Searchable Symmetric Encryption Scheme——对称密文检索
引言:
在IT界,大数据安全和密码学的高级实现似乎很难找到,很简单的一个例子是:倒排索引的实现有很多,但是在加密基础上再次实现密文检索和倒排索引却是寥寥无几,这篇博文基于对称密文实现检索。
数据集
真实数据集:
http://archive.ics.uci.edu/ml/datasets/Bag+of+Words
Enron Emails,NIPS full papers,NYTimes news articles 用关键词W对密文建立索引,对密文进行检索 D=39861 代表文档数目 W=28102代表单词数目 N=6,400,000 (approx)代表单词总数
问题描述
实现以下加密方案


环境
Python3.7
Pycharm professional
Cryptography(python密码学算法库)
Cryptography是Python提供的一个为密码学使用者提供便利的第三方库,官方中,cryptography 的目标是成为“人们易于使用的密码学包”,就像 requests 是“人们易于使用的http库”一样。这个想法使你能够创建简单安全、易于使用的加密方案。如果有需要的话,你也可以使用一些底层的密码学基元,但这也需要你知道更多的细节,否则创建的东西将是不安全的。
参考学习链接:
官网:
https://cryptography.io/en/latest/
Python3加密学习:
https://linux.cn/article-7676-1.html
安装:
Pip install cryptography
调用(这里只提供本文需要的包)
from cryptography.fernet import Fernet #used for the symmetric key generation
from cryptography.hazmat.backends import default_backend #used in making key from password
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.pbkdf2 import PBKDF2HMAC
dataset
数据集: 本次实验采用University of California Irvine的数据集,Enron Emails,NIPS full papers,NYTimes news articles 用关键词W对密文建立索引,对密文进行检索 D=39861 代表文档数目 W=28102代表单词数目 N=6,400,000 (approx)代表单词总数。
首先以Enron Emails数据为例子,数据文件的数据以如下的形式呈现:

其中每一行的第一个数据是文件的编号,第二个数据是单词的编号,第三个数据是词频,这种形式的数据其实为我们在进行倒排索引的构建时提供了便利。
倒排索引word_dict的构建
这一部分是对数据集构建基本的倒排索引,采用传统的建立方法就可以,核心代码如下:
for idx, val in enumerate(filenames):#val is the name of the file
cnt = Counter()
for line in open(filenames[idx], 'r'):
print(line)
word_list = line.replace(',', '').replace('\'', '').replace('.', '').lower().split()
for word in word_list:
cnt[word] += 1
filedata.append((val, cnt))
for i in allwords:
word_dict[i]
for idx, val in enumerate(filedata):
if i in val[1]:#val[1] is allwords of the value
word_dict[i].append(val[0])# val[0] is the name of file
word_dict[i].sort()
首先我们通过两个简单的测试文件进行验证:
example1:
File1:“hello this is a test data file data file file”
File2: “also file data is a test file”
将这两个文件作为输入,可以看到输出的倒排索引如下:word_dict
defaultdict(
example2:
有了这两个的基础,我们再对Enron Emails dataset进行word_list构建,考虑到Enron Emails dataset的数据量较大,难以从输出上看到结构,我们只取其中的前10个文件对应的数据集运行,得到如下的word_dict:
defaultdict(
索引完整代码:
import itertools
from itertools import permutations, combinations # used for permutations
from cryptography.fernet import Fernet # used for the symmetric key generation
from collections import Counter # used to count most common word
from collections import defaultdict # used to make the the distinct word list
from llist import dllist, dllistnode # python linked list library
import base64 # used for base 64 encoding
import os
from cryptography.hazmat.backends import default_backend # used in making key from password
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.pbkdf2 import PBKDF2HMAC
import random # to select random key
import sys
import re
import bitarray # for lookup table
def main():
word_dict = intialization() # if you want to repair ,it is important
print(word_dict)
word_dict = intialization2()
print(word_dict)
############################################################################################
def intialization():
'''
Prompts user for documents to be encrypted and generates the distinct
words in each. Returns the distinct words and the documents that contained them
in a dictionary 'word_dict'
'''
filenames = []
x = input("Please enter the name of a file you want to encrypt: ") # filename
filenames.append(x)
while (True):
x = input("\nEnter another file name or press enter if done: ")
if not x:
break
filenames.append(x)
# finds the occurence of each word in a flle
filedata = []
for idx, val in enumerate(filenames):#val is the name of the file
cnt = Counter()
for line in open(filenames[idx], 'r'):#这里的line感觉是文件中的所有内容,,还是一个个单词读的??
