Apache-Flink
Apache-Flink
概述
Flink是构建在数据流之上地有状态计算地流计算框架 通常被人们理解为是第三代大数据分析方案
- 第一代-Hadoop的MapReduce(计算) Storm流计算(2014.9) 两套独立计算引擎 使用难度大
- 第二代-Spark RDD静态批处理(2014.2) DStream|Structured Streaming流计算 统一计算引擎 难度系数小
- 第三代-Flink DataStream(2014.12)流计算框架 Flink Dataset批处理 统一计算引擎 难度系数中级
可以看出Spark和Flink几乎同时诞生 但是Flink之所以发展慢 是因为早期人们对大数据的分析认知不够深刻 或者当时业务场景大都局限在批处理领域 从而导致Flink的发展相比较于Spark较为缓慢 直到2016年人们才开始慢慢意识流计算的重要性
流计算领域:系统监控 舆情监控 交通预测 国家电网 疾病预测 银行/金融风控等
参考:https://blog.csdn.net/weixin_38231448/article/details/100062961
Spark vs Flink战略
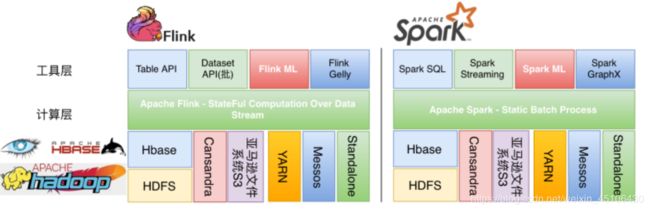
| 计算层 | 工具层 | |
|---|---|---|
| Spark | 采用静态批处理 | Spark SQL SparkStreaming Spark ML Spark GraphX |
| Flink | 有状态计算的数据流 | Table API Dataset API(批处理) Fink ML Flink Gelly |
运行架构
概念
Task和Operator Chain
Flink是一个分布式流计算引擎 该引擎将一个计算job拆分成若干个Task(等价于Spark中的Stage) 每个Task都有自己的并行度 每个并行度都由一个Thread表示 因为一个Task是并行执行的 因此一个Task底层对应一系列的Thread Flink称为这些Thread为该Task的subtask 与Spark不同的地方在于Spark是通过RDD的依赖关系实现Stage的划分而Flink是通过OperatorChain的概念实现Task的拆分 所谓的OperatorChain指的是Flink在做job编织的时候 尝试将多个操作符算子进行串联到一个Task中 以减少数据的Thread到Thread的传输开销
目前Flink创建的OperatorChain 的方式有两种: forwark hash|rebalance
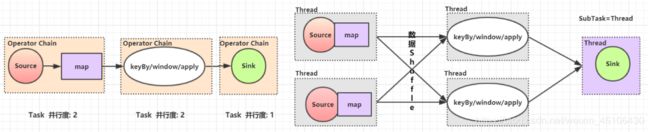
-Task: 等价Spark中的stage 每个Task都有若干个sbuTask
-SubTask: 等价一个线程 是Task中的一个子任务
-OperatorChain: 将多个算子归并到一个Task的一种机制 归并原则类似SparkRDD的宽窄依赖
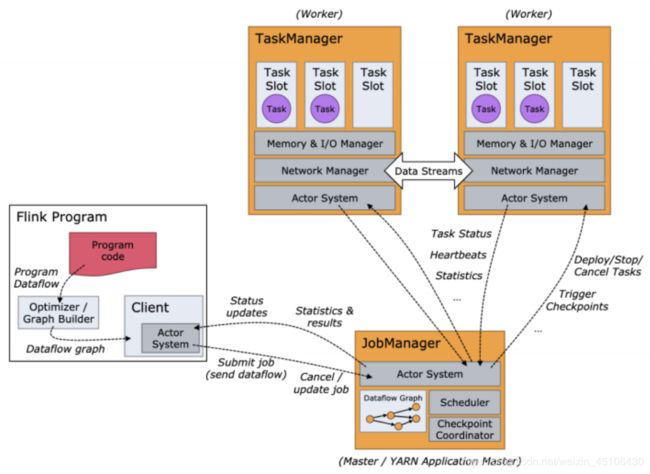
JobManagers TaskManagers Clients
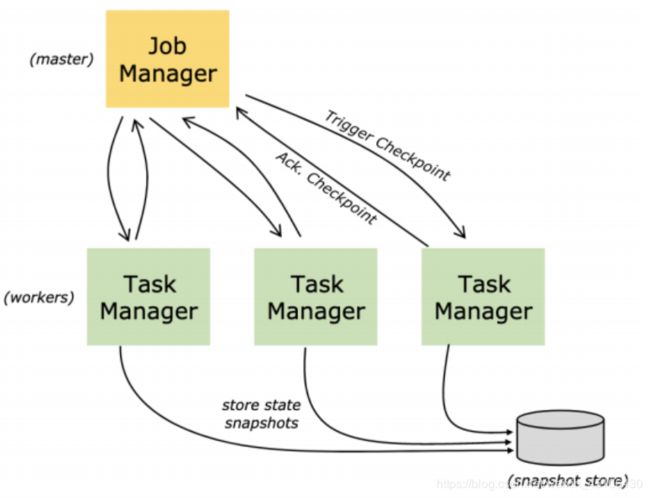
- jobManagers- (也称master) 负责协调分布式执行 负责任务调度 协调检查点 协调故障恢复等 等价于Spark中的Master+Driver的功能 通常一个集群中至少1个Active的JobManager 如果在HA模式下其他出于StandBy状态
(also called masters ) coordinate the distributed execution. They schedule tasks, coordinate
checkpoints, coordinate recovery on failures, etc. There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader , and the others are standby .
- TaskManagers-(称为Worker) 真正负责Task执行计算节点 同时需要向JobManager汇报自身状态信息和工作负荷 通常一个集群中有若干个TaskManager
(also called workers ) execute the tasks (or more specifically, the subtasks) of a dataflow, and bu!er
and exchange the data streams .There must always be at least one TaskManager
- Clients- 与Spark不同 Flink中的Client并不是集群计算的一部分 Client仅仅负责提交任务的Dataflow Graph给JobManager 提交完成之后可以直接退出 Client不负责任务执行过程中调度
The client is not part of the runtime and program execution, but is used to prepare and send a
dataflow to the JobManager. A"er that, the client can disconnect, or stay connected to receive
progress reports
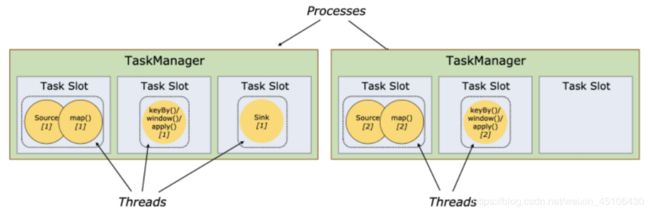
Task Slots和 Resources
每一个Worker(TaskManager) 是一个JVM进程 可以执行一个或者多个子任务(Thread/SubTask) 为了控制Worker节点能够接受多个Task Worker提出Task slot用于表达一个计算节点的计算能力(每个计算节点至少有一个Task slot)
每个TaskSlot表示的是TaskManager计算资源的固定子集 例如:如果一个TaskManager拥有3个TaskSlot 每个Task Slot表示占用当前TaskManager的进程的1/3内存资源 每个job(计算)启动的时候都拥有子集的固定的Task Slot 也就意味着避免了不同job间的在运行时产生内存资源抢占 这些被分配的TaskSlot资源只能被当前job的所有Task所使用 不同Job的Task之间不存在资源共享和抢占问题
但是⼀个Job会被拆分成若⼲个Task,每个Task由若⼲个SubTask构成(取决于Task并⾏度)。默认Task Slot
所对应的内存资源只能在同⼀个Job下的不同Task的subtask间进⾏共享,也就意味着同⼀个Task的不同
subtask不能运⾏在同⼀个Taskslot中,但是如果是相同的job的不同Task的SubTask却可以如果同⼀个Job的不同Task的subtask不共⽤slot,会导致资源浪费。例如下图中 source、map操作定位 为资源稀疏性操作,因为该操作占⽤内存量⼩,⽽keyBy/windows()/apply()涉及Shuffle会占⽤⼤量的内存资源,定位为资源密集型操作,⽐较吃内存。
因此Flink底层默认做的时不同Task的子任务共享TaskSlot资源 因此用户可以将source/map和keyBy/windows()/apply()所对应的任务的并行读进行调整 将并行度由上图中2调整6 这样Flink底层就会做如下资源分配

因此可以看出Flink默认⾏为是尝试将同⼀个job的下的不同Task的SubTask进⾏Task slot共享。也就意味着
⼀个Job的运⾏所需要的Task Slot的个数应该等于该Job中Task并⾏度的最⼤值。当然⽤户也可以通过 程
序⼲预Flink Task间Task Slot共享策略
结论:Flink的job运行所需要的资源数时自动计算出来的 无需用户指定 用户只需指定计算并行度即可
State Backends
Flink是⼀个基于状态计算流计算引擎,存储的key/value状态索引的确切数据结构取决于所选的State
Backend。例如:使⽤Memory State Backend将数据存储在内存中的HashMap中,或者使⽤RocksDB(内
嵌NoSQL数据,和Derby数据库类似)作为State Backend 存储状态。除了定义保存状态的数据结构之
外,State Backend还实现逻辑以获key/value状态的时间点快照并将该快照存储为Checkpoint的⼀部分
Savepoints
⽤Data Stream API编写的程序可以从Savepoint恢复执⾏。Savepoint允许更新程序和Flink群集,⽽不会丢
失任何状态
Savepoint是⼿动触发的Checkpoint,Savepoint为程序创建快照并将其写到State Backend。Savepoint依
靠常规的Checkpoint机制。所谓的Checkpoint指的是程序在执⾏期间,程序会定期在⼯作节点上快照并
产⽣Checkpoint。为了进⾏恢复,仅需要获取最后⼀次完成的Checkpoint即可,并且可以在新的
Checkpoint完成后⽴即安全地丢弃较旧的Checkpoint。
Savepoint与这些定期Checkpoint类似,Savepoint由⽤户触发并且更新的Checkpoint完成时不会⾃动过
期。⽤户可以使⽤命令⾏或通过REST API取消作业时创建Savepoint
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/runtime.html
环境安装
下载地址:https://www.apache.org/dyn/closer.lua/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz
前提条件
- jdk必须是1.8+ 完成JAVA_HOME配置
- 安装Hadoop 并保证正常运行-SSH免密 HADOOP_HOME
Flink安装(Standalone)
- 上传并解压
[root@hbase ~]# tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /usr/soft flink-1.10.0
[root@hbase flink-1.10.0]# tree -L 1 ./
./
!"" bin #执⾏脚本⽬录
!"" conf #配置⽬录
!"" examples #案例jar
!"" lib # 依赖的jars
!"" LICENSE
!"" licenses
!"" log # 运⾏⽇志
!"" NOTICE
!"" opt # 第三⽅备⽤插件包
!"" plugins
#"" README.txt
8 directories, 3 files
- 配置flink-conf.yaml
[root@hbase conf]# vim flink-conf.yaml
#==============================================================================
# Common
#==============================================================================
jobmanager.rpc.address: hbase
taskmanager.numberOfTaskSlots: 4
parallelism.default: 3
- 配置salves
[root@hbase conf]# vim slaves
hbase
- 启动Flink
[root@hbase flink-1.10.0]# ./bin/start-cluster.sh
[root@hbase ~]# jps
3444 NameNode
4804 StandaloneSessionClusterEntrypoint
5191 Jps
3544 DataNode
5145 TaskManagerRunner
3722 SecondaryNameNode
- 检查是否启动成功
可以访问flink地WEB UI地址:http://hbase:8081

QuitckStart
- 引依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.9.2version>
dependency> <dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>1.10.0version>
dependency>
- Client程序
import org.apache.flink.streaming.api.scala._
object FlinkWordCountQiuckStart {
def main(args: Array[String]): Unit = {
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream-细化
val text = env.socketTextStream("hbase",9999)
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.print()
//5.执行流计算任务
env.execute("Window Stream WordCount")
}
}
- 引入maven打包插件
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>4.0.1version>
<executions>
<execution>
<id>scala-compile-firstid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
<executions>
<execution>
<phase>compilephase>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
- 使用mvn package打包
注意:在提交任务之前先启动nc服务 否则任务执行不成功
- 使用WEB UI提交任务
- 查看运行结果

程序部署
本地执行
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.创建DataStream-细化
val text = env.socketTextStream("hbase",9999)
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算结果在控制台打印
counts.print()
//5.执行流计算任务
env.execute("Window Stream WordCount")
[root@hbase ~]# nc -lk 9999
this is demo
1> (this,1)
1> (demo,1)
3> (is,1)
远程部署
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream-细化
val text = env.socketTextStream("hbase",9999)
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算结果在控制台打印
counts.print()
//5.执行流计算任务
env.execute("Window Stream WordCount")
[root@hbase ~]# nc -lk 9999
hello flink
4> (flink,1)
2> (hello,1)
StreamExecutionEnvironment.getExecutionEnvironment会自动识别运行环境 如果运行环境是idea系统会自动切换本地模式 默认系统的并行度使用系统最大线程数 等价于spark中设置的
local[*]如果是生产环境 需要用户在提交任务的时候指定并行度parallelism
- 部署方式
- WEB UI部署(略)
- 通过脚本部署
[root@hbase flink-1.10.0]# ./bin/flink run
--class qiuck_start.FlinkWordCountQuickStart
--detached #后台提交
--parallelism 4 #指定程序默认并行度
--jobmanager hbase:8081 #提交目标主机
/root/ #jar包存放路径
Job has been submitted with JobID b84b11c64018ffd303e5370bb5a9bf44
查看现有任务
[root@hbase flink-1.10.0]# ./bin/flink list --running --jobmanager hbase:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
05.03.2020 12:50:47 : b84b11c64018ffd303e5370bb5a9bf44 : Window Stream WordCount (RUNNING)
--------------------------------------------------------------
取消指定任务
[root@hbase flink-1.10.0]# ./bin/flink cancel --jobmanager hbase:8081 b84b11c64018ffd303e5370bb5a9bf44
Cancelling job b84b11c64018ffd303e5370bb5a9bf44.
Cancelled job b84b11c64018ffd303e5370bb5a9bf44.
查看程序执行计划
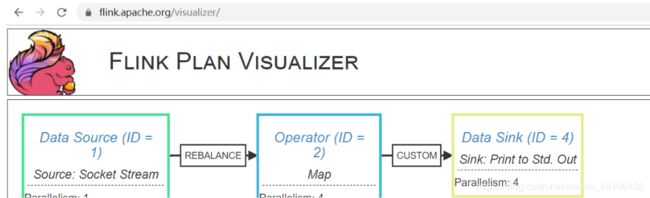
[root@hbase flink-1.10.0]# ./bin/flink info --class qiuck_start.FlinkWordCountQuickStart --parallelism 4 /root/flink-1.0-SNAPSHOT.jar
----------------------- Execution Plan -----------------------
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data Source","contents":"Source: Socket Stream","parallelism":1},{"id":2,"type":"Flat Map","pact":"Operator","contents":"Flat Map","parallelism":4,"predecessors":[{"id":1,"ship_strategy":"REBALANCE","side":"second"}]},{"id":3,"type":"Map","pact":"Operator","contents":"Map","parallelism":4,"predecessors":[{"id":2,"ship_strategy":"FORWARD","side":"second"}]},{"id":5,"type":"aggregation","pact":"Operator","contents":"aggregation","parallelism":4,"predecessors":[{"id":3,"ship_strategy":"HASH","side":"second"}]},{"id":6,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":4,"predecessors":[{"id":5,"ship_strategy":"FORWARD","side":"second"}]}]}
--------------------------------------------------------------
No description provided.
用户可以访问:https://flink.apache.org/visualizer/将json数据粘贴过去 查看Flink执行计划图

跨平台发布
//1.创建流计算执行环境
var jars="D:\\ideaProject\\bigdataCodes\\Flink\\target\\flink-1.0-SNAPSHOT.jar"
val env = StreamExecutionEnvironment.createRemoteEnvironment("hbase",9999,jars)
//设置默认并行度
env.setParallelism(4)
//2.创建DataStream-细化
val text = env.socketTextStream("hbase",9999)
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算结果在控制台打印
counts.print()
//5.执行流计算任务
env.execute("Window Stream WordCount")
在运行之前需要使用mvn重新打包程序 直接运行main函数即可
Streaming(DataStream API)
DataSource
数据源是程序读取数据的来源 用户可以通过env.addSource(SourceFunction) 将SourceFunction添加到程序中 Flink内置许多已知实现的SourceFunction 但是用户可以自定义实现SourceFunction(非并行化)接口或者实现ParallelSourceFunction(并行化)接口 如果需要有状态管理还可以继承RichParallelSourceFunction
File-based
- readTextFile(path)
Reads(once) text files, i.e. files that respect the TextInputFormat specification, line-by-line and returns them as Strings.
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
val text:DataStream[String]=env.readTextFile("hdfs://hbase:9000/demo/word/words")
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
4> (is,1)
3> (good,1)
4> (day,1)
1> (this,1)
2> (demo,1)
4> (day,2)
3> (good,2)
3> (study,1)
2> (up,1)
- readFile(fileInputFormat,path)
Reads (once) files as dictated by the specified file input format.
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
var inputFormat:FileInputFormat[String]=new TextInputFormat(null)
val text:DataStream[String]=env.readFile(inputFormat,"hdfs://hbase:9000/demo/word/words")
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split(","))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
4> (is,1)
3> (good,1)
4> (day,1)
1> (this,1)
2> (demo,1)
4> (day,2)
3> (good,2)
3> (study,1)
2> (up,1)
- readFile(fileInputFormat,path,watchType,interval,pathFilter,typeInfo)
This is the method called internally by the two previous ones. It reads files in the path based on the
given fileInputFormat . Depending on the provided watchType , this source may periodically
monitor (every interval ms) the path for new data
( FileProcessingMode.PROCESS_CONTINUOUSLY ), or process once the data currently in the path
and exit ( FileProcessingMode.PROCESS_ONCE ). Using the pathFilter , the user can further
exclude files from being processed
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
var inputFormat:FileInputFormat[String]=new TextInputFormat(null)
val text:DataStream[String]=env.readFile(inputFormat,"hdfs://hbase:9000/demo/word/words"
,FileProcessingMode.PROCESS_CONTINUOUSLY,1000)// PROCESS_ONCE
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split(","))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
2> (demo,1)
4> (is,1)
2> (up,1)
4> (day,1)
1> (this,1)
3> (good,1)
4> (day,2)
3> (good,2)
3> (study,1)
该方法会检查采集目录下的文件 如果文件发生变换系统会重新采集 此时可能会导致文件的重复计算 一般来说不建议修改文件内容 直接上传文件即可
Socket Based
- socketTextStream
从socket读取 元素可以用分割符分割
Reads from a socket. Elements can be separated by a delimiter
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
val text = env.socketTextStream("hbase",9999,'\n',3)
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
2> (hello,1)
4> (flink,1)
3> (,1)
1> (spark,1)
Collection-based
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
val text = env.fromCollection(List("this is demo","hello flink"))
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
4> (flink,1)
4> (is,1)
1> (this,1)
2> (hello,1)
2> (demo,1)
UserDefinedSource
- SourceFunction-非并行化接口
class UserDefinedonParallelSourceFunction extends SourceFunction[String]{
@volatile //防止线程拷贝变量
var isRunning:Boolean=true
val lines:Array[String]=Array("this is demo","hello flink","spark kafka")
//在该方法中启动线程 通过sourceContext的collect方法发送数据
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
while (isRunning){
Thread.sleep(1000)
//输送数据给下游
sourceContext.collect(lines(new Random().nextInt(lines.size)))
}
}
//释放资源
override def cancel(): Unit = {
isRunning=false
}
}
- ParallelSourceFunction
class UserDefinedonParallelSourceFunction extends ParallelSourceFunction[String]{
@volatile //防止线程拷贝变量
var isRunning:Boolean=true
val lines:Array[String]=Array("this is demo","hello flink","spark kafka")
//在该方法中启动线程 通过sourceContext的collect方法发送数据
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
while (isRunning){
Thread.sleep(1000)
//输送数据给下游
sourceContext.collect(lines(new Random().nextInt(lines.size)))
}
}
//释放资源
override def cancel(): Unit = {
isRunning=false
}
}
ParallelSourceFunction-并行化接口
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream -细化
val text = env.addSource[String](new UserDefinedonParallelSourceFunction) //⽤户定义的SourceFunction
//3.执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制台打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
Kafka集成-重点
- 引依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.10.0version>
dependency>
SimpleStringSchema
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val props = new Properties()
props.setProperty("bootstrap.servers", "hbase:9092")
props.setProperty("group.id", "g1")
val text = env.addSource(new FlinkKafkaConsumer[String]("topic01",new
SimpleStringSchema(),props))
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
- 执行脚本
[root@hbase kafka_2.11-2.2.0]# ./bin/kafka-console-producer.sh --broker-list hbase:9092 --topic topic01
>hello flink
>spark
- 测试结果
2> (hello,1)
4> (flink,1)
1> (spark,1)
KafkaDeserializationSchema
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.flink.api.scala._
class UserDefinedKafkaDeserializationSchema extends KafkaDeserializationSchema[(String,String,Int,Long)]{
//流计算不会读到结尾 永远都是false
override def isEndOfStream(t: (String, String, Int, Long)): Boolean = false
//返回的值 反序列化规划
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String, Int, Long) = {
//添加以下代码 防止报错 判断key是否为空
if(consumerRecord.key()!=null){
(new String(consumerRecord.key()),new String(consumerRecord.value()),consumerRecord.partition(),consumerRecord.offset())
}else{
(null,new String(consumerRecord.value()),consumerRecord.partition(),consumerRecord.offset())
}
}
override def getProducedType: TypeInformation[(String, String, Int, Long)] = {
createTypeInformation[(String, String, Int, Long)]
}
}
//1.创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建kafka连接条件
val props = new Properties()
props.setProperty("bootstrap.server","hbase")
props.getProperty("group.id","g1")
//2.创建DataStream -细化
val text=env.addSource(new FlinkKafkaConsumer[String,String,Int,Long]("topic01",new UserDefinedKafkaDeserializationSchema(),props))
//3.执行DS的转换算子
val counts=text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算结果打印控制台
counts.print()
//5.执行流计算任务
env.execute("Window Stream WordCount")
(null,this is a kafka,0,30)
1> (this,6)
1> (kafka,5)
3> (a,3)
4> (is,6)
JSONKeyValueNodeDeserializationSchema
要求kafka中的topic的key和value都必须是json格式 也可以在使用的时候 指定是否读取元数据(topic 分区 offset等)
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val props = new Properties()
props.setProperty("bootstrap.servers", "hbase:9092")
props.setProperty("group.id", "g1")
//{"id":1,"name":"zhangsan"}
val text = env.addSource(new FlinkKafkaConsumer[ObjectNode]("topic01",new
JSONKeyValueDeserializationSchema(true),props))
//3.执⾏DataStream的转换算⼦
/*t:{"value":{"id":1,"name":"zhangsan"},"metadata":{"offset":0,"topic":"topic01","partition":13}}*/
val counts = text
.map(t=>(t.get("value").get("id").asInt(),t.get("value").get("name").asText()))
.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
[root@hbase kafka_2.11-2.2.0]# ./bin/kafka-console-producer.sh --broker-list hbase:9092 --topic topic01
>{"id":1,"name":"zhangsan"}
#测试结果
1> (1,zhangsan)
Data Sinks
Data Sink使用DataStreams并将其转发到文件 Socket 外部系统或者打印它们 Flink带有多种内置输出格式 这些格式封装在DataStreams的操作后面
File-based
- writeAsText()/
TextOutputFormat
Writes elements line-wise as Strings. The Strings are obtained by calling the toString() method of each element.
- writeAsCsv(…)/
CsvOutputFormat
Writes tuples as comma-separated value files. Row and field delimiters are configurable. The value for each field comes from the toString() method of the objects.
- writeUsingOutputFormat/
FileOutputFormat
Method and base class for custom file outputs. Supports custom object-to-bytes conversion.
注意:DataStream上的write*()方法主要用于调试目的
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.socketTextStream("hbase", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.writeUsingOutputFormat(new TextOutputFormat[(String, Int)](new
Path("D:\\flink-results")))
//5.执⾏流计算任务
env.execute("Window Stream WordCount")

注意事项:如果改成HDFS,需要⽤户⾃⼰产⽣⼤量数据,才能看到测试效果,原因是因为HDFS⽂件系统写⼊时的缓冲区⽐较⼤。以上写⼊⽂件系统的Sink不能够参与系统检查点,如果在⽣产环境下通常使⽤flink-connector-filesystem写⼊到外围系统
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.10.0version>
dependency>
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
var bucketingSink=StreamingFileSink.forRowFormat(new
Path("hdfs://hbase:9000/bucket-results"),
new SimpleStringEncoder[(String,Int)]("UTF-8"))
.withBucketAssigner(new DateTimeBucketAssigner[(String, Int)]("yyyy-MM-dd"))//动态产⽣写⼊路径
.build()
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.addSink(bucketingSink)
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
老版本写法
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)
//2.创建DataStream - 细化
val text = env.readTextFile("hdfs://hbase:9000/demo/words")
var bucketingSink=new BucketingSink[(String,Int)]("hdfs://hbase:9000/bucket-results")
bucketingSink.setBucketer(new DateTimeBucketer[(String,Int)]("yyyy-MM-dd"))
bucketingSink.setBatchSize(1024)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
print() /printToErr()
Prints the toString() value of each element on the standard out / standard error stream. Optionally, a
prefix (msg) can be provided which is prepended to the output. This can help to distinguish between
di!erent calls to print . If the parallelism is greater than 1, the output will also be prepended with the
identifier of the task which produced the output.
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)
//2.创建DataStream - 细化
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
var bucketingSink=new BucketingSink[(String,Int)]("hdfs://hbase:9000/bucket-results")
bucketingSink.setBucketer(new DateTimeBucketer[(String,Int)]("yyyy-MM-dd"))
bucketingSink.setBatchSize(1024)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
counts.printToErr("测试").setParallelism(2)
//5.执⾏流计算任务
env.execute("Window Stream WordCount")

UserDefinedSinkFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
class UserDefinedSinkFunction extends RichSinkFunction[(String,Int)]{
override def open(parameters: Configuration): Unit = {
println("打开链接...")
}
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
println("输出:"+value)
}
override def close(): Unit = {
println("释放连接")
}
}
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)
//2.创建DataStream - 细化
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
var bucketingSink=new BucketingSink[(String,Int)]("hdfs://hbase:9000/bucket-results")
bucketingSink.setBucketer(new DateTimeBucketer[(String,Int)]("yyyy-MM-dd"))
bucketingSink.setBatchSize(1024)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
counts.addSink(new UserDefinedSinkFunction)
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
RedisSink
参考:https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
引依赖
org.apache.bahir
flink-connector-redis_2.11
1.0
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//2.创建DataStream - 细化
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
//redis的连接参数
var flinkJeidsConf = new FlinkJedisPoolConfig.Builder()
.setHost("hbase")
.setPort(6379)
.build()
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
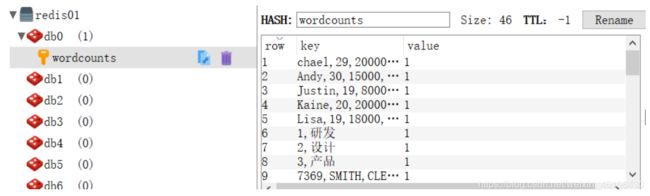
counts.addSink(new RedisSink(flinkJeidsConf,new UserDefinedRedisMapper()))
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
flinkJeidsConf:连接参数
UserDefinedRedisMapper:输入的数据类型映射成redis的K,V 需要mapper
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand,RedisCommandDescription, RedisMapper}
//(String, Int)映射的类型
class UserDefinedRedisMapper extends RedisMapper[(String, Int)] {
//以何种类型存储数据
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "wordcounts")
}
override def getKeyFromData(data: (String, Int)): String = data._1 //key
override def getValueFromData(data: (String, Int)): String = data._2 + "" //value 变成字符串
}
启动redis
[root@hbase redis-3.2.9]# ./src/redis-server redis.conf
Kafka集成-重点
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.10.0version>
dependency>
方案一
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema
import org.apache.kafka.clients.producer.ProducerRecord
class UserDefinedKafkaSerializationSchema extends KafkaSerializationSchema[(String,Int)]{
override def serialize(t: (String, Int), timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
return new ProducerRecord("topic",t._1.getBytes(),t._2.toString.getBytes())
}
}
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建datastream
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
//创建kafka连接参数
val props = new Properties()
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hbase:9092")
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"100")
props.setProperty(ProducerConfig.LINGER_MS_CONFIG,"500")
//Semantic.EXACTLY_ONCE:开启kafka幂等写特性
//Semantic.AT_LEAST_ONCE:开启Kafka Retries机制 反复
val kafkaSink = new FlinkKafkaProducer[(String,Int)](
"defult_topic",
new UserDefinedKafkaSerializationSchema,
props,
Semantic.AT_LEAST_ONCE)
//执行datastream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
counts.addSink(kafkaSink)
//执行流计算
env.execute("wordcount")
启动kafka并消费
./bin/kafka-console-consumer.sh --bootstrap-server hbase:9092 --topic topic02 --group g1 --property print.key=true --property print.value=true --property key.separator=,
defult_topic没有任何意义
方案2-老版本
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema
class UserDefinedKafkaSerializationSchema extends KeyedSerializationSchema[(String,Int)]{
override def serializeKey(t: (String, Int)): Array[Byte] = {
t._1.getBytes()
}
override def serializeValue(t: (String, Int)): Array[Byte] = {
t._2.toString.getBytes()
}
//可以覆盖 默认是topic 如果返回null 则将数据写入到默认的topic中
override def getTargetTopic(t: (String, Int)): String = {
null
}
}
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建datastream
val text = env.readTextFile("hdfs://hbase:9000/demo/word")
//创建kafka连接参数
val props = new Properties()
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hbase:9092")
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"100")
props.setProperty(ProducerConfig.LINGER_MS_CONFIG,"500")
//Semantic.EXACTLY_ONCE:开启kafka幂等写特性
//Semantic.AT_LEAST_ONCE:开启Kafka Retries机制 反复
val kafkaSink = new FlinkKafkaProducer[(String,Int)](
"defult_topic",
new UserDefinedKafkaSerializationSchema,
props,
Semantic.AT_LEAST_ONCE)
//执行datastream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
counts.addSink(kafkaSink)
//执行流计算
env.execute("wordcount")
查看是否生成默认topic
[root@hbase kafka_2.11-2.2.0]# ./bin/kafka-topics.sh --bootstrap-server hbase:9092 --list
__consumer_offsets
defult_topic
topic01
topic02
topic03
Operators
DataStream Transformations
DataStream --> DataStream
Map
Takes one element and produces one element. A map function that doubles the values of the input stream:
取一个元素并产生一个元素 一个映射函数 将输入流的值加倍
dataStream.ma{x=>x * 2}
FlatMap
Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:
去一个元素并且生产0个 ,1 个或者多个元素 flatmap函数 可以将句子分割成单词
dataStream.flatMap{str => str.split(" ")}
Filter
Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
为每个元素求布尔函数的值 并保留函数返回true的元素 过滤出0值得过滤器
dataStream.filter{_ ! =0}
DataStream* --> DataStream
Union
Union of two or more data streams creating a new stream containing all the elements from all the streams. Note: If you union a data stream with itself you will get each element twice in the resulting stream.
两个或多个数据流的并集 创建包含来自所有流的所有元素 的新流 注意:如果你将一个数据流与它子集相结合 您将得到两次结果流中的每个元素
dataStream.union(otherStream1, otherStream2, ...)
DataStream,DataStream --> ConnectedStreams
connect
“Connects” two data streams retaining their types, allowing for shared state between the two streams.
连接两个数据流 保持它们的类型 允许两个流之间
共享状态
someStream:DataStream[Int]=...
otherStream:DataStream[String]=...
val connectedStreams = someStream.connect(otherStream)
ConnectedStreams --> DataStream
CoMap,CoFlatMap
Similar to map and flatMap on a connected data stream
类似于连接数据流上的map和flatMap
connetedStreams.map(
(_:Int)=>true,
(_:String)=>false
)
connectedStreams.flatMap(
(_:Int)=>true,
(_:String)=>false
)
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建datastream
val text1 = env.socketTextStream("hbase",9999)
val text2 = env.socketTextStream("hbase",8888)
//执行datastream的转换算子
text1.connect(text2)
.flatMap((line:String)=>line.split("\\s+"),(line:String)=>line.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.print("总数")
//执行流计算
env.execute("wordcount")
[root@hbase ~]# nc -lk 9999
hello spark
[root@hbase ~]# nc -lk 8888
this flink
总数:4> (flink,1)
总数:2> (hello,1)
总数:1> (spark,1)
总数:1> (this,1)
DataStream --> SplitStream
Split
Split the stream into two or more streams according to some criterion.
根据某些标准将流分为两个或多个流
val split = someDataStream.split(
(num:Int)=>
(num%2) match{
case 0 => List("even")
case 1 => List("odd")
}
)
SplitStream --> DataStream
Select
Select one or more streams from a split stream.
从拆分流中选择一个或多个流
val even = split.select("even")
val odd = split.select("odd")
val all = split.select("all")
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建datastream
val text1 = env.socketTextStream("hbase",9999)
//执行datastream的转换算子
val splitStream = text1.split(line=>{
if(line.contains("error")){
List("error")
}else{
List("info")
}
})
splitStream.select("error").printToErr("错误")
splitStream.select("info").print("信息")
splitStream.select("error","info").print("All")
//执行流计算
env.execute("wordcount")
[root@hbase ~]# nc -lk 9999
error
info
error info
All:3> error
错误:3> error
信息:2> info
All:4> info
错误:4> error info
All:1> error info
ProcessFunction
一般来说 更多使用ProcessFunction完成流的分支
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("hbase", 9999)
val errorTag = new OutputTag[String]("error")
val allTag = new OutputTag[String]("all")
val infoStream = text.process(new ProcessFunction[String, String] {
override def processElement(value: String,
ctx: ProcessFunction[String, String]#Context,
out: Collector[String]): Unit = {
if (value.contains("error")) {
ctx.output(errorTag, value) //边输出
} else {
out.collect(value) //正常数据
}
ctx.output(allTag, value) //边输出
}
})
infoStream.getSideOutput(errorTag).printToErr("错误")
infoStream.getSideOutput(allTag).printToErr("所有")
infoStream.print("正常")
//执行流计算
env.execute("wordcount")
[root@hbase ~]# nc -lk 9999
error
all
this is demo
错误:2> error
所有:2> error
所有:3> all
正常:3> all
所有:4> this is demo
正常:4> this is demo
DataStream --> KeyedStream
KeyBy
Logically partitions a stream into disjoint partitions, each partition containing elements of the same key. Internally, this is implemented with hash partitioning. See keys on how to specify keys. This transformation returns a KeyedStream.
从逻辑上将流划分为不相交的分区 每个分区都包含同一key的元素 在内部 这是通过hash分区实现的 有关如何指定key的信息 请参见key 此转换返回KeyedStream
dataStream.keyBy("someKey") //Key by field "someKey"
dataStream.keyBy(0) //Key by the first element of a Tuple
KeyStream->DataStream
Reduce
A “rolling” reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value.
A reduce function that creates a stream of partial sums- reduce函数创建部分和流
减少键控数据流上的
滚动将当前元素与最后一个reduce值合并 并发出新的值
keyedStream.reduce(_+_)
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines = env.socketTextStream("hbase",9999)
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy("_1")
.reduce((v1,v2)=>(v1._1,v1._2+v2._2))
.print()
//执行流计算
env.execute("wordcount")
[root@hbase ~]# nc -lk 9999
hello spark
flink spark
1> (spark,1)
2> (hello,1)
4> (flink,1)
1> (spark,2)
Fold-折叠
A “rolling” fold on a keyed data stream with an initial value. Combines the current element with the last folded value and emits the new value.
A fold function that, when applied on the sequence (1,2,3,4,5), emits the sequence “start-1”, “start-1-2”, “start-1-2-3”, …
具有初始值的键控数据流上的 滚动 折叠 将当前元素与最后折叠的值组合并且输出新值
当作用于序列(1,2,3,4,5)时 发出序列"start-1",“start-1-2”,“start-1-2-3”,“start-1-2-3…”
val result:DataStream[String]=keyedStream.fold("start")((str,i)=>{
str+"-"+i
})
//创建流计算环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines = env.socketTextStream("hbase",9999)
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy("_1")
.fold((null:String,0:Int))((z,v)=> (v._1,v._2+z._2))
.print()
//执行流计算
env.execute("wordcount")
[root@hbase ~]# nc -lk 9999
this is flink
is hello
1> (this,1)
4> (is,1)
4> (flink,1)
2> (hello,1)
4> (is,2)
Aggregations
Rolling aggregations on a keyed data stream. The difference between min and minBy is that min returns the minimum value, whereas minBy returns the element that has the minimum value in this field (same for max and maxBy)
在键控数据流上滚动聚合 min和minBy之间的区别是 min返回最小值 而minBy返回该字段中具有最小值的元素(max和maxBy也是如此)
keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")
keyedStream.minBy(0)
keyedStream.minBy("key")
keyedStream.maxBy(0)
keyedStream.maxBy("key")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines = env.socketTextStream("hbase",9999)
//海绵宝宝,后勤部,1000.0
//蟹老板,销售部,60000.0
//派大星,研发部,900.0
lines.map(line=>line.split("\\s+"))
.map(ts=>Emp(ts(0),ts(1),ts(2).toDouble))
.keyBy("dept")
.maxBy("salary")
.print()
//执行流计算
env.execute("wordcount")
如果使用max 则返回的是 Emp(蟹老板,销售部,60000.0)
Physical partitioning
Flink还通过以下function对转换后的DataStream进行分区(如果需要)
Rebalancing(Round-robin partitioning):
分区元素轮循 从而为每个分区创建相等的负载 在存在数据偏斜的情况下对性能优化有用
dataStream.rebalance()
Random partitioning
根据均匀分布对元素进行随机划分
dataStream.shuffle()
Rescaling
和Roundrobin Partitioning一样 Rescaling Partitioning也是一种通过循环的方式进行数据重平衡的分区策略 但是不同的是 当使用Roundrobin Partitioning时 数据会全局性地通过网络介质传输到其他的节点完成数据的重新平衡 而Rescaling Partitioning仅仅会对上下游继承的算子数据进行重平衡 具体的分区主要根据上下游算子的并行度决定 例如上游算子的并发度为2 下游算子的并行度为4 就会发生上游算子中一个分区的数据按照同等比例将数据路由在下游的固定的两个分区中 另外一个分区同理由到下游两个分区中
dataStream.rescale()
Broadcasting
Broadcasts elements to every partition.
