苏宁易购书城爬虫(重点:价格请求的url的构造分析)【Scrapy+Mongodb】
下载方式提供两种:
- github下载
- 腾讯微云下载【密码:54250p】
苏宁易购书城爬虫抓取的内容
- 图书价格
- 图书标题
- 图书购买详情页链接
- 图书分类
- 图书作者
- 图书出版社以及出版日期
直接切入正题,重点是图书价格的构造,所以,开始就先解决图书价格请求的url构造:
这里先列一下本文里分析的页面有哪几个(如下):
(1)初始分析页面【图书类别分类页】
(2)图书目录页面【这里拿其中的”小说---->魔幻“类来分析】
(3)图书详情页【图书购买详情页】
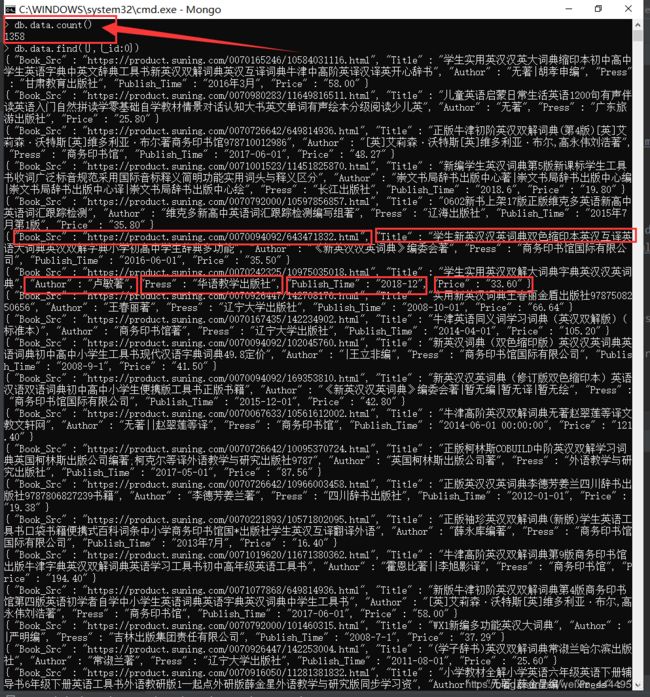
首先,从图书目录页面这个页面来看,价格在这里,如下图所示,价格的获取并容易,首先是和其他信息都不一样,其他信息都可以从图书目录页面来直接提取,然而价格这个数据,是请求另外的url生成的。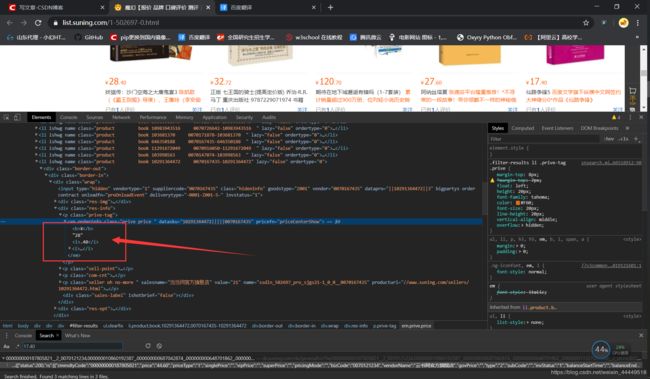
得出结论以后,开始寻找请求的urll在哪,如下图所示,全局搜索确实找到了,但是这好像贼难断定价格到底是怎么个构造法,并且这个url返回的json数据竟然是5条,每条对应一个价格,并且页面中各商品价格的存放也没有一点规律。有一说一,如果开始的时候从这个页面直接分析价格怎么构造出来的,那可就真的瞎了

结论,不能直接从[图书目录页面]这个页面分析价格请求的url是什么构造。还有一个地方也请求了图书的价格的信息,就是图书的详情页,每个详情页图书价格返回肯定是唯一的,首先是好判断,其次是,很有可能分析出url什么构造方法。故,接着分析,如下图所示,找到了请求的url,并且也锁定了数据在什么位置。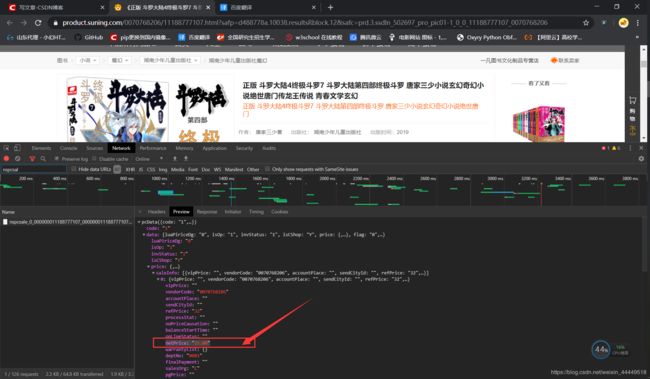
那么,就来看看请求图书价格的url长什么样:
长这样----->贼猥琐:![]()
首先,据经验来看,后面的callback=pcData&_=1581214174334直接删掉,没什么用。好了,下图所示,删掉了,那么剩下的又是什么呢?![]()
这里,看了一下刚刚请求的图书的详情页的url地址,里面就有几和这个url中一样的参数,如下图所示
到这一步为止,就剩下如下图所示的参数未知了![]()
这里首先的想法是,这些参数没用,可以去掉,不影响返回值。
实验验证,这些参数有一些是有用的,一些是可以直接删掉不影响返回结果的。这里就不细说了,可以自己去尝试,下图所示,是得到的最简的请求价格信息的url,并且得到,_120_534这个参数是恒保持不变的
至此,分析差不多就结束了,你可以通过正则,在图书详情页的url中匹配出价格的url的前三个参数,然后加上_120_534这个参数就是最简的价格url。
可是,这里我没用这种方法来做,我发现在图书目录页面每个图书都有一个如下图所示的参数,我直接从这个参数中提取的数据
至此,价格的url提取就分析完了。总结价格的url就是:
https://pas.suning.com/nspcsale_0_0000000 + (prdid) + _ + 0000000 + (prdid) + _ + (shopid) + _120_534.html?

另外,整个项目仅完成了一小部分,还有一些相对比较麻烦的提取,比如说,图书的分类提取,每个图书都有一个大分类,大分类下面有细一点的分类,然后下面还有更细的分类,最后才是图书目录。这里就直接放上我的代码了,分析不是多么困难,就是比较麻烦而已:
tushu.py
# -*- coding: utf-8 -*-
import scrapy
import time
import re
from suningtushu.items import SuningtushuItem
count = 0
class TushuSpider(scrapy.Spider):
name = 'tushu'
allowed_domains = ['suning.com']
start_urls = ['http://book.suning.com']
def parse(self, response):
list = response.xpath("//div[@class='menu-list']")
div_list = list.xpath("./div[@class='menu-item']")
'''把大分类放到列表中'''
liname_list = []
for div in div_list:
liname_list.append(div.xpath("./dl/dt/h3/a/text()").extract_first())
'''打印对应的分类目录'''
print("\n一级分类:", end=" ")
for index in range(len(liname_list)):
print("【{}】{}".format(index, liname_list[index]), end=" ")
'''获取待爬取的目录的索引值【需要判断是否为数字】'''
li_index = int(input("\n\n请输入待抓取的图书前面'【】'中对应的序号:\n"))
