MergeTree的Merge和Mutation机制
注:以下分析基于开源 v19.15.2.2-stable 版本进行
引言
ClickHouse内核分析系列文章,继上一篇文章 MergeTree查询链路 之后,这次我将为大家介绍MergeTree存储引擎的异步Merge和Mutation机制。建议读者先补充上一篇文章的基础知识,这样会比较容易理解。
MergeTree Mutation功能介绍
在上一篇系列文章中,我已经介绍过ClickHouse内核中的MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。但是绝大部分用户场景中,难免会出现需要手动订正、修复数据的场景。所以ClickHouse为用户设计了一套离线异步机制来支持低频的Mutation(改、删)操作。
Mutation命令执行
ALTER TABLE [db.]table DELETE WHERE filter_expr; ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr;
ClickHouse的方言把Delete和Update操作也加入到了Alter Table的范畴中,它并不支持裸的Delete或者Update操作。当用户执行一个如上的Mutation操作获得返回时,ClickHouse内核其实只做了两件事情:
-
检查Mutation操作是否合法;
-
保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
两者的主体逻辑分别在MutationsInterpreter::validate函数和StorageMergeTree::mutate函数中。
MutationsInterpreter::validate函数dry run一个异步Mutation执行的全过程,其中涉及到检查Mutation是否合法的判断原则是列值更新后记录的分区键和排序键不能有变化。因为分区键和排序键一旦发生变化,就会导致多个Data Part之间之间Merge逻辑的复杂化。剩余的Mutation执行过程可以看做是打开一个Data Part的BlockInputStream,在这个BlockStream的基础上封装删除操作的FilterBlockInputStream,再加上更新操作的ExpressionBlockInputStream,最后把数据通过BlockOutputStream写回到新的Data Part中。这里简单介绍一下ClickHouse的计算层实现,整体上它是一个火山模型的计算引擎,数据的各种filer、投影、join、agg都是通过BlockStrem抽象实现,在BlockStream中数据是按照Block进行传输处理的,而Block中的数据又是按照列模式组织,这使得ClickHouse在单列的计算上可以批量化并使用一些SIMD指令加速。BlockOutputStream承担了MergeTree Data Part列存写入和索引构建的全部工作,我会在后续的文章中会详细展开介绍ClickHouse计算层中各类功能的BlockStream,以及BlockOutputStream中构建索引的实现细节。
在Mutation命令的执行过程中,我们可以看到MergeTree会把整条Alter命令保存到存储文件夹下,然后创建一个MergeTreeMutationEntry对象保存到表的待修改状态中,最后唤醒一个异步处理merge和 mutation的工作线程。这里有一个关键的问题,因为Mutation的实际操作是异步发生的,在用户的Alter命令返回之后仍然会有数据写入,系统如何在异步订正的过程中排除掉Alter命令之后写入的数据呢?下一节中我会介绍MergeTree中Data Part的Version机制,它可以在Data Part级别解决上面的问题。但是因为ClickHouse写入链路的异步性,ClickHouse仍然无法保证Alter命令前Insert的每条纪录都被更新,只能确保Alter命令前已经存在的Data Part都会被订正,推荐用户只用来订正T+1场景的离线数据。
异步Merge&Mutation
Batch Insert和Mutation的数据一致性
struct MergeTreePartInfo { String partition_id; Int64 min_block = 0; Int64 max_block = 0; UInt32 level = 0; Int64 mutation = 0; /// If the part has been mutated or contains mutated parts, is equal to mutation version number. ... /// Get block number that can be used to determine which mutations we still need to apply to this part /// (all mutations with version greater than this block number). Int64 getDataVersion() const { return mutation ? mutation : min_block; } ... bool operator<(const MergeTreePartInfo & rhs) const { return std::forward_as_tuple(partition_id, min_block, max_block, level, mutation) < std::forward_as_tuple(rhs.partition_id, rhs.min_block, rhs.max_block, rhs.level, rhs.mutation); } }
