ElasticSearch+Filebeat+kibana+log4j
1.日志内容输出到指定文件:
需求:将某个类中的大于info级别的日志输出到特定的日志文件中,并以一定的格式保存,昨天以及以后的文件以压缩包的形式保存
log/jh.log
%date [%level] [%thread] %logger{60} [%file : %line] %msg%n
log/daily/jh.%d{yyyy-MM-dd}.gz
180
${log-home-ErpToWarehose}/erpToWarehouse.log
${warehouse-format}
${log-home-ErpToWarehose}/daily/jh.%d{yyyy-MM-dd}.gz
180
${log-home-WarehouseToErp}/warehouseToErp.log
${warehouse-format}
${log-home-WarehouseToErp}/daily/jh.%d{yyyy-MM-dd}.gz
180
${warehouse-format}
2. 装机步骤
2.0ES装机步骤:
1.下载
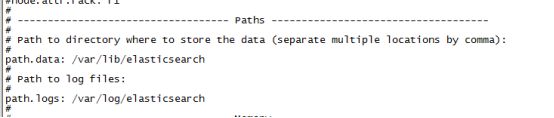
Rpm安装:安装地址默认linux的 /etc/elasticsearch/elasticsearch 下面
/kibana/kibana
/filebeat/filebeat
启动日志目录:/var/log/*
filebeat和log文件所在服务器A
ElasticSearch和kibana在B
测试有没安装成功
$ curl localhost:9200
{
"name" : "atntrTf",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "tf9250XhQ6ee4h7YI11anA",
"version" : {
"number" : "5.5.1",
"build_hash" : "19c13d0",
"build_date" : "2017-07-18T20:44:24.823Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
2.修改配置文件
Es:
1:
2:必须在第一个位置开始写,不然无效,亲测。默认只能本机访问,这么配置外网可以访问

Kibana:
1:内网地址

2:ES部署在本机上所以是本机地址,也可以是内网地址

Filebeat:
1:采集日志地址

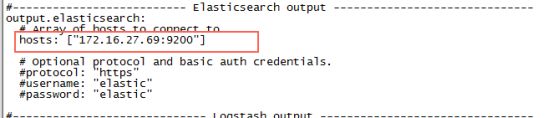
2:直接输出到ES上,需要配置内网地址
3.启动
systemctl start elasticsearch
systemctl satry kibana
systemctl start filebeat
启动检查日志路径:/var/log/* /*.log
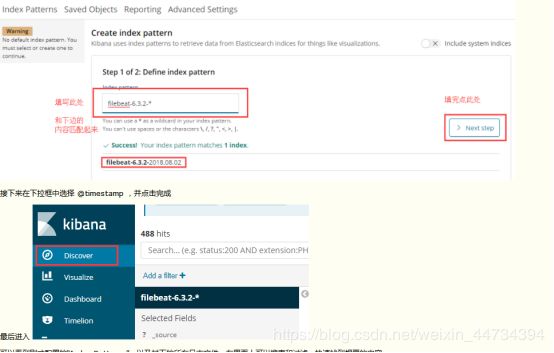
4.补充:开启filebeat中自带的默认模块
filebeat modules disable system:关闭状态不自动采集,根据配置的
filebeat modules enable system:开启状态及时注释掉配置路径约会采集默认的日志路径
默认全部关闭状态
3. 逻辑

4. 让我来了解下ElasticSearch
Elasticsearch是一个开源的分布式文档存储和搜索引擎,可以近乎实时地存储和检索数据结构。 由Shay Banon开发并于2010年发布,它在很大程度上依赖于Apache Lucene,这是一个用Java编写的全文搜索引擎。
Elasticsearch以结构化JSON文档的形式表示数据,并通过RESTful API和Web客户端访问PHP,Python和Ruby等语言的全文搜索。 它也具有弹性,因为它易于水平扩展 - 只需添加更多节点即可分配负载。 如今,许多公司,包括维基百科,eBay,GitHub和Datadog,都使用它来存储,搜索和分析大量数据。
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
1.提供restApI来进行增删改查的操作,返回的是JSON数据。查询索引删除等。
2.Elastic 的查询非常特别,使用自己的查询语法,
3.典型的多节点的集群安装
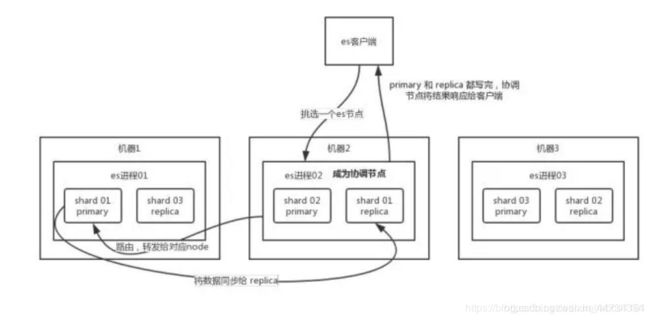
写数据原理:
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。[路由的算法是?]
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
读数据过程:
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node。
coordinate node 返回 document 给客户端。
总结:
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。面试说清楚可是很加分的
参考:
https://www.jianshu.com/p/53580217a010
https://blog.csdn.net/abcd1101/article/details/89010070