为什么进行选举
因为我们的任务支持分片,分片的逻辑不需要重复执行多次,由于是去中心化设计,所以我们需要通过选举的形式选出一台服务器作为主节点,执行分片逻辑。
zookeeper节点
下面的zookeeper会在选举以及分片中用到,因此提前列出来
| 节点 | 节点类型 | 节点作用 |
|---|---|---|
| /${namespace}/${jobName}/leader/election/latch | 持久 | 用于选举的锁 |
| /${namespace}/${jobName}/leader/election/instance | 临时 | 保存主节点地址 |
| /${namespace}/${jobName}/leader/sharding/necessary | 持久 | 判断是否需要重新分片 |
| /${namespace}/${jobName}/leader/sharding/processing | 临时 | 标记主节点正在sharding 的标志 |
| /${namespace}/${jobName}/sharing/${shardingItem}/instance | 永久 | 保存拿到shardingItem分片的作业实例 |
${...}表示可变的配置
临时节点会在创建节点服务器断开连接时删除
选举
选举的逻辑在LeaderService的electLeader方法。主节点的选举采用先到先得的策略,其他节点会在当前节点选举的时候阻塞。
/**
* 选举主节点.
*/
public void electLeader() {
log.debug("Elect a new leader now.");
jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback());
log.debug("Leader election completed.");
}
LeaderNode.LATCH用于做节点选举
LeaderElectionExecutionCallback回调会在拿到leader锁的节点触发
主节点的选举使用了Curator框架的LeaderLatch类
/**
* 在主节点执行操作.
*
* @param latchNode 分布式锁使用的作业节点名称
* @param callback 执行操作的回调
*/
public void executeInLeader(final String latchNode, final LeaderExecutionCallback callback) {
//注意到这边try语句用法,结束后会自动释放锁
try (LeaderLatch latch = new LeaderLatch(getClient(), jobNodePath.getFullPath(latchNode))) {
latch.start();
//这边会等待锁的释放,也就是callback会执行多次
latch.await();
callback.execute();
//CHECKSTYLE:OFF
} catch (final Exception ex) {
//CHECKSTYLE:ON
handleException(ex);
}
}
但是这里LeaderLatch的用法更多是为了保证有序性,因为拿到leader锁的服务器在执行完之后会释放锁,其他await的节点也会相继拿到leader锁,执行callback逻辑。
callback的具体实现中又使用了乐观锁,判断leaderNode.INSTANCE节点是否被设置,显然,第一个拿到leader锁的服务器已经设置,成为主节点。其他服务器不执行逻辑。
在我的elasticjob-springboot-demo项目中对LeaderLatch进行了测试
@RequiredArgsConstructor
class LeaderElectionExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
//判断eaderNode.INSTANCE是否已经设置,相当于乐观锁
if (!hasLeader()) {
//设置leaderNode.INSTANCE节点的内容为当前服务器
jobNodeStorage.fillEphemeralJobNode(LeaderNode.INSTANCE, JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
}
}
注意Instance节点为临时节点,也就是主节点下线后,这个节点会消失。这个对于触发主节点重新选举有关。
Curator的LeaderLatch的leader和Elastic Job主节点是两个完全不同的概念。LeaderLatch更多了是为了保证只有一个节点能持有某个目录的锁。Elastic Job使用LeaderLatch实现了抢占式选主。
分片
分片的逻辑封装在ShardingService
设置分片状态
在我们Job初始化的时候,会调用setReshardingFlag方法来设置重新分片标记,当job第一次执行的时候,发现重新分片状态存在,那么会先等待主节点分片完成,在获取自己对应的分片执行job逻辑
public void setReshardingFlag() {
jobNodeStorage.createJobNodeIfNeeded(ShardingNode.NECESSARY);
}
分片逻辑
shardingIfNecessary方法封装了分片逻辑
/**
* 如果需要分片且当前节点为主节点, 则作业分片.
*
*
* 如果当前无可用节点则不分片.