在具体展开MergeTree的异步merge和mutation机制之前,先需要详细介绍一下MergeTree中对Data Part的管理方式。每个Data Part都有一个MergeTreePartInfo对象来保存它的meta信息,MergeTreePartInfo类的结构如上方代码所示。
-
partition_id:表示所属的数据分区id。
-
min_block、max_block:blockNumber是数据写入的一个版本信息,在上一篇系列文章中讲过,用户每次批量写入的数据都会生成一个Data Part。同一批写入的数据会被assign一个唯一的blockNumber,而这个blockNumber是在MergeTree表级别自增的。以及MergeTree在merge多个Data Part的时候会准守一个原则:在同一个数据分区下选择blockNumber区间相邻的若干个Data Parts进行合并,不会出现在同一个数据分区下Data Parts之间的blockNumber区间出现重合。所以Data Part中的min_block和max_block可以表示当前Data Part中数据的版本范围。
-
level:表示Data Part所在的层级,新写入的Data Part都属于level 0。异步merge多个Data Part的过程中,系统会选择其中最大的level + 1作为新Data Part的level。这个信息可以一定程度反映出当前的Data Part是经历了多少次merge,但是不能准确表示,核心原因是MergeTree允许多个Data Part跨level进行merge的,为了最终一个数据分区内的数据merge成一个Data Part。
-
mutation:和批量写入数据的版本号机制类似,MergeTree表的mutation命令也会被assign一个唯一的blockNumber作为版本号,这个版本号信息会保存在MergeTreeMutationEntry中,所以通过版本号信息我们可以看出数据写入和mutation命令之间的先后关系。Data Part中的这个mutation表示的则是当前这个Data Part已经完成的mutation操作,对每个Data Part来说它是按照mutation的blockNumber顺序依次完成所有的mutation。
解释了MergeTreePartInfo类中的信息含义,我们就可以理解上一节中遗留的异步Mutation如何选择哪些Data Parts需要订正的问题。系统可以通过MergeTreePartInfo::getDataVersion() { return mutation ? mutation : min_block }函数来判断当前Data Part是否需要进行某个mutation订正,比较两者version即可。
Merge&Mutation工作任务
ClickHouse内核中异步merge、mutation工作由统一的工作线程池来完成,这个线程池的大小用户可以通过参数background_pool_size进行设置。线程池中的线程Task总体逻辑如下,可以看出这个异步Task主要做三块工作:清理残留文件,merge Data Parts 和 mutate Data Part。
BackgroundProcessingPoolTaskResult StorageMergeTree::mergeMutateTask() { .... try { /// Clear old parts. It is unnecessary to do it more than once a second. if (auto lock = time_after_previous_cleanup.compareAndRestartDeferred(1)) { { /// TODO: Implement tryLockStructureForShare. auto lock_structure = lockStructureForShare(false, ""); clearOldPartsFromFilesystem(); clearOldTemporaryDirectories(); } clearOldMutations(); } ///TODO: read deduplicate option from table config if (merge(false /*aggressive*/, {} /*partition_id*/, false /*final*/, false /*deduplicate*/)) return BackgroundProcessingPoolTaskResult::SUCCESS; if (tryMutatePart()) return BackgroundProcessingPoolTaskResult::SUCCESS; return BackgroundProcessingPoolTaskResult::ERROR; } ... }