print(line)
word_list = line.replace(',', '').replace('\'', '').replace('.', '').lower().split()
for word in word_list:
cnt[word] += 1
filedata.append((val, cnt))#这其实是一个统计词频的
print(filedata)
# takes the 5 most common from each document as the distinct words,in fact ,this is not necessary
allwords = []
for idx, val in enumerate(filedata):
for value, count in val[1].most_common(5):
if value not in allwords:
allwords.append(value)
print(allwords)
# makes a dictory with the distinct word as index and a value of a list of filenames
word_dict = defaultdict(list)
for i in allwords:
word_dict[i]
for idx, val in enumerate(filedata):
if i in val[1]:#val[1] is allwords of the value
word_dict[i].append(val[0])# val[0] is the name of file
word_dict[i].sort()
return word_dict
############################################################################################
def intialization2():
filenames = ["data1.txt"]
# finds the occurence of each word in a flle
filedata = []
list1=[]
docnum=0
linenum=0
for idx, val in enumerate(filenames):#val is the name of the file
cnt = Counter()
for line in open(filenames[idx], 'r'):#这里的line经过测试是按照一行一行读的,每一行有三个数字
a=1
linenum+=1
word_list = line.replace(',', '').replace('\'', '').replace('.', '').lower().split()
for data in word_list:
if a==1:#说明这个提取的词是文档的编号
if linenum!=1:
if str(doc)!=str(data):
filedata.append((doc, cnt))
del cnt
cnt = Counter()
docnum+=1
doc=data
a+=1
continue
if a==2:#说明这个提取的词是单词的编码
term=data
a+=1
continue
if a==3:
fre=data
cnt[term] = fre
#print("first line"+data)
filedata.append((doc, cnt))
#print(filedata)
allwords = []
for idx, val in enumerate(filedata):
for value, count in val[1].most_common(5):
if value not in allwords:
allwords.append(value)
#print(allwords)
# makes a dictory with the distinct word as index and a value of a list of filenames
word_dict = defaultdict(list)
for i in allwords:
word_dict[i]
for idx, val in enumerate(filedata):
if i in val[1]: # val[1] is allwords of the value
word_dict[i].append(val[0]) # val[0] is the name of file
word_dict[i].sort()
#print(word_dict)
return word_dict
if __name__ == '__main__':
main()
算法
根据输入的密码生成密钥:
key_s, key_y, key_z = keygen(password)
构造节点存储数据并进行加密,存储在数组中:
生成密钥后,对于关键词wi的所有文档,构造节点数组,每个节点由三部分组成:文档id,下一个节点的加密密钥,下一个节点的加密地址
![]()
我们使用密钥K(i,j-1)加密节点N(i,j),并将其保存在数组中的第K1(ctr)个位置,同时令ctr=ctr+1
实现:
(1) 初始化数组A,地址,加密密钥:
A = [0] * 10000
ctr = 1
keyword_key_pair = []
(2) 对word list中的灭一个word,对一个节点生成key
K_i_0 = Fernet.generate_key()
keyword_key_pair.append([i, K_i_0, ctr])
(3) 对后面的文档(1 <= j <= |D(wi)|)中的每一个,构建节点
N(i,j) = (id(D(i,j) || K(i,j) || v(s)(ctr+1))
K_i_j = Fernet.generate_key()
curr_addr = psuedo_random(key_s, ctr)
N = doc + "\n" + str(K_i_j) + "\n" + str(next_addr)
特别要注意对没后一个文档的处理,即指针尾的处理:
if j == len(doc_list) - 1:
next_addr = None
else:
next_addr = psuedo_random(key_s, ctr+1)
(4) 当然,这个节点本身也是要用K(i,j-1)进行加密的
N = Fernet(K_i_jminus1).encrypt(str.encode(N))
(5) 将加密后的节点存储后数组中,并且进行更新:
A[curr_addr] = N
K_i_jminus1 = K_i_j
ctr = ctr + 1
生成表头,存储wi的所有文档的第一个文档位置,存储置换函数的异或结果:
![]()
(1)设置伪随机置换
random.seed(keyword + str(key_z))
index = random.randrange(0, 1000)
(2)计算
addr = psuedo_random(key_s,ctr)
value = str(addr) + "\n" + str(key)
(3)对f_y进行异或
cat_string = [] #empty string to begin
for m in value:
#concatenate ascii value of each character in value
cat_string.append(ord(m))
value = [f_y ^ x for x in cat_string]
(4)将所有等于零的元素设置为某个随机键值:
for ind,val in enumerate(T):
if (val == 0):
x = random.randrange(0, 10000)
x = str(x)
x = Fernet(key_s).encrypt(str.encode(x))
T[ind] = x
完成以上内容以后,对索引节点加密的部分基本完成,我们已经建立起数组A和表单T,接下来就可以进入查询query的部分了!
