大数据【企业级360°全方位用户画像】统计型标签开发
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在初次介绍用户画像项目的时候我们谈到过,按照实现方式,标签可以分为匹配型,统计型和挖掘型。之前已经为大家介绍了关于用户画像项目中匹配型标签的开发流程。
具体请见
大数据【企业级360°全方位用户画像】匹配型标签累计开发
本篇博客,我们来谈谈统计型标签的开发~

统计型标签是需要使用聚合函数计算后得到的标签,比如最近3个月的退单率,用户最常用的支付方式等等。
本篇博客,我将通过完整开发一个标签的流程,为大家做详细介绍。
例如我们现在需要开发一个统计型标签,计算用户的客单价。
客单价就是一个客户所有的订单金额/订单数量,简单说就是我们需要统计每个用户每笔订单所花的钱。

现在目标清楚了,我们需要先到web页面,创建对应的四级和五级标签。
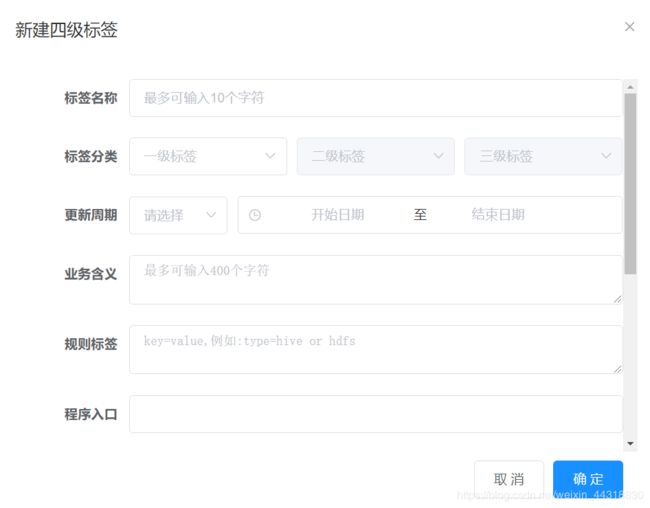
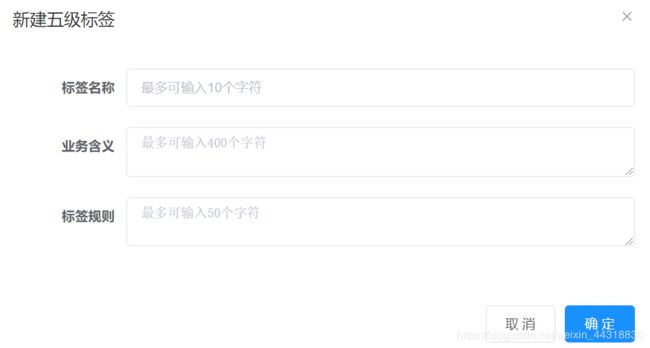
我们可以看到类似的效果

创建完毕之后,我们可以在数据库中看到对应的数据。
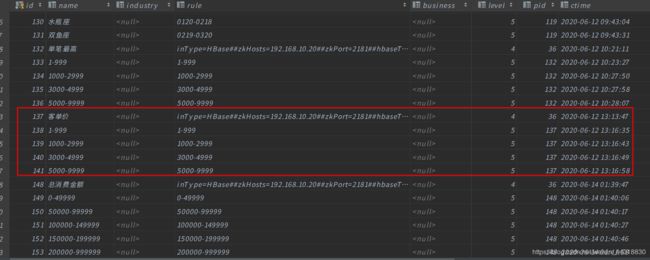
接着我们就要开始写代码了。
首先创建一个object,根据需要开发的标签名字,我们将其命名为:AvgTransactionTag
1、创建SparkSession
因为我们汇总计算需要使用到SparkSQL,所以我们需要先创建SparkSQL的运行环境。
为了方便我们后期运行时查看控制台,我们可以设置一下日志级别。
val spark: SparkSession = SparkSession.builder().appName("AgeTag").master("local[*]").getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
2、连接MySQL
我们这里采用Spark通过jdbc的方式连接MySQL。
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
// 连接MySQL
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
3、读取MySQL数据库四级标签的数据
因为后续可能需要对读取的数据做一些形式上的转换,所以我们这里先引入了隐式转换和SparkSQL的内置函数,然后根据MySQL的连接对象,读取了四级标签的数据,并对其做了一定的处理。
// 引入隐式转换
import spark.implicits._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
//读取MySQL数据库的四级标签
val fourTagsDS: Dataset[Row] = mysqlConn.select("rule").where("id=137")
// 对四级标签数据做处理
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule值
val RuleValue: String = row.getAs("rule").toString
// 使用"##"对数据进行切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
// 将Map 转换成HBaseMeta的样例类
val hbaseMeta: HBaseMeta = toHBaseMeta(KVMap)
因为涉及到了样例类的调用,所以我们也提前写好了样例类。
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse(HBaseMeta.ZKHOSTS,""),
KVMap.getOrElse(HBaseMeta.ZKPORT,""),
KVMap.getOrElse(HBaseMeta.HBASETABLE,""),
KVMap.getOrElse(HBaseMeta.FAMILY,""),
KVMap.getOrElse(HBaseMeta.SELECTFIELDS,""),
KVMap.getOrElse(HBaseMeta.ROWKEY,"")
)
}
4、读取MySQL数据库五级标签的数据
上一步我们已经读取完了四级标签,这一步我们需要读取MySQL中五级标签的数据,也就是标签值的数据。同样,再读取完之后,需要对数据进行处理。因为我们的标签值是一个范围的数据,例如1-999,我们需要将这个范围的开始和结束的数字获取到,然后将其添加为DataFrame的Schema,方便我们后期对其与Hbase数据进行关联查询的时候获取到区间起始数据。
//4. 读取mysql数据库的五级标签
val fiveTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("pid=137")
