python实战:将cookies添加到requests.session中实现淘宝的模拟登录
声明:本文仅供学习用,旨在分享
我们知道现在爬取淘宝商品是必须要登录的,在没有登录的情况下搜索商品也会自动重定向到登录页面。之前学着用selenium,pyppeteer等自动化框架模拟登录淘宝,但是无论怎么滑动滑块验证都失败。然而就像星爷《新喜剧之王》中所说得:只要不投降就是成功,同时为了安慰自己受伤的小心灵,决定用cookies来模拟登陆,思路是先通过浏览器登录成功后获取cookies手动存到文本来,然后通过代码实现后续cookies自动更新。当然一开始只用requests还是gg了,后来想到requests.session,经过不懈努力终于看到了曙光。
**1、**首先我们要先清空有关淘宝的cookies,然后来到登陆页面页面后打开chrome的开发者工具,按下图进行操作:
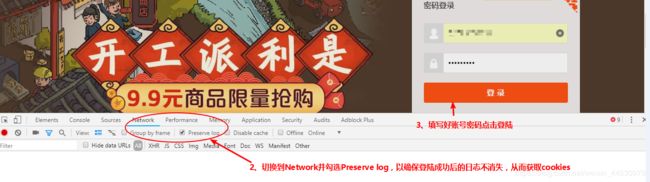
此时我们登陆成功后就会跳转到淘宝网主页,然后找到发送post请求的URL,见下图操作:
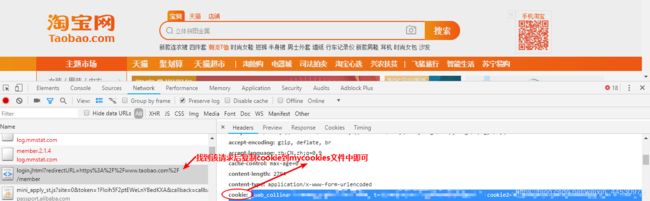
**2、**新建一个叫做mycookies.txt文件将上图的cookie直接复制进去,确保该文件和我们模拟登录的login.py文件在同一目录,然后我们开始敲代码:
import requests
import random
#用于设计随机UA
def set_user_agent():
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
user_agent = random.choice(USER_AGENTS)
return user_agent
class TaoBao:
def __init__(self):
#test_url是我们实际登陆后才能看到的内容,为了确保模拟成功在此用它进行测试
self.test_url='https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20190221&ie=utf8'
self.headers={"Origin":"https://login.taobao.com",
"Upgrade-Insecure-Requests":"1",
"Content-Type":"application/x-www-form-urlencoded",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer":"https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fwww.taobao.com%2F",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"User-Agent":set_user_agent()}
self.cookies = {} # 申明一个字典用于存储手动复制的cookies
self.res_cookies_txt = "" # 申明刚开始浏览器返回的cookies为空字符串
#读取mycookies.txt中的cookies
def read_cookies(self):
with open("mycookies.txt",'r',encoding='utf-8') as f:
cookies_txt = f.read().strip(';') #读取文本内容
#由于requests只保持 cookiejar 类型的cookie,而我们手动复制的cookie是字符串需先将其转为dict类型后利用requests.utils.cookiejar_from_dict转为cookiejar 类型
#手动复制的cookie是字符串转为字典:
for cookie in cookies_txt.split(';'):
name,value=cookie.strip().split('=',1) #用=号分割,分割1次
self.cookies[name]=value #为字典cookies添加内容
#将字典转为CookieJar:
cookiesJar = requests.utils.cookiejar_from_dict(self.cookies, cookiejar=None,overwrite=True)
return cookiesJar
#保存模拟登陆成功后从服务器返回的cookies,通过对比可以发现是有所不同的
def set_cookies(self,cookies):
# 将CookieJar转为字典:
res_cookies_dic = requests.utils.dict_from_cookiejar(cookies)
#将新的cookies信息更新到手动cookies字典
for i in res_cookies_dic.keys():
self.cookies[i] = res_cookies_dic[i]
#将服务器返回的cookies写入到mycookies.txt中实现更新
for k in self.cookies.keys():
self.res_cookies_txt += k+"="+self.cookies[k]+";"
with open('mycookies.txt',"w",encoding="utf-8") as f:
f.write(self.res_cookies_txt)
def login(self):
#开启一个session会话
session = requests.session()
#设置请求头信息
session.headers = self.headers
#将cookiesJar赋值给会话
session.cookies=self.read_cookies()
#向测试站点发起请求
response = session.get(self.test_url)
print(response.content.decode())
self.set_cookies(response.cookies)
if __name__ == '__main__':
taobao=TaoBao()
taobao.login()
运行后的结果:
到此我们就实现了淘宝的模拟登陆,然后就可以开心的去抓数据了(埋个伏笔)。。