Python中的内存管理和垃圾回收机制
python的内存管理方式是:使用引用计数为主,清除标记,分代回收为辅
引用计数
Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。引用计数方式:让每个被管理的对象与一个引用计数器关联在一起,该计数器记录着该对象当前被引用的次数,每当创建一个新的引用指向该对象时其计数器就加1,每当指向该对象的引用失效时计数器就减1。当该计数器的值降到0就认为对象死亡。(如图所示:图片来自Python核心编程)
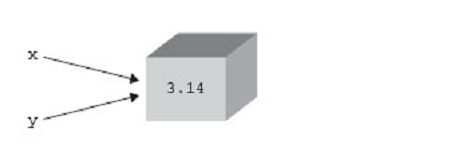
首先创建了一个对象3.14, 然后将这个对象的引用赋值给x,此时x是第一个引用,当前对象的引用计数为1,然后使用语句y = x创建了一个指向同一个对象的引用别名y,当前并没有为y创建一个新的对象,而是将y也指向了x指向的对象,使其引用计数为2.
python中的内置函数id()返回的是对象的内存地址,可以对此进行验证
parameter1 = [1,2,3]
parameter2 = parameter1
print(id(parameter1))
print(id(parameter2))
#输出结果
1471271984
1471271984此时我们发现parameter1和parameter2指向了同一地址,使用查看对象的引用计数:sys.getrefcount()再次进行验证
import sys
parameter1 = [1,2,3]
print(sys.getrefcount(parameter1))
parameter2 = parameter1
print(sys.getrefcount(parameter1))
parameter3=parameter1
print(sys.getrefcount(parameter1))
当使用某个引用作为参数,传递给getrefcount()时,该参数实际上已经对对象做了一次引用。那么getrefcount()所得到的结果,会在原有的基础上+1,此时向后传递得到的引用计数均+1。当对象的引用计数为0时,用户不可能通过任何的方式接触到或者动用到这个对象,当垃圾回收机启动时,Python扫面到这个引用计数为0的对象,就会将它占据的内存空间清空。但是当垃圾回收时python不能进行其他的任务,频繁的垃圾回收会大大的降低python的工作效率,因此python只会在特定的条件下,启动垃圾回收;当python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两个对象的差值达到规定的阈值时,垃圾回收机制会自动启动。
import gc
#python中查看垃圾阈值的方法
print(gc.get_threshold())
#输出结果
(700, 10, 10)标记清除
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
当两个对象的引用计数都为1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被回收的对象,实际上这两个对象存在的有效的引用计数都是0,但由于其相互循环引用使这两个对象的引用计数一直都不为0。此时就需要将循环引用摘掉,就会得出这两个对象的有效计数。举个例子,假设现在Object1和Object2两个对象,此时从Object1开始,Object1中存在一个对Object2的引用,则将Object2的引用计数减1,然后顺着Obje1中的引用到达Object2中,Object2中存在一个对Object1的引用,同样将Object1的引用计数减1,这样就完成了循环引用对象之间的摘除。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
举个例子,现在存在一个对象A,经过了多次的垃圾收集之后依然存活,此时就将对象A分配到一个集合C中,而新创建的对象则分配到集合D中。当垃圾收集开始后,大多数时候都对集合D进行垃圾回收,而对集合C进行垃圾回收的时间间隔会更长,这就使得垃圾回收机制对每次需要检测和处理的对象减少了,效率也会大大的提高,而在垃圾收集的过程之中,集合D中某些存活时间长的对象则会被转到集合C中。依据python中对对象存活时间不同划分不同的集合,存活时间更久的对象会被分配到一个新的集合中。当然无论哪个集合都会存在垃圾,不同集合中的垃圾也会因为垃圾分代回收机制有所延迟。
内存池:
Python的内存机制以金字塔行,-1,-2层主要有操作系统进行操作,
第0层是C中的malloc,free等内存分配和释放函数进行操作;
第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
第3层是最上层,也就是我们对Python对象的直接操作;
Python 在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切换,这将严重影响 Python 的执行效率。为了加速 Python 的执行效率,Python 引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python 内部默认的小块内存与大块内存的分界点定在 256 个字节,当申请的内存小于 256 字节时,PyObject_Malloc 会在内存池中申请内存;当申请的内存大于 256 字节时,PyObject_Malloc 的行为将蜕化为 malloc 的行为。当然,通过修改 Python 源代码,我们可以改变这个默认值,从而改变 Python 的默认内存管理行为

调优手段:
手动回收垃圾
调高垃圾回收的阈值
避免循环引用(手动解循环引用和使用弱引用)
参考:
1、Python内存池管理与缓冲池设计 - 张知临的专栏
2、《垃圾回收的算法与实现》
3、《pyhton源码剖析》