python爬虫期末复习笔记,基础传智播客书 《解析Python网络爬虫》
使用场景区分:通用爬虫和聚焦爬虫
通用爬虫:将互联网上的网页下载到本地。
聚焦爬虫:按照特定目的进行工作的爬虫
爬取形式进行区分:累积式爬虫和增量式爬虫
累积式爬虫:通过遍历的方式爬取所有允许的内容
增量式爬虫:在爬取了大量网页前提的基础下爬取网页更新的内容
按照爬取数据的存在方式进行区分:表层爬虫 和深层爬虫
表层爬虫:爬取网页表层的内容
深层爬虫:不能通过静态网页显示的内容
(建议记住名字)
浏览网页的过程
- DNS解析器解析你输入的网址,解析成对应的ip地址
- 向对应的ip地址发送请求
- Web服务器,返回请求的网页
- 浏览器解析html的内容,并显示出来
URL地址由协议头,服务器地址,文件路径三部分组成
例:http://www.770aa.com/ index/data
http协议头 www.770aa.com服务器地址(会被dns服务器解析格式例如10.10.10.211/分割表示路径)
域名:一个域名只能对应一个ip地址,但是一个ip地址可以对应多个域名
Get请求与put请求“:get请求所有参数都显示在url上,post请求数据隐藏通常用来向服务器提交数据
响应状态码
100~199:表示服务器接收到消息,需要客户端继续提交才能完成整个过程
200~299:表示服务器成功接收处理问题。
300~399:需要客户端继续细化请求,例如请求资源转移到了新的地址(302)
400~499:客户端请求错误,404服务器无法找到请求的页面,403客户权限不够
500~599:服务器出错
Urllib库
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urlopen :request下的一个方法参数
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
注意:
Data必须是一个bytes对象
Timeout 设置超时
剩下两个cadefault、context很少使用书上有介绍懒得打。
最简单的urlopen使用
注意直接返回的对象无法直观看到需要用read方法解析,decode进行编码进行可视化的浏览
如果需要对爬取的网页进行更复杂的操作就需要构造Request对象
构建request 对象可以添加请求头,数据等等
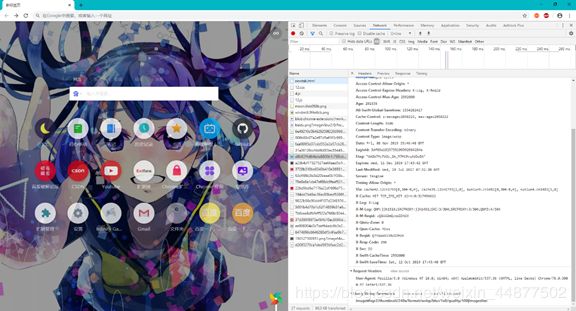
添加请求头直接F12找到User-Agent:
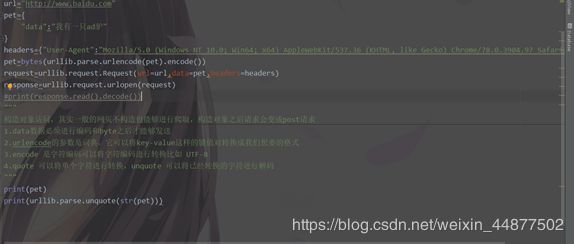
处理get请求的话直接拼接加编码
Post请求直接如图看着构造的发就可以
代理:默认的request暂时不支持所以需要使用自定义的poener

第五章数据解析
有三个重要考点 Xpath 和lxml(lxml是支持xpath的一个库)
、xpath最常用的一些语法选取节点

看完两张图片应该可以基本了解xpath用法 这个方法巨方便建议使用
通配符*用于匹配任何属性
/*用于匹配此节点下面的所有元素
@*用于匹配下面的所有属性节点
Lxml库使用
From lxml import etree
Element、
Xx=etree.Element(“你愿意定义的东西”,可以自己添加的属性)
追加属性 root.set(属性)键值对方法赋值

Etree解析xml

Fromstring方法和XML直接解析标签,巨简单
Elementpath方法解析
Find 和findall方法 一个返回匹配到第一个一个返回所有的文件
先用fromstring或者用XML解析完之后可以用此查询
Lxml库介绍
学会x-path这个就可以直接使用 调用此函数的.xpath直接使用
参考 于 https://www.cnblogs.com/liangmingshen/p/9990669.html
Beautiful soup解析方法,这是一款非常优秀的html解析器
Pip install bs4 导入库其他已经不维护了
使用bs4最基本的方法是创建创建bs4对象
Xx=BeautifulSoup(“此处可以填写自己从网上爬取的数据或者本地存储的”,”l此处填写应用什么库进行解析,一般默认使用lxml,或者xml”)
此函数需要用prettify方法进行输出
Printf(xx.prettify())
此方法同样可以使用find和findall方法,可以参考上方↑
Css 选择器怪麻烦的。。。。。。。平时也用不到所以我0.。0.00.0.00.0.0.0.0.0.0
Jsonpath 与json模块
Json 是python内置的模块可以直接import 调用
Json.dumps方法可以直接将字典类型转换为字符类型
Json.dump方法可以直接将文件类型转换为字符类型
json.loads()用于将字符串形式的数据转化为字典
json.load()用于将文件里字符串形式的数据转化为字典
jssonpath Pip install jsonpath 安装支持库
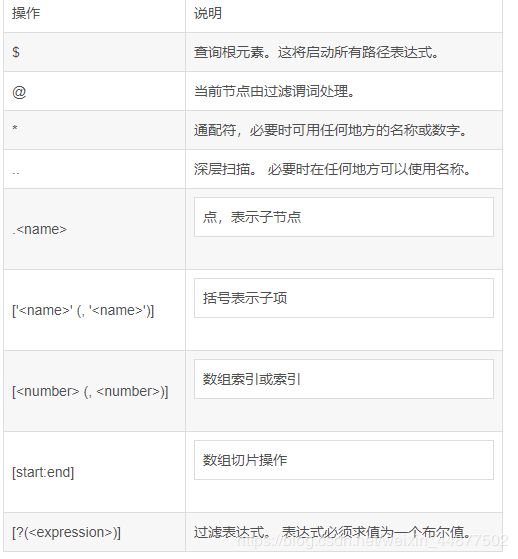
jsonpath 其实和xpath类似都是对xml文件进行节点上的过滤同样可以参考xpath但是jsonpath又和xpath又有些许的不同
可以参考下表
第七章
动态网页就是以来JavaScript脚本动态加载数据的网页
Jquery 常见的的JavaScript库注意爬取的时候可能信息不同步
AJAX能够使网页不需要单独的页面请求就可以访问服务器进行交互
Dhtml 一系列用于解决网络问题的集合,主要是客户端操作改变数据
(并不是很重要)
Selenium库
此库相当于按键精灵 代替用户进行操作
安装此库直接 pip install selenium
此库需要一个简单浏览器的支持一般都是使用淘宝镜像,查看浏览器版本选择合适的镜像,机房一般可以参考我传在班群里的,考试应该不考安装记得代码里引用对了位置即可。
位置位置可以自己定义。
操作一般需要导入库文件