需要清理的残留文件分为三部分:过期的Data Part,临时文件夹,过期的Mutation命令文件。如下方代码所示,MergeTree Data Part的生命周期包含多个阶段,创建一个Data Part的时候分两阶段执行Temporary->Precommitted->Commited,淘汰一个Data Part的时候也可能会先经过一个Outdated状态,再到Deleting状态。在Outdated状态下的Data Part仍然是可查的。异步Task在收集Outdated Data Part的时候会根据它的shared_ptr计数来判断当前是否有查询Context引用它,没有的话才进行删除。清理临时文件的逻辑较为简单,在数据文件夹中遍历搜索"tmp_"开头的文件夹,并判断创建时长是否超过temporary_directories_lifetime。临时文件夹主要在ClickHouse的两阶段提交过程可能造成残留。最后是清理数据已经全部订正完成的过期Mutation命令文件。
enum class State { Temporary, /// the part is generating now, it is not in data_parts list PreCommitted, /// the part is in data_parts, but not used for SELECTs Committed, /// active data part, used by current and upcoming SELECTs Outdated, /// not active data part, but could be used by only current SELECTs, could be deleted after SELECTs finishes Deleting, /// not active data part with identity refcounter, it is deleting right now by a cleaner DeleteOnDestroy, /// part was moved to another disk and should be deleted in own destructor };
Merge逻辑
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可以处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool和max_bytes_to_merge_at_max_space_in_pool参数分别决定当空闲线程数最大时可处理的数据量上限以及只剩下一个空闲线程时可处理的数据量上限。当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
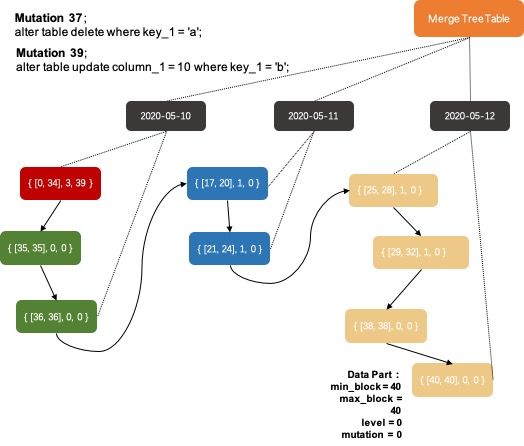
接下来介绍merge过程中最核心的逻辑:如何选择Data Parts进行merge?为了方便理解,这里先介绍一下Data Parts在MergeTree表引擎中的管理组织方式。上一节中提到的MergeTreePartInfo类中定义了比较操作符,MergeTree中的Data Parts就是按照这个比较操作符进行排序管理,排序键是(partition_id, min_block, max_block, level, mutation),索引管理结构如下图所示:

自动Merge的处理逻辑,首先是通过MergeTreeDataMergerMutator::selectPartsToMerge函数筛选出本次merge要合并的Data Parts,这个筛选过程需要准守三个原则:
-
跨数据分区的Data Part之间不能合并;
-
合并的Data Parts之间必须是相邻(在上图的有序组织关系中相邻),只能在排序链表中按段合并,不能跳跃;
-
合并的Data Parts之间的mutation状态必须是一致的,如果Data Part A 后续还需要完成mutation-23而Data Part B后续不需要完成mutation-23(数据全部是在mutation命令之后写入或者已经完成mutation-23),则A和B不能进行合并;
所以我们上面的Data Parts组织关系逻辑示意图中,相同颜色的Data Parts是可以合并的。虽然图中三个不同颜色的Data Parts序列都是可以合并的,但是合并工作线程每次只会挑选其中某个序列的一小段进行合并(如前文所述,系统会限定每次合并的Data Parts的数据量)。对于如何从这些序列中挑选出最佳的一段区间,ClickHouse抽象出了IMergeSelector类来实现不同的逻辑。当前主要有两种不同的merge策略:TTL数据淘汰策略和常规策略。
-
TTL数据淘汰策略:TTL数据淘汰策略启用的条件比较苛刻,只有当某个Data Part中存在数据生命周期超时需要淘汰,并且距离上次使用TTL策略达到一定时间间隔(默认1小时)。TTL策略也非常简单,首先挑选出TTL超时最严重Data Part,把这个Data Part所在的数据分区作为要进行数据合并的分区,最后会把这个TTL超时最严重的Data Part前后连续的所有存在TTL过期的Data Part都纳入到merge的范围中。这个策略简单直接,每次保证优先合并掉最老的存在过期数据的Data Part。
-
