李宏毅机器学习(四)
此篇博文是基于李宏毅老师此视频的学习总结。此部分主要介绍,Logistic Regression模型。
一、课程部分内容记录
(1) Logistics Regression和Linear Regression对比
| Logistics Regression | Linear Regression | |
|---|---|---|
| Step 1: | f w , b ( x ) = σ ( ∑ i w i x j + b ) f_{w,b}(x) = \sigma(\sum_iw_ix_j+b) fw,b(x)=σ(∑iwixj+b) Output:value between 0 and 1 |
f w , b ( x ) = ∑ i w i x j + b f_{w,b}(x) = \sum_iw_ix_j+b fw,b(x)=∑iwixj+b Output:any value |
| Step 2: | Training data: ( x n , y ^ n ) (x^n, \hat y^n) (xn,y^n) y ^ \hat y y^:Class1 = 1,Class2 = 0 L ( f ) = ∑ n C ( f ( x n ) , y ^ n ) L(f) = \sum_n C(f(x^n),\hat y^n) L(f)=∑nC(f(xn),y^n) |
Training data: ( x n , y ^ n ) (x^n, \hat y^n) (xn,y^n) y ^ n \hat y^n y^n:real value L ( f ) = 1 2 ∑ n ( f ( x n ) − y ^ n ) 2 L(f) = \frac12\sum_n (f(x^n)-\hat y^n)^2 L(f)=21∑n(f(xn)−y^n)2 |
| Step 3: | w i = w i − η ∑ n − ( y ^ − f w , b ( x n ) ) x i n w_i = w_i-\eta\sum_n-(\hat y-f_{w,b}(x^n))x_i^n wi=wi−η∑n−(y^−fw,b(xn))xin | w i = w i − η ∑ n − ( y ^ n − f w , b ( x n ) ) x i n w_i = w_i-\eta\sum_n-(\hat y^n-f_{w,b}(x^n))x_i^n wi=wi−η∑n−(y^n−fw,b(xn))xin |
交叉熵: C ( f ( x n ) , y ^ n ) = − [ y ^ n l n f w , b ( x n ) + ( 1 − y ^ n ) l n ( 1 − f w , b ( x n ) ) ] C(f(x^n),\hat y^n)=-[\hat y^nlnf_{w,b}(x^n)+(1-\hat yn)ln(1-f_{w,b}(x^n))] C(f(xn),y^n)=−[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))]
(2) Discrimination和Generative(判别模型与生成模型)
| Discrimination Model | Generative Model | |
|---|---|---|
| Function | $P(C_1 | x) = \sigma(w.x+b)$ |
| Target | w w w , b b b | μ 1 \mu^1 μ1, μ 2 \mu^2 μ2, Σ − 1 \Sigma^{-1} Σ−1 |
生成模型的好处
- 对于较少的训练数据,比较有效;
- 针对具有噪音的数据(数据标记有问题)有效;
- 可以从不同来源估计先验概率和类依赖概率。
(3) Limitation of Logistic Regression
Logistic Regression模型具有限制,因为根据Logistic Regression模型找到的分类函数是一条直线,针对某些情况,会出现不适用:
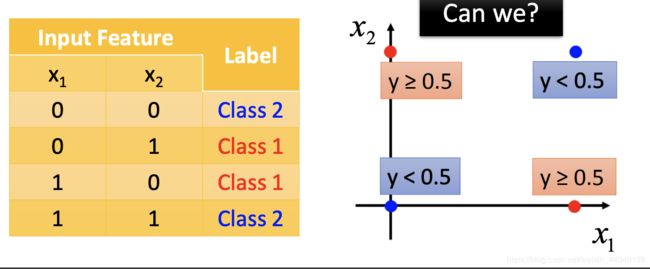
如图,你无法找到一条直线将Class1和Class2完全分开。
解决方法:
- 特征转化,转化成容易分类的特征:
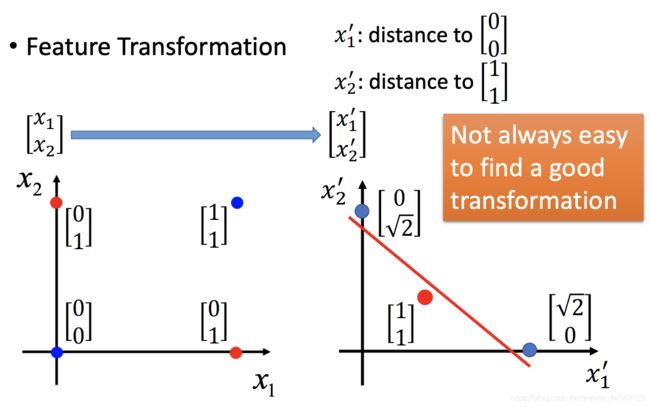
- 级联逻辑回归模型:
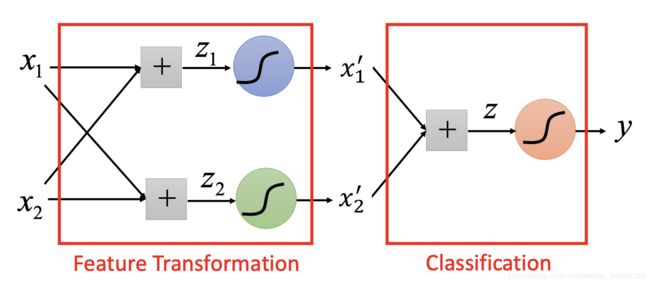
二、学习打卡
(1) Logistic Regression损失函数
LR损失函数的作用就是评价函数的好坏,也就是Step 2:Goodness of a Function,这个作用。
- 假设,训练数据如下:
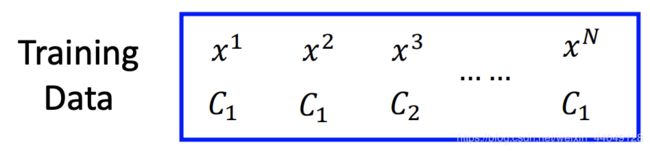
假设存在 f w , b ( x ) = P w , b ( C 1 ∣ x ) f_{w,b}(x)=P_{w,b}(C_1|x) fw,b(x)=Pw,b(C1∣x),表示选出 x x x的条件下, x x x是属于 C 1 C_1 C1的概率。
-
根据之前的学习,为了求到最优参数 w w w和 b b b,设计损失函数:
(1.1) L ( w , b ) = f w , b ( x 1 ) f w , b ( x 2 ) ( 1 − f w , b ( x 3 ) ) … L(w, b) = f_{w,b}(x^1)f_{w,b}(x^2)(1-f_{w,b}(x^3))… \tag{1.1} L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))…(1.1)
最优的 w ∗ w^* w∗和 b ∗ b^* b∗就是使损失函数值最大的那对:
(1.2) w ∗ , b ∗ = a r g m a x w , b L ( w , b ) = a r g m i n w , b − l n L ( w , b ) w^*,b^*=arg\; \underset{w,b}{max}L(w,b) = arg\; \underset{w,b}{min}-lnL(w, b) \tag{1.2} w∗,b∗=argw,bmaxL(w,b)=argw,bmin−lnL(w,b)(1.2) -
于是,可得:
(1.3) − l n L ( w , b ) = − l n f w , b ( x 1 ) − l n f w , b ( x 2 ) − l n ( 1 − f w , b ( x 3 ) ) . . . -lnL(w,b) = -lnf_{w,b}(x^1)-lnf_{w,b}(x^2)-ln(1-f_{w,b}(x^3))... \tag{1.3} −lnL(w,b)=−lnfw,b(x1)−lnfw,b(x2)−ln(1−fw,b(x3))...(1.3) -
转变数据对应方式:
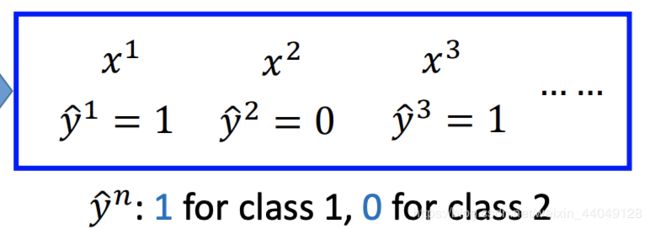
图中有错误, y ^ 2 = 1 \hat y^2=1 y^2=1,以及 y ^ 3 = 0 \hat y^3 = 0 y^3=0。因此,推导公式变成以下形式:
(1.4) − l n f w , b ( x 1 ) = − [ y ^ 1 l n f ( x 1 ) + ( 1 − y ^ 1 ) l n ( 1 − f ( x 1 ) ) ] − l n f w , b ( x 2 ) = − [ y ^ 2 l n f ( x 2 ) + ( 1 − y ^ 2 ) l n ( 1 − f ( x 2 ) ) ] − l n ( 1 − f w , b ( x 3 ) ) = − [ y ^ 3 l n f ( x 3 ) + ( 1 − y ^ 3 ) l n ( 1 − f ( x 3 ) ) ] -lnf_{w,b}(x^1) = -[\hat y^1lnf(x^1)+(1-\hat y^1)ln(1-f(x^1))] \\ -lnf_{w,b}(x^2) = -[\hat y^2lnf(x^2)+(1-\hat y^2)ln(1-f(x^2))] \\ -ln(1-f_{w,b}(x^3)) = -[\hat y^3lnf(x^3)+(1-\hat y3)ln(1-f(x^3))] \tag{1.4} −lnfw,b(x1)=−[y^1lnf(x1)+(1−y^1)ln(1−f(x1))]−lnfw,b(x2)=−[y^2lnf(x2)+(1−y^2)ln(1−f(x2))]−ln(1−fw,b(x3))=−[y^3lnf(x3)+(1−y^3)ln(1−f(x3))](1.4)
