python3 网络爬虫开发实战(崔庆才著)第二章
2、爬虫基础
2.1 HTTP基本原理
2.1.1 URI URL URN
- URI 全称Uniform Resource Identifier,即统一资源标志符
- URL 全称Uniform Resource Locator ,即统一资源定位符
- URN 全称Uniform Resource Name , 即统一资源名称
URI包含URL和URN
2.1.2 超文本
英文名称:hypertext 。包含有标签的网络源代码
2.1.3 URL的开头会有http或https
- HTTP 全称Hyper Text Transfer Protocol ,中文名超文本传输协议。从网络传输超文本数据到本地浏览器的传送协议,高效、准确。广泛使用的是HTTP1.1版本
- HTTPS 全称Hyper Text Transfer Protocol over Secure Socket Layer,以安全为目标的HTTP通道。是HTTP的安全版。在HTTP下加入SSL层。阐述的内容通过SSL传送。
- 建立信息安全通道来保证数据传输的安全
- 确认网站的真实性,可以通过CA机构颁发的安全签章查询。(12306网站使用的https,其CA证书是由中国铁道部自行签发的。)
2.1.4 HTTP请求过程
们在浏览器中输入一个URL,回车之后便会在浏览器中观察到页面内容。实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来。
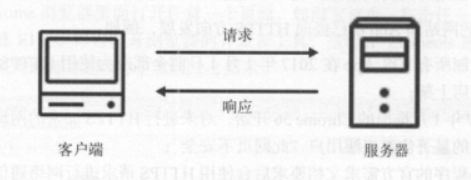
2.1.5 请求
由棵树段向服务端发出,可分为4部分内容:请求方法(Request Method)、请求网址(Request URL)、请求头(Request Headers)、请求体(Request Body)
- 请求方法(Request Method)
| 方法 | 描述 |
|---|---|
| GET | 请求页面,并返回页面内容(请求参数包含在URL里面,提交的数据最多1024字节) |
| HEAD | 类似于GET请求,返回的响应里面没有具体内容,用于获取报头 |
| POST | 大多用于提交表单或上传文件,数据包含在请求体中(不限制上产数据的大小) |
| PUT | 用从客户端向服务器传送的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器当作跳板,让服务器代替客户端访问其他网站 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TEACE | 回显服务器收到的请求,主要用于测试或诊断 |
- 请求网址
即统一资源定位符 URL,可以唯一确定请求的资源 - 请求头
用来说明服务器要是用的附加信息,比较重要的信息有Cookie、Referer、User-Agent等- Accept:请求报头域,用于指客户端可接收那些类型的信息
- Accept-Language:指定客户端可接受的语言类型
- Accept-Encoding:指定客户端可接受的内容编码
- Host:用于指定请求资源的主机IP和端口号,内容为请求URL的原始服务器或网关的位置。从HTTP1.1版本开始,必须包含
- Cookie:网站为了辨别用户进行会话跟踪而存储在用户本地的数据。只要功能是维持当前访问会话。(记住密码)
- Referer:标识请求来源页面,可以做来源统计或防盗链处理等
