python爬取2019国庆热门景点1——数据爬取与保存
据文化和旅游部综合测算,2019年国庆7天全国共接待国内游客7.82亿人次,同比增长7.81%,今年真的太疯狂了。不知道回城搬砖的伙伴们国庆假期过的如何,哈哈哈题外话,想知道这个国庆哪些景点便宜又好玩吗?可以给明年的行程提前了。
本文主要介绍数据的获取,以去哪儿网为例,打开去哪儿网首页,点击门票,搜索关键字“国庆”,网址url=https://piao.qunar.com/ticket/list.htm?keyword=%E5%9B%BD%E5%BA%86®ion=&from=mps_search_suggest%24page&page=,如下图

现在右击该页面,打开源代码,这里说一下,用谷歌浏览器和普通IE浏览器打开时,右击出现的页面不同,我比较喜欢源代码,所以利用谷歌浏览器打开的,如下图

1.导入包(这些包之后会用过,实际中根据需要添加)
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import os
import random
2.爬取每个页面的信息
我们以第一页为例,爬取景点名称、地区、评分、星级、简介、票价、销量这些信息,观察源代码需要寻找每个属性对应的标签,从标签下获取,就跟剥洋葱一样,一层一层向内找,找最近的。
#爬取每个页面的信息
def pagespider(url):
content=requests.get(url)
content=content.text
soup=BeautifulSoup(content,"html.parser")
#找div和attrs下的所有记录,每条记录相当于一个列表
soup=soup.find_all("div",attrs={"class":"sight_item"})
name = []
star = []
month_sales = []
price = []
info = []
district=[]
hotsum=[]
data = {}
#在每一个列表下再去寻找对应标签
for lst in soup:
#加上if是为了防止出现空值报错,下面也一样
if lst.find("span","hot_num"):
month_sales.append(lst.find("span","hot_num").text)
else:
month_sales.append("暂无")
if lst.find("span",class_="level"):
star.append(lst.find("span",class_="level").text)
else:
star.append("暂无")
if lst.find("span",class_="sight_item_price"):
price.append((lst.find("span",class_="sight_item_price").find("em")).text)
else:
price.append("暂无")
if lst.find("span",class_="product_star_level"):
hotsum.append(lst.find("span",class_="product_star_level").text)
name.append(lst.find("h3",class_="sight_item_caption").find(target="_blank",hidefocus="true").text)
info.append(lst.find("div",class_="intro color999").text)
district.append(lst.find("span", class_="area").find(target="_blank", hidefocus="true").text)
#将数据都存为字典
data["name"]=name
data["star"]=star
data["info"]=info
data["price"]=price
data["month_sales"]=month_sales
data["district"]=district
data["hotsum"] = hotsum
return data
3.保存为excel文件
保存数据的时候真的费了好大劲,因为要保存为excel,但是不想使用专门的xlwt包,我还不熟悉,所以百度到pandas自带的保存为excel文件的方法。虽然方法找到了,但是过程出了很多问题:
问题:我找到的代码df=df.append(place_list)这行中没有设置ignore_index=True,所以出现错误

百度说可以设置一下ignore_index=True解决,可是我试过df=df.append(place_list,ignore_index=True)之后,保存的文件是这样,第一页正常,之后的就有问题了,请教之后,想了很久,发现问题出在append了,因为每一页的数据保存之后都是一个表格,但是我现在需要将几个表进行合并,但是由于数据格式问题,直接append有问题,将数据转成.DataFrame之后就正常了。
#保存为excel文件
place_path="qunar.xlsx"
def save_excel(place_list):
if os.path.exists(place_path):
df=pd.read_excel(place_path)
df=df.append(pd.DataFrame(place_list),ignore_index=True)
else:
df=pd.DataFrame(place_list)
writer=pd.ExcelWriter(place_path)
df.to_excel(excel_writer=writer,columns=["name","district","hotsum","star","info","price","month_sales"],index=False,
encoding="utf-8",sheet_name="去哪儿国庆热门景点")
writer.save()
writer.close()
4.爬取所有页面信息
我们知道,之前只是爬取了第1页的信息,我们可以点一下第2页第3页,发现网址唯一的不同就是最后的page值,所以通过for循环可以批量爬取所有页面信息。
def spider(keyword):
if os.path.exists(place_path):
os.remove(place_path)
url="https://piao.qunar.com/ticket/list.htm?keyword=%E5%9B%BD%E5%BA%86®ion=&from=mps_search_suggest%24page&page="
for i in range(3):
i=i+1
print(f'正在爬取 {keyword} 第{i}页')
nurl=url+str(i)
place_list=pagespider(nurl)
save_excel(place_list)
time.sleep(random.randint(2,5))
print("爬取完成")
spider("2019国庆热门景点")
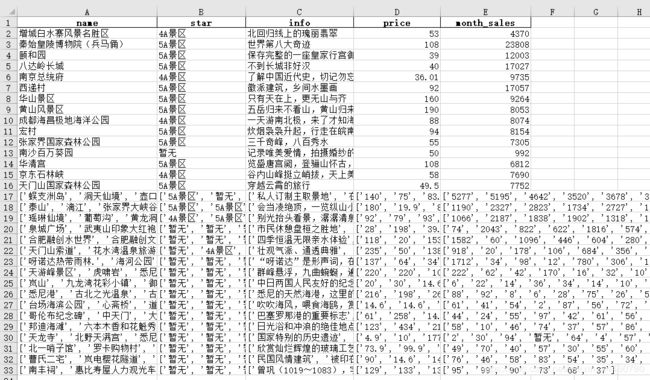
运行之后,打开qunar.xlsx文件,下面是截图:(因为热点信息一直在变,所以截图可能有部分变化,但是方法是这样的)

终于整理完了,主要为了记忆,以后可以翻翻自己的笔记,之后我会抽空更新一下相关数据分析,来寻找比性价比高的景点。