Tensorflow2.0实战练习之猫狗数据集(包含自定义训练和迁移学习)
最近在学习使用Tenforflow2.0,写下这篇文章,用来帮助和我一样的初学者,文章中如果存在某些问题,还希望各位指出。
目录
- 数据集介绍
- 数据处理及增强
- VGG模型介绍
- 模型搭建
- 训练及结果展示
- 自定义训练
- 迁移学习
一.数据集介绍
猫狗数据集是kaggle平台上比较著名的数据集,如果需要猫狗数据集,可以去kaggle上下载,也可以找我要,该数据集分为train和test两部分。在本次训练中,我使用的是我所看tf2.0教程提供的数据集,该数据集是精简数据集,其中train数据集部分各包含1000张猫和狗的图像。
1.简易猫狗数据集:
2.数据集

数据处理及增强
首先需要读取数据集,我们引用glob库来获取文件路径。因为数据集的标签包含在文件名中,我们通过切割文件名来获取标签,通过遍历来获取每一张图像的标签,并将他们创建为一个列表,用0表示dog,1表示cat。上述代码如下:
path = '' #path为你数据集所在的位置
train_image_path = glob.glob(path+'\\train\\*\\*.jpg')
train_image_label = [int(p.split('\\')[-2] == 'cat')for p in train_image_path]
接下来是加载图像部分
我们需要加载数据集中的每一张图像,我们选择使用tenforflow自带的tf.image模块来完成数据加载。由于我使用的数据集是比较小的数据集,所以训练量可能不够,我们可以通过1.选装图像;2.改变图像的对比度;3裁剪,亮度等来改变增加我们图像的数量。对于神经网络而言,他所处理的是图像的像素(3维矩阵),当我们改变图像的方向,亮度等条件后,图像矩阵的数值就会发生相应的变化,对于神经网络而言,就是一张新的图像。所以,通过改变图像的方向,对比度等因素可以打打提高数据集的数量,当我们遇到数据集比较小的时候,都可以采用这种方式来增加我们数据集的数量。下面就是代码展示部分:
def load_preprocess_image(path,label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image,channels = 3)
#读取jpg格式的文件,tf同时还支持多种格式图像文件的读取
image = tf.image.resize(image,[360,360])
#将读取到的图像进行缩放
image = tf.image.random_crop(image,[256,256,3])
#将读取到的图像进行裁剪
image = tf.image.random_flip_left_right(image)
#将图像上下颠倒
image = tf.image.random_flip_up_down(image)
#将图像左右颠倒
image = tf.image.random_brightness(image,0.5)
#调整图像的亮度
image = tf.image.random_contrast(image,0,1)
#调整图像的对比度
image = tf.cast(image,tf.float32)
#将图像的类型转换为tf.float32类型
image = image/255
#将图像进行归一化处理,使得图像的范围处于0和1之间
#同样可以使用tf.image.convert_image_dtype进行处理
label = tf.reshape(label,[1])
return image,label
接下来我们来看看处理前后图像的对比
处理前:
处理后:
最后我们将所得到的的数据打包成tensor,使得神经网络能够识别并使用,同时将打包后的数据集随机打乱顺序,便于训练,并提取提取部分作为batch。代码如下:
train_image_ds = tf.data.Dataset.from_tensor_slices((train_image_path,train_image_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE
#根据CPU的状况自动处理,可以不使用
train_image_ds = train_image_ds.map(load_preprocess_image,num_parallel_calls = AUTOTUNE)
train_image_ds = train_image_ds.shuffle(train_count).batch(BATCH_SIZE)
#.shuffle是随机打乱数据集的顺序
#.batch是取batch大小,这里我的BATCH_SIZE取得是16
train_image_ds = train_image_ds.prefetch(AUTOTUNE)
#预取数据
test数据集我们也做同样的处理,你们可以自己尝试着写一写test数据集的处理。
三.VGG模型介绍
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
模型架构如图所示:
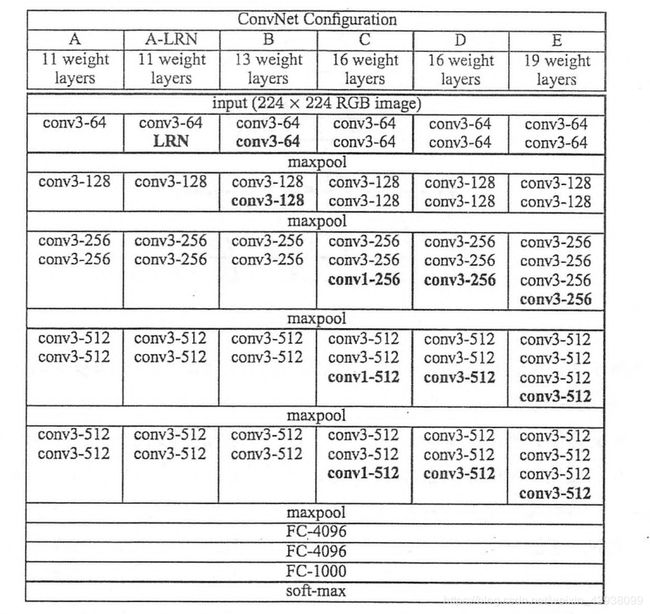
架构简介:图中的conv3是指采用33的卷积核,同理,conv1指的是采用11的卷积核,图中池化层采用的是maxpool池化。最后有4层全连接层。
模型搭建
我们采用tensorflow2.0中keras高阶封装来搭建VGG模型,使用keras的目的是模型更加简洁清晰,易于看懂。下面就是模型搭建的代码部分。
model = tf.keras.Sequential([
layers.Conv2D(64,(3,3),input_shape = (256,256,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(64,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(),
layers.Conv2D(128,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(128,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(),
layers.Conv2D(256,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(256,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(256,(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(),
layers.Conv2D(512,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(512,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(512,(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(),
layers.Conv2D(512,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(512,(3,3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(512,(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(),
layers.GlobalAveragePooling2D(),
layers.Dense(4096,activation='relu'),
layers.BatchNormalization(),
layers.Dense(4096,activation='relu'),
layers.BatchNormalization(),
layers.Dense(1000,activation='relu'),
layers.BatchNormalization(),
layers.Dense(1)
])
我们使用model.summary函数可以清晰的看到网络层结构,以及参数的大小。

