Python正则表达式/分组/优先级
正则表达式:参考链接:https://www.cnblogs.com/zjltt/p/6955965.html
模块:re
用途:用于模糊匹配
正则表达式的符号
一.元字符
- . 通配符:可代指任意一个符号,除换行符
import re
print(re.findall('a..x','scdcdabnxmn'))
#输出:
['abnx']
- ^ 在字符串开头匹配
import re
print(re.findall('^a..x','ascxdcdabnxmn'))
#输出
['ascx']
- $ 在字符串结尾匹配
import re
print(re.findall('a..x$','ascxdcdabnxamnx'))
['amnx']
-
- 重复0到无穷次
import re
print(re.findall('m*','ascxdcmmmmmdabnxamnx'))
#输出
['', '', '', '', '', '', 'mmmmm', '', '', '', '', '', '', 'm', '', '', '']
-
- 重复1到无穷次
import re
print(re.findall('m+','ascxdcmmmmmdabnxamnx'))
#输出
['mmmmm', 'm']
- ?结尾数据匹配0或1次
import re
print(re.findall('xdc?','ascxdcccmmmmmdabnxamnx'))
#输出
['xdc']
- {a,b} 结尾数据匹配 a到b次
import re
print(re.findall('xdm{2,3}','ascxdmmmmmdabnxxdmmnx'))
#输出
'xdmmm', 'xdmm']
- []或, []中不可加元字符。在[]中有特殊意义的字符有:-(表示范围),^(表示取反),\ (表示转义,去格式化)
import re
print(re.findall('x[yz]','hiuhwfxyndvkfjxz'))
#输出
['xy', 'xz']
- \ 表示转义符,放在特殊字符前可将特殊字符变成普通字符
- | 或 表示或:
import re
s='abekwjbnkcdndnv'
print(re.findall('kw|c',s))
#输出:
['kw', 'c']
- ()表示分组,分组内的内容为整体
import re
print(re.findall('x(dm)','ascxdmxdmxdmmmdabnxxdmmnx'))
#输出:
['dm', 'dm', 'dm', 'dm']
- findall+分组:优先匹配分组里的内容
f=re.findall('www\.(baidu|163).com','www.baidu.com')
print(f)
#输出
['baidu']
- 有名分组:?Ppattern 匹配方式 将用pattern在字符串里匹配到的内容以键值对的形式输出,name为key,pattern匹配到的结果为value
import re
s='alex23xiaoming35xiaohong56'
print(re.search('(?P[a-z]+)(?P\d+)',s).groupdict('name'))
#输出
{'name': 'alex', 'age': '23'}
字符表
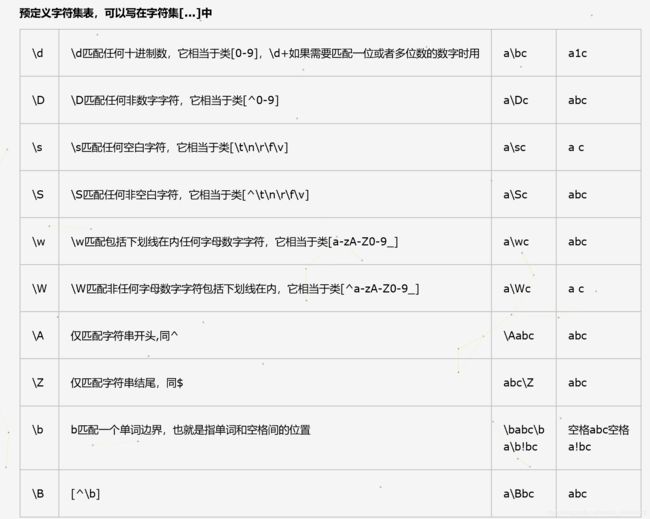
re模块下的方法:
-
re.findall(pattern, string) pattern是正则表达式,string 是需要匹配的字符串
返回所有符合条件的, 返回列表返回所有符合条件的, 返回列表 -
obj=re.search(pattern, string) 找到一个即停止寻找,返回一个对象,通过三种方法调用:
obj.group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
obj.groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
obj.groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果 #用于有名分组
#实例:
import re
obj=re.search('a(..)x','scdcdabnxmn')
print(type(obj))
print(obj)
print(obj.group())
print(obj.groups())
print(obj.groupdict())
#输出
abnx
('bn',)
{}
- re.match(pattern,string)从开头匹配,返回一个对象,调用同search
- re.split(pattern,string) 按正则表达式搜索到的结果分割字符串,结果中不包含分隔符
import re
s='alexm23xiaoming35mxiaohongm56'
print(re.split('\d\w',s))
#输出
['alexm', 'xiaoming', 'mxiaohongm', '']
- re.sub(‘需要替换的对象’,‘替换的内容’,s,n替换次数):替换
import re
s='abchjh9vjhfe8kjqv3bj'
print(re.sub('\d+','A',s))
#输出:
abchjhAvjhfeAkjqvAbj
- re.compile(pattern) 编译正则表达式
import re
s='abchjh933737vjhfe8kjqv3bj'
com=re.compile('\d+')
#两种使用方法
print(com.findall(s))
print(re.findall(com,s))
#输出
['933737', '8', '3']
['933737', '8', '3']
- re.finditer() 返回迭代器,迭代对象是re.Match对象,调用方法如search和match
import re
s='abchjh933737vjhfe8kjqv3bj'
it=re.finditer('\d+',s)
print(type(it))
print(type(next(it)))
print(next(it).group())
#输出:
8
- findall+分组:优先匹配分组里的内容
f=re.findall('www\.(baidu|163).com','www.baidu.com')
print(f)
#输出
['baidu']
- 在分组加?:去优先级
import re
f=re.findall('www\.(?:baidu|163).com','www.baidu.com')
print(f)
#输出
['www.baidu.com']
- re.S: 匹配时自动换行
正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
import re
a = '''asdfsafhellopass:
234455
worldafdsf
'''
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print 'b is ' , b
print 'c is ' , c
#输出:
b is []
c is ['pass:\n\t234455\n\t']
#辨析:优先级/去优先级/贪婪匹配/非贪婪匹配
一些例子感受区别:
import re
print(re.findall('m(.*?)','ascxdcmmmmmdabnxamnx')) #优先匹配分组里的内容
['', '', '', '', '', '']
print(re.findall('m.+?','ascxdcmmmmmdabnxamnx')) #
['mm', 'mm', 'md', 'mn']
print(re.findall('m*?','ascxdcmmmmmdabnxamnx'))
['', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '']
print(re.findall('m(?:.*?)','ascxdcmmmmmdabnxamnx')) #去优先级
['m', 'm', 'm', 'm', 'm', 'm']
print(re.findall('m.*?','ascxdcmmmmmdabnxamnx'))
['m', 'm', 'm', 'm', 'm', 'm']
import re
print(re.findall('m(.*?)x','ascxdcmmmmmdabnxamnx')) #优先匹配分组里的内容,尽可能少的匹配
['mmmmdabn', 'n']
print(re.findall('m(.*)x','ascxdcmmmmmdabnxamnx')) #优先匹配分组里的内容,尽可能多的匹配
['mmmmdabnxamn']