生成陷门
为了保证服务器不知道我们的查询内容,我们同样需要对查询的关键字进行加密,这个过程就叫陷门。生成的陷门形式为:
![]()
(1) 返回置换函数,关键字的伪随机排列函数
random.seed(keyword + str(key_z))
index = random.randrange(0, 1000)
random.seed(keyword + str(key_y))
f_y = random.randrange(0,1000)
搜索
前面的过程中,我们已经有了T, A, trapdoor,这样服务器对给定的trapdoor,就可以从T中找到第一个节点的地址,再从A从不断查找下一个,就可以完成搜索。最后服务器将找到的文档标识返回给数据的所有者。这里要用到的一个数学性质就是a异或b再异或b等于a,这是解密的关键。
(1)将ascii值与f_y进行异或运算,以获得字符串的列表,包含节点的地址和密钥
addr_and_key = [chr(f_y ^ x) for x in value]
mystring = ''
for x in addr_and_key:
mystring = mystring + x
这里的mystring就是节点的地址
这样我们就可以对节点的内容进行解密,得到doc-id,增加到结果中即可。
split_node = re.split(r"\n", d_n)
doc_id = split_node[0]
key = split_node[1]
addr = split_node[2]
list_of_docs.append(doc_id)
实现效果:
我们以123456为密码,可以看到以下实现效果:
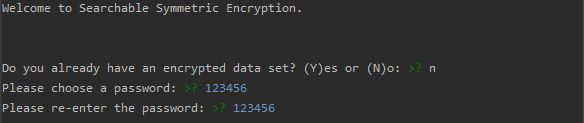
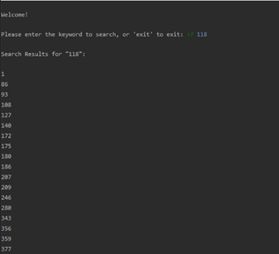
建立A,T完成后,可以进行搜索,我们以118为例子:

源代码:
import itertools
from itertools import permutations, combinations #used for permutations
from cryptography.fernet import Fernet #used for the symmetric key generation
from collections import Counter #used to count most common word
from collections import defaultdict # used to make the the distinct word list
from llist import dllist, dllistnode # python linked list library
import base64 #used for base 64 encoding
import os
from cryptography.hazmat.backends import default_backend #used in making key from password
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.pbkdf2 import PBKDF2HMAC
import random #to select random key
import sys
import re
import bitarray #for lookup table
def main():
print("Welcome to Searchable Symmetric Encryption.\n\n")
reply = input("Do you already have an encrypted data set? (Y)es or (N)o: ")
while(True):
#if yes then you have already generated keys and just want to search
if(reply.lower() == 'y' or reply.lower() == "yes"):
password = input("Please enter the password: ")
break
#if no then need to generate symmetric keys
elif (reply.lower() == 'n' or reply.lower() == "no"):
password = None
while(True):
password1 = input("Please choose a password: ")
password2 = input("Please re-enter the password: ")
if(password1 == password2):
password = password1
print("")
break
print("Passwords not the same try again\n")
# here really start
key_s, key_y, key_z = keygen(password)
word_dict = intialization2()#if you want to repair ,it is important
A, keyword_key_pair = build_array(word_dict, key_s, key_y, key_z)#A is the array, keyword_key_pair is gauge outfit
T = look_up_table(keyword_key_pair, key_s, key_y, key_z)
print("\n\nWelcome!")