五.训练及结果展示
首先我们选择adam优化器对参数进行优化,由于我们的猫狗数据集是一个二分类问题,所以我们选择binary crossentropy作为损失函数。损失函数和优化器是训练神经网络必须要的参数,而metrics是我们用来验证训练所得到的神经网络的预测能力的。代码如下:
model.compile(loss = 'binary_crossentropy',
optimizer =‘adam’,
metrics = ['acc'])
关于学习率的设置,在tf.keras.optimizers.Adam(等效于‘adam’)中,有个参数lr,我们可以通过改变lr的值来改变学习率的大小,默认学习率的大小为0.01
接下来是训练部分。代码如下:
history1 = model.fit(train_image_ds,epochs=num_epochs,
#我设置的轮数是30
steps_per_epoch = steps_per_epoch,
#step_per_epoch是每轮训练需要训练多少次,一般我们用数据的数量除batch_size得到
validation_data = test_image_ds,
validation_steps= validation_steps)
#和step_per_epoch是同样的道理
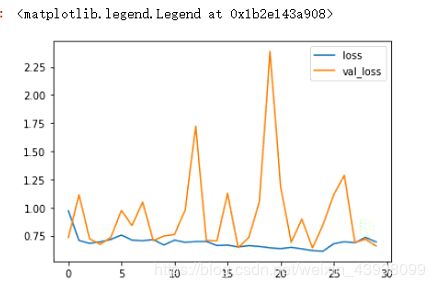
下面就是结果展示部分,我在进行了3次30轮(总共90轮)的训练后,出现了过拟合的现象,并且在测试集是的准确率也只有75%左右。如图:

下面是正确率和损失的变化情况。如图:
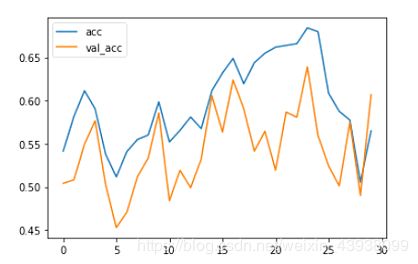
六.自定义训练
所谓自定义训练就是不使用tendforflow自带的model.compile(), model.fit()进行训练,怎么实现呢?
优化器和损失函数定义部分,代码如下:
optimizer = tf.keras.optimizers.Adam()
epoch_loss_avg = tf.keras.metrics.Mean('train_loss')
train_accuracy = tf.keras.metrics.Accuracy()
epoch_loss_avg_test = tf.keras.metrics.Mean('test_loss')
test_accuracy = tf.keras.metrics.Accuracy()
#我们使用tf.keras.metrics.Mean和tf.keras.metrics.Accuracy来记录训练过程中的损失值和正确率
单步训练部分,代码如下:
def train_step(model, images, labels):
with tf.GradientTape() as t:
#使用tf.GradientTape来记录梯度的变化
pred = model(images)
#获取预测值
loss_step = tf.keras.losses.BinaryCrossentropy(from_logits=True)(labels, pred)
#计算损失值
grads = t.gradient(loss_step, model.trainable_variables)
#计算梯度
optimizer.apply_gradients(zip(grads, model.trainable_variables))
#根据计算的梯度优化神经网络
epoch_loss_avg(loss_step)
#记录每轮训练损失值的平均值
train_accuracy(labels, tf.cast(pred>0, tf.int32))
#记录每轮训练的正确率,由于这是一个二分类问题,所以我们规定梯度为正说明预测正确,梯度为负则预测错误
#test不用优化神经网络,只需要验证神经网络
def test_step(model, images, labels):
pred = model(images, training=False)
loss_step = tf.keras.losses.BinaryCrossentropy(from_logits=True)(labels, pred)
epoch_loss_avg_test(loss_step)
test_accuracy(labels, tf.cast(pred>0, tf.int32))
下面是训练部分。代码如下:
train_loss_results = []
train_acc_results = []
test_loss_results = []
test_acc_results = []
num_epochs = 50
def train():
for epoch in range(num_epochs):
#训练
for imgs_, labels_ in train_image_ds:
train_step(model, imgs_, labels_)
print('.', end='')
print()
#记录损失和正确率
train_loss_results.append(epoch_loss_avg.result())
train_acc_results.append(train_accuracy.result())
for imgs_, labels_ in test_image_ds:
test_step(model, imgs_, labels_)
test_loss_results.append(epoch_loss_avg_test.result())
test_acc_results.append(test_accuracy.result())
print('Epoch:{}: loss: {:.3f}, accuracy: {:.3f}, test_loss: {:.3f}, test_accuracy: {:.3f}'.format(
epoch + 1,
epoch_loss_avg.result(),
train_accuracy.result(),
epoch_loss_avg_test.result(),
test_accuracy.result()
))
epoch_loss_avg.reset_states()
train_accuracy.reset_states()
epoch_loss_avg_test.reset_states()
test_accuracy.reset_states()
这些就是自定义训练的全部内容了。
七.迁移学习
什么是迁移学习呢,我的理解就是用别人训练好的神经网络来训练我们自己的神经网络,训练好的神经网络具有提取特征的功能。
那我们来看看比较官方的解释又是什么样呢?
https://blog.csdn.net/dakenz/article/details/85954548
我看这篇博主写的十分详细,想了解的可以去看看。
接下来就是迁移学习的代码部分,我们还是分步骤来.
模型搭建部分:
conv_base = keras.applications.VGG16(weights='imagenet',include_top=False)
#引用VGG16模型
conv_base.trainable =False
#设置为不可训练
model = tf.keras.Sequential()
model.add(conv_base)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
#模型搭建
训练部分:
model.compile(optimizer='Adam',
loss='binary_crossentropy',
metrics=['acc'])
num_epochs = 30
steps_per_epoch = len(train_image_path)//BATCH_SIZE
test_steps = len(test_image_path)//BATCH_SIZE
history1 = model.fit(train_image_ds,
epochs=num_epochs,
steps_per_epoch=steps_per_epoch,
validation_data = test_image_ds,
validation_steps = test_steps
)
训练的结果如下图所示:

可以看到,使用迁移学习的效果比我们自己搭建模型训练的效果高出很多。
接下来是我们解冻卷积层的最后3层,对最后3层也进行训练。
代码部分:
conv_base.trainable = True
fine_tune_at = -3
for layer in conv_base.layers[:fine_tune_at]:
layer.trainable = False
model.compile(loss = 'binary_crossentropy',
optimizer = tf.keras.optimizers.Adam(lr=0.0005/10),
metrics = ['acc'])
initial_epochs = 12
fine_tune_epochs = 10
total_epochs = initial_epochs+fine_tune_epochs
test_count = len(test_image_path)
history2 = model.fit(
train_image_ds,
epochs = total_epochs,
steps_per_epoch= steps_per_epoch,
initial_epoch = initial_epochs,
validation_data = test_image_ds,
validation_steps = test_steps)
需要注意的是initial_epochs是我们之前训练的部分其实神经网络并不进行该部分的训练。
训练结果:

写在最后
通过我本次练习,进一步增强了自己对于TensorFlow2.0的使用,并且学习到了TensorFlow处理图像数据的方法。
本文章中如若出现一些问题,还请读者们给我指出来,谢谢大家。