Spark Streaming基础案例实现
文件流
在文件流的应用场景中,需要编写Spark Streaming 程序,一直对文件系统的某个目录进行监听,一旦发现有新的文件生成,
Spark Streaming就会自动把文件内容读取过来,使用用户自定义的处理逻辑进行处理套接字流
Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应的处理
一、在spark-shell中创建文件流
1、创建一个目录 logfile
cd /usr/local/spark/mycode
mkdir streaming
cd streaming
mkdir logfile
2、在另一个终端进入spark-shell,依次输入以下语句
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc,Seconds(20))
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@2108d503
scala> val lines = ssc.
| textFileStream("file:///usr/local/spark/mycode/streaming/logfile")
lines: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.MappedDStream@63cf0da6
scala> val words = lines.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@761b4581
scala> val wordCounts = words.map(x => (x,1)).reduceByKey(_ + _)
wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@515576b0
scala> wordCounts.print()
scala> ssc.start()
# 输出以下:
-------------------------------------------
Time: 1592364620000 ms
-------------------------------------------
3、在回到刚刚创建文件夹的终端,在logfile目录下创建文件log.txt
spark sql
spark streaming
spark MLlib
4、再回到spark-shell的终端就可以看到词频统计的结果
-------------------------------------------
Time: 1592364620000 ms
-------------------------------------------
-------------------------------------------
Time: 1592364640000 ms
-------------------------------------------
(spark,3)
(MLlib,1)
(streaming,1)
(sql,1)
-------------------------------------------
Time: 1592364660000 ms
-------------------------------------------
-------------------------------------------
Time: 1592364680000 ms
-------------------------------------------
二、采用独立程序方式创建文件流
1、创建代码目录和代码文件TestStreaming.scala
cd /usr/local/spark/mycode
mkdir streaming
cd streaming
mkdir file
cd file
mkdir -p /src/main/scala
cd src/main/scala
vi TestStreaming.scala
TestStreaming.scala
import org.apache.spark._
import org.apache.spark.streaming._
object WordCountStreaming{
def main(args:Array[String]){
val sparkConf = new SparkConf().setAppName("WordCountStreaming").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf,Seconds(2))
val lines = ssc.textFileStream("file:///usr/local/spark/mycode/streaming/logfile")
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
2、在/usr/local/spark/mycode/streaming/file目录下创建simple.sbt文件,并写入:
name :="Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.4.5"
3、使用sbt工具对代码进行打包:
cd /usr/local/spark/streaming/file
/usr/local/sbt/sbt package
4、打包成功后,输入命令启动这个程序
cd /usr/local/local/spark/mycode/streaming/file
/usr/local/spark/bin/spark-submit \
--class "WountCountStreaming" \
./target/scala-2.11/simple-project_2.11-1.0.jar
5、在另一个终端的/usr/local/spark/myycode/streaming/logfile目录创建log2.txt文件并写入:
spark sql
spark streaming
spark MLlib
6、再切回spark-shell的终端就可以看到单词统计的信息

三、使用套接字流作为数据源
在套接字流为数据源的应用场景中,它通过Socket方式请求数据,获取数据以后启动流计算过程进行处理
1、创建代码目录和代码文件NetworkWordCount.scala
cd /usr/local/spark/mycode
mkdir streaming #(如果存在则不用创建)
cd streaming
mkdir socket
cd scoket
mkdir -p scr/main/scala
cd /usr/local/spark/mycode/streaming/socket/src/main/scala
2、创建文件NetworkWordCount.scala和StreamingExamples.scala
cd /usr/local/spark/mycode/streaming/socket/src/main/scala
vi NetworkWordCount.scala
vi StreamingExamples.scala
NetworkWordCount.scala写入代码
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object NetworkWordCount{
def main(args:Array[String]){
if(args.length < 2){
System.out.println("Usage: NetworkWordCount " )
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf,Seconds(10))
val lines = ssc.socketTextStream(args(0),args(1).toInt,StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
StreamingExamples.scala写入
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level,Logger}
object StreamingExamples extends Logging{
def setStreamingLogLevels(){
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized){
logInfo("Setting log level to [WARN[ for streaming example."+"To override add custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
3、创建打包代码
在/usr/local/spark/mycode/streaming/socket创建一个文件simple.sbt并写入
name :="Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.4.5"
4、使用sbt工具对代码进行编译打包
cd /usr/local/spark/mycode/streaming/socket
/usr/local/sbt/sbt package
5、打包成功后输入以下命令启动这个程序
[root@master socket]# /usr/local/spark/bin/spark-submit \
> --class "org.apache.spark.examples.streaming.NetworkWordCount" \
> ./target/scala-2.11/simple-project_2.11-1.0.jar \
> localhost 9999
6、在另一个终端窗口输入nc -lk 9999 回车,再输入“hello spark streaming”

