Pytorch实现CNN_含验证集
一、CNN的结构
输入层---->[卷积层*N---->池化层]*M---->全连接层
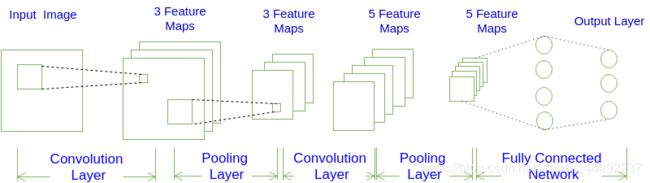
二、卷积、池化和训练
卷积运算过程:
以为5* 5的image和 3* 3的filter,stride=1,Relu为激活函数,为例。
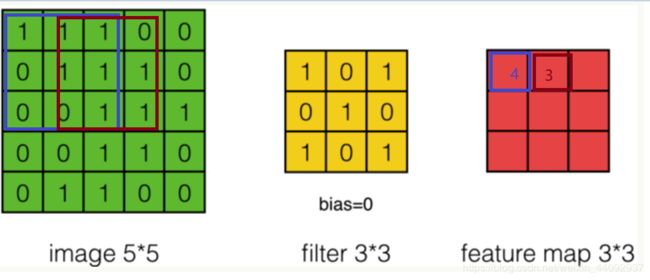
feature_map中第一个元素的计算公式:
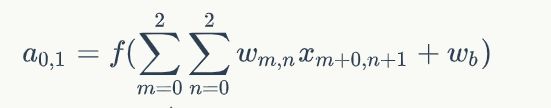
feature_map[0][0]=Relu(1 * 1+1 * 0+1 * 1+0 * 0+1* 1+1 * 0+0 * 1+0 * 0+1 * 1)
=Relu(4)
= 4
feature_map[0][1]=Relu(1 * 1+ 1 * 0+ 0 * 1 + 1 * 0 + 1 * 1+ 1 * 0 + 0 * 1 + 1 * 0 +1* 1) =Relu(3)
= 3
以此类推可以得到frature_map的矩阵。
和全连接神经网络不同,有局部连接和权值共享的思想:每层神经元只和上一层部分神经元相连,且filter的权值对于上一层所有神经元都是一样的。
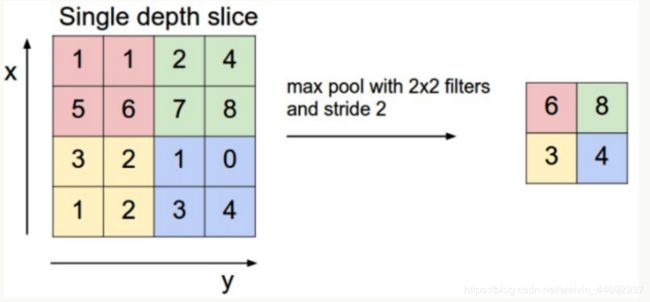
池化的过程
Pooling层主要的作用是下采样,进一步减少参数数量。
以常用的Max Pooling为例(也可以用Mean Pooling 取平均值)。以2*2的filter,以stride=1进行扫描,取扫描区域中的最大值作样本值。
全连接层
其实就是在池化层后面加了全连接神经网络。
这里需要将池化层的输出展平,作为全连接层的输入。
卷积层的训练
训练算法依然是反向传播算法。
池化层误差传递
在卷积神经网络的训练中,Pooling层需要做的仅仅是将误差项传递到上一层,而没有梯度的计算。下一层的误差项的值会原封不动的传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0。
(对于mean pooling,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元)
二、用CNN实现 Mnist手写数据集分类
整体流程:
卷积( Conv2d ) -> 激励函数( ReLU ) -> 池化, 向下采样 ( MaxPooling ) -> 再来一遍 -> 展平多维的卷积成的特征图 -> 接入全连接层 ( Linear ) -> 输出。
我用工具NN-SVG,画了下面这张图:
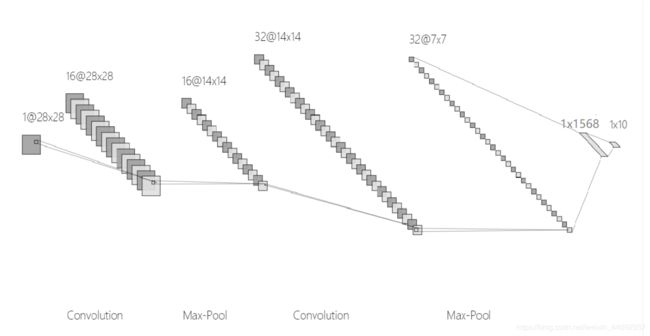
超参数 Hyper Parameters
EPOCH = 1 # 训练次数
BATCH_SIZE = 50 # 每一批训练的数据量
LR = 0.001 # 学习率 learning_rate
DOWNLOAD_MNIST = False
Mnist数据集
我们从mnist中下载黑白的手写数字图片。它是 1 * 28 * 28。
(若是RGB图片,为 3* 28 *28)
TIP:像素的值需要从区间[0,255] 压缩到 [0,1]。
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存的位置
train = True, # 训练集
transform = torchvision.transforms.ToTensor(), # 将(o,255)的像素值压缩到 (0,1)
download = DOWNLOAD_MNIST, # 下载完成后 DOWNLOAD_MNIST=Flase
)
CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.covn1=nn.Sequential(
nn.Conv2d( # (1,28,28)
in_channels=1, #黑白为1 RGB为3
out_channels=16, #filter的个数
kernel_size=5, #filter为 5*5
stride=1, #步长为1
padding=2, # padding=(kernal_size-stride)/2=(5-1)/2
), # ->(16,28,28)
nn.ReLU(), # ->(16,28,28)
nn.MaxPool2d(kernel_size=2), #2*2的filter扫描选择最大值 ->(16,14,14)
)
self.conv2=nn.Sequential( #(16,14,14)
nn.Conv2d(16,32,5,1,2), # ->(32,14,14)
nn.ReLU(), # ->(32,14,14)
nn.MaxPool2d(2) # ->(32,7,7)
)
self.out=nn.Linear(32*7*7,10) # 全连接神经网络将它展平 0~9共有十个分类
def forward(self,x):
x=self.covn1(x)
x=self.conv2(x) #(batch,32,7,7)
x=x.view(x.size(0),-1) #(batch,32*7*7)
output=self.out(x)
return output
print(cnn)

训练
将 y 都用 Variable 包起来, 然后放入 cnn 中计算 output, 最后再计算误差.
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
loss_func=nn.CrossEntropyLoss()
#traning and testing
for epoch in range(EPOCH):
for step,(x,y) in enumerate(train_loader):
b_x=Variable(x)
b_y=Variable(y)
output=cnn(b_x)
loss=loss_func(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
训练完成后选择十个数字进行测试
test_output=cnn(test_x[:10])
pred_y=torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
最后老师让修改代码,分清楚了测试集、验证集、训练集。
总共2000张照片,前1600作为测试集,200张验证,200张测试。
所谓验证集就是在训练过程中进行准确率的测试。
注意这里图片是随机的,我用random.shuffle()函数来实现。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
from sklearn.utils import shuffle
import random
# torch.manual_seed(1)
# Hyper Parameters
EPOCH = 2 # 迭代次数
BATCH_SIZE = 50 # 批数据大小
LR = 0.001 # 学习率 learning_rate
DOWNLOAD_MNIST = False
# Mnist 手写数字
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存的位置
train = True, # 训练集
transform = torchvision.transforms.ToTensor(), # 将图片转化为tensor的形式,且/255归一化到[0,1.0]之间
download = DOWNLOAD_MNIST, # 下载完成后 DOWNLOAD_MNIST=Flase
)
#设置测试集
test_data = torchvision.datasets.MNIST(root='./mnist/', train = False)
# 训练数据加载器:批训练 50samples, 1 channel, 28x28 ,(50, 1, 28, 28),
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1), volatile=True).type(torch.FloatTensor)[
:2000] / 255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.covn1=nn.Sequential(
nn.Conv2d( # (1,28,28)
in_channels=1, #灰度图像为1 RGB为3
out_channels=16, #filter有16个,输出的维度为16
kernel_size=5, #filter为 5*5
stride=1, #步长为1
padding=2, # padding=(kernal_size-stride)/2=(5-1)/2 卷积出来图像尺寸不变
), # ->(16,28,28)
nn.ReLU(), # ->(16,28,28)
nn.MaxPool2d(kernel_size=2), #2*2的filter扫描选择最大值 ->(16,14,14)
)
self.conv2=nn.Sequential( #(16,14,14)
nn.Conv2d(16,32,5,1,2), # ->(32,14,14)
nn.ReLU(), # ->(32,14,14)
nn.MaxPool2d(2) # ->(32,7,7)
)
self.out=nn.Linear(32*7*7,10) # flatten ;0~9共有10个分类
def forward(self,x):
x=self.covn1(x)
x=self.conv2(x)
x=x.view(x.size(0),-1) #降维
output=self.out(x)
return output
cnn=CNN()
print(cnn)
#定义优化器
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
#定义损失函数
loss_func=nn.CrossEntropyLoss()
#traning
for epoch in range(EPOCH):
random.seed(epoch)
random.shuffle(train_data.train_data)
random.seed(epoch)
random.shuffle(train_data.train_labels)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
random.seed(epoch)
random.shuffle(test_data.test_data)
random.seed(epoch)
random.shuffle(test_data.test_labels)
test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1), volatile=True).type(torch.FloatTensor)[
:2000] / 255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
for step,(x,y) in enumerate(train_loader):
b_x=Variable(x)
b_y=Variable(y)
output=cnn(b_x)
loss=loss_func(output,b_y)
optimizer.zero_grad() #把梯度置零,也就是把loss关于weight的导数变成0
loss.backward() # caculate gradient
optimizer.step() # apply gradient
if step==1600:
break
validation_output = cnn(test_x[1600:1800])
val_y = torch.max(validation_output, 1)[1].data.numpy().squeeze()
print('validation :', val_y)
print('real number:', test_y[1600:1800].numpy())
b=0
for i in range(200):
if val_y[i] == test_y[1600:1800].numpy()[i]:
b += 1
val_accuracy = float(b / 200)
print('| val accuracy: %.2f' % val_accuracy)
test_output=cnn(test_x[1800:2000])
pred_y=torch.max(test_output,1)[1].data.numpy().squeeze()
print('prediction :',pred_y)
print('real number:',test_y[1800:2000].numpy())
a=0
for i in range(200):
if pred_y[i]==test_y[1800:2000].numpy()[i]:
a+=1
accuracy=float(a/200)
print('| test accuracy: %.2f' % accuracy)