Get方法可以访问网页想访问啥就直接输入就可以
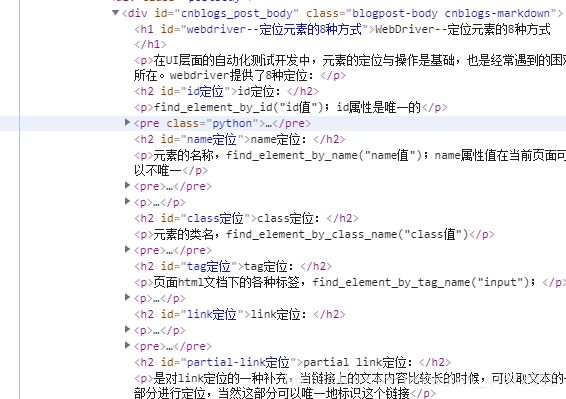
Webdriver定位八种方法
同时可以调用一个By库来对这种方法的替换
![]()

id定位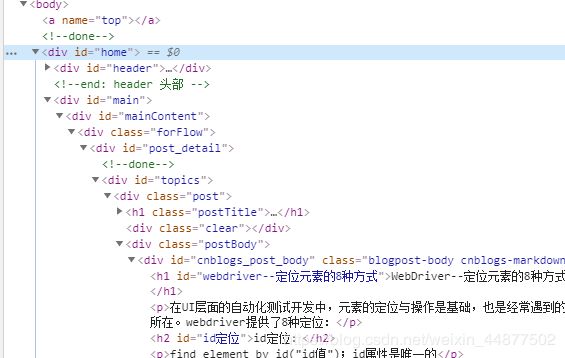
就是找这种id巨简单
例如

其他几种调用均可用此代替,不做过多讲述
Name定位无特殊可参考id
Class更简单可以参考Name定位
Tag定位定的极其不准不建议习惯使用比如
代码中有大量的h、p标签十分容易定不准
Link 定位和partial_link
这两个东西都是根据代码中的连接进行定位,一时找不到例子,自己意会把
Xpath定位
此定位需要了解xpath会在后边进行说明
模拟浏览器的一些操作
浏览器前进后退

浏览器刷新
driver.refresh()
键盘动作
首先需要导入包
From selenium.webdriver.common.key import Keys
模拟ctrl + 操作
Driver.find_element_by_xx(xx).send_keys(Keys.CONTROL,”此处添加你想+的按键”)
模拟输入ENTER
Driver.find_element_by_xx(xx).send_keys(Keys.ENTER)
鼠标动作
首先需要导入
from selenium.webdriver import ActionChains
有以下几种方法
context_click() 右击
double_click() 双击
drag_and_drop() 拖动
move_to_element() 鼠标悬停
通过find_element_by 方法定位到指定元素之后可以直接进行操作注意
最后一定要加上 perform() 用于鼠标操作事件的提交
显示等待和隐式等待
隐式等待是等待特定的时长,显示等待是等待特定的条件
显示等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
导入两个库
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver:浏览器驱动
timeout:最长超时时间,默认单位是秒
poll_frequency:检测的间隔时间,默认是0.5秒
ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException异常。
隐式等待
from selenium .common.exceptions import NoSuchElementException
设置等待时间
driver.implicitly_wait(10)
Select类实现
功能:当遍历表单选择时使用
导入包
From selenium.webdriver.support.ui import Select
Xxx=Select(driver.find_ekement.xx(获取表单))
Select.by_index(通过索引查询)
Select.by_values(“根据值查询”)
Select。By_visible_text(u,“根据文字选择”)
页面切换
For hxxx in driver.window_handles:
Driver.switch_to_window(driver.handler[i])
弹窗处理函数
Alert=driver.Switch_to.alert())
·
一些pip安装可以背一下,给个心里安慰,因为我觉得第六章第九章补考所以没写
Pip install bs4
Pip install jsonpath
pip install selenium
一些import 操作
import urllib
import urllib.request
import re
import lxml
import requests
from lxml import etree
from bs4 import BeautifulSoup
import json
import jsonpath
from queue import Queue
import gevent
from selenium import webdriver
from pymongo import *
实在不知道写啥了引包玩也挺好玩的

祝 成绩优秀,飞黄腾达。