【简单总结】句子相似度计算的几种方法
【简单总结】句子相似度计算的几种方法
1.句子相似度介绍:
句子相似度–指的是两个句子之间相似的程度。在NLP中有很大的用处,譬如对话系统,文本分类、信息检索、语义分析等,它可以为我们提供检索信息更快的方式,并且得到的信息更加准确。
2.句子相似计算的方法概括:
句子相似度计算主要分为:
- 基于统计的方法:
-
莱文斯坦距离(编辑距离)
-
BM25
-
TFIDF计算
-
TextRank算法中的句子相似性
-
-
基于深度学习的方法:
-
基于Word2Vec的余弦相似度
-
DSSM(Deep Structured Semantic Models)
-
3.句子相似计算方法具体介绍:
3.1基于统计的方法:
3.1.1莱文斯坦距离(编辑距离)
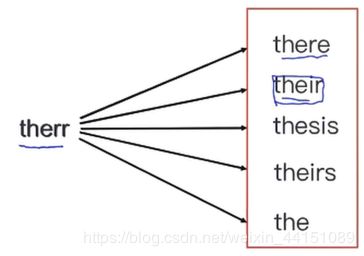
编辑距离是描述由一个字串转化成另一个字串最少的编辑操作次数,如果它们的距离越大,说明它们越是不同。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
举例:there的几个变形
3.1.2BM25算法
BM25算法,BM25源于概率相关模型,而非向量空间模型,BM25同样词频,逆文档频率以及字段长度归一化,但是每个因子的定义都有细微差别。通常用来作搜索相关性平分。BM25算法通过加入文档权值和查询权值,拓展了二元独立模型的得分函数。
主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。其实这个算法的原理很简单,就是将需要计算的query分词成w1,w2,…,wn,然后求出每一个词和文章的相关度,最后将这些相关度进行累加,最终就可以的得到文本相似度计算结果。
计算公式:

其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。 这个公式第二项R(qi,d)表示我们查询query中的每一个词和文章d的相关度。
3.1.3TFIDF计算
TFIDF :就是在词频 TF 的基础上再加入 IDF 的信息,IDF 称为逆文档频率。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。TF意思是词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数,IDF意思是逆文本频率指数(Inverse Document Frequency)是一个词语普遍重要性的度量。
主要思想:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF的计算公式分三步走:

其统计公式如下:
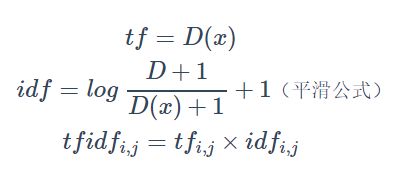
其中,tf表示词频(Term Frequency),即词条在文档i中出现的频率;idf为逆向文件频率(Inverse Document Frequency),表示某个关键词在整个语料所有文章中出现的次数的倒数(该指标用于降低常用词的重要性)。
优点:能过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要词语。
缺点:不能有效反应特征词的分布情况,也没有体现词语的位置信息(通常文章首尾句词的重要性较高)。
算法实现:
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
sys.path.append("你的路径")
from numpy import *
fr = open('你的文本名.txt')
fr_list = fr.read()
dataList = fr_list.split('\n')
data = []
for oneline in dataList:
data.append(" ".join(jieba.cut(oneline)))
#将得到的词语转换为词频矩阵
freWord = CountVectorizer()
#统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#计算出tf-idf(第一个fit_transform),并将其转换为tf-idf矩阵(第二个fit_transformer)
tfidf = transformer.fit_transform(freWord.fit_transform(data))
#获取词袋模型中的所有词语
word = freWord.get_feature_names()
#得到权重
weight = tfidf.toarray()
tfidfDict = {}
for i in range(len(weight)):
for j in range(len(word)):
getWord = word[j]
getValue = weight[i][j]
if getValue != 0:
if tfidfDict.has_key(getWord):
tfidfDict[getword] += string.atof(getValue)
else:
tfidfDict.update({getWord:getValue})
sorted_tfidf = sorted(tfidfDict.iteritems(),
key = lambda d:d[1],reverse = True)
fw = open('result.txt','w')
for i in sorted_tfidf:
fw.write(i[0] + '\t' + str(i[1]) +'\n')3.1.4TextRank算法中的句子相似性
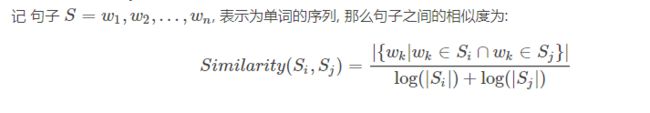
公式中,Si,Sj分别表示两个句子,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的相同词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
代码实现:
def two_sentences_similarity(sents_1, sents_2):
counter = 0
for sent in sents_1:
if sent in sents_2:
counter += 1
sents_similarity=counter/(math.log(len(sents_1))+math.log(len(sents_2)))
return sents_similarity3.2基于深度学习的方法:
3.2.1基于Word2Vec的余弦相似度
首先对句子分词,使用Gensim的Word2Vec训练词向量,获取每个词对应的词向量,然后将所有的词向量相加求平均,得到句子向量,最后计算两个句子向量的余弦值(余弦相似度)。
余弦相似度:用向量空间中的两个向量夹角的余弦值作为衡量两个个体间差异大小的度量,值越接近1,就说明夹角角度越接近0°,也就是两个向量越相似。
计算公式:

#对每个句子的所有词向量取均值,来生成一个句子的vector
#sentence是输入的句子,size是词向量维度,w2v_model是训练好的词向量模型
def build_sentence_vector(sentence,size,w2v_model):
vec=np.zeros(size).reshape((1,size))
count=0
for word in sentence:
try:
vec+=w2v_model[word].reshape((1,size))
count+=1
except KeyError:
continue
if count!=0:
vec/=count
return vec
#计算两个句向量的余弦相似性值
def cosine_similarity(vec1, vec2):
a= np.array(vec1)
b= np.array(vec2)
cos1 = np.sum(a * b)
cos21 = np.sqrt(sum(a ** 2))
cos22 = np.sqrt(sum(b ** 2))
cosine_value = cos1 / float(cos21 * cos22)
return cosine_value
#输入两个句子,计算两个句子的余弦相似性
def compute_cosine_similarity(sents_1, sents_2):
size=300
w2v_model=Word2Vec.load('w2v_model.pkl')
vec1=build_sentence_vector(sents_1,size,w2v_model)
vec2=build_sentence_vector(sents_2,size,w2v_model)
similarity = cosine_similarity(vec1, vec2)
return similarity3.2.1DSSM(Deep Structured Semantic Models)
DSSM(Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层

优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
1. DSSM 是端到端的模型,虽然省去了人工特征转化、特征工程和特征组合,但端到端的模型有个问题就是效果不可控。
2. DSSM 是弱监督模型,因为引擎的点击曝光日志里 Query 和 Title 的语义信息比较弱。
参考文章:
https://blog.csdn.net/Jaygle/article/details/80927732
https://blog.csdn.net/u014665013/article/details/90045408