val fiveTagDF: DataFrame = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
//133 1-999
//134 1000-2999
var start: String = ""
var end: String = ""
val arr: Array[String] = rule.split("-")
if (arr != null && arr.length == 2) {
start = arr(0)
end = arr(1)
}
// 封装
(id, start, end)
}).toDF("id", "start", "end")
fiveTagDF.show()
//+---+-----+----+
//| id|start| end|
//+---+-----+----+
//|138| 1| 999|
//|139| 1000|2999|
//|140| 3000|4999|
//|141| 5000|9999|
//+---+-----+----+
5、读取Hbase中的标签值数据
到了这一步,开始逐渐显得与匹配型标签的操作不一样了。我们在读取完了Hbase中的数据之后,需要展开分析。
因为一个用户可能会有多条数据 ,也就会有多个支付金额。我们需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价。
// 5. 读取hbase中的数据,这里将hbase作为数据源进行读取
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
hbaseDatas.show(5)
//+--------+-----------+
//|memberId|orderAmount|
//+--------+-----------+
//|13823431| 2479.45|
//| 4035167| 2449.00|
//| 4035291| 1099.42|
//| 4035041| 1999.00|
//|13823285| 2488.00|
//+--------+-----------+
// 因为一个用户可能会有多条数据 ,也就会有多个支付金额
// 我们需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价
val userFirst: DataFrame = hbaseDatas.groupBy("memberId").agg(sum("orderAmount").cast("Int").as("sumAmount"),count("orderAmount").as("countAmount"))
userFirst.show(5)
//+---------+---------+-----------+
//| memberId|sumAmount|countAmount|
//+---------+---------+-----------+
//| 4033473| 251930| 142|
//| 13822725| 179298| 116|
//| 13823681| 169746| 108|
//|138230919| 240061| 125|
//| 13823083| 233524| 132|
//+---------+---------+-----------+
// val frame: DataFrame = userFirst.select($"sumAmount" / $"countAmount")
val userAvgAmount: DataFrame = userFirst.select('memberId,('sumAmount / 'countAmount).cast("Int").as("AvgAmount"))
userAvgAmount.show(5)
//+---------+-------------------------+
//| memberId|(sumAmount / countAmount)|
//+---------+-------------------------+
//| 4033473| 1774.1549295774648|
//| 13822725| 1545.6724137931035|
//| 13823681| 1571.7222222222222|
//|138230919| 1920.488|
//| 13823083| 1769.121212121212|
//+---------+-------------------------+
6、数据关联
我们在第四步和第五步中分别对MySQL中的五级标签数据和Hbase中的标签值数据进行了处理。在第六步中,我们理应对其进行关联。因为客单价的标签值时一个范围的数据,所以我们这里使用到了Between,想要获取到区间范围的起始值只需要用五级标签返回的DataFrame对象fiveTagDF.col的形式即可获取到,是不是很方便呢?
