爬虫练习(四)-电影票房爬取与可视化
目标:
1、从网站上爬取电影名,电影票房
2、用条形图进行可视化
思路:
1、找网站接口
![]()
![]()
由上可见每个电影都有一个4位代码号
2、拆分动作(找出存放电影代码的列表-抓网页-存列表-可视化)
代码:
1、存电影代码的列表
html_code=getFilm('http://58921.com/alltime') #抓取存放电影代码的网页
soup2=bs(html_code,'html.parser')#煲汤(利于抓取数据)
l = str(soup2.find_all('a')) #变成字符串(为了用正则表达式寻找)
film_list = re.findall(r'm/\d{4}',l)
fcode_list=[]
code = ''
for each_code in film_list:
code=each_code.split('/')[1]
fcode_list.append(code)
2、抓取网页
def getFilm(url):
try:
r = rs.get(url,headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4620.400 QQBrowser/9.7.13014.400'})
r.raise_for_status()
r.encoding='utf-8'
return r.text
except:
print('爬取失败')
3、存入表格
def Fillinfo(name_list,sales_list,html):
soup = bs(html,'html.parser')
b = str(soup.find_all('h3',class_="block_title"))
e = re.findall(r'title=\".*\"',b)[0]
file_name=e.split('\"')[1]
a = str(soup.find_all('h3',class_="panel-title"))
file_sales=re.findall('\d*\.\d*亿',a)[0]
name_list.append(file_name)
sales_list.append(file_sales)
4、运行上述函数
start_url='http://58921.com/film/'
name_list=[]
sales_list=[]
for each_film in fcode_list:
url = start_url + each_film +'/boxoffice'
html =getFilm(url)
Fillinfo(name_list,sales_list,html)
5、把票房变成数值型
int_sales=[]
for sale in sales_list:
sales = float(sale.split('亿')[0])
int_sales.append(sales)
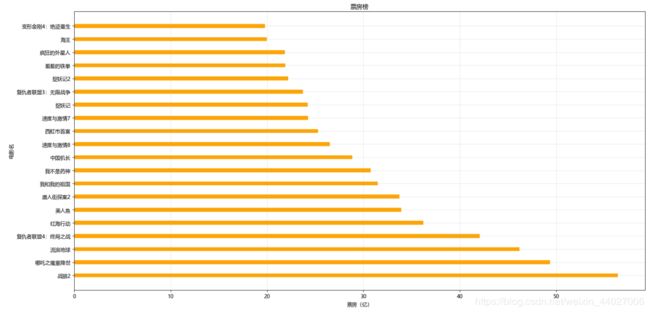
6、利用Matplotlib可视化
plt.figure(figsize=(20,10),dpi=100)
plt.yticks(range(len(name_list)),name_list)
plt.ylabel('电影名')
plt.xlabel('票房(亿)')
plt.title('票房榜')
plt.barh(range(len(name_list)),int_sales,height=0.3,color='orange')
plt.grid(alpha=0.3)
plt.show()
效果: