二、JVM面试题
目录
Java内存模型
Java虚拟机中共有五大内存区域
2.java内存模型中堆和栈的区别
3.类的装载过程(类加载机制)
4.谈谈类加载器的双亲委派机制
5. 反射中,Class.forName() 和 ClassLoader.loadClass()区别
6. Java 中都有哪些加载器?
7. 对象有哪几部分构成?虚拟机如何访问对象?
8. java 中都有哪些引用类型?
GC相关
1.判定对象是否为垃圾的算法
2.谈谈你了解的垃圾回收算法
3. 分代垃圾回收器是怎么工作的?
4.什么情况下会触发fullGC
5. 内存泄露和内存溢出分别是什么?什么原因造成?如何避免?
Java内存模型
Java虚拟机中共有五大内存区域
程序计数器,Java虚拟机栈,本地方法栈,java堆,方法区
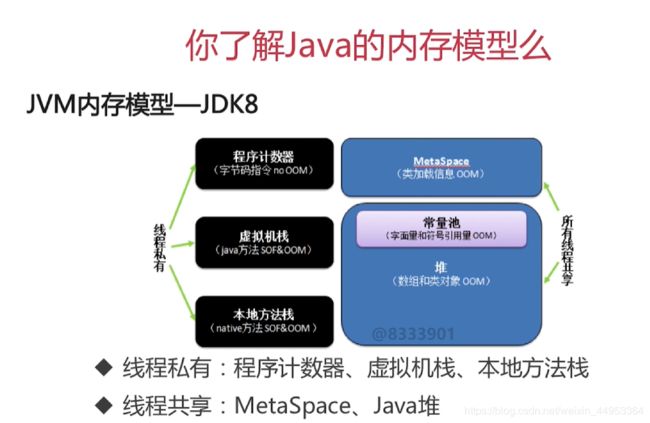
程序计数器:是一块很小的内存空间,用于存储当前线程执行字节码文件的行号指示器。
虚拟机栈:是描述Java方法执行过程的内存模型,每个方法被执行时都会创建一个栈桢,栈桢中存储了局部变量表,操作数栈,动态链接,方法出口等。
本地方法栈:和虚拟机栈作用类似,区别是虚拟机栈为Java方法服务,本地方法栈为Native方法服务。
Java堆:JVM运行过程中创建的对象和生成的数据都存储在堆中,堆是被线程共享的内存区域,也是垃圾回收最主要的内存区域。
方法区:用来存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量池等数据。
2.java内存模型中堆和栈的区别
联系:引用对象、数组时,栈里定义变量保存堆中目标的首地址
区别:
管理方式:栈自动释放,堆需要GC
空间大小:栈比堆小
碎片相关:栈产生的碎片远小于堆
分配方式:栈支持静态和动态分配,而堆仅支持动态分配
效率:栈的效率比堆高
3.类的装载过程(类加载机制)
(1)加载:把class文件加载到内存中
(2)链接(又分为验证、准备、解析)
1、验证:检查加载到内存的文件是否符合格式要求
2、准备:为类变量(static修饰的变量)赋初值(系统默认值)
3、解析:把符号引用转换为直接引用
(3)初始化:执行类变量赋值和静态代码块
4.谈谈类加载器的双亲委派机制
类加载器之间的层次关系叫做双亲委派模型,要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。
一个类收到类加载请求后会层层找父类加载器去尝试加载,因此所有的加载请求最终都会被传送到顶层的启动类加载器,只有当
父类加载器反馈自己无法完成加载时,子类加载器才会尝试自己去加载。
好处:避免同样字节码多次重复加载(内存宝贵,避免保存重复的class类对象)
实现:先判断该类是否被加载过,如果未被加载就调用父类的 loadClass()方法,如果父类为null,则使用启动类加载器作为加载器。如果父类加载失败,抛出 notfound 异常,则调用自己的 findClass 进行加载。简单概括:自底向上检查类是否被加载,自顶向下尝试加载类。
5. 反射中,Class.forName() 和 ClassLoader.loadClass()区别
➢forName得到的class是已经初始化完成的,它会执行static代码
创建数据库驱动:Class. forName (”com. mysql.jdbc. Driver" )
➢loadClass得到的class是还没有链接的
6. Java 中都有哪些加载器?
启动类加载器、扩展类加载器、系统类加载器、用户自定义类加载器
启动类加载器将
扩展类加载器和系统类加载器都是继承自 Java 的 ClassLoader 抽象类,用户可以直接使 用的类加载器。
启动类加载器,Java 程序不可用直接使用,虚拟机默认使用 null 代表启动类加载器
三者存在继承关系,系统类加载器调用 classloader 的构造器把父类设置为扩展类加载器,扩展类加载器调用 classloader 把父类设置为 null(启类动加载器)
7. 对象有哪几部分构成?虚拟机如何访问对象?