向每个分区广播元素
dataStream.broadcast
Custom partitioning
Selects a subset of fields from the tuples
从元组中选择字段的子集
dataStream.partitionCustom(partitioner,"someKey")
dataStream.partitionCustom(partitioner,0)
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("hbase",9999)
.map((_,1))
.partitionCustom(new Partitioner[String] {
override def partition(key:String,numPartitions:Int):Int={
key.hashCode & Integer.MAX_VALUE % numPartitions
}
},_._1)
.print()
.setParallelism(4)
println(env.getExecutionPlan)
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data Source","contents":"Source: Socket Stream","parallelism":1},{"id":2,"type":"Map","pact":"Operator","contents":"Map","parallelism":4,"predecessors":[{"id":1,"ship_strategy":"REBALANCE","side":"second"}]},{"id":4,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":4,"predecessors":[{"id":2,"ship_strategy":"CUSTOM","side":"second"}]}]}
3> (hello flink,1)
Task chaining and resource groups
对两个子操作进行Chain 意味着将这两个算子放置了一个线程中 这样是为了没必要的线程开销 提升性能 如果可能的话 默认情况下Flink会连接运算符 例如用户可以调回
StreamExecutionEnvironment.disableOperatorChaining()
禁用chain行为 但是不推荐
startNewChain
someStream.filter(...)
.map(...)
.startNewChain()
.map(...)
将第一map算子和fliter算子进行隔离
disableChaining
someStream.map(...).disableChaining()
所有操作符禁止和map操作符进行chain
slotSharingGroup
设置操作的slot共享组。 Flink会将具有相同slot共享组的operator放在同⼀个Task slot中,同时将没有slot
共享组的operator保留在其他Task slot中。这可以⽤来隔离Task Slot。下游的操作符会⾃动继承上游资源
组。默认情况下,所有的输⼊算⼦的资源组的名字是 default ,因此当⽤户不对程序进⾏资源划分的
情况下,⼀个job所需的资源slot,就等于最⼤并⾏度的Task。
someStream.filter(...).slotSharingGroup("name")
State&Fault Tolerance-重点
Flink是一个基于状态计算的流计算服务 Flink将所有的状态分为两大类:keyed state与operator state 所谓的keyed state指的是Flink底层会给每一个key绑定若干个类型的状态值 特指操作KeyedStream中涉及的状态 所谓operator state指的是非keyed stream中所涉及状态的operator state 所有的operator state会将状态和具体某个操作符进行绑定 无论是keyed state还是operator state flink将这些状态管理底层分为两种存储形式:Managed State和Raw state
Managed State-所谓的Managed State 指的是有flink控制状态存储结构 例如:状态数据结构 数据类型等 由于是flink子集管理状态 因此Flink可以更好的针对于管理状态做内存的优化和故障恢复
Raw State-所谓的Raw state 指的是flink对状态的信息和结构一无所知 flink仅仅知道该状态是一些二进制字节数组 需要用户自己完成状态序列化和反序列化 因此Raw State flink不能够针对性的做内存优化 也不支持故障状态的恢复 因此在flink实战项目开发中 几乎不使用Raw state
All datastream functions can use managed state, but the raw state interfaces can only be used when
implementing operators. Using managed state (rather than raw state) is recommended, since with
managed state Flink is able to automatically redistribute state when the parallelism is changed, and
also do better memory management.
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/state.html
Managed Keyed State(管理状态)
flink中的managed keyed state 接口提供访问不同数据类型状态 这些状态都是和key进行绑定的 这意味着这种状态只能在KeyeStream上使用 flink内建以下六中类型的state:
| 类型 | 使用场景 | 方法 |
|---|---|---|
| ValueState | 该状态用于存储单一状态值 | T value() update(T) clear() |
| ListState | 该状态主要用于存储单集合状态值 | add(T) addAll(List) update(List) lterable() get() clear() |
| MapState |
该状态主要用于存储一个Map集合 | put(UK,UV) putAll(Map) get(UK) entries() keys() values() clear() |
| ReducingState | 该状态主要用于存储单一状态值 该状态会将添加的元素和历史状态自动做运算 调用用户提供的ReduceFunction | add(T) T get() clear() |
| AggregatingState |
该状态主要用于存储单一状态值 该状态会将添加的元素和历史状态自动做运算 调用用户提供的AggregatingFunction 该状态和ReducingState不同点在于数据输入和输出类型可以不一致 | add(T) OUT get() clear() |
| FoldingState |
该状态主要用于存储单一状态值 该状态会将添加的元素和历史状态自动做运算 调用用户提供的FoldFunction 该状态和ReducingState不同点在于数据输入和中间结果类型可以不一致 | add(T) T get() clear() |
It is important to keep in mind that these state objects are only used for interfacing with state. The state is not necessarily stored inside but might reside on disk or somewhere else. The second thing to keep in mind is that the value you get from the state depends on the key of the input element. So the value you get in one invocation of your user function can differ from the value in another invocation if the keys involved are different.
To get a state handle, you have to create aStateDescriptor. This holds the name of the state (as we will see later, you can create several states, and they have to have unique names so that you can reference them), the type of the values that the state holds, and possibly a user-specified function, such as aReduceFunction. Depending on what type of state you want to retrieve, you create either aValueStateDescriptor , aListStateDescriptor , a ReducingStateDescriptor , a FoldingStateDescriptor or a MapStateDescriptor.
State is accessed using the RuntimeContext , so it is only possible in rich functions . Please see here for information about that, but we will also see an example shortly. The RuntimeContext that is available in a RichFunction has these methods for accessing state:
务必记住 这些状态对象仅用于与状态交互 状态不一定存储在内部 但可能驻留在磁盘或者其他地方 要记住得第二件事是 从状态获取得值取决于输入元素的键 因此 如果涉及的键不同 那么在一次用户函数调用中得到的值可能与另一次调用中得到的值不同
要获取处理状态 你必须创建一个
状态描述符(StateDescriptor)这是在保存状态名字(我们稍后会看到 你可以创建多个状态 它们必须有唯一的名字 这样你猜可以引用它们) 保存值得状态类型 也可能是用户指定的函数 比如ReduceFunction这取决于你想要得到的状态类型 创建以下任一ValueStateDescriptor,ListStateDescriptor,ReducingStateDescriptor,FoldingStateDescriptor或者MapStateDescriptor.因此只有在函数中才有可能 使用
RuntimeContext访问状态 请看关于这里的信息 很快就会看到一个例子 在RichFunction中可用的’RuntimeContext有以下方法来访问状态:
-
ValueState getState(ValueStateDescriptor)
-
ReducingState getReducingState(ReducingStateDescriptor)
-
ListState getListState(ListStateDescriptor)
-
AggregatingState getAggregatingState(AggregatingStateDescriptor)
-
FoldingState getFoldingState(FoldingStateDescriptor)
-
MapState getMapState(MapStateDescriptor)
ValueState
object FlinkWordCountValueState {
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.socketTextStream("hbase", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.map(new WordCountMapFunction)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Stream WordCount")
}
}
class WordCountMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
var vs:ValueState[Int]=_
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
val vsd = new ValueStateDescriptor[Int]("wordcount", createTypeInformation[Int])
//2.获取RuntimeContext
var context: RuntimeContext = getRuntimeContext
//3.获取指定类型状态
vs=context.getState(vsd)
}
override def map(value: (String, Int)): (String, Int) = {
//获取历史值