div00 = list.xpath("./div[@class='menu-sub']")[li_index]
p_list = div00.xpath("./div[1]/p")
if p_list != []:
'''把待爬取的p标签对应的里面的文本放到 p_data_list 中'''
p_data_list = []
for p in p_list:
p_data_list.append(p.xpath("./a/text()").extract_first())
'''列出待爬取的p标签的小题目'''
print("\n二级分类({}):".format(liname_list[li_index]), end=" ")
for p_index in range(len(p_data_list)):
print("【{}】{}".format(p_index, p_data_list[p_index]), end=" ")
'''输入待爬取的二级目录索引值【需要验证是否输入数字】'''
print("\n\n请输入待抓取的二级目录 {}种类 的图书前面'【】'中对应的序号:\r".format(liname_list[li_index]))
pi_index = int(input())
'''获取备爬取的二级目录对应索引的图书'''
ul_list = div00.xpath("./div[1]/ul")
ul_li_list = ul_list[pi_index].xpath("./li")
'''遍历li,取出对应的链接以及名字,存到字典里'''
ul_li_dict_list = []
for li in ul_li_list:
li_dict = {}
li_dict['name'] = li.xpath("./a/text()").extract_first()
li_dict['href'] = li.xpath("./a/@href").extract_first()
ul_li_dict_list.append(li_dict)
'''取得列表中的字典,输出三级目录'''
print("\n三级分类({}):".format(p_data_list[pi_index]), end=" ")
for ul_li_dict_index in range(len(ul_li_dict_list)):
print("【{}】{}".format(ul_li_dict_index, ul_li_dict_list[ul_li_dict_index]['name']), end=" ")
'''输入三级目录待抓取的图书的分类的索引【需要验证是否输入数字】'''
print("\n\n请输入待抓取的三级目录 {}种类 的图书前面'【】'中对应的序号:\r".format(p_data_list[pi_index]))
ul_index = int(input())
'''Xpath效率来说比不上正则,但是稳定,所以这个事吧,我一部分用的正则,一部分用的xpath'''
'''输入完以后,需要取出对应的字典中的href,进行初始页面的请求'''
data_href = ul_li_dict_list[ul_index]['href']
# https://list.suning.com/1-502314-0.html
'''下一页根据'''
data = re.findall(r"https://list.suning.com/1-(.*)-0.html", data_href)[0]
'''请求一级图书页面'''
yield scrapy.Request(
data_href,
callback=self.seconed_html_request,
meta={"data": data}
)
else:
'''获取备爬取的二级目录对应索引的图书'''
ul_list = div00.xpath("./div[1]/ul")
ul_li_list = ul_list.xpath("./li")
# print(ul_li_list)
'''遍历li,取出对应的链接以及名字,存到字典里'''
ul_li_dict_list = []
for li in ul_li_list:
li_dict = {}
li_dict['name'] = li.xpath("./a/text()").extract_first()
li_dict['href'] = li.xpath("./a/@href").extract_first()
ul_li_dict_list.append(li_dict)
# print(ul_li_dict_list)
'''取得列表中的字典,输出图书种类目录'''
for ul_li_dict_index in range(len(ul_li_dict_list)):
print("【{}】{}".format(ul_li_dict_index, ul_li_dict_list[ul_li_dict_index]['name']), end=" ")
'''输入三级目录待抓取的图书的分类的索引【需要验证是否输入数字】'''