7、再回到刚刚那个终端窗口就可以看到输出以下内容

四、使用Socket编程实现自定义数据源
采用自己编写的程序产生数据源
1、编写代码文件 DataSourceSocket.scala
cd /usr/local/spark/mycode/streaming/socket/src/main/scala
vi DataSourceSocket.scala
写入
package org.apache.spark.examples.streaming
import java.io.{PrintWriter}
import java.net.ServerSocket
import scala.io.Source
object DataSourceSocket{
def index(length:Int) = {
val rdm = new java.util.Random
rdm.nextInt(length)
}
def main(args:Array[String]){
if(args.length != 3){
System.err.println("usage: " )
System.exit(1)
}
val fileName = args(0)
val lines = Source.fromFile(fileName).getLines.toList
val rowCount = lines.length
val listener = new ServerSocket(args(1).toInt)
while (true){
val socket = listener.accept()
new Thread(){
override def run = {
println("Got client connected from: "+socket.getInetAddress)
val out = new PrintWriter(socket.getOutputStream(),true)
while (true){
Thread.sleep(args(2).toLong)
val content = lines(index(rowCount))
println(content)
out.write(content + '\n')
out.flush()
}
socket.close()
}
}.start()
}
}
}
2、使用sbt工具对代码进行编译打包
cd /usr/local/spark/mycode/streaming/socket
/usr/local/sbt/sbt package
3、打包成功后新建一个word.txt文件和输入以下命令启动DataSourceSocket这个程序
word.txt文件(在/us/local/spark/mycode/streaming/socket/目录下)
hello spark streaming
hello spark sql
启动DataSourceSocket这个程序
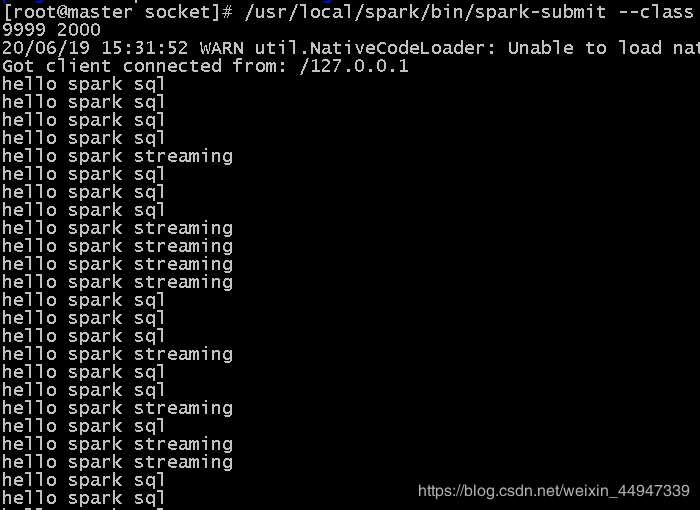
/usr/local/spark/bin/spark-submit \
> --class "org.apache.spark.examples.streaming.DataSourceSocket" \
> ./target/scala-2.11/simple-project_2.11-1.0.jar \
> ./word.txt 9999 1000
DataSourceSocket程序启动后会一直监听9999端口,一旦监听到客户端的连接请求,就会建立连接,每个1秒向客户端源源不断发生数据
4、新开一个终端窗口启动NetworkWordCount
[root@master socket]# /usr/local/spark/bin/spark-submit \
> --class "org.apache.spark.examples.streaming.NetworkWordCount" \
> ./target/scala-2.11/simple-project_2.11-1.0.jar \
> localhost 9999
执行上面命令后,就在当前的linux终端内顺利启动了Socket客户端
他会向本机的9999号端口发起Socket连接,在另一个终端内正在运行的DataSourceSocket程序,一直在监听9999端口,一旦监听到NetworkWordCount程序的连接请求,就会建立连接,每个1秒向NetworkWordCount源源不断的发送数据,终端的NetworkWordCount程序收到数据后,就会执行词频统计,打印如下信息(没有完全截下来)
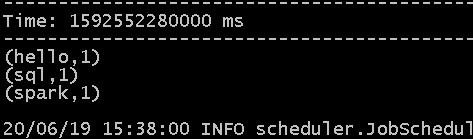


5、在另一个窗口可以看到源源不断的发送数据