val historyData = vs.value()
//更新状态
vs.update(historyData+value._2)
//返回最新值
(value._1,vs.value())
}
}
[root@hbase ~]# nc -lk 9999
this
this is demo
this is flink
1> (this,1)
4> (is,1)
4> (flink,1)
1> (this,2)
1> (this,3)
2> (demo,1)
4> (is,2)
ListState
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._ //asScala asJava转换
object FlinkWordCountValueState {
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.socketTextStream("hbase", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.map(line=>line.split("\\s+"))
.map(ts=>(ts(0)+":"+ts(1),ts(2)))
.keyBy(0)
.map(new UserVisitedMapFunction)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Stream WordCount")
}
}
class UserVisitedMapFunction extends RichMapFunction[(String,String),(String,String)]{
var userVisited:ListState[String]=_
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
val lsd = new ListStateDescriptor[String]("userVisited",
createTypeInformation[String])
//2.获取RuntimeContext
var context: RuntimeContext = getRuntimeContext
//3.获取指定类型状态
userVisited=context.getListState(lsd)
}
override def map(value: (String, String)): (String, String) = {
//获取历史值
var historyData = userVisited.get().asScala.toList
//更新状态
historyData = historyData.::(value._2).distinct
userVisited.update(historyData.asJava)
//返回最新值
(value._1,historyData.mkString(" | "))
}
}
[root@hbase ~]# nc -lk 9999
001 zhangsan 电子类 xxxx
002 lisi 手机类 xxxx
001 zhangsan 母婴类 xxxx
3> (001:zhangsan,电子类)
3> (002:lisi,手机类)
3> (001:zhangsan,母婴类 | 电子类)
MapState
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
//用户访问map状态
object FlinkUserVisitedMapState {
def main(args: Array[String]): Unit = {
//创建流计算的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建DataStream 001 zhangsan 电⼦类 xxxx 001 zhangsan ⼿机类 xxxx 001 zhangsan ⺟婴类 xxxx
val text = env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts=text.map(line=>line.split("\\s+"))
.map(ts=>(ts(0)+":"+ts(1),ts(2))) //ts(0)001 ts(1)zhangsan t(2)电子类
.keyBy(0)
.map(new UserVisitedMapFunction)
//将计算的结果在控制台打印
counts.print()
//执行流计算任务
env.execute("Stream WordCount")
}
}
class UserVisitedMapFunction extends RichMapFunction[(String,String),(String,String)]{
var userVisitedMap:MapState[String,Int]=_
override def open(parameters: Configuration): Unit = {
//创建对应状态描述符
val msd = new MapStateDescriptor[String,Int]("UserVisitedMap",createTypeInformation[String],createTypeInformation[Int])
//获取RuntimeContext
var context:RuntimeContext = getRuntimeContext
//获取指定类型状态
userVisitedMap=context.getMapState(msd)
}
override def map(value: (String, String)): (String, String) = {
var count=0
//获取历史值
if(userVisitedMap.contains(value._2)){
count=userVisitedMap.get(value._2)
}
userVisitedMap.put(value._2,count+1)
//更新状态
var historyList = userVisitedMap.entries()
.asScala
.map(entry=>entry.getKey+":"+entry.getValue)
.toList
//返回最新值
(value._1,historyList.mkString(" | "))
}
}
[root@hbase ~]# nc -lk 9999
001 zhangsan 电子类 xxxx
001 zhangsan 电子类 xxxx
001 lisi 手机类 xxxx
001 zhangsan 母婴类 xxxx
3> (001:zhangsan,电子类:1)
3> (001:zhangsan,电子类:2)
3> (001:lisi,手机类:1)
3> (001:zhangsan,电子类:2 | 母婴类:1)
ReducingState
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object FlinkWordCountReduceState {
def main(args: Array[String]): Unit = {
//创建流计算执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//创建DataStream
val text=env.socketTextStream("hbase",9999)
//执行DataStream转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.map(new WordCountReduceStateMapFunction)
//将计算结果打印
counts.print()
//执行流计算任务
env.execute("Stream WordCount")
}
}
class WordCountReduceStateMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
var rs:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
//创建对应状态描述符
val rsd = new ReducingStateDescriptor[Int]("reducingStateDescriptor",
new ReduceFunction[Int](){
override def reduce(v1: Int, v2: Int): Int = {
v1+v2
}
},createTypeInformation[Int])
//获取runtimeContext
var context:RuntimeContext = getRuntimeContext
//获取指定类型状态
rs = context.getReducingState(rsd)
}
override def map(value: (String, Int)): (String, Int) = {
//获取历史值 更新状态
rs.add(value._2)
//返回新值
(value._1,rs.get())
}
}
[root@hbase ~]# nc -lk 9999
this flink
hello spark
hello word
1> (spark,1)
2> (hello,1)
3> (word,1)
2> (hello,2)
AggregtingState
import org.apache.flink.api.common.functions.{AggregateFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object FlinkUserOrderAggregatingState {
def main(args: Array[String]): Unit = {
//创建流计算执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
val counts = text.map(line=>line.split("\\s+"))
.map(ts=>(ts(0)+":"+ts(1),ts(2).toDouble))
.keyBy(0)
.map(new UserOrderAggregatingStateMapFunction)
//控制台打印
counts.print()
env.execute("wordCount")
}
}
class UserOrderAggregatingStateMapFunction extends RichMapFunction[(String,Double),
(String,Double)]{
var as:AggregatingState[Double,Double]=_
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
val asd = new AggregatingStateDescriptor[Double,(Int,Double),Double] ("userOrderAggregatingStateMapFunction",
new AggregateFunction[Double,(Int,Double),Double](){
override def createAccumulator(): (Int, Double) = (0,0.0)
override def add(value: Double, accumulator: (Int, Double)): (Int, Double) = {
(accumulator._1+1,accumulator._2+value)
}
override def getResult(accumulator: (Int, Double)): Double = {
accumulator._2/accumulator._1
}
override def merge(a: (Int, Double), b: (Int, Double)): (Int, Double) = {
(a._1+b._1,a._2+b._2)
}
},createTypeInformation[(Int,Double)])
//获取runtimecontext
var context : RuntimeContext = getRuntimeContext
//3.获取指定类型状态
as=context.getAggregatingState(asd)
}
override def map(value: (String, Double)): (String, Double) = {
as.add(value._2)
//返回最新值
(value._1,as.get())
}
}
[root@hbase ~]# nc -lk 9999
001 zhangsan 1000
001 zhangsan 800
3> (001:zhangsan,1000.0)
3> (001:zhangsan,900.0)
FoldingState-不是很懂
import org.apache.flink.api.common.functions.{ FoldFunction, ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{AggregatingState, FoldingStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object FlinkUserOrderAggregatingState {