print("\n\n请输入待抓取的图书种类前面'【】'中对应的序号:\r")
ul_index = int(input())
'''Xpath效率来说比不上正则,但是稳定,所以这个事吧,我一部分用的正则,一部分用的xpath'''
'''输入完以后,需要取出对应的字典中的href,进行初始页面的请求'''
data_href = ul_li_dict_list[ul_index]['href']
# https://list.suning.com/1-502314-0.html
'''下一页根据'''
data = re.findall(r"https://list.suning.com/1-(.*)-0.html", data_href)[0]
'''请求一级图书页面'''
yield scrapy.Request(
data_href,
callback=self.seconed_html_request,
meta={"data": data}
)
def seconed_html_request(self, response):
li_list = response.xpath("//ul[@class='clearfix']/li")
'''list_al内部存放的有 每个图书的 'prdid','shopid' 以及图书不完整的url地址'''
list_all = []
for li in li_list:
'''匹配图书的url以及图书价格url的重要参数'''
li_list = li.xpath(".//*").re(
'''sa-data="{'eletp':'prd','prdid':'(.*?)','shopid':'(.*?)'.*?href="(.*?)" name''')[
0:3]
'''提取的过程中,拿着 'prdid','shopid' 以及图书不完整的url地址去请求第三个页面,取得所有数据'''
url = "https:" + li_list[-1]
yield scrapy.Request(
url,
callback=self.third_html_request,
meta={"data": li_list}
)
list_all.append(li_list)
# print(len(list_all))
'''下一页请求'''
res = re.findall('''title="(下一页)"''', response.text)[0]
if res == '下一页':
global count
count = count + 1
nex_url = "https://list.suning.com/1-" + response.meta['data'] + "-{}".format(
count) + "-0-0-0-0-14-0-4.html"
print(nex_url)
yield scrapy.Request(
nex_url,
callback=self.seconed_html_request,
meta={"data": response.meta['data']}
)
def third_html_request(self, response):
'''第三页进行数据的提取以及存放'''
li_list = response.meta["data"]
item = SuningtushuItem()
'''Book_Src提取'''
item['Book_Src'] = response.url
item['Title'] = response.xpath("//h1/text()").extract()[1]
rbq_list = response.xpath("//ul[@class='bk-publish clearfix']/li")
'''修补的bug'''
count = len(rbq_list)
try:
if count > 0:
'''作者'''
item['Author'] = rbq_list[0].xpath('./text()').extract_first()
if count > 1:
'''出版社'''
item['Press'] = rbq_list[1].xpath('./text()').extract_first()
if count > 2:
'''出版日期'''
item['Publish_Time'] = rbq_list[2].xpath('./span[2]/text()').extract_first()
except:
item['Author'] = " "
item['Press'] = " "
item['Publish_Time'] = " "
print("异常图书。。。。。。。")
# print(item)
'''构造价格请求的url'''
url = "https://pas.suning.com/nspcsale_0_0000000" + li_list[0] + "_0000000" + li_list[0] + "_" + li_list[
1] + "_120_534.html?"
