Secure Federated Transfer Learning (论文翻译与拓展)
Secure Federated Transfer Learning
安全联邦迁移学习
#论文链接 https://arxiv.org/pdf/1812.03337.pdf
(因数学符号无法正常表示,请参照原文的数学公式阅读)
一.摘要
机器学习依赖于大量训练数据的可用性。然而,在现实中,大多数数据分散在不同的组织中,无法在许多法律和实际约束下轻松集成。在本文中,我们引入了一种新的技术和框架,称为联邦迁移学习(FTL),以改进数据联合下的统计模型。该联合允许在不损害用户隐私的情况下共享知识,并允许补充知识在网络中可以传输的。因此,目标域方可以利用来自源域方的丰富标签构建更灵活和更强大的模型。一种安全的传输交叉验证方法被提出来保护联合下的FTL性能。该框架需要对现有模型结构进行最小的修改,并提供与非隐私保护方法相同的精确度。该框架非常灵活,能够有效地适应各种安全的多方机器学习任务。
二.介绍
最近的人工智能(AI)成就一直依赖于大量标记数据的可用性。AlphaGo (Silver et al. 2016)使用了16万场实际比赛中的3000万步棋。ImageNet数据集(Deng et al. 2009)拥有超过1400万幅图像。然而,在不同的行业中,更多的应用领域只有很小或质量很差的数据。标记数据非常昂贵,尤其是在需要人类专业知识和领域知识的领域。此外,特定任务所需的数据可能不会保存在一个地方。许多组织可能只有未标记的数据,而其他一些组织的标记数量可能非常有限。这使得组织越来越难以合并它们的数据。例如,由欧盟提出的新法案《一般数据保护条例》(General Data Protection Regulation, GDPR) (EU 2016)实施了许多保护用户安全隐私的条款,禁止组织直接交换数据。如何在满足数据隐私、安全和监管要求的同时,让大量数据量小(样本和特性少)或监管薄弱(标签少)的企业和应用构建有效、准确的人工智能模型,是一个重大挑战。为了克服这些挑战,谷歌首先引入了一个联邦学习(FL)系统(McMahan et al. 2016),其中一个全球机器学习模型由一个分布式参与者联盟更新,同时将他们的数据保存在本地。它们的框架要求所有贡献者共享相同的特性空间。另一方面,研究了基于特征空间数据分割的安全机器学习(Karr等,2004;Sanil等,2004;Gasc ’ on et al. 2016;杜,韩,陈,2004;Wan等,2007;Hardy等,2017;Nock等,2018)。这些现有方法只适用于联合下的公共特性或公共示例。然而,在现实中,一组共同实体可能很小,从而使联合的吸引力降低,并使大多数不重叠的数据受到损害。在本文中,我们针对这些挑战提出了一个可能的解决方案:联邦迁移学习(FTL),利用迁移学习技术(Pan et al. 2010)为联邦下的整个样本和特征空间提供解决方案。我们的主要贡献如下:
1.我们在隐私保护设置中引入联邦迁移学习,以提供现有联邦学习方法范围之外的联邦问题的解决方案。
2.我们提供了一个端到端的解决方案,并证明了该方法的收敛性和准确性可与非隐私保护方法相媲美。
3.我们为多方计算和神经网络提供一个采用加法同态加密的新颖的方法,这样只需要对神经网络进行最少的修改而准确性几乎无损,而大多数现有的安全深度学习框架采用隐私保护技术时遭受精的损失。
三.相关工作
·联邦学习和安全的深度学习
近年来,关于加密机器学习的研究激增。例如
·谷歌引入了一种安全聚合方案,在其联邦学习框架下保护聚合用户更新的隐私(Bonawitz等,2017)。
·CryptoNets (Dowlin et al. 2016)采用神经网络计算来处理用同态加密的数据(Rivest、Adleman和Dertouzos 1978)。
·CryptoDL (McMahan等,2016)近似于激活函数在低阶多项式神经网络中实现较低的预测精度损失。
·深度安全学习 (Rouhani, Riazi, Koushanfar 2017)使用姚氏混淆电路协议代替HE(同态加密)进行数据加密。
所有这些框架都是为使用服务器端模型进行加密预测而设计的,因此只适用于推理。SecureML (Mohassel and Zhang 2017)是一种多方计算方案,它使用秘密共享(Rivest, Shamir, and Tauman 1979)和姚氏混淆电路,支持线性回归、逻辑回归和神经网络的协作训练,最近由(Mohassel和Rindal 2018)用三方计算扩展。差异隐私(Dwork 2008)是另一项隐私保护培训工作。它的缺点是原始数据可能被公开且无法对单个实体进行推理。
·迁移学习
迁移学习是一种功能强大的技术,可以为数据集较小或监控能力较弱的应用程序提供解决方案。近年来,将迁移学习技术应用于图像分类(Zhu等,2010)和情绪分析(Pan等,2010;Li等,2017)等多个领域的研究工作取得了长足的进展。迁移学习的性能取决于各领域之间的关联程度。直观地说,相同数据联合中的参与方通常是来自相同或相关行业的组织,因此更容易传播知识。
四.问题定义
假设一个源域数据集DA:= {(xAi, yAi)}NA i=1,其中xAi∈Ra和yAi∈{+1,;1}是第i个标签,目标域DB:= {xBj}NB j=1,其中xBj∈Ra。DA、DB分别由两个私有方持有,不能相互公开。我们还假设在甲方:存在一组有限的共发生样本DAB:= {(xAi, xBi)}NAB i=1和一小组存在A方的标签B:Dc:= {(xBi, yAi)}Nc i=1,其中Nc为可用目标标签的数量。不失一般性,我们假设所有的标签都在A方,但是这里所有的推论可以在标签存在B方的情况下做调整 。我们可以通过加密技术例如RSA方案掩饰数据ID来找到共享样本ID设置 。这里我们假设A和B已经找到或者都知道它们的共享样例ID。在上述背景下,双方的目标是建立一个迁移学习模型以尽可能准确地预测目标域方的标签,而不需要相互公开数据。
·安全的定义
在我们的安全定义中,所有各方都是诚实但好奇的。我们假设一个威胁模型,其中有一个半诚实的对手D,他最多可以破坏两个数据客户机中的一个。安全的定义是,一个协议P执行(OA, OB) = P (IA ,IB), OA和OB是A方和B的输出,IA和IB是他们的输入,P是安全的,对与A来讲是否存在无穷多的(I′B,O′B)对这样(OA, O′B) = P (IA,I′B)。这样的安全定义已在(Du, Han, and Chen 2004)中采用。与完全零知识安全相比,它为控制信息披露提供了一种切实可行的解决方案。
五.建议的方法
在本节中,我们将首先介绍迁移学习模型,然后提出一个联邦框架。近年来,深度神经网络被广泛应用于迁移学习中,以寻找隐式迁移机制(Oquab et al. 2014)。在这里,我们探讨一个一般的场景其中A和B的隐藏表示由两个神经网络uAi = Net A(x Ai)和uBi = NetB (x Bi)产生,其中uA∈RNA×d, uB∈RNB×d, d为隐藏表示层的维数。标签目标域,一般的方法是引入一个预言函数ϕ(uBj) =ϕ(uA1 yA1…uANA, yANA, uBj)。无损耗的慷慨,我们假设ϕ(uBj)是线性可分的,这是ϕ(uBj) =ΦAG (uBj)。例如,(蜀et al . 2015年)使用翻译功能,ϕ(uBj) =1/NA PNA i yAi uAi (uBj )′, where ΦA = 1NA PNA i yAi uAi and G(uBj) = (uBj )′,我们可以使用可用的标记集编写训练目标函数:

ΘA,ΘB 分别是NetA和NetB训练参数。让LA和LB分别作为NetA和NetB的网络层的数目,然后ΘA ={θAl} LA l = 1,ΘB ={θBl}LB l=1,θAl和θBl是第l层的训练参数。ℓ1表示损失函数。对于物流损失,ℓ1(y,ϕ)= log(1 + exp ((yϕ))。
此外,我们还希望将A和B之间的对准损失降到最低。
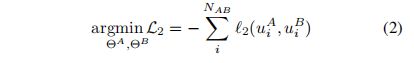
ℓ2表示对齐的损失。典型的对准损失可以是![]() .为简单起见,我们假设他可以以ℓ2(uAi , uBi) =ℓA2 (uAi) + ℓB2 (uBi) + κuAi (uBi )′,的形式表示,而K是一个常数。
.为简单起见,我们假设他可以以ℓ2(uAi , uBi) =ℓA2 (uAi) + ℓB2 (uBi) + κuAi (uBi )′,的形式表示,而K是一个常数。
最终的目标函数是:
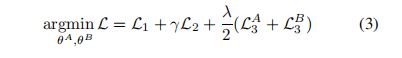
γ和λ是权重参数,LA3 = PLAl||θAl||2F , LB3 = PLBl||θBl||2F是正则化项。
现在我们专注于在反向传播中获取更新的ΘA,ΘB梯度。对于i∈{A, B},我们有

假设A和B不允许公开它们的原始数据,这里需要开发一种隐私保护方法来计算(3)和(4)。
·加法同态加密
加法同态加密(Acar et al. 2018)和多项式近似被广泛用于保护隐私的机器学习,采用这种近似的在效率和隐私之间做权衡也得到了深入的讨论(Aono et al. 2016;Kim等,2018;(Phong et al. 2017)。这里我们使用二阶泰勒近似来计算损耗和梯度:

对于逻辑损失,C(y) = y, D(y) = y^2。应用式(5)和式(6),加上同态加密,记为[[·]],最终得到:

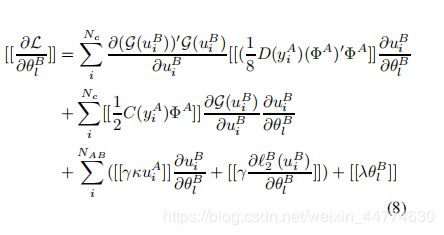
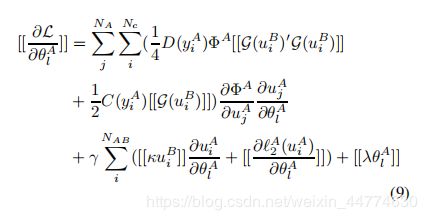
算法一:联邦迁移学习:训练
输入:学习率 η, 权重参数 γ, λ, 最大迭代次数 m, 容错值 t
输出:模型参数ΘA, ΘB
A,B初始化ΘA, ΘB,分别创建加密秘钥对并互相发送公钥。

算法二:联邦迁移学习:预测
输入:模型参数ΘA, ΘB, {xBj }j∈NB
输出:{yBj }j∈NB

·联邦迁移学习
