本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是算法与数据结构的第18篇文章,我们一起来看一个经典的数据结构——并查集。
首先我们来解释一下这个数据结构的名称,并查集其实是一个缩写,并指的是合并,查指的是查找,集自然就是集合。所以并查集的全称是合并查找集合,那么顾名思义,这是一个用来合并、查找集合的数据结构。
并查集的定义
集合虽然是一个抽象的概念,但是生活当中关于集合的操作其实不少,只是我们身处其中的时候往往习以为常了。
举个例子,比如A和B两个人都是社会精英,两人名下都有一大笔资产。突然某一天,两个人宣布结婚了,那么很显然,一般情况下两个人的资产会被合并成夫妻共同财产。如果我们把它们两人的资产都看成是一个集合,那么结婚其实就代表了这两个集合进行合并。再举一个例子,比如在古时候交通不便,河两岸的村庄往往很少来往。如果某一天河上建了一座桥,连通了河两岸,如果我们把两岸的紧密来往的村庄各自看成是一个集合,桥的建成显然也会让这两个集合合并。
上面的例子都是关于集合合并的, 关于集合查找的例子也很多。最经典的就是DNA检测,比如经常会有一些人号称自己是某某家族的后代。如果我们想要验证他们的身份最好的办法就是去查DNA谱系,我们人有一半的基因来自父亲,一般的基因来自母亲,这些基因也可以看成是集合。如果某个人号称是某朝皇室,我们把皇室的基因和他自己家族的基因一匹配,发现并非来自同一个集合,那么自然这些论调就不告而破了。据说科学家用这种方法考证了中山靖王刘胜并非刘邦的后裔,而是来自某个不知名的南方种群。
并查集正是解决了这两类集合相关的问题,即集合的合并与查找。
集合的查找
首先我们来看集合的查找,我们还是看上面那个例子,我们怎么判断两个不同的人是否来自同一个家族呢?
这个很简单,我们只需要查找它们是否有共同的祖先。如果我们基因分析他们两人的基因来自一个共同的祖先,那么说明这两人很有可能来自同一个家族。如果我们把这中间的血缘关系铺展开来,会得到一棵树形结构。祖先是树根,辈分最小的子女是树叶,和树一样,每个节点都只能有一个父节点(把父母看成一个节点),但是可以有多个子节点。
所以我们判断两个人是否来源同一个祖先,也就是判断两个节点是否在同一棵树。
由于我们要处理的数据有限,不像基因链路那么长,我们处理这个问题可以很简单。我们只需要找到这两个节点所处在的树的树根,然后比较它们的树根是否相等即可。如果相等,说明这两个节点来自同一棵树,自然属于同一个集合,否则则属于不同的集合。
到这里,我们不仅知道了应该如何查找两个节点是否属于同一个集合,还知道我们应该用树结构来表示集合。
集合的合并
既然我们明白了我们是通过树来表示集合,通过查找树根的方式来判断两个节点是否属于同一个集合,那么集合合并的操作就变得很简单了。我们只需要把两棵树合并就行了,如果需要考虑树深或者是逻辑结构的话,还不太容易,但是我们并不需要那么多信息,只需要保证集合内的元素正确。我们可以直接把其中一个树连到另一颗树当中。
比如我们有A和B两棵树需要合并:
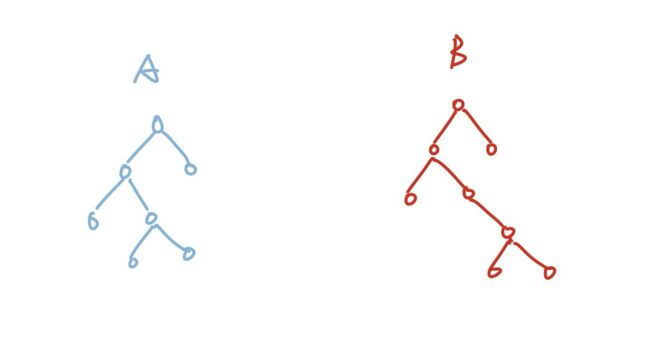
我们只需要将B的根节点连到A树上即可:
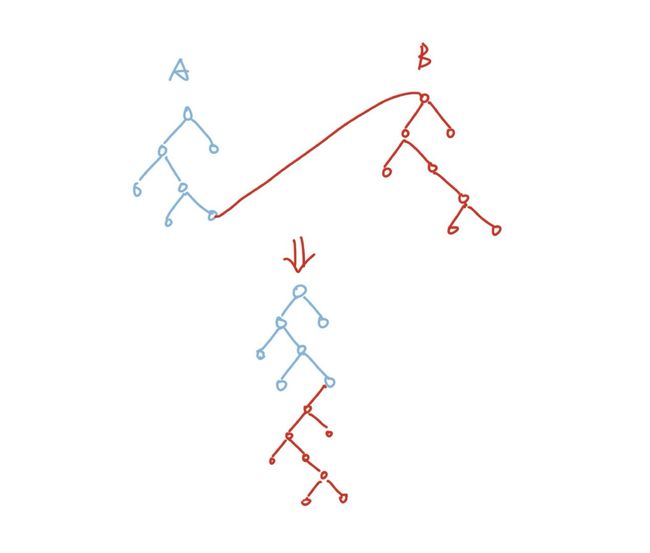
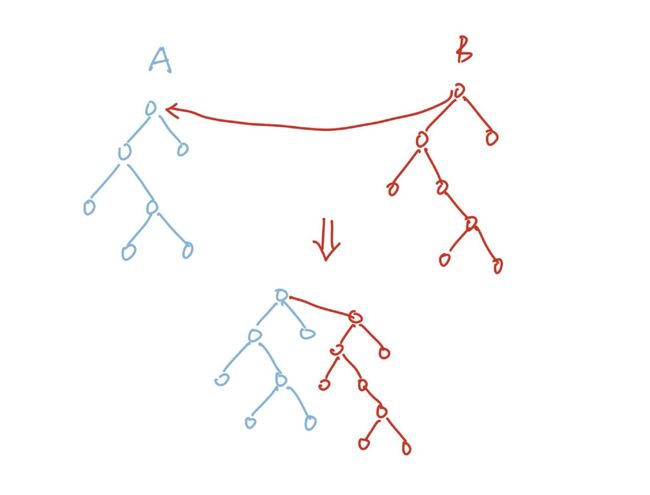
这样原来A树和B树上所有的节点都属于同一个集合,使用我们刚才查找的逻辑得出的结果也是正确的。但是我们分析一下会发现,如果我们这样合并两棵树的话会导致合并之后的树深变长,这样会使得我们后续查找的效率变低,因为我们从叶子节点到根节点变得更远了。所以我们可以直接将B树的树根指向A树的树根:
代码实现
对于树上的每一个节点而言,由于我们查找集合需要查找它们的树根,而不是叶子。所以对于树上的每一个节点而言,我们只需要记录它们的父节点即可。我们可以用一个dict存储所有节点的父节点,对于根节点而言,我们通常将它的父节点设置成它自己。也就是说当我们找到一个节点的父节点等于它自己的时候,就说明我们已经找到了树根。
明白了这个逻辑之后,我们用代码实现就变得非常简单:
father = {}
def query(x):
if father[x] == x:
return x
return query(father[x])
def union(a, b):
fa, fb = query(a), query(b)
if fa == fb:
return
father[fb] = fa
你看,这段代码十行都不到,这样当然是可以work的,但是它还有很大进步的空间。
效率优化
虽然我们已经实现了算法,但是这并不是最优的,我们还可以进行一些优化。首先我们比较容易想到,既然我们每次判断元素是否在同一个集合是通过树根来判断的,并且我们并不在意树的结构,我们只在意树根是什么。既然如此,我们完全可以不用保留树的结构,让它变得扁平,让除了根节点之外的节点都是叶子节点,比如这样:
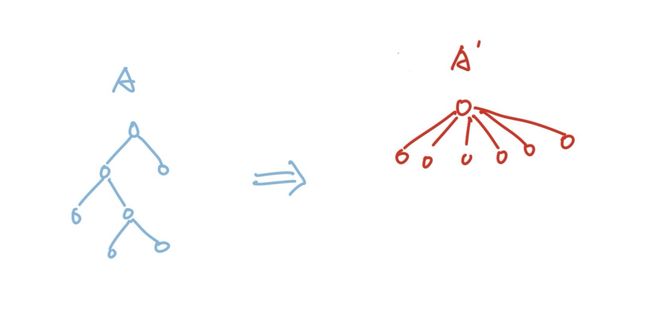
这两个棵树我们查询的结果是一样的,节点数和边的数量也是一样的,但不同的是左边的树我们查询树根最多需要遍历3次,但是右边的所有节点都最多只需要进行一次查询。如果树的结构更加复杂,那么这个优化还会更加明显。
但问题是我们做树结构的变动也是需要开销的,理论上来说每次我们进行合并之后,树结构都会发生变化。难道我们每次合并之后都需要耗费的时间进行树的重构吗?但我们并不能确定查找和合并出现的比例,有可能查找的情况很多,那我们重构树就是非常划算的,如果查找很少,大部分都是合并操作,那可能我们花了很大的代价进行了树重构,但是却没派上用场。
另外一个问题是,我们重构树是针对树上所有节点而言的,我们把所有节点都抬升到了根节点的子节点。但问题是可能并不是所有节点都参与查找的,有可能我们只查找其中几个节点的情况,那其余的节点我们也同样白白计算了。
针对这个问题,有一个非常简单也非常绝妙地优化——懒惰运算。
懒惰运算我们不是第一次遇见了,之前介绍替罪羊树的时候就曾经提到过懒惰运算。在替罪羊树当中,由于我们删除节点会导致树结构发生变化,这会带来大量开销。所以我们就不删除节点,而是给它打上一个已经删除的标记。这样当我们查找到这个节点的时候,这个节点当中的内容不参与查询,从而模拟删除。当打上了删除标记的节点数量达到一定程度的时候,我们再将它们整体批量删除。
在并查集当中同样用到了这样的懒惰计算的思想,如果我们要进行树的重构,那么势必需要查找根节点。查找根节点需要开销,那除了重构树的时候,还有什么情况下会需要重找根节点呢?很明显,就是当我们查找两个节点是否属于同一个集合的时候。既然如此,我们可以一边查找一边重构,将查找这条链路上所有的节点全部指向根节点。
我们来举个例子,假设某一次查找的是下图当中的F元素,那么查找完成之后,整棵树会变成右边的样子:
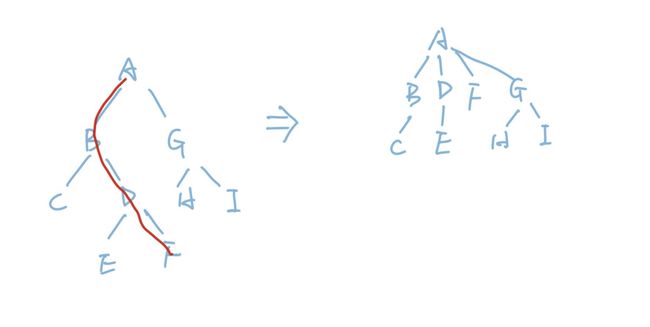
我们用递归很容易实现这个逻辑,非常简单:
def query(x):
if father[x] == x:
return x
father[x] = query(father[x])
return father[x]