// 将 Hbase的数据与 五级标签的数据进行 关联
val dataJoin: DataFrame = userAvgAmount.join(fiveTagDF, userAvgAmount.col("AvgAmount")
.between(fiveTagDF.col("start"), fiveTagDF.col("end")))
dataJoin.show()
// 选出我们最终需要的字段,返回需要和Hbase中旧数据合并的新数据
val AvgTransactionNewTags: DataFrame = dataJoin.select('memberId.as("userId"),'id.as("tagsId"))
AvgTransactionNewTags.show(5)
7、解决数据覆盖的问题
在获取到了新数据之后,我们需要将Hbase结果表中的“旧数据”读取出来,然后,与之进行合并。所以我们需要定义一个udf,用于解决标签值重复或者数据合并的问题。
/* 定义一个udf,用于处理旧数据和新数据中的数据合并的问题 */
val getAllTages: UserDefinedFunction = udf((genderOldDatas: String, jobNewTags: String) => {
if (genderOldDatas == "") {
jobNewTags
} else if (jobNewTags == "") {
genderOldDatas
} else if (genderOldDatas == "" && jobNewTags == "") {
""
} else {
val alltages: String = genderOldDatas + "," + jobNewTags //可能会出现 83,94,94
// 对重复数据去重
alltages.split(",").distinct // 83 94
// 使用逗号分隔,返回字符串类型
.mkString(",") // 83,84
}
})
// 读取hbase中的历史数据
val genderOldDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts","192.168.10.20")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.load()
// 新表和旧表进行join
val joinTags: DataFrame = genderOldDatas.join(AvgTransactionNewTags, genderOldDatas("userId") === AvgTransactionNewTags("userId"))
joinTags.show()
val allTags: DataFrame = joinTags.select(
// 处理第一个字段
when((genderOldDatas.col("userId").isNotNull), (genderOldDatas.col("userId")))
.when((AvgTransactionNewTags.col("userId").isNotNull), (AvgTransactionNewTags.col("userId")))
.as("userId"),
getAllTages(genderOldDatas.col("tagsId"), AvgTransactionNewTags.col("tagsId")).as("tagsId")
)
// 新数据与旧数据汇总之后的数据
allTags.show(10)
8、数据写入
我们在合并完了数据之后,最后将其写入到Hbase中即可。
// 将最终结果进行覆盖
allTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.option("repartition",1)
.save()
完整代码
import java.util.Properties
import com.czxy.bean.HBaseMeta
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/*
* @Author: Alice菌
* @Date: 2020/6/12 21:10
* @Description:
*
* 基于用户的客单价统计标签分析
*/
object AvgTransactionTag {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("AgeTag").master("local[*]").getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
// 连接MySQL
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
// 引入隐式转换
import spark.implicits._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
// 读取MySQL数据库的四级标签
val fourTagsDS: Dataset[Row] = mysqlConn.select("rule").where("id=137")
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule值
val RuleValue: String = row.getAs("rule").toString
// 使用"##"对数据进行切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
println(KVMap)
// 将Map 转换成HBaseMeta的样例类
val hbaseMeta: HBaseMeta = toHBaseMeta(KVMap)
//4. 读取mysql数据库的五级标签
val fiveTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("pid=137")
val fiveTagDF: DataFrame = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
//133 1-999
//134 1000-2999
var start: String = ""
var end: String = ""
val arr: Array[String] = rule.split("-")
if (arr != null && arr.length == 2) {
start = arr(0)
end = arr(1)
}
// 封装
(id, start, end)
}).toDF("id", "start", "end")
fiveTagDF.show()
//+---+-----+----+
//| id|start| end|
//+---+-----+----+
//|138| 1| 999|
//|139| 1000|2999|
//|140| 3000|4999|
//|141| 5000|9999|
//+---+-----+----+
// 5. 读取hbase中的数据,这里将hbase作为数据源进行读取
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
hbaseDatas.show(5)
//+--------+-----------+
//|memberId|orderAmount|
//+--------+-----------+
//|13823431| 2479.45|
//| 4035167| 2449.00|