利用上述式(7)、(8)和(9),我们现在可以设计一个联邦算法来解决迁移学习问题。参见算法1。表示[[·]]A和[[·]]B分别为公钥A和公钥B的同态加密。具体来说,甲乙双方在本地初始化并运行各自独立的神经网络Net A和Net B,得到隐藏的表示uAi和uBi,然后甲方计算并加密组件{hk (uAi, yAi)}k=1,2…KA 发送到B,协助计算Net B的梯度。在目前的情况下,……类似地,B计算加密组件{hBk (uBi)}k=1,2…KB并发送到A,以帮助计算A的梯度和损失L,……最近,有大量的工作讨论了与这种间接泄漏相关的潜在风险,如梯度(Hitaj、Ateniese和P’erez-Cruz 2017;Bonawitz等,2017;Shokri和Shmatikov 2015;McSherry说2016;(Phong et al. 2018)。为了避免知道A和B的梯度,A和B进一步用加密的随机值屏蔽每一个梯度,然后A和B互相发送加密的屏蔽梯度和损失,并得到解密的值。一旦满足损耗收敛条件,A可以向B发送终止信号。否则,A和B将解掩码梯度,分别用梯度更新权值参数,并移动到下一次迭代。
(算法二)一旦模型被训练好,我们就可以为乙方提供未标注数据的预测。对于每个未标记的数据,B使用训练过的网络参数ΘB计算uBj,发送加密的[[G (uBj)]]给A,然后A方用随机值评估和屏蔽并发送加密和屏蔽的ϕ(uBj)给 B, B解密并发送回给A,A获得ϕ(uBj)和标签,并将标签发送给B。请注意,在安全FTL过程中性能损失的唯一来源是最终损失函数的二阶泰勒近似,而不是在神经网络的每个非线性激活层,如in (Hesamifard、Takabi和Ghasemi 2017),并且网络内部的计算不受影响。由实验部分可知,采用我们的方法损失和梯度计算的误差以及精度损失是最少的。因此,该方法对神经网络结构的变化具有可扩展性和灵活性。
算法三:联邦迁移学习:交叉验证
输入:模型MF,折叠次数K
输出:模型性能VMF,DF

·迁移交叉验证
对于模型验证,我们还提出了一种安全迁移交叉验证方法(TrCV),其灵感来自(Zhong et al. 2010)。参见算法3。首先,我们将源域中的带标签数据分割成K个褶(层),每次保留一个褶数据作为测试集。利用剩余的数据通过算法1建立模型,通过算法2进行标签预测。接下来,我们将预测的标签与原始数据集结合起来,并通过算法1建再训练模型,并在预留数据集上进行计算,计算结果为:
![]()
解密[[ϕ(uAj)]],与真实标签{yAi }i∈Ik作比较,我们获得第k褶的性能:VMF, Dk。最后,选取最优模型为:
![]()
注意,TrCV使用源域标签执行验证,这在难以获得目标标签的情况下可能是有利的。利用Dc建立了一个自学习监督模型MF,Dc,以防范负迁移(Kuzborskij and Orabona 2013;Zhong et al. 2010)。在标签位于源域方的场景中,自学习被转化为基于特征的联邦学习问题。否则目标域方将自己构建自学习模型。在迁移学习模型不如自主学习模型的情况下,知识不需要转移。
六.安全分析
定理1.在我们的安全定义下,算法1和算法2中的协议是安全的,前提是底层的加法同态加密方案是安全的。
证明.算法1和算法2中的训练协议没有泄露任何信息,因为所有A和B学习的都是带掩码的梯度。每次迭代A和B都会创建新的随机掩码,因此掩码的随机性和保密性对各方(杜,韩,陈,2004)都将保证信息的安全性。在训练过程中,A方每一步都要学习自己的梯度,但这并不足以让A从B处学习到任何信息基于无法用n个以上的未知数求解n个方程(Du, Han, and Chen 2004;Vaidya和Clifton, 2002)。换句话说,B中存在无限数量的输入来听提供给A相同梯度。相似地,B方无法从A处获得任何信息。因此,只要认为加密方案是安全的,协议就是安全的。在评估过程中,A方从B方学习每个样本的预测结果,这是一个标量积,A无法从B处学习到B的信息。而B也只学习标签,无法学习A的信息。
