这里我们将建立 一个对抗生成网络 (GAN)训练MNIST,并在最后生成新的手写数字。
这里先介绍几个Demo:
- Pix2Pix
- CycleGAN
- A whole list
Pix2pix 基本上就是你画一个东西它就能生成类似的图片
CycleGAN 这里视频可以让马看起来像斑马。

GAN背后的思想是你有一个生成器和辨别器,它们都处在这样的一个博弈中,生成器产生假图像,比如假数据,让它看起来更像真数据,然后辨别器努力辨识该数据是真或是假。所以生成器将假数据传递给辨别器,而你将真数据传递给辨别器,然后由辨别器判定它是真是假。当你在训练时,生成器会学习生成图像和数据,让它们看起来尽量与真实数据一样,在这个过程中它会模仿实际真实数据的概率分布,通过这种方式,你可以生成与真实世界中看起来一样的新图像、新数据。
这里导入包和数据集
%matplotlib inline
import pickle as pkl
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data')
模型输入
这里创建两个输入,辨别器的输入为inputs_real,生成器的输入为inputs_z。
def model_inputs(real_dim, z_dim):
inputs_real = tf.placeholder(tf.float32,(None ,real_dim),name ='input_real')
inputs_z = tf.placeholder(tf.float32,(None,z_dim),name = 'input_z')
return inputs_real, inputs_z

