目标检测-EfficientDet算法介绍
1. 引言
文章:EfficientDet: Scalable and Efficient Object Detection
论文地址:https://arxiv.org/pdf/1911.09070.pdf
近日,谷歌大脑团队发布了论文 EfficientDet: Scalable and Efficient Object Detection ,通过改进 FPN 中多尺度特征融合的结构和借鉴 EfficientNet 模型缩放方法,提出了一种模型可缩放且高效的目标检测算法 EfficientDet。
其高精度版本 EfficientDet-D7 仅有 52M 的参数量和326B FLOPS ,在COCO数据集上实现了目前已公布论文中的最高精度 :51.0 mAP!
相比于之前的最好算法,它的参数量小 4 倍,FLOPS小9.3倍,而精度却更高(+ 0.3 % mAP)!
下面,我们就来一睹为快,这篇文章到底做了什么改进?提出了哪些目标检测研究的新思路?
2. EfficientDet算法总结
Google Brain在EfficientNet的基础上提出了针对于物体检测的可扩展模型架构EfficientDet。全部作者均来自谷歌大脑团队。
下图中陡峭的红色曲线即来自EfficientDet的 7 个模型:
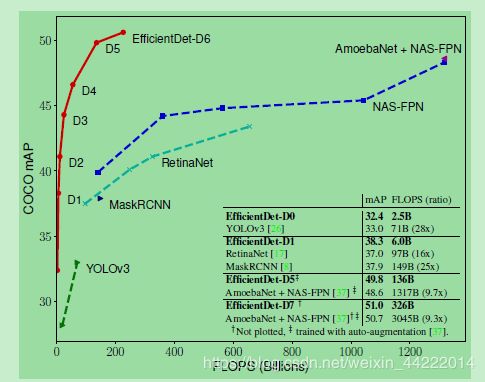
从小模型低计算量模型到高精度SOTA模型,EfficientDet 搜索出来的 8 个模型一路吊打所有之前的知名算法!
2.1 EfficientDet主要贡献
-
新的多尺度特征金字塔 BiFPN(Bi-directional feature pyramid network,在simplified PANet上引入了lateral shortcut)和weighted-BiFPN(在不同scale的特征进行融合时引入注意力机制对不同来源的feature进行权重调整(per-feature / per-channel / pei-pixel),由实验来看带来的性能提升相比BiFPN较小)
-
仿照EfficientNet中的Compound Scaling方法,对检测网络中的各个部分进行Compound Scaling(输入图像大小,backbone的深度、宽度,BiFPN的深度(侧向级联层数),cls/reg head的深度)。(由于检测网络中的变量更多,没有采用grid search,而是基于经验进行实验~)
BiFPN拥有不一样的连接方式,采用加权的方式融合features(feature map级别的attention)。当然是anchor-based的检测,从paper上结果来看确实很亮眼。
在保证更小的#PARAMS`和 #FLOPS的基础上,EfficientDet超越了目前的SOTA方法。使用Compound Scaling可以方便的在不同资源限制下对网络结构进行调整(EfficientDet-D0 ~ EfficientDet-D7)EfficientDet中的对比实验表明:在backbone上,EfficientNet比ResNet,ResNeXt要更优(在ResNet50下降低了params和FLOPs且带来了3.0mAP的提升);在neck上,BiFPN比FPN更优(带来了4.0mAP的提升)。

结果确实令人震撼,但是我对上图的结果存在一点疑惑,PANet加上feature map的加权融合操作,说不定更好。感觉BiFPN就是PANet的剪枝版本(特征融合更高效一点),减少了计算量而已,并没有结构上的优越性(个人看法~)。
2.2 主要改进点
该文一大创新点是改进了FPN中的多尺度特征融合方式,提出了加权双向特征金字塔网络BiFPN。
FPN 引入了一种自顶向下的路径,融合P3~P7的多尺度特征,下图为该文提出的BiFPN与几种FPN 改进的比较:

(b)PANet引入了自底向上的融合路径,(c)NAS-FPN则使用神经架构搜索得到不规则的特征网络拓扑结构,(d)为作者提出的另一种改进,全连接FPN,(e)为作者提出的一种简化FPN,(f)为作者最终在 EfficientDet 使用的BiFPN。
值得指出的是,作者认为FPN中各尺度的特征重要性是不同的,故在BiFPN特征融合的连接中需要加权,而权值是在训练中学习得到的。
(仔细想想其实这是很自然的,不同尺度特征肯定对目标检测贡献大小不同。)
EfficientDet 网络结构:

作者引入了 EfficientNet 中模型缩放的思想,考虑Input size、backbone Network、BiFPN侧向级联层数、Box/class 层深度作为搜索空间,通过统一的系数缩放(具体方法见原论文),得到了以下不同计算量和参数量的8个模型:

目前这些模型还未公布,不过作者称将开源。
2.3 实验结果
作者使用得到的 8 个模型配置,在COCO上训练并测试的结果如下:

AA代表AutoAugmentation。
EfficientDet 在与精度相当的算法相比较时,参数量小 4 到 8 倍,FLOPS小 9.7 到 28 倍,GPU下加速 1.4 到 3.2 倍,CPU下加速 3.4 到 8.1 倍。
而且 EfficientDet-D7 取得了COCO数据集上的精度新高。
与SOTA方法比较,模型Size明显更小:

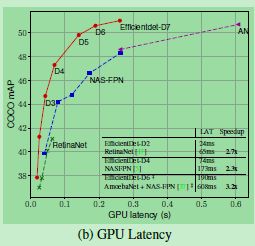
GPU计算延迟比较结果(GPU 为 Titan-V):
个
CPU计算延迟比较结果(单线程的 Xeon CPU):

综上所述,通过改进FPN多尺度融合方法和模型缩放,该文的结果非常吸引人,是最近目标检测领域的新标杆,作者称代码将开源。
3.个人总结
个人总结:我认为其最大的亮点在于提出了目标检测网络联合调整复杂度的策略,从而在COCO上达到51.0 mAP的最优成绩。
其动机源自于谷歌在分类任务的EfficientNet,EfficientDet有如此出色的效果,一部分原因也在于EfficientNet,而EfficientNet的Baselin是通过NAS得到的。第二大亮点在于堆叠FPN,通过堆叠FPN就可以涨几个点,当然BiFPN的设计也是非常有效的,通过增加短接以及学习加权和,能达到很好效果也更符合理解。
感觉这个工作和EfficientNet一样,在工程上很有意义。
由于文章刚出几天,还没细细研究,今天只是简单介绍一下网络,有兴趣的小伙伴可以赶紧入手学习一波~
您的支持,是我不断创作的最大动力~
欢迎点赞,关注,留言交流~
深度学习,乐此不疲~
个人微信公众号,欢迎关注交流学习~