//| 4035291| 1099.42|
//| 4035041| 1999.00|
//|13823285| 2488.00|
//+--------+-----------+
// 因为一个用户可能会有多条数据 ,也就会有多个支付金额
// 我们需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价
val userFirst: DataFrame = hbaseDatas.groupBy("memberId").agg(sum("orderAmount").cast("Int").as("sumAmount"),count("orderAmount").as("countAmount"))
userFirst.show(5)
//+---------+---------+-----------+
//| memberId|sumAmount|countAmount|
//+---------+---------+-----------+
//| 4033473| 251930| 142|
//| 13822725| 179298| 116|
//| 13823681| 169746| 108|
//|138230919| 240061| 125|
//| 13823083| 233524| 132|
//+---------+---------+-----------+
// val frame: DataFrame = userFirst.select($"sumAmount" / $"countAmount")
val userAvgAmount: DataFrame = userFirst.select('memberId,('sumAmount / 'countAmount).cast("Int").as("AvgAmount"))
userAvgAmount.show(5)
//+---------+-------------------------+
//| memberId|(sumAmount / countAmount)|
//+---------+-------------------------+
//| 4033473| 1774.1549295774648|
//| 13822725| 1545.6724137931035|
//| 13823681| 1571.7222222222222|
//|138230919| 1920.488|
//| 13823083| 1769.121212121212|
//+---------+-------------------------+
// 将 Hbase的数据与 五级标签的数据进行 关联
val dataJoin: DataFrame = userAvgAmount.join(fiveTagDF, userAvgAmount.col("AvgAmount")
.between(fiveTagDF.col("start"), fiveTagDF.col("end")))
dataJoin.show()
println("---------------------------------------------")
// 选出我们最终需要的字段,返回需要和Hbase中旧数据合并的新数据
val AvgTransactionNewTags: DataFrame = dataJoin.select('memberId.as("userId"),'id.as("tagsId"))
AvgTransactionNewTags.show(5)
// 7、解决数据覆盖的问题
// 读取test,追加标签后覆盖写入
// 标签去重
/* 定义一个udf,用于处理旧数据和新数据中的数据合并的问题 */
val getAllTages: UserDefinedFunction = udf((genderOldDatas: String, jobNewTags: String) => {
if (genderOldDatas == "") {
jobNewTags
} else if (jobNewTags == "") {
genderOldDatas
} else if (genderOldDatas == "" && jobNewTags == "") {
""
} else {
val alltages: String = genderOldDatas + "," + jobNewTags //可能会出现 83,94,94
// 对重复数据去重
alltages.split(",").distinct // 83 94
// 使用逗号分隔,返回字符串类型
.mkString(",") // 83,84
}
})
// 读取hbase中的历史数据
val genderOldDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts","192.168.10.20")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.load()
// 新表和旧表进行join
val joinTags: DataFrame = genderOldDatas.join(AvgTransactionNewTags, genderOldDatas("userId") === AvgTransactionNewTags("userId"))
joinTags.show()
val allTags: DataFrame = joinTags.select(
// 处理第一个字段
when((genderOldDatas.col("userId").isNotNull), (genderOldDatas.col("userId")))
.when((AvgTransactionNewTags.col("userId").isNotNull), (AvgTransactionNewTags.col("userId")))
.as("userId"),
getAllTages(genderOldDatas.col("tagsId"), AvgTransactionNewTags.col("tagsId")).as("tagsId")
)
// 新数据与旧数据汇总之后的数据
allTags.show(10)
// 将最终结果进行覆盖
allTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.option("repartition",1)
.save()
}
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse(HBaseMeta.ZKHOSTS,""),
KVMap.getOrElse(HBaseMeta.ZKPORT,""),
KVMap.getOrElse(HBaseMeta.HBASETABLE,""),
KVMap.getOrElse(HBaseMeta.FAMILY,""),
KVMap.getOrElse(HBaseMeta.SELECTFIELDS,""),
KVMap.getOrElse(HBaseMeta.ROWKEY,"")
)
}
}
小结
本篇博客,博主主要为大家带来了如何对统计型标签进行开发的一个小Demo。其实关于统计型标签的开发还有很多,它们会随着不同的业务,有着不同的开发流程,例如求取用户的常用支付方式,最近登录时间等等…这里就不一一叙述了。
大家可能发现了,最近几篇讲解标签开发的博客代码都有大量的相似之处,那么我们能不能将其抽取一下,优化一下代码的开发呢?下一篇博客,让菌哥来告诉你答案!
![]()
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