在训练过程的最后,每一方(A或B)都不会知道另一方的数据结构,并且只获得与自身特性相关的模型参数。在推理时,双方需要协同计算预测结果。注意,该协议不处理恶意方。如果A方伪造输入,只提交一个非零输入,则可以识别该输入位置uBi的值。它仍然不能识别xBi或ΘB,没有一方会获得正确的结果。
总之,我们在提议的FTL框架中提供了数据安全性和性能增益。提供数据安全性是因为原始数据DA和DB以及本地模型NetA和NetB从不公开,只交换加密的公共隐藏表示。在每次迭代,甲方和乙方接收到的唯一非加密值是它们的模型参数的梯度,这些梯度是从所有样本变体聚合而来的。将迁移学习、迁移交叉验证和一个自我学习监督模型的保障相结合,可以获得性能增益。
七.实验
在本节中,我们在多个公共数据集进行实验:1)NUS-WIDE数据集(seng蔡et al . 2009年)2)信用卡客户数据集的默认值 (Kaggle) (“Default-Credit”)来验证我们提出的方法和研究关于各种主要影响因素的方法的有效性和可伸缩性,包括重叠样本的数量、隐藏公共表示的维数和特征的数量。NUS-WIDE数据集(seng Chua et al. 2009)包括来自Flickr图像的数百个低层特性,以及它们的关联标签和地面真实标签。总共有81个地面真实标签。我们使用前1000个标签作为文本特征,并结合所有的低层特征,包括颜色直方图,颜色相关图作为图像特征。这里我们考虑的是A和B之间的数据联合,其中A具有文本标签特征和图像标签XA, YA,B具有低层图像特征XB,并且存在一个one-vs-all分类问题。在每次实验中,我们都会从负样本中随机抽取样本,以保持正样本和负样本之间的比例平衡。在这里我们考虑堆叠的自动编码器网络,其中对于i∈{A, B},
![]()
其中l为堆叠式自动编码器的第l层,uAi = xAL, Se(·)为sigmoid激活函数。在我们的实验中,我们分别为每一方训练堆叠的自动编码器,并将编码器的损耗和算法1所示的有监督的联邦迁移损耗最小化。“默认信用”数据集由信用卡记录组成,包括用户的人口统计特征、支付历史、账单报表等,并以用户的默认支付为标签。在对分类特征进行一次热编码后,我们得到包含33个特征和3万个样本的数据集,然后在特征空间和样本空间中对数据集进行分割,以模拟两方联合问题。我们将所有的标签分配给A方,我们也将每个样本分配给A方,B方,或者两者都分配给B方,使得A和B之间有少量的重叠样本。我们在本例中使用了32个神经元的单层SAEs。我们以人口特征放在一边,与支付和平衡特征分开的方式来分离特征。这种分离可以在工业场景中找到,在这种场景中,零售和汽车租赁等业务利用银行数据来预测用户的可信度和客户细分。许多企业(B)只有用户的人口统计数据,和可能的有限的用户融资行为数据集,而银行通常有可靠的标签。然而,由于数据隐私的限制,目前与银行数据(甲方)的合作并不多见,但联邦迁移学习为不同行业的数据搭建了桥梁。在我们的实验中,甲方有6个月的付款及账单余额数据,乙方有用户教育、婚姻、年龄、性别等个人资料。我们采用了转换器功能,如(Shu et al. 2015),逻辑损失功能和对齐损失-suAi (uBi) '。
·泰勒近似的影响
通过对训练损耗衰减和预测性能的监测和比较,研究了泰勒近似的效果。在本文中,我们使用不同深度的神经网络和NUS-WID数据来测试算法的收敛性和精度。在第一种情况下,NetA和NetB都有一个带有64个神经元的自动编码器层。在第二种情况下,NetA和NetB都有两个带有128和64个神经元的自动编码器层。在这两种情况下,我们使用500个训练样本,1396重叠对,γ= 0.05,λ= 0.005。我们在图(1)中总结了结果。[图1:两层和一层神经元联邦迁移学习中使用逻辑损失和泰勒近似的学习损失(左)和加权f1得分(右)比较]

我们发现,与使用全逻辑损失相比,使用泰勒近似时损失衰减速度相似,并且泰勒近似方法的加权F1得分也与全逻辑方法相当。损失在两种情况下收敛到不同的最小值,类似于(Hardy等,2017)。当我们增加神经网络的深度时,模型的收敛性和性能不会下降。大多数现有的安全深度学习框架在采用隐私保护技术时都会经历准确性损失。例如,SecureML (Mohassel和Zhang 2017)报告说,在MNIST数据集上的每一层都使用MPC技术,训练包含128个神经元的2个隐藏层时,准确率损失超过1%。CryptoDL (Hesamifard, Takabi, Ghasemi 2017)是一种纯推理安全的深度学习协议,它表明,在一个2层卷积神经网络中,使用2阶泰勒近似可以导致超过50%的精度损失。仅使用低阶泰勒近似,我们的方法在精度上的下降远远小于具有类似近似的最先进的安全神经网络,因此我们的方法是非常适合于更深层次的神经网络。
·转移学习vs自学
在本节中,我们通过将提出的迁移学习方法与自学习方法进行比较来评估其性能。我们用泰勒损失(TLT)和逻辑损失(TLL)测试了转移学习方法。对于自学习方法,我们选择了三种算法:逻辑回归(LR)、支持向量机(SVMs)和堆叠式自动编码器(SAEs)。SAES与我们用于迁移学习具有相同的结构,并且连接到逻辑层进行分类。我们在NUS-WIDE数据集中选择了三个最常见的标签。对于每个实验,我们使用的共现样本的数量是该类别中总样本数量的一半。我们改变了训练样本集的大小,对每个有随机不同划分的样本的实验进行了三次测试,对于每个实验参数λ和γ用交叉验证进行了优化。结果如表1所示。[表1:泰勒损失(TLT)、逻辑损失(TLL)、自学习的逻辑回归(LR)、支持向量机(SVMs)、堆叠自动编译器(SAEs)的迁移学习加权F1比较]
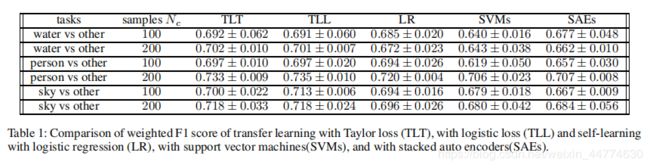
从表1中我们可以看出,TLT和TLL在所有测试中产生的性能相当。在几乎所有的实验中,所提出的转移学习方法只使用一小组训练样本,其性能优于基线自学习方法。此外,随着训练样本数量的增加,性能也得到了提高。实验结果验证了算法的鲁棒性。
·重叠样本的影响
图2显示了改变重叠样本数量对迁移学习性能的影响。重叠样本对用于连接双方之间的隐藏表示,因此,联邦迁移学习的性能会随着重叠样本对可用性的增加而提高。

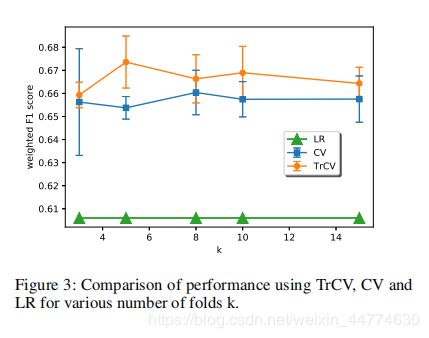
·迁移交叉验证
我们评估迁移交叉验证(TrCV)的性能是通过比较使用Default-Credit数据集的普通的交叉验证(CV)方法。实验进行使用dB = 18,200个训练样本和6000哥重叠的样品,和γ= 0.005,λ= 0.005。结果如图3所示。我们证明了在不同的k(折叠)值下,TrCV方法优于CV方法。
·可伸缩性(可拓展性)
为了评估该算法的可扩展性,我们在一台内存为8gb的Intel i5机器上进行了模拟三方计算的实验。在这些实验中,各方使用XML-RPC协议进行通信。我们使用python (1)中实现的Paillier加法同态加密(Paillier 1999)。我们采用的加密密钥大小为1024位。我们研究了运行时间如何随着重叠样本的数量和目标域特征的数量以及域不变隐藏表示的维数进行缩放,表示为d。从方程(8)和(9)我们展示了B发送加密信息给A的通信成本是:
[1.https://github.com/n1analytics/python-paillier ]
![]()
其中ct表示一个加密文本的大小,n表示发送的样本数量。当将加密的信息从A发送到b时,通信开销是相同的。对于d = 64, ct = 256字节,每个样本通信约为1 MB,我们在图(4)中展示了每次迭代的运行时间是如何与各种关键因素进行伸缩的。
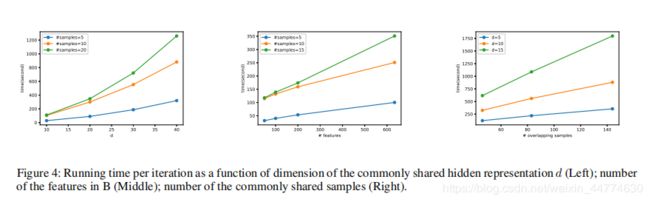
从上面的分析中可以看出,当我们增加隐藏表示d的维数时,运行时间的增加在被测试的重叠样本个数的不同值上是加速的。另一方面,运行时间对于目标域特性的数量以及共享样本的数量呈线性增长。通信时间包含在报告的整个运行时中。使用10个隐藏维度,通信时间大约占总运行时的40%。加密梯度的计算约占运行时的50%,其余的用于加密和解密操作。对于模拟,我们使用带有HTTP连接和localhost服务器代理的XML-RPC协议的python实现。效率和可伸缩性仍然是一个挑战,虽然我们还没有使用分布式和异步计算技术或高性能gpu来进行有效的改进,但是这里提出的算法是并行的,并且与tensorflow等高性能机器学习平台友好。
八.总结
在本文中,我们提出了联邦迁移学习(FTL)框架,并将现有的安全联邦学习扩展到更广泛的实际应用中。我们证明,与现有的总是有精度损失的安全深度学习方法相比,该方法与非隐私保护方法具有同样的准确性,并且具有优于非联邦自学习方法的性能。我们还介绍了一种可伸缩和灵活的方法来适应对现有神经网络结构最小修改的神经网络的加法同态加密。该框架是一个完整的隐私保护解决方案,包括培训、评估和交叉验证。目前的框架并不局限于任何特定的学习模型,而是一种保护隐私的转移学习的通用框架。也就是说,目前的解决方案确实有局限性。例如,它要求各方只交换来自公共表示层的加密中间结果,因此并不适用于所有迁移机制。FTL未来的工作可能包括探索并将该方法应用于其他需要保密数据协作的深度学习系统,以及继续利用分布式计算技术提高算法的效率,寻找较不昂贵的加密方案。
九.致谢
我们特别感谢南洋理工大学邢超平教授和香港科技大学丁存生教授就设计保密协议提出的意见。
·拓
·迁移学习的必要性

辨析:迁移学习与联邦迁移学习
相同点:指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
不同点:迁移学习的训练模型方式是传统的机器学习模式,即将数据全部上传到服务器再进行训练。而联邦迁移学习则是有联邦学习的特点,无需上传数据,用户协同训练模型,将结果上传到服务器端。
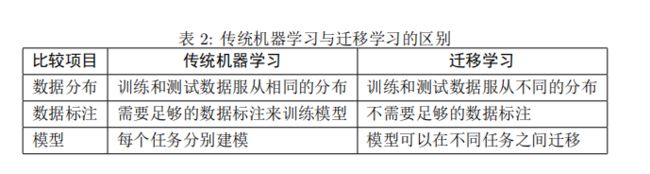
·迁移学习vs传统机器学习
·零知识证明(密码学的应用之一)
证明者可以向验证方证明他们知道X的值,但是不传达任何信息,除了他们知道X的值这件事。零知识证明的本质是通过简单地揭示它来证明某人拥有某些信息,难点在于证明这种占有而不泄露信息本身。