除此之外,我们还有另外一个优化。就是在我们合并两棵树的时候,其实我们合并的顺序是会影响合并之后的结果的。我们用下图举个例子:
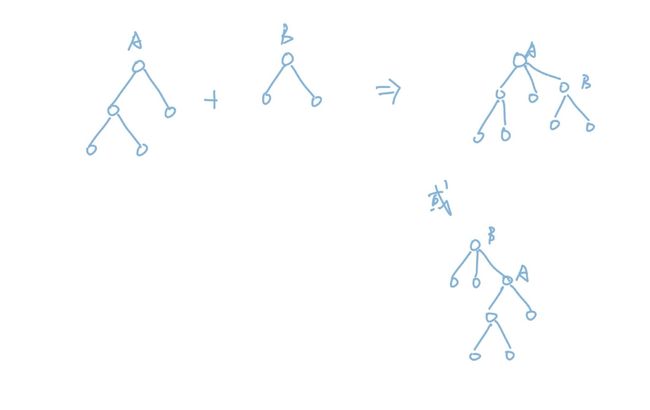
从图中可以看到,同样是两棵子树相加,A+B和B+A的结果是不同的。这两个结果当然都是正确的,但问题在于它们的深度不同。我们把树深更小的B加到树深更大的A上得到的结果树深是3,但如果反过来,得到的树深会是4。所以我们会想到可以维护每一棵子树的树深,当我们进行合并的时候,永远把树深小的加到树深大的上面,而不是相反。
最后,我们把所有的思路全部整合,写出完整的代码,非常简单,核心逻辑只有40行不到。
class DisjointSet:
def __init__(self, element_num=None):
self._father = {}
self._rank = {}
# 初始化时每个元素单独成为一个集合
if element_num is not None:
for i in range(element_num):
self.add(i)
def add(self, x):
# 添加新集合
# 如果已经存在则跳过
if x in self._father:
return
self._father[x] = x
self._rank[x] = 0
def _query(self, x):
# 如果father[x] == x,说明x是树根
if self._father[x] == x:
return x
self._father[x] = self._query(self._father[x])
return self._father[x]
def merge(self, x, y):
if x not in self._father:
self.add(x)
if y not in self._father:
self.add(y)
# 查找到两个元素的树根
x = self._query(x)
y = self._query(y)
# 如果相等,说明属于同一个集合
if x == y:
return
# 否则将树深小的合并到树根大的上
if self._rank[x] < self._rank[y]:
self._father[x] = y
else:
self._father[y] = x
# 如果树深相等,合并之后树深+1
if self._rank[x] == self._rank[y]:
self._rank[x] += 1
# 判断是否属于同一个集合
def same(self, x, y):
总结
如果你仔细思考会发现树深优化有一点点问题,因为我们在查询树根的时候做了树的重构处理,所以很有可能在此过程当中树深会发生变化。比如刚好我们查找的是树深最深的叶子节点,那么查找之后树深会减小。但是虽然有这么一个小问题,但是对我们实际使用的影响不大。一个是因为这种情况发生的概率并不大,另一个是即使发生了也不会带来很糟糕的后果,单次合并顺序不对,至多只会让树上小部分的节点的树深有常数级别的偏差。
除此之外,还有一些其他的优化方法,比如根据树的节点数来作为合并的依据。每次将节点少的树合并进节点数多的树当中,我个人觉得这个更不靠谱,因为节点越多的树并不一定树深越大,很有可能树深更小。所以总体来说一般我们还是习惯使用树深作为依据。
并查集这个算法非常经典,它并不难理解,代码量也很少,效率也高,学习曲线也很平滑,可以说除了使用场景比较窄之外几乎没有缺点。毕竟世上没有完美无缺的算法,这也是算法的魅力所在吧。
希望大家都能有所收获,原创不易,厚颜求个关注~
