MySql学习系列(四)
MySql学习系列(四)
- 任务四
- 4.1 MySQL 实战 - 复杂项目
- #作业#
- 项目十:行程和用户(难度:困难)
- 项目十一:各部门前3高工资的员工(难度:中等)
- 项目十二 分数排名 - (难度:中等)
任务四
4.1 MySQL 实战 - 复杂项目
#作业#
项目十:行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
Id Client_Id Driver_Id City_Id Status Request_at
1 1 10 1 completed 2013-10-01
2 2 11 1 cancelled_by_driver 2013-10-01
3 3 12 6 completed 2013-10-01
4 4 13 6 cancelled_by_client 2013-10-01
5 1 10 1 completed 2013-10-02
6 2 11 6 completed 2013-10-02
7 3 12 6 completed 2013-10-02
8 2 12 12 completed 2013-10-03
9 3 10 12 completed 2013-10-03
10 4 13 12 cancelled_by_driver 2013-10-03
建表:
create table Trips(
Id int not null primary key,
Client_Id int,
Driver_Id int,
City_Id int,
Status enum("completed", "cancelled_by_driver", "cancelled_by_client"),
Request_at DATE,
foreign key(Client_Id) references Users(Users_Id),
foreign key(Driver_Id) references Users(Users_Id)
);
插入数据:
insert into Trips values
(1,1,10,1,"completed","2013-10-01"),
(2 , 2 , 11 , 1 , "cancelled_by_driver","2013-10-01"),
(3 , 3 , 12 , 6 , "completed" ,"2013-10-01"),
(4 , 4 , 13 , 6 , "cancelled_by_client","2013-10-01"),
(5 , 1 , 10 , 1 , "completed" ,"2013-10-02"),
(6 , 2 , 11 , 6 , "completed" ,"2013-10-02"),
(7 , 3 , 12 , 6 , "completed" ,"2013-10-02"),
(8 , 2 , 12 , 12 , "completed" ,"2013-10-03"),
(9 , 3 , 10 , 12 , "completed" ,"2013-10-03"),
(10 , 4 , 13 , 12 , "cancelled_by_driver","2013-10-03");
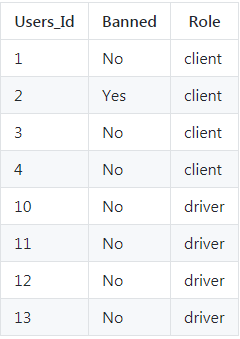
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
建表:
create table Users(
Users_Id int primary key,
Banned enum("yes", "no"),
Role enum("client", "driver", "Role")
);
插入数据:
insert into Users values
(1 ,"No","client"),
(2 ,"Yes","client"),
(3 ,"No","client"),
(4 ,"No","client"),
(10 ,"No","driver"),
(11 ,"No","driver"),
(12 ,"No","driver"),
(13 ,"No","driver");
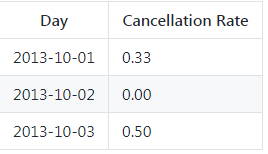
写一段 SQL 语句查出 **2013年10月1日 **至 **2013年10月3日 **期间非禁止用户的取消率。取消率(Cancellation Rate)保留两位小数。
select Request_at as Day, ROUND(count(Status != 'completed' OR NULL)/count(*),2) as "Cancellation Rate"
from Trips, users
where Trips.Client_Id = users.Users_Id
and Banned="no" and Request_at BETWEEN "2013-10-1" and "2013-10-3"
group by Request_at;
输出:
项目十一:各部门前3高工资的员工(难度:中等)
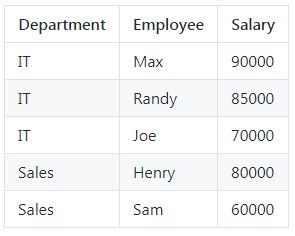
将项目7中的employee表清空,重新插入以下数据(其实是多插入5,6两行): | Id | Name | Salary | DepartmentId | |----|-------|--------|--------------| | 1 | Joe | 70000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 |
建表:
create table Employee2(
Id int not null,
name char(10) not null,
salary long,
departmentId int
);
插入数据:
insert into Employee2 values
(1,"Joe",70000,1),
(2,"Henry",80000,2),
(3,"Sam",60000,2),
(4,"Max",90000,1),
(5,"Janet",69000,1),
(6,"Randy",85000,1);
编写一个 SQL 查询,找出每个部门工资前三高的员工。
select d.Name Department, e.Name Employee2, e.Salary Salary
from Employee2 e inner join Department d
on e.DepartmentId = d.Id
where (
select count(distinct c.Salary)
from Employee2 c
where e.Salary < c.Salary and e.DepartmentId = c.DepartmentId
) < 3
order by e.DepartmentId, e.Salary desc;
输出:
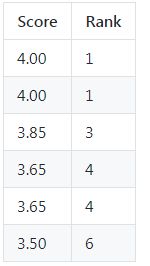
项目十二 分数排名 - (难度:中等)
依然是昨天的分数表,实现排名功能,但是排名是非连续的,如下: ±------±-----+ | Score | Rank | ±------±-----+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 3 | | 3.65 | 4 | | 3.65 | 4 | | 3.50 | 6 | ±------±-----
select score as Score,(
select count(score)+1
from scores s1
where s1.score>s2.score
) as "Rank"
from scores s2
order by score desc;
输出: