Spark 是什么
Spark 是一个用来实现快速而通用的集群计算的平台。
Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark使我们可以简单而低耗地把各种处理流程整合在一起。
不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分别管理的负担。Spark 所提供的接口非常丰富。除了提供基于 Python、Java、Scala 和 SQL 的简单易用的API 以及内建的丰富的程序库以外,Spark 还能和其他大数据工具密切配合使用。例如,Spark 可以运行在 Hadoop 集群上,访问包括 Cassandra 在内的任意 Hadoop 数据源。
Spark组件介绍
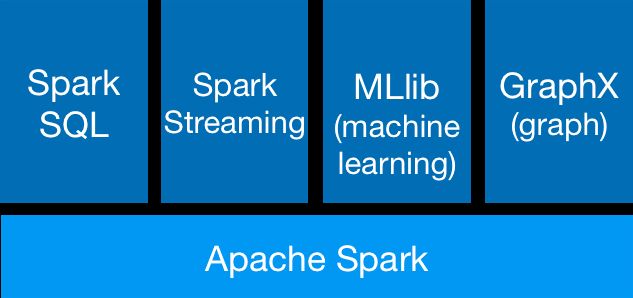
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。对熟悉Hive和HiveQL的人,Spark可以拿来就用。
- Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark,并在未来实现。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。
Spark数据存储
Spark 不仅可以将任何 Hadoop 分布式文件系统(HDFS)上的文件读取为分布式数据集,也可以支持其他支持 Hadoop 接口的系统,比如本地文件、亚马逊 S3、Cassandra、Hive、HBase 等。我们需要弄清楚的是,Hadoop 并非 Spark 的必要条件,Spark 支持任何实现了 Hadoop 接口的存储系统。
spark 安装
连接 Spark 的过程在各语言中并不一样。在 Java 和 Scala 中,只需要给你的应用添加一对于 spark工件的 Maven 依赖。
** 推荐使用maven依赖。**
RDD
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称RDD)。RDD 其实就是分布式的元素集合。
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。
在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有 RDD 以及调用 RDD 操作进行求值。而在这一切背后,Spark 会自动将RDD 中的数据分发到集群上,并将操作并行化执行。
- 创建RDD
Spark 提供了两种创建 RDD 的方式:
- 读取外部数据集
JavaRDDlines = sc.textFile("/path/to/README.md"); - 在驱动器程序中对一个集合进行并行化。
JavaRDDlines = sc.parallelize(Arrays.asList("pandas", "i like pandas"));
- RDD 操作
RDD 支持两种操作:转化操作和行动操作。
- RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() 。转化 出来的 RDD 是惰性求值的,只有在行动操作中用到这些 RDD 时才会被计算。意味着在被调用行动操作之前 Spark 不会开始计算。Spark 使用惰性求值,这样就可以把一些操作合并到一起来减少计算数据的步骤。
- 行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。
Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。