*
*/
public void shardingIfNecessary() {
//获取可分片的作业运行实例
List availableJobInstances = instanceService.getAvailableJobInstances();
//判断是否需要进行分片
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
//判断是否是主节点,不是主节点进入if逻辑,同时内部会等待主节点选举完成
if (!leaderService.isLeaderUntilBlock()) {
//等待主节点分片完成
blockUntilShardingCompleted();
return;
}
//等待当前任务的其他分片运行结束
waitingOtherShardingItemCompleted();
LiteJobConfiguration liteJobConfig = configService.load(false);
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
log.debug("Job '{}' sharding begin.", jobName);
//设置分片运行标志
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
//清空之前的sharding节点
resetShardingInfo(shardingTotalCount);
//获取配置的分片策略类,不存在使用默认的AverageAllocationJobShardingStrategy
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
//执行分片逻辑
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
log.debug("Job '{}' sharding complete.", jobName);
}
上述逻辑流程图如下

这个方法会在LiteJobFacade的getShardingContexts中被调用到,用来生成调用上下文,而getShardingContexts会被AbstractElasticJobExecutor的execute调用,excute最终调用到我们配置job的execute方法
因此分片逻辑会在执行job的时候触发,第一次是必定触发,之后触发看重新分片标志是否被重新设置
我们配置的Job是如何执行的,之后会单独讲解
分片策略
下面来看下分片的具体逻辑,从上面可以看到具体分片逻辑由JobShardingStrategy子类实现,先看下它的接口定义
public interface JobShardingStrategy {
/**
* 作业分片.
*
* @param jobInstances 所有参与分片的单元列表
* @param jobName 作业名称
* @param shardingTotalCount 分片总数
* @return 分片结果
*/
Map> sharding(List jobInstances, String jobName, int shardingTotalCount);
}
主要是根据shardingTotalCount和jobInstances进行分片分配
看下提供的默认实现类AverageAllocationJobShardingStrategy
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {
@Override
public Map> sharding(final List jobInstances, final String jobName, final int shardingTotalCount) {
if (jobInstances.isEmpty()) {
return Collections.emptyMap();
}
Map> result = shardingAliquot(jobInstances, shardingTotalCount);
addAliquant(jobInstances, shardingTotalCount, result);
return result;
}
private Map> shardingAliquot(final List shardingUnits, final int shardingTotalCount) {
Map> result = new LinkedHashMap<>(shardingTotalCount, 1);
//分片数/作业实例数,得到每个作业实例最少得到的分片数
int itemCountPerSharding = shardingTotalCount / shardingUnits.size();
int count = 0;
for (JobInstance each : shardingUnits) {
List shardingItems = new ArrayList<>(itemCountPerSharding + 1);
//给每个作业实例分配最少得到的分片数
for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) {
shardingItems.add(i);
}
result.put(each, shardingItems);
count++;
}
return result;
}
private void addAliquant(final List shardingUnits, final int shardingTotalCount, final Map> shardingResults) {
//分片数%作业实例数,得到多余的分片数
int aliquant = shardingTotalCount % shardingUnits.size();
int count = 0;
for (Map.Entry> entry : shardingResults.entrySet()) {
//把多余的分片数,按顺序分给作业服务器
if (count < aliquant) {
entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count);
}
count++;
}
}
}
这个算法的实例如下
* 基于平均分配算法的分片策略.
*
*
* 如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
* 如:
* 1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
* 2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
* 3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
*
至于其他实现类,OdevitySortByNameJobShardingStrategy和RotateServerByNameJobShardingStrategy都是基于AverageAllocationJobShardingStrategy实现的,只不过修改了List
设置分片结果
通过JobShardingStrategy得到分片结果之后,会通过PersistShardingInfoTransactionExecutionCallback将结果持久化到zookeeper
@RequiredArgsConstructor
class PersistShardingInfoTransactionExecutionCallback implements TransactionExecutionCallback {
private final Map> shardingResults;
@Override
public void execute(final CuratorTransactionFinal curatorTransactionFinal) throws Exception {
for (Map.Entry> entry : shardingResults.entrySet()) {
for (int shardingItem : entry.getValue()) {