对象在内存中的组成部分(对象在内存的划分、对象的内存布局):
对象头: 第一:元数据、GC 分代、哈希值等自身运行信息;
第二:类型指针,确定属于哪个类的实例
实例数据:对象真正存储的有效信息,定义的各种字段的值。
对齐填充:没有实际意义,JVM 内存地址需要 8 字节的整数倍
虚拟机如何访问对象
句柄:堆中专门划分一个区域作为句柄池,虚拟机栈存储是堆中句柄的地址,句柄存储 的是对象的实例数据和类型数据的地址
直接指针:栈中的引用直接指向的就是对象的实例数据和类型数据的地址。
对比:直接指针避免二次寻址;使用句柄,在对象移动时,只修改句柄地址而不用改变 引用的地址。
8. java 中都有哪些引用类型?
强引用:new 语句产生的都是强引用,虚拟机不会主动去回收,即便内存溢出,也是会抛出异常而不是回收强引用。可以将对象=null,从而在垃圾回收器在下一次回收。
软引用:在内存足够时,不会回收,在内存不足时,会回收。常用于缓存技术。
弱引用:垃圾回收器遇到该引用就会回收,常与引用队列一起使用
虚引用:最弱的引用,在对象被 JVM 回收之后收到一个系统通知,用于追踪垃圾回收 过程,必须与应用队列一起使用。
GC相关
1.判定对象是否为垃圾的算法
➢引用计数算法
判断对象的引用数量:
通过判断对象的引用数量,来决定对象是否可以被回收
每个对象实例都有一个引用计数器,被引用则+1 ,完成引用则-1
如果一个对象引用计数为0,则表示此刻该对象没有被引用,可以被当作垃圾收集
优点:执行效率高,程序执行受到的影响较小
缺点:无法检测出循环引用的情况(如父对象有个对子对象的引用,子对象又反过来引用父对象,那么他们的引用数量就永远不可能为0),导致内存泄露
➢可达性分析算法(主流用这种)
通过判断对象的引用链是否可达,来决定对象是否可以被回收
可以作为GC Root的对象:
虚拟机栈中引用的对象(栈帧中的本地变量表)
方法区中的常量引用的对象
方法区中的类静态属性引用的对象
本地方法栈中JNI (Native方法)的引用对象
活跃线程的引用对象
2.谈谈你了解的垃圾回收算法
①标记-清除算法(Mark and Sweep)
➢标记出所有需要回收的对象,然后清除可回收的对象。
缺点:效率较低,且容易造成内存碎片化问题
②复制算法(Copying)
将可用内存分为区域1(对象面)和区域2(空闲面),将新生成的对象放在区域1,
在区域1满后对区域1进行一次标记,将标记后仍然存活的对象复制到区域2,
然后清除区域1。
优点:效率较高且易于实现,解决了内存碎片化的问题
缺点:浪费了大量内存
③标记-整理算法(Compacting)
结合了标记清除算法和复制算法的优点,标记过程和标记-清除算法一样,标记后将存活的对象移动到一端,清理另一端。
优点:避免内存的不连续,不用设置两块内存互换
缺点:要准备两块内存
④分代收集算法(Generational Collector)
根据对象不同类型把内存划分为不同区域,把堆划分为新生代和老年代。
由于新生代的对象生命周期较短,主要采用复制算法。
老年代主要存储长生命周期的大对象,因此采用标记清除或标记整理算法。

3. 分代垃圾回收器是怎么工作的?
新生代和老年代的对象数量和存活时间不同,所以通常是分代使用不同的垃圾回收器。
少量对象存活,适合复制算法:在新生代中,每次 GC 时都发现有大批对象死去,只 有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成 GC。
大量对象存活,适合用标记 - 清理 / 标记 - 整理:在老年代中,因为对象存活率高、 没有额外空间对他进行分配担保,就必须使用 “标记 - 清理”/“标记 - 整理” 算法进行 GC。
4.什么情况下会触发fullGC
①调用System.gc
②老年代空间不足时
③永久代空间不足(JDK1.7之前,JDK1.8已经移除了永久代)
5. 内存泄露和内存溢出分别是什么?什么原因造成?如何避免?
内存泄露:本应被回收的对象因为其他对象的引用而不能被回收,从而在堆中寄存,造成内存泄露,长周期对象持有短周期对象的引用会造成。
内存溢出:无法为对象分配足够的内存,对象申请过多
避免:
不要在循环中创建对象
不要一次调用过多数据
大量字符串使用 StringBuffer 或者 StringBuilder
方法区很少进行垃圾回收,尽量避免申请常量和静态变量