(PDF 33页)
一个简单小程序
任务:编写一个Spark应用程序,对某个文件中的单词进行词频统计。
// 第一步:创建SparkConf对象,设置Spark应用的配置信息
// 使用setMaster()可以设置Spark应用程序要连接的Spark集群的master节点的url
// 但是如果设置为local则代表,在本地运行
SparkConf conf = new SparkConf()
.setAppName("WordCountLocal")
.setMaster("local");
// 第二步:创建JavaSparkContext对象
// 在Spark中,SparkContext是Spark所有功能的一个入口,你无论是用java、scala,甚至是python编写
// 都必须要有一个SparkContext,它的主要作用,包括初始化Spark应用程序所需的一些核心组件,包括
// 调度器(DAGSchedule、TaskScheduler),还会去到Spark Master节点上进行注册,等等
// 一句话,SparkContext,是Spark应用中,可以说是最最重要的一个对象
// 但是呢,在Spark中,编写不同类型的Spark应用程序,使用的SparkContext是不同的,如果使用scala,
// 使用的就是原生的SparkContext对象
// 但是如果使用Java,那么就是JavaSparkContext对象
// 如果是开发Spark SQL程序,那么就是SQLContext、HiveContext
// 如果是开发Spark Streaming程序,那么就是它独有的SparkContext
// 以此类推
JavaSparkContext sc = new JavaSparkContext(conf);
// 第三步:要针对输入源(hdfs文件、本地文件,等等),创建一个初始的RDD
// 输入源中的数据会打散,分配到RDD的每个partition中,从而形成一个初始的分布式的数据集
// 我们这里呢,因为是本地测试,所以呢,就是针对本地文件
// SparkContext中,用于根据文件类型的输入源创建RDD的方法,叫做textFile()方法
// 在Java中,创建的普通RDD,都叫做JavaRDD
// 在这里呢,RDD中,有元素这种概念,如果是hdfs或者本地文件呢,创建的RDD,每一个元素就相当于
// 是文件里的一行
JavaRDD
// 第四步:对初始RDD进行transformation操作,也就是一些计算操作
// 通常操作会通过创建function,并配合RDD的map、flatMap等算子来执行
// function,通常,如果比较简单,则创建指定Function的匿名内部类
// 但是如果function比较复杂,则会单独创建一个类,作为实现这个function接口的类
// 先将每一行拆分成单个的单词
// FlatMapFunction,有两个泛型参数,分别代表了输入和输出类型
// 我们这里呢,输入肯定是String,因为是一行一行的文本,输出,其实也是String,因为是每一行的文本
// 这里先简要介绍flatMap算子的作用,其实就是,将RDD的一个元素,给拆分成一个或多个元素
JavaRDD
private static final long serialVersionUID = 1L;
@Override
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
// 接着,需要将每一个单词,映射为(单词, 1)的这种格式
// 因为只有这样,后面才能根据单词作为key,来进行每个单词的出现次数的累加
// mapToPair,其实就是将每个元素,映射为一个(v1,v2)这样的Tuple2类型的元素
// 如果大家还记得scala里面讲的tuple,那么没错,这里的tuple2就是scala类型,包含了两个值
// mapToPair这个算子,要求的是与PairFunction配合使用,第一个泛型参数代表了输入类型
// 第二个和第三个泛型参数,代表的输出的Tuple2的第一个值和第二个值的类型
// JavaPairRDD的两个泛型参数,分别代表了tuple元素的第一个值和第二个值的类型
JavaPairRDD
new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String word) throws Exception {
return new Tuple2(word, 1);
}
});
// 接着,需要以单词作为key,统计每个单词出现的次数
// 这里要使用reduceByKey这个算子,对每个key对应的value,都进行reduce操作
// 比如JavaPairRDD中有几个元素,分别为(hello, 1) (hello, 1) (hello, 1) (world, 1)
// reduce操作,相当于是把第一个值和第二个值进行计算,然后再将结果与第三个值进行计算
// 比如这里的hello,那么就相当于是,首先是1 + 1 = 2,然后再将2 + 1 = 3
// 最后返回的JavaPairRDD中的元素,也是tuple,但是第一个值就是每个key,第二个值就是key的value
// reduce之后的结果,相当于就是每个单词出现的次数
JavaPairRDD
new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 到这里为止,我们通过几个Spark算子操作,已经统计出了单词的次数
// 但是,之前我们使用的flatMap、mapToPair、reduceByKey这种操作,都叫做transformation操作
// 一个Spark应用中,光是有transformation操作,是不行的,是不会执行的,必须要有一种叫做action
// 接着,最后,可以使用一种叫做action操作的,比如说,foreach,来触发程序的执行
wordCounts.foreach(new VoidFunction
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2 wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
官方文档及书籍推荐
spark 官方文档https://spark.apache.org/docs/latest/
部分书籍推荐
1.** Spark快速大数据分析**

优点:有 JAVA 参考代码,讲解还可以。
2.Spark大数据处理:技术、应用与性能优化

里面的参考代码编程语言为SCALA
3.Spark机器学习