//设置节点/namespace/jobName/sharding/shardingItem/instance = jobinstanceid(相当于ip)
curatorTransactionFinal.create().forPath(jobNodePath.getFullPath(ShardingNode.getInstanceNode(shardingItem)), entry.getKey().getJobInstanceId().getBytes()).and();
}
}
//清除分片标记
curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.NECESSARY)).and();
//清除分片进行中标记
curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.PROCESSING)).and();
}
}
在/namespace/jobName/sharding下面的子节点会把分片结果保存起来。建立与分片数字对应节点,节点instance的data内容为该分片持有的服务器。
例如
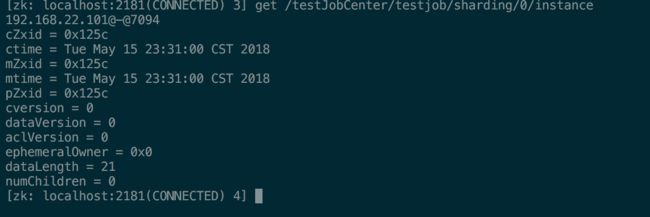
重新选举/分片
在主节点下线的情况下,我们需要重新进行选举或者我们在控制台修改了分片配置需要重新触发分片,这个是如何实现的
基于zookeeper的watch特性,我们可以对zookeeper的节点进行监听,如果节点或者子节点发生了改变,就会触发回调。重新选举/分片就是基于这个实现的
重新选举
主节点重新选举由ElectionListenerManager中的监听器LeaderElectionJobListener实现,关键逻辑如下
class LeaderElectionJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (!JobRegistry.getInstance().isShutdown(jobName) && (isActiveElection(path, data) || isPassiveElection(path, eventType))) {
//触发选举
leaderService.electLeader();
}
}
//判断是否不存在主节点并且本机有效
private boolean isActiveElection(final String path, final String data) {
return !leaderService.hasLeader() && isLocalServerEnabled(path, data);
}
//判断主节点是否down机并且当前主机可用
private boolean isPassiveElection(final String path, final Type eventType) {
return isLeaderCrashed(path, eventType) && serverService.isAvailableServer(JobRegistry.getInstance().getJobInstance(jobName).getIp());
}
//判断当前回调触发的原因是主节点down机了
private boolean isLeaderCrashed(final String path, final Type eventType) {
return leaderNode.isLeaderInstancePath(path) && Type.NODE_REMOVED == eventType;
}
//判断当前服务器对应节点是否可用
private boolean isLocalServerEnabled(final String path, final String data) {
return serverNode.isLocalServerPath(path) && !ServerStatus.DISABLED.name().equals(data);
}
}
这个监听器触发重新选举的条件,首先是当前节点对应job不能停止,其次判断是否当前没有主节点或者当前回调触发的原因就是因为主节点下线。
如果条件满足,就之前讲的一样,通过 leaderService.electLeader()竞争主节点
重新分片标记
设置重新分片标记由ShardingListenerManager的监听器ShardingTotalCountChangedJobListener和ListenServersChangedJobListener执行,主要逻辑是设置重新分片标记。实际的分片操作会在下一次job任务执行前触发,并且由主节点进行分片。
ShardingTotalCountChangedJobListener在分片数配置发生改变时触发
class ShardingTotalCountChangedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
//判断是否是由config节点改变触发,并且当前本地缓存的配置分片大小不为0
if (configNode.isConfigPath(path) && 0 != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {
int newShardingTotalCount = LiteJobConfigurationGsonFactory.fromJson(data).getTypeConfig().getCoreConfig().getShardingTotalCount();
//如果分片大小发生改变
if (newShardingTotalCount != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {
//设置分片标记
shardingService.setReshardingFlag();
//更新本地缓存
JobRegistry.getInstance().setCurrentShardingTotalCount(jobName, newShardingTotalCount);
}
}
}
}
ListenServersChangedJobListener在作业实例发生改变时触发
class ListenServersChangedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
//当前作业节点没有停止的前提下,作业服务器实例或者作业实例发生变化时,设置分片标记
if (!JobRegistry.getInstance().isShutdown(jobName) && (isInstanceChange(eventType, path) || isServerChange(path))) {
shardingService.setReshardingFlag();
}
}
//instance节点发生改变
private boolean isInstanceChange(final Type eventType, final String path) {
return instanceNode.isInstancePath(path) && Type.NODE_UPDATED != eventType;
}
//server节点发生改变
private boolean isServerChange(final String path) {
return serverNode.isServerPath(path);
}
}
我们可以看到,这里不会直接进行分片,而是设置了分片标记,分片操作延迟到任务执行前触发,这其实算一种优化吧,在任务执行前,任务的配置可能会发生多次,每次都执行分片逻辑,并且都需要控制在主节点进行,很浪费性能。这个设计略巧妙。
思考
在想一个问题,如果分片策略是AverageAllocationJobShardingStrategy,我们的应用一般每个job都会配置,那么如果在分片很少的情况下,如果每个job的instance节点顺序一致(zookeeper应该存在默认的排序规则),那么后面的服务器根本轮不到执行任务。所以配置分片策略的时候,不要使用默认的,使用后面2个和hash有关的,或者自己自定义策略。