keyword = input("\nPlease enter the keyword to search, or 'exit' to exit: ")
while keyword != 'exit':
trapdoor = Trapdoor(keyword, key_z, key_y) #陷门
list_of_docs = Search(T, A, trapdoor) #搜索
print(f"\nSearch Results for \"{keyword}\":\n")
for i in list_of_docs:
print(i)
keyword = input("\nPlease enter the keyword to search, or 'exit' to exit: ")
print("\n\nGoodbye!\n")
break
#this just makes sure user enters yes or no or y or n
else:
reply = input("\nInput Y for yes or N for no: ")
############################################################################################
def intialization():
'''
Prompts user for documents to be encrypted and generates the distinct
words in each. Returns the distinct words and the documents that contained them
in a dictionary 'word_dict'
'''
filenames = []
x = input("Please enter the name of a file you want to encrypt: ") #filename
filenames.append(x)
while(True):
x = input("\nEnter another file name or press enter if done: ")
if not x:
break
filenames.append(x)
# finds the occurence of each word in a flle
filedata = []
for idx, val in enumerate(filenames):
cnt = Counter()
for line in open(filenames[idx], 'r'):
word_list = line.replace(',','').replace('\'','').replace('.','').lower().split()
for word in word_list:
cnt[word]+=1
filedata.append((val,cnt))
#takes the 5 most common from each document as the distinct words
allwords = []
for idx, val in enumerate(filedata):
for value, count in val[1].most_common(5):
if value not in allwords:
allwords.append(value)
#makes a dictory with the distinct word as index and a value of a list of filenames
word_dict = defaultdict(list)
for i in allwords:
word_dict[i]
for idx, val in enumerate(filedata):
if i in val[1]:
word_dict[i].append(val[0])
word_dict[i].sort()
return word_dict
############################################################################################
def keygen(u_password):
''' Generates 3 keys, key s,y,z, based on the given password from the user. '''
# This is input in the form of a string
password_provided = u_password
# Convert to type bytes
password = password_provided.encode()
salt_s = b'\x91\xabr\xebx\xc5\x9dx^b_7\xb6\x8a\xbb5'
salt_y = b'\x1cy8\r\x7f\xf8,\xe2Pu!/\x043\xdc\x0e'
salt_z = b'\x9b\xd0\xb6\x85!J\xde\xe5\xc8\xb3\xc9\xa2\tqPy'
kdf_s = PBKDF2HMAC(
algorithm=hashes.SHA256(),
length=32,
salt=salt_s,
iterations=100000,
backend=default_backend()
)
key_s = base64.urlsafe_b64encode(kdf_s.derive(password))
kdf_y = PBKDF2HMAC(
algorithm=hashes.SHA256(),
length=32,
salt=salt_y,
iterations=100000,
backend=default_backend()
)
key_y = base64.urlsafe_b64encode(kdf_y.derive(password))
kdf_z = PBKDF2HMAC(
algorithm=hashes.SHA256(),
length=32,
salt=salt_z,
iterations=100000,
backend=default_backend()
)
key_z = base64.urlsafe_b64encode(kdf_z.derive(password))
#returns three base_64 encoded keys
return key_s, key_y, key_z
############################################################################################
def psuedo_random(key_s, ctr):
''' A pseudorandom function based on key s, to return a value to index array A '''
#Convert key s to decimal value
decimal_key = int.from_bytes(key_s, byteorder=sys.byteorder)
combined = decimal_key + ctr
#Find a random value based on key s and counter
random.seed(combined)
index = random.randrange(0, 10000)
return index
############################################################################################
def build_array(word_dict, key_s, key_y, key_z):
'''
Creates an array of nodes, each containing the document id, key to encrypt the
next node, and the address of the next node
'''
A = [0] * 10000
ctr = 1
keyword_key_pair = []
#for each word in set of distinct words, word_dict in this case
for i, doc_list in word_dict.items():
#Generate a key for the first node
K_i_0 = Fernet.generate_key()
keyword_key_pair.append([i, K_i_0, ctr])
#initialize the previous key to the first one created
K_i_jminus1 = K_i_0
# for 1 <= j <= |D(wi)|:
# for each document which has distinct word wi....iterate through doc_list
for j, doc in enumerate(doc_list):
#again generate key K(i,j)
K_i_j = Fernet.generate_key()
#N(i,j) = (id(D(i,j) || K(i,j) || v(s)(ctr+1)), where id(D(i,j) is the jth identifier in D(wi)
curr_addr = psuedo_random(key_s, ctr)
if j == len(doc_list) - 1:
next_addr = None
else:
next_addr = psuedo_random(key_s, ctr+1)# return a random value
N = doc + "\n" + str(K_i_j) + "\n" + str(next_addr)
#newline is a delimeter to separate three components of the encrypted string
#N = doc + K_i_j + address of next node.
#encrypt N with Ki,j-1, ie the previous key
N = Fernet(K_i_jminus1).encrypt(str.encode(N))
#update and save K at i,j-1
K_i_jminus1 = K_i_j
#store the encrypted N in the array
A[curr_addr] = N
#update counter
ctr = ctr + 1
# Filling in the rest of the array with random encrypted data
for ind,val in enumerate(A):
if (val == 0):
x = random.randrange(0, 10000)
x = str(x)
x = Fernet(key_s).encrypt(str.encode(x))
A[ind] = x
return A, keyword_key_pair
############################################################################################
def look_up_table(keyword_key_pair,key_s, key_y, key_z):
'''
Generates a table which stores the XORed result of permutation
function f_y and the address of a node concatenated with the key
'''
T = [0] * 1000
for i in keyword_key_pair:
keyword = i[0]
key = i[1]
ctr = i[2]
# pseudorandom permutation on z
random.seed(keyword + str(key_z))
index = random.randrange(0, 1000)
#computes value