上图显示了整个网络的样子,这里生成器输入是我们的z,它只是一个随机向量,一种随机白噪声,我们会将其传入生成器,然后生成器学习如何将这个随机向量Z转变为tanh层中的图像,tanh的输出范围为-1到1,这意味我们需要做转化工作,需要转换MNIST,使其取值-1到1之间。然后再将其传入到辨别器网络。
生成器
def generator(z, out_dim, n_units=128, reuse=False, alpha=0.01):
''' Build the generator network.
Arguments
---------
z : Input tensor for the generator
out_dim : Shape of the generator output
n_units : Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out, logits:
'''
with tf.variable_scope('generator',reuse = reuse) :
# Hidden layer
h1 = tf.layers.dense(z,n_units,activation = None)
# Leaky ReLU
h1 = tf.maximum(alpha * h1,h1)
# Logits and tanh output
logits = tf.layers.dense(h1,out_dim)
out = tf.tanh(logits)
return out
使用tf.variable_scope,需要声明with tf.variable_scope('scope_name', reuse=False):这里我们使用generator作为域的名称,所以基本上所有的变量都将以generator开头。
这里我们选择重用,所以它将告诉作用域重用本网络中的变量。那么,我们从函数参数中获得reuse,默认情况下它是False。tf.layers.dense是一个全连接层,你可以直接使用层模块,因为它是高级的,它会为你执行所有权重初始化。
辨别器
辨别器和生成器构造方法差不多。
def discriminator(x, n_units=128, reuse=False, alpha=0.01):
''' Build the discriminator network.
Arguments
---------
x : Input tensor for the discriminator
n_units: Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out, logits:
'''
with tf.variable_scope('discriminator',reuse = reuse):
# Hidden layer
h1 =tf.layers.dense(x,n_units,activation = None)
# Leaky ReLU
h1 =tf.maximum(alpha * h1,h1)
logits = tf.layers.dense(h1,1,activation = None)
out =tf.sigmod(logits)
return out, logits
超参数
# Size of input image to discriminator
input_size = 784 # 28x28 MNIST images flattened
# Size of latent vector to generator
z_size = 100
# Sizes of hidden layers in generator and discriminator
g_hidden_size = 128
d_hidden_size = 128
# Leak factor for leaky ReLU
alpha = 0.01
# Label smoothing
smooth = 0.1
构建网络
tf.reset_default_graph()
# Create our input placeholders
input_real, input_z = model_inputs(input_size, z_size)
# Build the model
g_model = generator(input_z, input_size)
# g_model is the generator output
d_model_real, d_logits_real = discriminator(input_real)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True)
这里辨别器用相同的权重,所以reuse这里为true.
计算辨别器及生成器的损失
同时训练辨别器和生成器网络,我们需要这两个不同网络的损失。对辨别器总损失:是真实图像和假图像损失之和。
关于标签,对于真实图像,我们想让辨别器知道它们是真的,我们希望标签全部是1。为了帮助辨别器更好的泛化,我们要执行一个叫做标签平滑的操作,创建一个smooth的参数,略小于1。假数据辨别器损失也类似,设定这些标签全部为0。最后对于生成器,再次使用d_logits_fake,但这次我们的标签全部为1,我们想让生成器欺骗辨别器,我们想让辨别器认为假图像是真的
# Calculate losses
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_logits_real) * (1 - smooth)))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_logits_real)))
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_logits_fake)))
优化器
我们要分别更新生成器和辨别器变量,首先获取所有可训练的变量
# Optimizers
learning_rate = 0.002
# Get the trainable_variables, split into G and D parts
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith('generator')]
d_vars = [var for var in t_vars if var.name.startswith('discriminator')]
d_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)
训练
batch_size = 100
epochs = 100
samples = []
losses = []
# Only save generator variables
saver = tf.train.Saver(var_list=g_vars)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for ii in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
# Get images, reshape and rescale to pass to D
batch_images = batch[0].reshape((batch_size, 784))
batch_images = batch_images*2 - 1
# Sample random noise for G
batch_z = np.random.uniform(-1, 1, size=(batch_size, z_size))
# Run optimizers
_ = sess.run(d_train_opt, feed_dict={input_real: batch_images, input_z: batch_z})
_ = sess.run(g_train_opt, feed_dict={input_z: batch_z})
# At the end of each epoch, get the losses and print them out
train_loss_d = sess.run(d_loss, {input_z: batch_z, input_real: batch_images})
train_loss_g = g_loss.eval({input_z: batch_z})
print("Epoch {}/{}...".format(e+1, epochs),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
# Save losses to view after training
losses.append((train_loss_d, train_loss_g))
# Sample from generator as we're training for viewing afterwards
sample_z = np.random.uniform(-1, 1, size=(16, z_size))
gen_samples = sess.run(
generator(input_z, input_size, reuse=True),
feed_dict={input_z: sample_z})
samples.append(gen_samples)
saver.save(sess, './checkpoints/generator.ckpt')
# Save training generator samples
with open('train_samples.pkl', 'wb') as f:
pkl.dump(samples, f)
结果
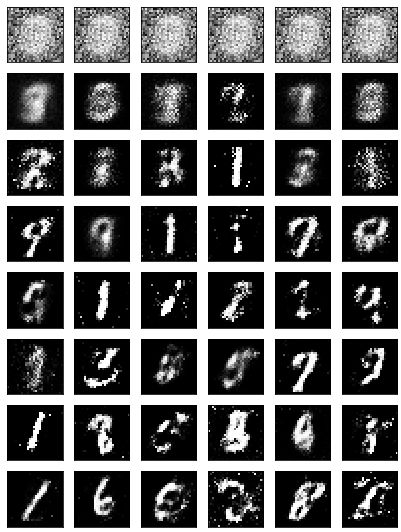
改进GAN
我向你展示的 GAN,在生成器和辨别器中只使用了一个隐藏层。这个 GAN 的结果已经非常不错了,但仍然有很多噪声图像,以及有些图像看起来不太像数字。但是,要让生成器生成的图像与 MNIST 数据集几乎一样,是完全可能的。

这来自一篇题为 Improved Techniques for Training GANs 的文章。那么,它们如何生成如此美观的图像呢?
批归一化
提醒一下,在三层情况下你可能无法使它很好地工作。网络会变得对权重的初始值非常敏感,导致无法训练。我们可以使用 批归一化(Batch Normalization) 来解决这个问题。原理很简单。就像我们对网络输入的做法一样,我们可以对每个层的输入进行归一化。也就是说,缩放层输入,使它具有零均值和标准差 1。经发现,批归一化对于构建深度 GAN 非常有必要。
欢迎大家看我以前写的Batch Normalization