- User-Agent:简称UA,特殊的字符串头,服务器识别客户使用的操作系统及版本、浏览器等。在做爬虫时加上这些信息可以伪装成浏览器访问。
- Content-Type:也叫互联网媒体类型(Internet Media Type)或者MIME类型。表示媒体类型信息。例如:text、html代表HTML格式,image、gif代表GIF 图片,application、json代表JSON类型。更多参考http://tool.oschina.net/commons。
- 请求体
一般承载的内容是POST请求中的表单数据,而对于GET请求,请求体为空

2.1.6 响应
由服务端返回给客户端,分为三部分:响应状态码(Response Status Code)、响应头(Response Headers),响应体(rESPONSE Body)
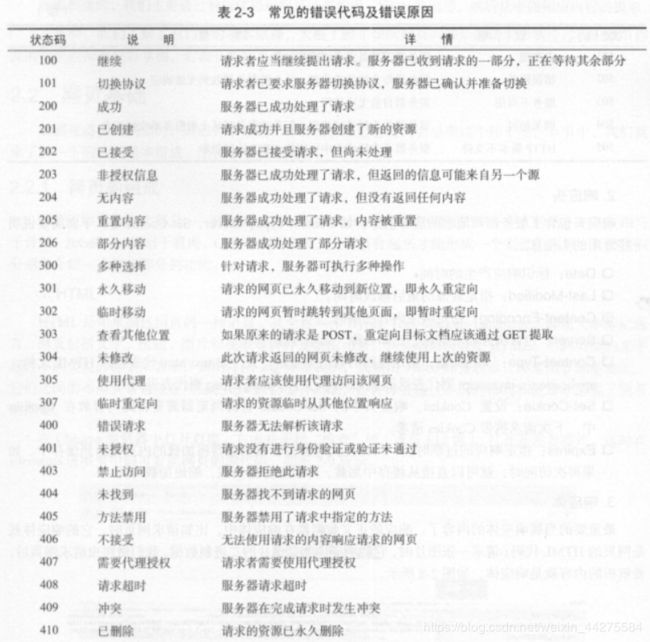
- 响应状态码


- 响应头
包含了服务器对请求的应答信息- Date:响应产生的时间
- Last-Modified:最后的修改时间
- Content-Encoding:相应内容的编码
- Server:服务器的信息,例如:名称、版本号等
- Content-Type:文档类型,指定返回的数据类型
- Set-Cookie:设置Cookie。
- Expires:响应过期的时间。再次访问时可以直接从缓存中加在,降低服务器负载,缩短加载时间
- 响应体
最重要的是内容。响应的正文数据都在响应体中,比如请求网页时,响应体就是网页的HTML代码;请求一张图片时,响应体就是图片的二进制数据。
2.2 网页基础
2.2.1 网页的组成
网页分为三大部分——HTML(骨架)、CSS(皮肤)和JavaScript(肌肉)。
- HTML
用来描述网页的一种语言, 全称是Hyper Text Markup Language,即超文本标记语言。网页包括文字、按钮、图片、视频资料等元素,其基础框架就是HTML。不同类型的文字通过不同的标签表示,如图片用img标签,视屏用video标签,段落用p标签。布局用div标签嵌套组合而成 - CSS
全称:Cascading Style Sheets ,即层叠样式表。“层叠”是指能依据层叠顺序处理多个样式文件。“样式”是指网页中文字大小、颜色、元素间距、排列等格式。目前唯一的网页页面排版样式标准。
后缀为css,用link标签引用 - JaveScript
简称JS,是一种脚本语言。交互动画效果,如下载进度条、提示框。轮播图等。
后缀为js,通过script标签引用
2.2.2 网页的结构
< !DOCTYPE html>
< html>
< head>
< meta charset="UTF-8">
This is a Demo
Hello World
这就是一个最简单的HTML实例,开头用DOCTYPE定义了文档类型,其次最外层是html标签,最后还有对应的结束标签来表示闭合,其内部是head标签和body标签,分别代表网页头和网页体,它们也需要结束标签。head标签内定义了一些页面的置和引用,如:
它指定了网页的编码为UTF-8。title标签则定义了网页的标题,会显示在网页的选项卡中,不会显示在正文中。body标签内则是在网页正文中显示的内容。div标签定义了网页中的区块,它的id是container,这是一个非常常用的属性,且id的内容在网页中是唯一的,我们可以通过它来获取这个区块。然后在此区块内又有一个div标签,它的class为wrapper,这也是一个非常常用的属性,经常与css配合使用来设定样式。然后此区块内部又有一个h2标签,这代表一个二级标题。另外,还有一个p标签,这代表一个段落。在这两者中直接写入相应的内容即可在网页中呈现出来,它们也有各自的class属性。
