scrapy框架爬取鬼故事
python版本:3.8.3
编译器:vscode
框架:scrapy
数据存放:mongodb
适合有一定爬虫基础以及scrapy框架的爬友观看
仅做技术交流,不可商用或攻击对方服务器,侵权联系作者删
转载请注明原链接
项目上传到码云:Scrapy_GhostStory
目标网站:鬼故事大全
- 生成scrapy文件
scrapy startproject Scrapy_GhostStory
cd Scrapy_GhostStory
scrapy genspider ghost "123"

- 修改一下spider.py文件
# -*- coding: utf-8 -*-
import scrapy
class GhostSpider(scrapy.Spider):
name = 'ghost'
allowed_domains = ['guidada.com']
start_urls = ['http://www.guidada.com/']
def parse(self, response):
pass

- settings.py配置文件
BOT_NAME = 'Scrapy_GhostStory'
SPIDER_MODULES = ['Scrapy_GhostStory.spiders']
NEWSPIDER_MODULE = 'Scrapy_GhostStory.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 下载延迟
DOWNLOAD_DELAY = 3
# 下载超市
DOWNLAOD_TIMEOUT = 5
# 日志显示级别
LOG_LEVEL = 'INFO'

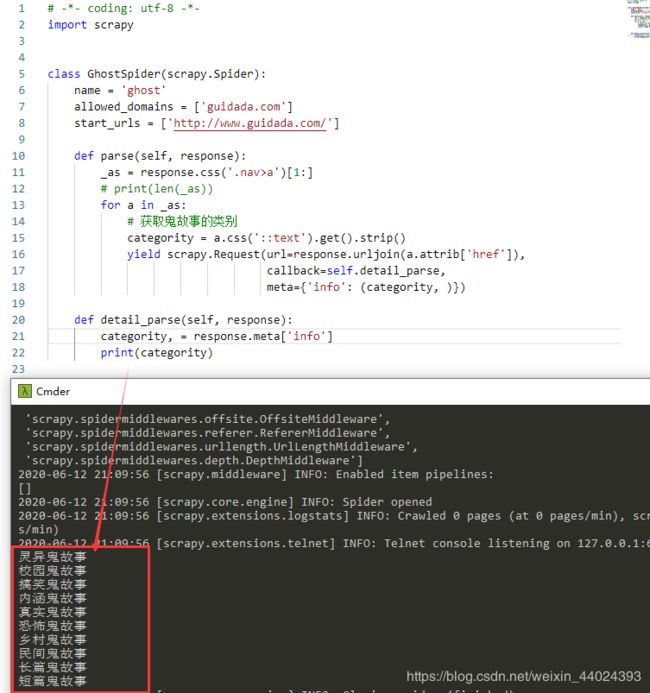
- 分析网站

def parse(self, response):
_as = response.css('.nav>a')[1:]
# print(len(_as))
for a in _as:
# 获取鬼故事的类别
categority = a.css('::text').get()
yield scrapy.Request(url=response.urljoin(a.attrib['href']),
callback=self.detail_parse,
meta={'info': (categority, )})
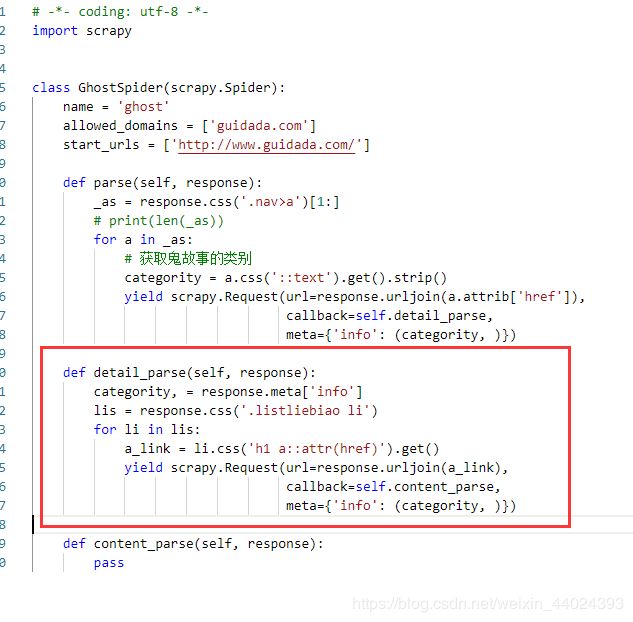
- 分析每个鬼故事类别的结构,都是在li标签里面

def detail_parse(self, response):
categority, = response.meta['info']
lis = response.css('.listliebiao li')
for li in lis:
a_link = li.css('h1 a::attr(href)').get()
yield scrapy.Request(url=response.urljoin(a_link),
callback=self.content_parse,
meta={'info': (categority, )})
- 进到详情页之后,根据自己想获取的信息直接获取就行了
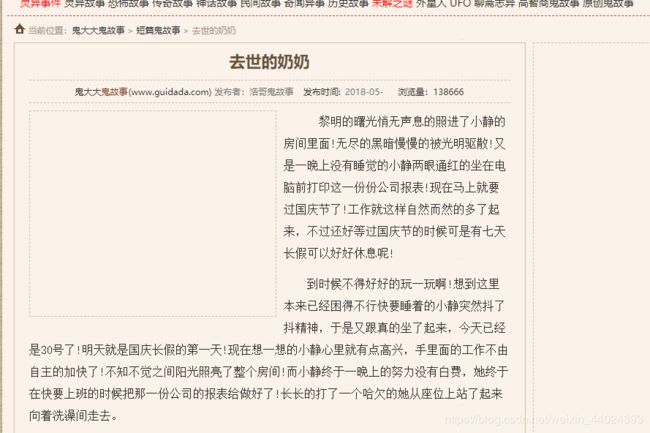
- 另外有些故事是有下一页的,这里我偷懒就不写了

- item.py,我就获取这些信息
import scrapy
class ScrapyGhoststoryItem(scrapy.Item):
# 鬼故事类别
categority = scrapy.Field()
# 标题
title = scrapy.Field()
# 发布时间
issue_time = scrapy.Field()
# 作者
author = scrapy.Field()
# 浏览量
page_views = scrapy.Field()
# 网名名字
website = scrapy.Field()
# 内容
content = scrapy.Field()
# 详情页链接
content_url = scrapy.Field()
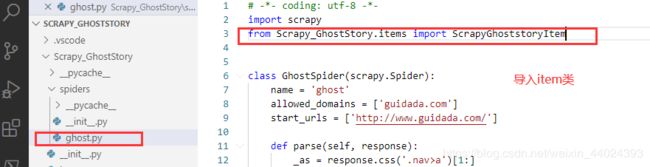
- 开始获取,记得导入item类
def content_parse(self, response):
# 鬼故事类别
categority, = response.meta['catagority']
# 标题
title = response.css('h1::text').get()
# 发布时间
try:
issue_time = response.css('.nrbt font::text').re(
r'\d+-\d+-\d+ \d+:\d+:\d+')[0]
except IndexError:
issue_time = None
# 作者
try:
author = response.css('.nrbt font::text').re(
r'发布者:(.*)')[0].strip()
except (IndexError, TypeError):
author = None
# 浏览量
page_views_link = response.css('.nrbt>span>script::attr(src)').get()
page_views = self.page_views_parse(response.urljoin(page_views_link))
# 网站名字
website = '鬼故事大全网'
# 内容
content = ''.join(response.css('div.text ::text').getall())
# 稍微清洗一下
content = re.sub(r'\s|\u3000|PC.*?;', '', content)
yield ScrapyGhoststoryItem(categority=categority,
title=title,
issue_time=issue_time,
author=author,
page_views=page_views,
website=website,
content=content,
content_url=response.url)
# 浏览量需要访问另一个链接才能获取到
def page_views_parse(self, url):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
resp = requests.get(url, headers=headers)
return re.findall(r'\d+', resp.text)[0]

- settings.py打开项目管道
# 管道
ITEM_PIPELINES = {'Scrapy_GhostStory.pipelines.ScrapyGhoststoryPipeline': 300}
- pipelines.py,将数据保存到mongodb中,数据库ghost,集合story
import pymongo
class ScrapyGhoststoryPipeline:
def __init__(self):
self.client = pymongo.MongoClient(host='192.168.19.128', port=27017)
self.db = self.client.ghost
def process_item(self, item, spider):
# 插入数据
self.db.story.insert_one(dict(item))
return item
def close(self, spider):
self.client.close()
- 运行报错了
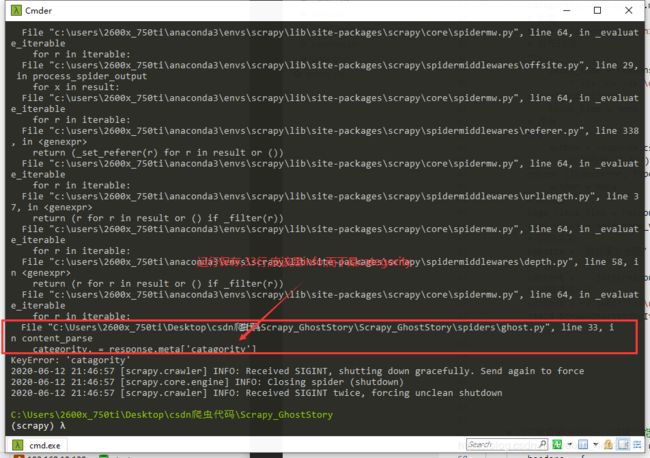
- 33行

- 修改一下

- 重新运行,数据抓取成功并存入mongodb(如果没有打印出来,那就设置settings.py的日志级别为DEBUG或者注释即可)
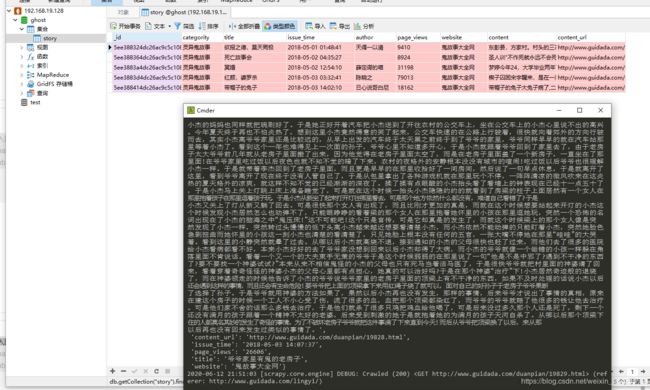
- 剩下的就是翻页了

def detail_parse(self, response):
categority, = response.meta['info']
lis = response.css('.listliebiao li')
for li in lis:
a_link = li.css('h1 a::attr(href)').get()
yield scrapy.Request(url=response.urljoin(a_link),
callback=self.content_parse,
meta={'info': (categority, )})
# 翻页
next_link = response.css('#lg_nextpage::attr(href)').get()
if next_link:
yield scrapy.Request(url=response.urljoin(next_link),
callback=self.detail_parse,
meta={'info': (categority, )})
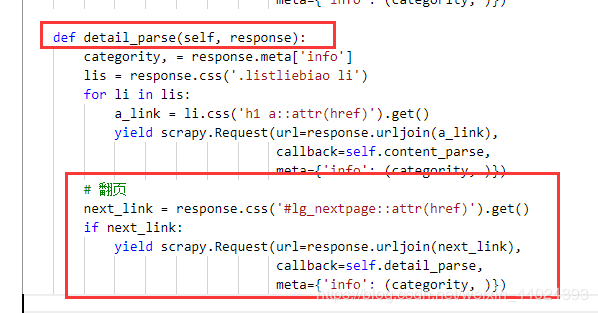
- 大功告成