结果如图:
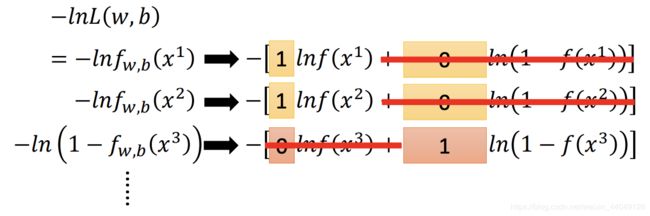
5. 对公式 (1.1)(1.3)(1.4)综合,得到下式:
(1.5) L ( w , b ) = f w , b ( x 1 ) f w , b ( x 2 ) ( 1 − f w , b ( x 3 ) ) … f w , b ( x N ) − l n L ( w , b ) = − l n f w , b ( x 1 ) − l n f w , b ( x 2 ) − l n ( 1 − f w , b ( x 3 ) ) . . . − l n L ( w , b ) = ∑ n [ y ^ n l n f w , b ( x n ) + ( 1 − y ^ n ) l n ( 1 − f w , b ( x n ) ) ] L(w, b) = f_{w,b}(x^1)f_{w,b}(x^2)(1-f_{w,b}(x^3))…f_{w,b}(x^N) \\ -lnL(w,b) = -lnf_{w,b}(x^1)-lnf_{w,b}(x^2)-ln(1-f_{w,b}(x^3))... \\ -lnL(w,b) = \sum_n[\hat y^nlnf_{w,b}(x^n)+(1-\hat y^n)ln(1-f_{w,b}(x^n))] \tag{1.5} L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))…fw,b(xN)−lnL(w,b)=−lnfw,b(x1)−lnfw,b(x2)−ln(1−fw,b(x3))...−lnL(w,b)=n∑[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))](1.5)
6. 最后,展示如下图所示的形式:

其中cross entropy是交叉熵,表示两个分布p和q之间的接近程度。
(2) Logistic Regression梯度下降
LR梯度下降的目的就是在LR损失函数的基础上,找到最好的函数。
-
根据推导结果公式1.5,损失函数对 w w w进行偏微分:
(2.1) − l n L ( w , b ) ∂ w i = ∑ n [ y ^ n l n f w , b ( x n ) ∂ w i + ( 1 − y ^ n ) l n ( 1 − f w , b ( x n ) ) ∂ w i ] \frac{-lnL(w,b)}{\partial w_i} = \sum_n[\hat y^n \frac{lnf_{w,b}(x^n)}{\partial w_i} +(1-\hat y^n) \frac{ln(1-f_{w,b}(x^n))}{\partial w_i} ] \tag{2.1} ∂wi−lnL(w,b)=n∑[y^n∂wilnfw,b(xn)+(1−y^n)∂wiln(1−fw,b(xn))](2.1) -
根据上一节课程的结果,知道:函数 f w , b ( x ) f_{w,b}(x) fw,b(x)是一个关于 z z z的SIGMOD函数:
(2.2) f w , b ( x ) = σ ( z ) = 1 1 + e − z z = w . x + b = ∑ i w i x i + b f_{w,b}(x)=\sigma(z) = \frac{1}{1+e^{-z}} \\ z = w.x+b = \sum_iw_ix_i+b \tag{2.2} fw,b(x)=σ(z)=1+e−z1z=w.x+b=i∑wixi+b(2.2) -
计算公式(2.1)的偏微分,首先计算左侧偏微分:
(2.3) ∂ l n f w , b ( x ) ∂ w i = ∂ l n f w , b ( x ) ∂ z . ∂ z ∂ w i \frac{\partial lnf_{w,b}(x)}{\partial w_i} = \frac{\partial lnf_{w,b}(x)}{\partial z}.\frac{\partial z}{\partial w_i} \tag{2.3} ∂wi∂lnfw,b(x)=∂z∂lnfw,b(x).∂wi∂z(2.3)
结合公式(2.2)对公式(2.3)细分:
(2.4) ∂ l n f w , b ( x ) ∂ z = ∂ l n σ ( z ) ∂ z = 1 σ ( z ) . ∂ σ ( z ) ∂ z = 1 σ ( z ) . σ ( z ) ( 1 − σ ( z ) ) = 1 − σ ( z ) \frac{\partial lnf_{w,b}(x)}{\partial z}=\frac{\partial ln\sigma(z)}{\partial z}=\frac{1}{\sigma(z)}.\frac{\partial\sigma(z)}{\partial z}=\frac{1}{\sigma(z)}.\sigma(z)(1-\sigma(z)) = 1-\sigma(z) \tag{2.4} ∂z∂lnfw,b(x)=∂z∂lnσ(z)=σ(z)1.∂z∂σ(z)=σ(z)1.σ(z)(1−σ(z))=1−σ(z)(2.4)
(2.5) ∂ z ∂ w i = x i \frac{\partial z}{\partial w_i} = x_i \tag{2.5} ∂wi∂z=xi(2.5)
结合公式(2.4)和(2.5),可得:
(2.6) ∂ l n f w , b ( x ) ∂ w i = ( 1 − f w , b ( x n ) ) x i n \frac{\partial lnf_{w,b}(x)}{\partial w_i} = (1-f_{w,b}(x^n))x_i^n \tag{2.6} ∂wi∂lnfw,b(x)=(1−fw,b(xn))xin(2.6)
同理,计算公式(2.1)右侧的偏微分:
(2.7) ∂ l n ( 1 − f w , b ( x ) ) ∂ w i = ∂ ( 1 − l n f w , b ( x ) ) ∂ z . ∂ z ∂ w i \frac{\partial ln(1-f_{w,b}(x))}{\partial w_i} = \frac{\partial (1-lnf_{w,b}(x))}{\partial z}.\frac{\partial z}{\partial w_i} \tag{2.7} ∂wi∂ln(1−fw,b(x))=∂z∂(1−lnfw,b(x)).∂wi∂z(2.7)
结合公式(2.2)对公式(2.7)细分:
(2.8) ∂ l n ( 1 − f w , b ( x ) ) ∂ w i = 1 1 − σ ( z ) . ∂ σ ( z ) ∂ z = 1 1 − σ ( z ) . σ ( z ) ( 1 − σ ( z ) ) = σ ( z ) \frac{\partial ln(1-f_{w,b}(x))}{\partial w_i} =\frac{1}{1-\sigma(z)}.\frac{\partial\sigma(z)}{\partial z}=\frac{1}{1-\sigma(z)}.\sigma(z)(1-\sigma(z)) = \sigma(z) \tag{2.8} ∂wi∂ln(1−fw,b(x))=1−σ(z)1.∂z∂σ(z)=1−σ(z)1.σ(z)(1−σ(z))=σ(z)(2.8)
(2.9) ∂ z ∂ w i = x i \frac{\partial z}{\partial w_i} = x_i \tag{2.9} ∂wi∂z=xi(2.9)
结合公式(2.8)和(2.9),可得:
(2.10) ∂ l n ( 1 − f w , b ( x ) ) ∂ w i = f w , b ( x n ) x i n \frac{\partial ln(1-f_{w,b}(x))}{\partial w_i} = f_{w,b}(x^n)x_i^n \tag{2.10} ∂wi∂ln(1−fw,b(x))=fw,b(xn)xin(2.10)
- 将偏微分计算结果代入公式(2.1)中,可得:
(2.11) − l n L ( w , b ) ∂ w i = ∑ n − [ y ^ n ( 1 − f w , b ( x n ) ) x i n − ( 1 − y ^ n ) f w , b ( x n ) x i n ] = ∑ n − ( y ^ − f w , b ( x n ) ) x i n \frac{-lnL(w,b)}{\partial w_i} = \sum_n-[\hat y^n(1-f_{w,b}(x^n))x_i^n-(1-\hat y^n)f_{w,b}(x^n)x_i^n] \\ = \sum_n-(\hat y-f_{w,b}(x^n))x_i^n \tag{2.11} ∂wi−lnL(w,b)=n∑−[y^n(1−fw,b(xn))xin−(1−y^n)fw,b(xn)xin]=n∑−(y^−fw,b(xn))xin(2.11)
因此,梯度下降的迭代式:
(2.12) w i = w i − η ∑ n − ( y ^ − f w , b ( x n ) ) x i n w_i = w_i-\eta\sum_n-(\hat y-f_{w,b}(x^n))x_i^n \tag{2.12} wi=wi−ηn∑−(y^−fw,b(xn))xin(2.12)
从结果来看,当前输出 f w , b ( x n ) f_{w,b}(x^n) fw,b(xn)与实际值 y ^ \hat y y^的差距越大,梯度更新值越大。
(3) Softmax原理
在机器学习中,softmax函数广泛使用于多分类的场景中。他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。因此,经过softmax处理后的数据,输出的是每个分类被取到的概率。下图是李老师在课件中展示的softmax计算原理:

假设有一系列不同类别的数, z i z_i zi表示第 i i i个元素,一共有 j j j个数。这个元素的softmax值就是:
S i = e z i ∑ j e z j S_i = \frac{e^{z_i}}{\sum_j e^{z_j}} Si=∑jezjezi
(4) softmax损失函数
首先,重新定义一个Softmax函数:
(3.1) S i = e V i ∑ i C e i V S_i = \frac{e^{V_i}}{\sum_i^C e^V_i} \tag{3.1} Si=∑iCeiVeVi(3.1)
其中, V i V_i Vi 是经过模型函数之后输出的值。 i i i表示第 i i i类,总的类别个数为 C C C。 S i S_i Si 表示的是当前元素的指数与所有元素指数和的比值。
根据上节可知,softmax的输出是:
(3.2) S i = e S y i ∑ j = 1 C e S j S_i= \frac{e^{S_{y_i}}}{\sum_{j=1}^C e^{S_j}} \tag{3.2} Si=∑j=1CeSjeSyi(3.2)
S y i S_{y_i} Syi是正确类别对应的线性得分函数, S i S_i Si 是正确类别对应的 Softmax输出。由于 l n ln ln 运算符不会影响函数的单调性,我们对 S i S_i Si 进行 $ln $操作:
(3.3) l n S i = l n e S y i ∑ j = 1 C e S j lnS_i= ln\frac{e^{S_{y_i}}}{\sum_{j=1}^C e^{S_j}} \tag{3.3} lnSi=ln∑j=1CeSjeSyi(3.3)
我们希望 $S_i $越大越好,即正确类别对应的相对概率越大越好,在 l n S i lnS_i lnSi 前面加个负号,表示损失函数:
(3.4) L i = − l n S i = − l n e S y i ∑ j = 1 C e S j L_i=-lnS_i=-ln\frac{e^{S_{y_i}}}{\sum_{j=1}^Ce^{S_j}} \tag{3.4} Li=−lnSi=−ln∑j=1CeSjeSyi(3.4)
进一步处理:
(3.5) L i = − l n e S y i ∑ j = 1 C e S j = − ( s y i − l n ∑ j = 1 C e s j ) = − s y i + l n ∑ j = 1 C e s j L_i=-ln\frac{e^{S_{y_i}}}{\sum_{j=1}^Ce^{S_j}}=-(s_{y_i}-ln\sum_{j=1}^Ce^{s_j})=-s_{y_i}+ln\sum_{j=1}^Ce^{s_j} \tag{3.5} Li=−ln∑j=1CeSjeSyi=−(syi−lnj=1∑Cesj)=−syi+lnj=1∑Cesj(3.5)
于是,损失函数简化成公式(3.5)。
(5) Softmax梯度下降
Softmax梯度下降是对权重参数进行求导:
(4.1) ∂ L i ∂ w i = − s y i + l n ∑ j = 1 C e s j ∂ w i = − s y i ∂ w i + l n ∑ j = 1 C e s j ∂ w i \frac{\partial L_i}{\partial w_i} = \frac{-s_{y_i}+ln\sum_{j=1}^Ce^{s_j}}{\partial w_i} = \frac{-s_{y_i}}{\partial w_i} + \frac{ln\sum_{j=1}^Ce^{s_j}}{\partial w_i} \tag{4.1} ∂wi∂Li=∂wi−syi+ln∑j=1Cesj=∂wi−syi+∂wiln∑j=1Cesj(4.1)
其中, s y j = w i . x + b i s_{y_j} = w_i.x+b_i syj=wi.x+bi, s j = w j . x + b j s_j = w_j.x+b_j sj=wj.x+bj
(4.2) − s y i ∂ w i = − ( w i . x + b i ) ∂ w i = − x l n ∑ j = 1 C e s j ∂ w i = l n e s 1 + l n e s 2 + . . . + l n e s C ∂ w i = x w 1 . x + b 1 + x w 2 . x + b 2 + . . . + x w C . x + b C \frac{-s_{y_i}}{\partial w_i} = \frac{-(w_i.x+b_i)}{\partial w_i} = -x \\ \frac{ln\sum_{j=1}^Ce^{s_j}}{\partial w_i} = \frac{ln\;e^{s_1}+ln\;e^{s_2}+...+ln\;e^{s_C} }{\partial w_i} = \frac{x}{w_1.x+b_1}+\frac{x}{w_2.x+b_2}+...+\frac{x}{w_C.x+b_C} \tag{4.2} ∂wi−syi=∂wi−(wi.x+bi)=−x∂wiln∑j=1Cesj=∂wilnes1+lnes2+...+lnesC=w1.x+b1x+w2.x+b2x+...+wC.x+bCx(4.2)
最终,得到:
(4.3) ∂ L i ∂ w i = − x + ∑ j C x w j + b j \frac{\partial L_i}{\partial w_i} = -x+\sum_j^C \frac{x}{w_j+b_j} \tag{4.3} ∂wi∂Li=−x+j∑Cwj+bjx(4.3)
因此,梯度下降的迭代式:
(4.4) w i = w i − η ( − x + ∑ j C x w j + b j ) w_i = w_i-\eta(-x+\sum_j^C \frac{x}{w_j+b_j}) \tag{4.4} wi=wi−η(−x+j∑Cwj+bjx)(4.4)