2.2.3 节点数及节点间的关系
标签定义的内容都是节点,构成一个HTML DOM树。
DOM是W3C(万维网联盟)的标准,英文全称为Document Object Model ,即文档对象模型。定义了访问HTML和XML文档的标准。W3C文档对象模型(DOM)是中立于平台和语言的接口,允许程序和脚本动态地访问和更新文档的内容、结构和样式。
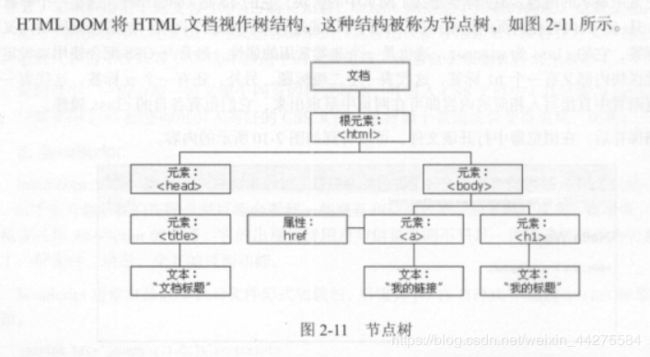
树中的所有节点都可以通过JavaScript访问,节点元素都可被修改、创建或删除。节点彼此间拥有层级关系。通常用父(parent)、子(child)和兄弟(siblig)等术语描述这些关系。
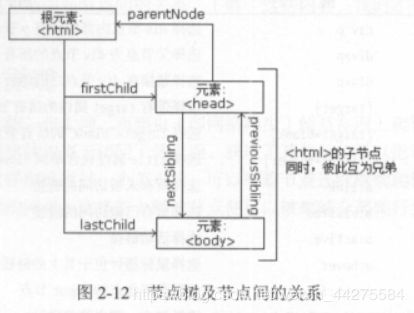
2.2.4 选择器
在css中,使用CSS选择器来定位节点。例如,div节点的id为container,那么就可以表示为#container,其中#开头代表选择id,其后紧跟id的名称。另外,如果想选择class为wrapper的节点,可以使用.wrapper,这里以(.)开头代表选择class,其后几根class的名称。还有一种选择方式。就是根据标签名筛选,例如想选择二级标签,直接用h2即可。
另外,CSS选择器还支持嵌套选择,各个选择器之间加上空格分隔开代表嵌套关系,如#container. wrapper p则代表先选择id为container的节点,然后选中其内部的class为wrapper的节点,然后再进一步选中其内部的p节点。另外,如果不加空格,则代表并列关系,如div#container .wrapper p.text代表先选择id为container的div节点,然后选中其内的clss为container的div节点,然后选中其内部的class为wrapper的节点,再进一步选中其内部的class为text的p节点。


还有一种比较常用的选择器是XPath。
2.3 爬虫的基本原理
把互联网比作一张大网,那么网页就是网的节点。那么爬虫是就像蜘蛛一样的顺着网去打每个地方,抓取各个网站的数据。
2.3.1 爬虫概述
爬虫就是获取网页并提取和保存信息的自动化程序
- 获取网页
也就是获取源代码,因为源代码里有网页的部分有用信息。构造一个请求发送给服务器,然后接收响应并解析。
- 提取信息
分析源代码,从中提取有用信息。
- 采用正则表达式提取
- 根据网页结构规则,如节点属性,CSS选择器、XPath。运用Beautiful Soup 、pyquery、lxml等库
- 保存数据
可以简单的保存为TXT文本或JSON文本,也可以保存到数据库,甚至借助于SFTP进行操作保存至远程服务器。
- 自动化程序
爬虫是用来做爬取工作的自动化程序,进行异常处理、错误重试等操作
2.3.2 怎么抓取数据
最常抓取常的是HTML源码,也可能是JSON字符串、二进制数据(图片、视频、音频)、各种扩展名文件(CSS、JavaScript、配置文件)
2.3.3 JavaScript 渲染页面
有时候,用urllib和ruquests抓取网页的时候,得到的源代码和实际中看到的不一样。因为原网页中用js文件来渲染网站
2.4 会话和Coolies
2.4.1 静态网页和动态网页
- 静态网页
网页的内容是HTML岱庙编写的,文字、图片等内容均通过写好的HTML代码来指定。
有点:加载速度快,编写简单
缺点:可维护性差,不能根据URL灵活多变的显示内容
- 动态网页
可以动态解析URL中参数的变化,关联数据库并动态呈现不同的页面,灵活多变。还可以实现用户登录注册功能。
2.4.2 无状态HTTP
HTTP的无状态是指HTTP协议对事务处理是没有记忆能力的,也就是服务器不知道客户端是什么状态。如果后续要处理前面的信息,则必须重传。
会话和Cookies用于保持HTTP连接状态。会话在服务端,用来保存用户的会话信息;Cookies在客户端,浏览器在下次访问网页时会自动附带上他发送给服务器,服务器通过识别Cookies并鉴定出是哪一个用户,再来判别登录状态。
- 会话
本来含义是指有始有终的一系列动作/消息。在Web中,会话对象用来存储特定用户会话所需的属性及配置信息。如果该用户还没有会话,Web服务器将自动创建一个会话对象。当会话过期或被放弃之后,服务器将终止该对话。
- Cookies
为了辨别用户身份、进行会话跟踪二存储在用户本地终端上的数据。
2.4.3 常见误区
除非程序通知服务器删除一个会话,否则服务器会一直保留。关闭浏览器不会导致会话被删除。
2.5 代理的基本原理
当网站采取反爬虫措施时会看到“您的IP访问频率太高”。
2.5.1 基本原理
代理就是指代理服务器,英文叫做proxy server,其功能为代理网络用户去取得网络信息。即网络信息中转站。
2.5.2 代理的作用
- 突破自身ip访问限制
- 访问一些单位或团体内部资源
- 提高访问速度
- 隐藏真实IP,防止自身IP被封锁
2.5.3 爬虫代理
在爬取的过程中不断更换代理,防止被封锁
2.5.4 代理分类
- 根据协议区分
- FTP代理服务器:主要用于访问FTP服务器,一般有上传、下载以及缓存功能,端口一般为21、2121等
- HTTP代理服务器:主要用于访问网页,一般有 内容过滤和缓存功能,端口一般为80、8080、3128等
- SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持128位加密强度),端口一般为443
- RTSP代理:主要用于访问Real流媒体服务器,一般有缓存功能,端口一般为554
- Telnet代理:主要用于telnet远程控制(黑客入侵计算机室影藏身份)端口一般为23
- POP3/SMTP代理:主要用于POP3/SMTP方式收发邮件,一般有缓存功能,端口一般为110、25
- SOCKS代理:单纯传递数据包,不关心具体协议和用法,速度快,一般有缓存功能,端口一般为1080
- 根据匿名程度区分
- 高度匿名代理:会将数据包原封不动的转发,就像是普通端用户在访问,记录代理服务器的IP
- 普通匿名代理:会在数据包上做一些改动,服务端可能会发现是代理服务器,也有一定几率查到客户端的真实IP。代理服务器通常会加入的HTTP头有HTTP_VIA和HTTP_X_FORWARDED_FOR
- 透明代理:不但改动了数据包,还会告诉服务客户端的真实IP。这种代理除了能缓存技术提高浏览速度,能用内容过滤提高安全性之外,无其他显著作用。最常见的例子就是内网中的硬件防火墙
- 间谍代理:是组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器
2.5.5 常见代理设置
- 使用网上的免费代理:最好使用高匿代理,
- 使用付费代理服务:
- ADSL拨号:拨一次换一次IP,稳定性高