爬虫练习-爬取新浪微博信息并生成词云图
文章目录
- 前言:
- 1.分析爬取对象
- 2.分析网页结构
- 3.获取下一页的数据
- 4.生成词云图
- 效果图
- 完整代码
前言:
爬取新浪微博 “战疫情” 版块微博信息,并将信息内容存储为文本格式,且生成相应的词云图。该爬虫使用的一些技术:
- requests,对网页请求
- json,解析网页返回的数据
- jieba,对中文文本进行分词
- wordcloud,生成词云图
环境:
Python3(Anaconda3)
PyCharm
Chrome浏览器
1.分析爬取对象
前人栽树,后人乘凉。有前辈指出移动端要比PC端好爬取,所以我们爬取移动端微博。如下是两个网址的区别。
PC端微博,https://weibo.com/

移动端微博,https://m.weibo.cn/

2.分析网页结构
打开开发者工具(F12),分析移动端微博的网页结构。
没有分页条,通过滑动侧边进度条加载数据,很明显是通过异步加载实现的。我们前去查看开发者工具中Network板块的XHR文件,记得刷新一下网页。
我们发现箭头所指的文件返回了json格式的微博内容。
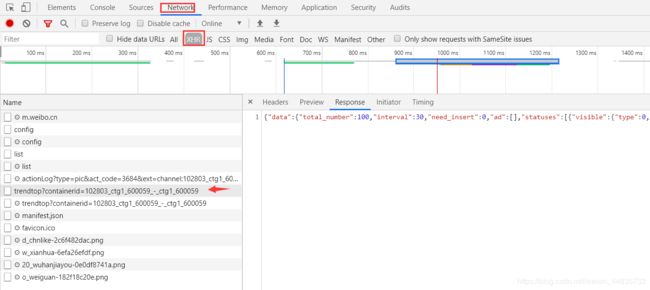
至此,我们需要获取如下两个信息
1.请求该信息的URL。

2.json数据中,微博内容的路径,点击Preview可以更好的查看json内容。

获取json数据的代码写成了一个 get_info() 的函数,如下
# 创建TXT文件
f = open('./weibo.txt', 'a+', encoding='utf-8')
# 定义获取信息的函数
def get_info(url):
rs = requests.get(url=url, headers=headers, timeout=3,cookies=cookies)
print(url, rs)
json_data = json.loads(rs.text)
results = json_data['data']['statuses']
for result in results:
text = re.sub('<.*?>', '', str(result['text']))
print(text + '\n-----------------\n')
f.write(text + '\n\n')
3.获取下一页的数据
手动滑动侧边进度条,直至页面加载,开发者工具内会得到加载的下一页文件数据。

由真实请求的URL,我们发现增加了page这个参数,那我们尝试由此构造URL的列表解析式,以爬取多个页面。
# 爬取i页,可自行修改
urls = ["https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page={}".format(i)for i in range(1, 10)]
这里我要提醒一下,因为加载的第二页或第n页是在加载第一页的基础上的,并非是另外加载一个新的网页,所以我们用cookie来保证我们在一个时间线上,我这提供两个办法。
- 可以一开始就在请求头里加上自己的cookie(我测试过,这里就需要登入微博,不然开发者工具内没有相应的cookie值让你粘贴)
- 是本文中使用的方法,通过 requests.Session() 方法获取cookie值,代码如下:
# 获取cookies值
def get_cookie():
# 原始网页的URL
url = "https://m.weibo.cn"
s = requests.Session()
s.get(url, headers=headers, timeout=3) # 请求首页获取cookies
cookie = s.cookies # 为此次获取的cookies
return cookie
# 获取一次cookies,这里面包含一个时间戳,确保后面的信息是一条时间线上的
cookies = get_cookie()
4.生成词云图
以上步骤就已经可以获得一个微博信息的文本了,接下来我们生成词云图,看看大家热议的话题。
Anaconda安装jieba和wordcloud教程。
python安装就直接在cmd中使用pip install jieba和pip install wordcloud两条命令就行,若是出错了可以参考上面的“Anaconda安装jieba和wordcloud”。
# 定义生成词云的函数
def wordcloud_image():
file = open('./weibo.txt', encoding='utf-8')
txt = file.read()
w = wordcloud.WordCloud(width=1000, height=700, font_path="msyh.ttc")
jieba.del_word(('全文', ''))
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("wuhan.jpg")
file.close()
效果图


完整代码
# 导入相应的文件
import requests
import json
import re
import time
import jieba
import wordcloud
# 加入请求头
headers = {
"Referer": "https://m.weibo.cn/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
# 创建TXT文件
f = open('./weibo.txt', 'a+', encoding='utf-8')
# 获取cookies值
def get_cookie():
# 原始网页的URL
url = "https://m.weibo.cn"
s = requests.Session()
s.get(url, headers=headers, timeout=3) # 请求首页获取cookies
cookie = s.cookies # 为此次获取的cookies
return cookie
# 获取一次cookies,这里面包含一个时间戳,确保后面的信息是一条时间线上的
cookies = get_cookie()
# 定义获取信息的函数
def get_info(url):
rs = requests.get(url=url, headers=headers, timeout=3,cookies=cookies)
print(url, rs)
json_data = json.loads(rs.text)
results = json_data['data']['statuses']
for result in results:
text = re.sub('<.*?>', '', str(result['text']))
print(text + '\n-----------------\n')
f.write(text + '\n\n')
# 定义生成词云的函数
def wordcloud_image():
file = open('./weibo.txt', encoding='utf-8')
txt = file.read()
w = wordcloud.WordCloud(width=1000, height=700, font_path="msyh.ttc")
jieba.del_word('全文')
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("wuhan.jpg")
file.close()
if __name__ == '__main__':
# 爬取i页,可自行修改
urls = ["https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page={}".format(i)for i in range(1, 10)]
for url in urls:
get_info(url)
# 测试少量爬取时间隔3秒,这里建议间隔20秒,不然容易出现403
time.sleep(3)
f.close()
wordcloud_image()