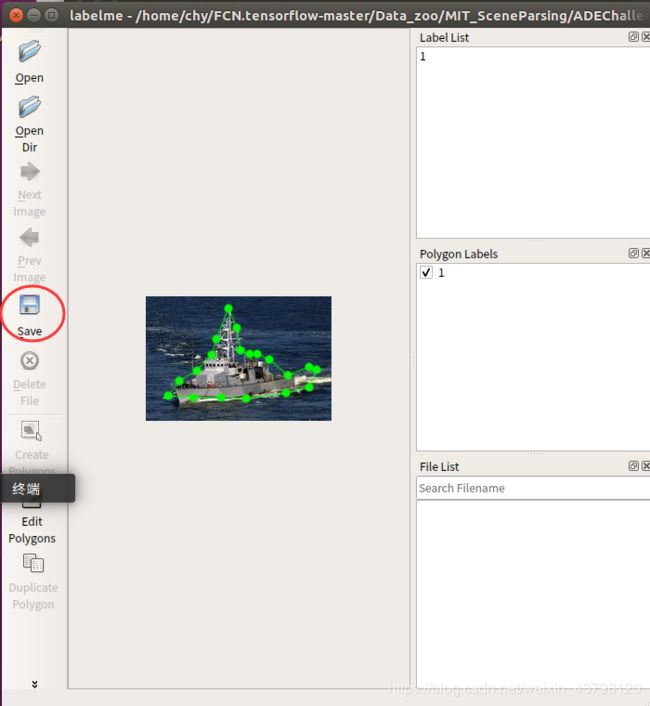
结果得到json文件,类似于下面这样

3.标注生成的json文件转化成png标注图片(批量转化)
找到json_to_dataset.py文件(路径在图片上方)
将下方的代码代替找到的json_to_dataset.py文件
import argparse
import json
import os
import os.path as osp
import warnings
import yaml
import numpy as np
import PIL.Image
from labelme import utils
def main():
'''
usage: python json2png.py json_file
'''
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
list = os.listdir(json_file)
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
filename=list[i][:-5]
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(list[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(list[i]), out_dir)
#out_dir = osp.join('./png', out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, '{}.png'.format(filename)))
lbl = PIL.Image.fromarray(np.uint8(lbl))
lbl.save(osp.join(out_dir, '{}_gt.png'.format(filename)))
# PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, '{}_viz.png'.format(filename)))
with open(osp.join(out_dir,'label_names.txt'),'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
使用:新建一个文件夹:命名12(自己命名)。
在该文件夹下打开终端环境,输入activate labelme 激活labelme
输入labelme_json_to_dataset /home/chy/junjianpy/json
进行批量转化json文件,其中/home/chy/junjianpy/json为json所在文件夹,转化后的文件保存在/home/chy/12/
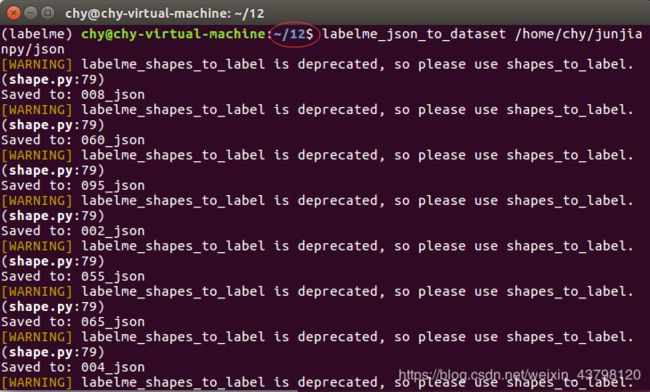
转化后会生成五个文件,我们需要的是_gt.png,可能是全黑的,不过没关系,按操作来就好。_gt.png作为标注图像(显示为全黑,实际像素值很小)。程序中将生成的png图片转化成8位的图片存储,此时_gt.png中像素实际以0,1,2…来分割图像,可以将灰度值放大来进行验证。
from skimage import io,data,color
img_name='/home/chy/005_gt.png'
#img=io.imread(img_name,as_grey=False)
img=io.imread(img_name)
img_gray=color.rgb2gray(img)
rows,cols=img_gray.shape
for i in range(rows):
for j in range(cols):
if (img_gray[i,j]<=0.5):
img_gray[i,j]=0
else:
img_gray[i,j]=1
io.imshow(img_gray)
io.show()
得到图片:

在整理数量较大的label你还需要这样的代码,即从大量json文件转化的文件里把需要的8位png全部拿出来(如果是16位先要转化成8位)
import os
import random
import shutil
import re
GT_from_PATH = "/home/chy/12/" #存json文件夹的根路径
GT_to_PATH = "./png" #不用改,自动生成
def copy_file(from_dir, to_dir, Name_list):
if not os.path.isdir(to_dir):
os.mkdir(to_dir)
for name in Name_list:
try:
# print(name)
if not os.path.isfile(os.path.join(from_dir, name)):
print("{} is not existed".format(os.path.join(from_dir, name)))
shutil.copy(os.path.join(from_dir, name), os.path.join(to_dir, name))
# print("{} has copied to {}".format(os.path.join(from_dir, name), os.path.join(to_dir, name)))
except:
# print("failed to move {}".format(from_dir + name))
pass