# print(url)
yield scrapy.Request(
url,
callback=self.Fourth_html_request,
meta={"item": item}
)
def Fourth_html_request(self, response):
item = response.meta['item']
'''进行图书价格的提取'''
text = response.text
'''原谅我,对速度无能为力了,本来价格这个获取的时候解析主机就很慢的'''
item['Price'] = re.findall('''"netPrice":"(.*?)"''', text)[0]
yield item
这里,是爬虫文件。对于有些书籍,作者信息以及出版社,出版日期存放的位置有点迷,因为无法判断它是什么结构,有的图书有作者信息,有的没有,有的图书详情页还把信息放到了旮旯里,确实,对于作者 / 出版社 / 出版日期这个地方仅有的几本书作者以及出版信息的bug,我采取了直接将作者 / 出版社 / 出版日期置为空串来解决。所以,原谅我确实没花太多的精力去解决这个缺陷。
pipeline.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from pymongo import MongoClient
import re
class SuningtushuPipeline(object):
def open_spider(self, spider):
print("Mongodb is establishing a connection....................")
client = MongoClient()
self.connect = client['suning']['data']
print("===================================================================================")
print("\n---------Name of the project: 苏宁易购图书爬虫--------------------- ||\n")
print("---------author: Caiden_Micheal ||")
print("---------GitHub address: https://github.com/Meterprete?tab=repositories ||")
print("---------Personal mailbox: [email protected] ||")
print("---------time: 2020.2.7 ||\n")
print("===================================================================================")
def process_item(self, item, spider):
self.data_clear(item)
m = self.connect.insert(dict(item))
print(m)
return item
def data_clear(self, contant):
'''简单的数据清晰'''
re_compile = re.compile("\s|\r|\n|\t")
try:
contant['Author'] = re_compile.sub("", contant['Author'])
contant['Press'] = re_compile.sub("", contant['Press'])
except Exception as e:
print(e)
contant['Title'] = re_compile.sub("", contant['Title'])
return contant
整个项目就这样结束了,我们来看一下运行截图:
初始化程序时的截图
这里如果你想把它改成无输入抓取所有分类的这样的一个爬虫程序也比较好实现,只需要循环列表提取分类信息就行,这里在程序中是可修改的。
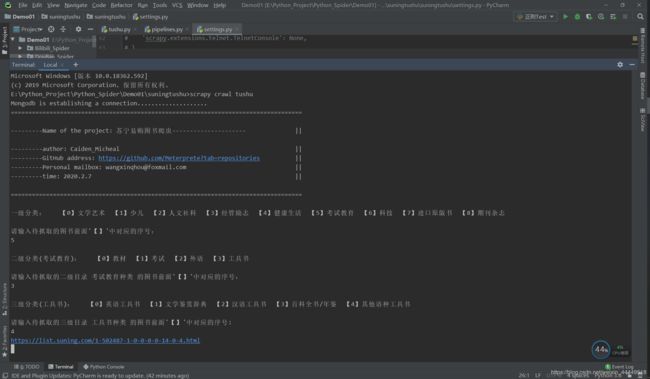
下面是运行过程中打印出来的下一页的url以及数据保存到Mongodb以后返回的信息:
我们去Mongodb中看一看数据抓取情况,这里就让它抓了1358条数据就强制停止了程序,基本上每秒钟提取一二十条数据的样子,没做具体的统计,速度还是挺快的,这里唯一的不满就是苏宁价格url返回速度确实有点慢,这个和人家服务器有关,咱也没办法,不过Scrapy此时的异步网络框架就有了施展才华的地方了,令插一句你炸了 数据提取挺纯净的。