常规策略:这里的选举策略就比较复杂,基本逻辑是枚举每个可能合并的Data Parts区间,通过启发式规则判断是否满足合并条件,再有启发式规则进行算分,选取分数最好的区间。启发式判断是否满足合并条件的算法在SimpleMergeSelector.cpp::allow函数中,其中的主要思想分为以下几点:系统默认对合并的区间有一个Data Parts数量的限制要求(每5个Data Parts才能合并);如果当前数据分区中的Data Parts出现了膨胀,则适量放宽合并数量限制要求(最低可以两两merge);如果参与合并的Data Parts中有很久之前写入的Data Part,也适量放宽合并数量限制要求,放宽的程度还取决于要合并的数据量。第一条规则是为了提升写入性能,避免在高速写入时两两merge这种低效的合并方式。最后一条规则则是为了保证随着数据分区中的Data Part老化,老龄化的数据分区内数据全部合并到一个Data Part。中间的规则更多是一种保护手段,防止因为写入和频繁mutation的极端情况下,Data Parts出现膨胀。启发式算法的策略则是优先选择IO开销最小的Data Parts区间完成合并,尽快合并掉小数据量的Data Parts是对在线查询最有利的方式,数据量很大的Data Parts已经有了很较好的数据压缩和索引效率,合并操作对查询带来的性价比较低。
Mutation逻辑
StorageMergeTree::tryMutatePart函数是MergeTree异步mutation的核心逻辑,主体逻辑如下。系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。
Mutation功能是MergeTree表引擎最新推出一大功能,从我个人的角度看在实现完备度上还有一下两点需要去优化:
-
mutation没有实时可见能力。我这里的实时可见并不是指在存储上立即原地更新,而是给用户提供一种途径可以立即看到数据订正后的最终视图确保订正无误。类比在使用CollapsingMergeTree、SummingMergeTree等高级MergeTree引擎时,数据还没有完全merge到一个Data Part之前,存储层并没有一个数据的最终视图。但是用户可以通过Final查询模式,在计算引擎层实时聚合出数据的最终视图。这个原理对mutation实时可见也同样适用,在实时查询中通过FilterBlockInputStream和ExpressionBlockInputStream完成用户的mutation操作,给用户提供一个最终视图。
-
mutation和merge相互独立执行。看完本文前面的分析,大家应该也注意到了目前Data Part的merge和mutation是相互独立执行的,Data Part在同一时刻只能是在merge或者mutation操作中。对于MergeTree这种存储彻底Immutable的设计,数据频繁merge、mutation会引入巨大的IO负载。实时上merge和mutation操作是可以合并到一起去考虑的,这样可以省去数据一次读写盘的开销。对数据写入压力很大又有频繁mutation的场景,会有很大帮助。
for (const auto & part : getDataPartsVector()) { ... size_t current_ast_elements = 0; for (auto it = mutations_begin_it; it != mutations_end_it; ++it) { MutationsInterpreter interpreter(shared_from_this(), it->second.commands, global_context); size_t commands_size = interpreter.evaluateCommandsSize(); if (current_ast_elements + commands_size >= max_ast_elements) break; current_ast_elements += commands_size; commands.insert(commands.end(), it->second.commands.begin(), it->second.commands.end()); } auto new_part_info = part->info; new_part_info.mutation = current_mutations_by_version.rbegin()->first; future_part.parts.push_back(part); future_part.part_info = new_part_info; future_part.name = part->getNewName(new_part_info); tagger.emplace(future_part, MergeTreeDataMergerMutator::estimateNeededDiskSpace({part}), *this, true); break; }
最后在经过后台工作线程一轮merge和mutation操作之后,上一节中展示的MergeTree表引擎中的Data Parts可能发生的变化如下图所示,2020-05-10数据分区下的头两个Data Parts被merge到了一起,并且完成了Mutation 37和Mutation 39的数据订正,新产生的Data Part如红色所示:
Clickhouse产品链接:https://www.aliyun.com/product/clickhouse
上云就看云栖号:更多云资讯,上云案例,最佳实践,产品入门,访问:https://yqh.aliyun.com/
本文为阿里云原创内容,未经允许不得转载。