# shutil.copyfile(fileDir+name, tarDir+name)
print("{} has copied to {}".format(from_dir, to_dir))
if __name__ == '__main__':
filepath_list = os.listdir(GT_from_PATH)
#print(filepath_list)
for i, file_path in enumerate(filepath_list):
gt_path = "{}/{}_gt.png".format(os.path.join(GT_from_PATH, filepath_list[i]), file_path[:-5])
print("copy {} to ...".format(gt_path))
gt_name = ["{}_gt.png".format(file_path[:-5])]
gt_file_path = os.path.join(GT_from_PATH, file_path)
copy_file(gt_file_path, GT_to_PATH, gt_name)
至此数据集准备完毕。
三、替换FCN的数据集
1、将生成的img(.jpg)和label(gt_{}.png)按原数据集http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip中MIT_SceneParsing/ADEChallengeData2016文件夹中类似存储
2、annotations/training和images/training中文件名字一定要相同且一一对应,比如都为001.png和001.jpg。validation中的文件名同理。
四、训练
1、将FCN.py中NUM_OF_CLASSESS改为自己训练数据的最大的label像素值+1(自己训练数据的类别数,注意加上背景)。vgg-19预训练模型在程序运行中会进行下载,也可以在训练前下载好http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat放在Model_zoo文件夹中。将flag中的data_dir改为自己的数据集所在文件(我的是Data_zoo/power/),训练时mode为train。
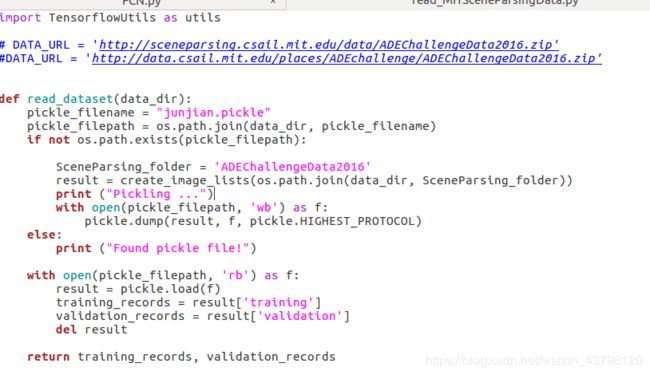
2、read_MITSceneParsingData.py中将pickle_filename改为你数据集的名字如"junjian.pickle",将SceneParsing_folder令为自己的文件夹SceneParsing_folder = 'ADEChallengeData2016 ’
主要修改read_dataset(data_dir)函数
删除掉下载数据集的语句utils.maybe_download_and_extract(data_dir, DATA_URL, is_zipfile=True)。
3、默认batch_size大小是2,迭代次数为1001次
4、损失函数可视化:
tensorboard --logdir ./logs/train
五、测试
在FCN.py中将mode改为visualize,网络生成的预测图像中灰度值不为0的点,可以在原图上对应位置将其灰度值修改为某固定值如200,就完成了可视化(这只有一种分类的情况,若是多种分类需要修改成对应不同的灰度值)。FCN.py中修改如下。
elif FLAGS.mode == "visualize":
#num: the number of images to be tested which can be a single batch_size or all validation set
valid_images, valid_annotations, num = validation_dataset_reader.get_random_batch(FLAGS.batch_size)
pred = sess.run(pred_annotation, feed_dict={image: valid_images, keep_probability: 1.0})
pred = np.squeeze(pred, axis=3)
for itr in range(num):
src_img = valid_images[itr].astype(np.uint8)
pred_img = pred[itr].astype(np.uint8)
#save images to ./logs/test_visualize
utils.save_image(src_img, FLAGS.logs_dir + 'test_visualize/', name="inp_" + str(itr))
utils.save_image(pred_img, FLAGS.logs_dir + 'test_visualize/', name="pred_" + str(itr))
for i in range(pred_img.shape[0]):
for j in range(pred_img.shape[1]):
if pred_img[i,j] != 0:
#if your source images are RGB format, you need to change three channels
src_img[i,j]=200
utils.save_image(src_img, FLAGS.logs_dir + 'test_visualize/', name="visual_" + str(itr))
print("Saved image: %d" % itr)