def main(args: Array[String]): Unit = {
//创建流计算执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
val counts = text.map(line=>line.split("\\s+"))
.map(ts=>(ts(0)+":"+ts(1),ts(2).toDouble))
.keyBy(0)
.map(new UserOrderAvgMapFunction)
//控制台打印
counts.print()
env.execute("wordCount")
}
}
class UserOrderAvgMapFunction extends RichMapFunction[(String,Double),
(String,Double)]{
var rs:ReducingState[Int]=_
var fs:FoldingState[Double,Double]=_
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
var rsd=new ReducingStateDescriptor[Int]("reducingState",
new ReduceFunction[Int] {
override def reduce(v1: Int, v2: Int): Int = v1+v2
},createTypeInformation[Int])
val fsd = new FoldingStateDescriptor[Double,Double]("foldstate",0,new FoldFunction[Double,Double] (){
override def fold(accumulator: Double, value: Double): Double = {
accumulator+value
}
},createTypeInformation[Double])
//2.获取RuntimeContext
var context: RuntimeContext = getRuntimeContext
//3.获取指定类型状态
rs=context.getReducingState(rsd)
fs=context.getFoldingState(fsd)
}
override def map(value: (String, Double)): (String, Double) = {
rs.add(1)
fs.add(value._2)
//返回最新值
(value._1,fs.get()/rs.get())
}
}
[root@hbase ~]# nc -lk 9999
001 zhangsan 1000
001 zhangsan 800
3> (001:zhangsan,1000.0)
3> (001:zhangsan,900.0)
State Time-To-Live(TTL)-不懂
Flink支持对上有的keyed state的状态指定TTL存活时间 配置状态的时效性 该特性默认是关闭 一旦开始该特性 Fliink会尽最大努力删除过期状态 TTL支持单一值失效特性 同时也支持集合类型数据失效 例如MapState和ListState中的元素 每个元素都有自己的时效时间
基本使用
//1.创建对应状态描述符
val xsd = new XxxxStateDescriptor[Int]("wordcount",createTypeInformation[Int])
//设置TTL时效性
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间 ①
.setUpdateType(UpdateType.OnCreateAndWrite) //创建,修改重新更新时间 ②
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据 ③
.build()
//启动TTL特性
xsd.enableTimeToLive(stateTtlConfig)
①:该参数指定State存活时间 必须指定
②:该参数指定State实效时间更新时机 默认值OnCreateAndWrite
- OnCreateAndWrite:只有修改操作 才会更新时间
- OnReadAndWrite:只有访问读取 修改state时间就会更新
③:设置state的可见性 默认值NeverReturnExpired
- NeverReturnExpired:永不返回过期状态
- ReturnExpiredIfNotCleanedUp: 如果flink没有删除过期的状态数据 系统会将过期的数据返回
注意:一旦用户开启了TTL特征 系统每个存储的状态数据会额外开辟8bytes(Long类型)的字节大小 用于存储state时间戳 系统的时效时间目前仅仅支持的是计算节点时间 如果程序一开始没有开启TTL 在服务重启以后 开启了TTL 此时服务在故障恢复的时候 会报错
Cleanup of Expired State 清楚过期状态
Flink默认仅仅当用户读状态的时候 才会去检查状态数据是否失效 如果失效将失效的数据立即删除 但就会导致在长时间运行的时候 会存在很多数据已经过期了 但是系统又没有去读取过期的状态数据 该数据一直驻留在内存中
This means that by default if expired state is not read, it won’t be removed, possibly leading to ever
growing state. This might change in future releases. 1.9.x之前说法
在flink-1.10版本中 系统可以根据State backend配置 定期在后台收集失效状态进行删除 用户可以通过调用以下API关闭自动清理
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.disableCleanupInBackground()
.build()
早期版本需要用户手动调用cleanupInBackground开启后台清理 flink-1.10版本该特性自动打开
Cleanup in full snapshot 快照中的清理
可以通过配置Cleanup in full snapshot机制 在系统恢复的时候或者重启的时候 系统会加载状态数据 此时会将过期的数据删除 也就意味着系统只用在重启或者恢复的时候才会加载状态快照信息
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupFullSnapshot()
.build()
缺点:需要定期关闭服务 进行服务重启 实现内存释放
Incremental cleanup 增量清理
Another option is to trigger cleanup of some state entries incrementally. The trigger can be a callback
from each state access or/and each record processing. If this cleanup strategy is active for certain
state, The storage backend keeps a lazy global iterator for this state over all its entries. Every time
incremental cleanup is triggered, the iterator is advanced. The traversed state entries are checked
and expired ones are cleaned up.
用户还可以使用增量清理策略 在用户每一次读取或者写入状态数据的时候 该清理策略会运行一次 系统的state backend会持有所有状态的一个全局迭代器 每一次当用户访问状态 该迭代器就会增量迭代一个批次数据 检查是否存在过期的数据 如果存在就删除
//设置TTL实效性
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupIncrementally(100,true)
.build()
- cleanupSize:表示一次检查key的数目
- runCleanupForEveryRecord:是否在有数据的数据就触发检查 如果为false 表示只有在状态访问或者修改的时候才会触发检查
The first one is number of checked state entries per each cleanup triggering. It is always triggered per
each state access. The second parameter defines whether to trigger cleanup additionally per each
record processing. The default background cleanup for heap backend checks 5 entries without
cleanup per record processing
Notes:
- 如果没有状态访问或者记录处理 过期的数据依旧不会删除 会被持久化
- 增量检查state 会带来记录处理延迟
- 目前增量式的清理仅仅在支持
Heap state backend如果是RocksDB该配置不起作用
CleanupDuring RockDB compaction
如果用户使用的是RocksDB作为状态后端实现 用户可以在RocksDB在做Compation的时候加入Filter 对过期的数据进行检查 删除过期数据
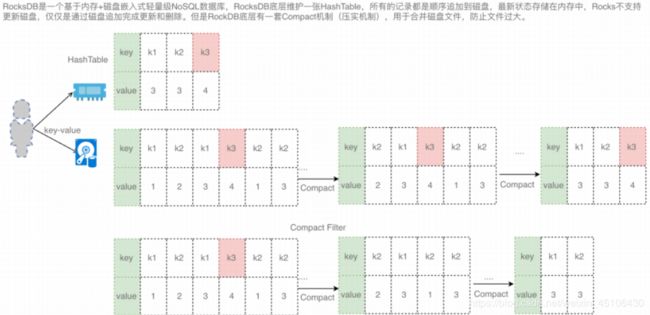
RocksDB periodically runs asynchronous compactions to merge state updates and reduce storage.
Flink compaction filter checks expiration timestamp of state entries with TTL and excludes expired
values
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupInRocksdbCompactFilter(1000)
.build()
- queryTimeAfterNumEntries:RocksDB进行合并扫描多少条记录后 执行一次查询 将过期数据删除
更频繁的更新时间戳可以提高清楚数据 但由于使用本地代码中的JNI调用 因此会降低压缩性能 每次处理1000个条目时 RocksDB后端的默认后台清理都会查询当前时间戳
Updating the timestamp more o"en can improve cleanup speed but it decreases compaction
performance because it uses JNI call from native code. The default background cleanup for RocksDB
backend queries the current timestamp each time 1000 entries have been processed.
Note
在flink-1.10版本之前 RocksDB的Compact Filter特性是关闭的 需要额外的开启 用户只需在flink-conf.yaml中添加如下配置
state.backend.rocksdb.ttl.compaction.filter.enabled: true
This feature is disabled by default. It has to be firstly activated for the RocksDB backend by setting
Flink configuration option
state.backend.rocksdb.ttl.compaction.filter.enabledor bycalling
RocksDBStateBackend::enableTtlCompactionFilterif a custom RocksDB statebackend is created for a job.
Checkpoint&Savepoint-不懂
由于Flink是一个有状态计算的流服务 因此状态的管理和容错是非常重要的 为了保证程序的健壮性 Flink提出Checkpoint机制 该机制用于持久化计算节点的状态数据 继而实现Flink故障恢复 所谓的Checkpoint机制指的是Flink会定期的持久化的状态数据 将状态数据持久化到远程文件系统(取决于State backend) 例如HDFS 该检查点协调或者发起是由JobManager负责实施 JobManager会定期向下游的计算节点发送Barrier(栅栏) 下游计算接地但收到该Barrier信号之后 会预先提交自己的状态信息 并且给JobManager以应答 同时会继续将数据收到Barrier继续传递给下游的任务节点 一次内推 所有的下游计算节点在收到该Barrier信号的时候都会做预提交自己的状态信息 等到所有的下游节点都完成了状态的预提交 并且JobManager收集完成所有下游节点的应答之后 JobManager才会认定此次的Checkpoint是成功的 并且会自动删除上一次检查点数据
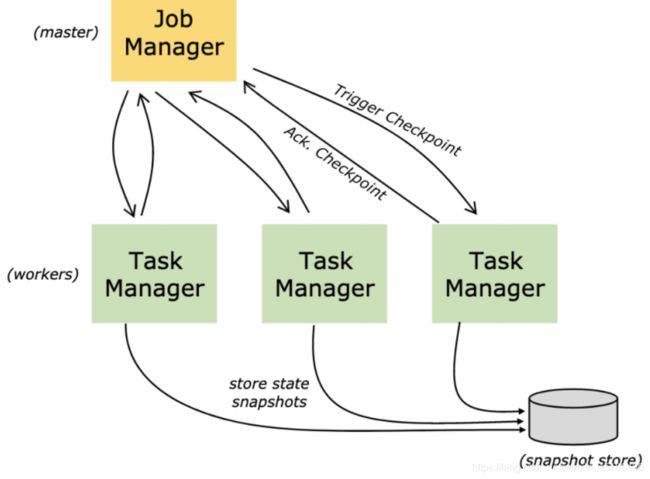
Savepoint是手动触发的Checkpoint Savepoint为程序创建快照并将其写到State Backend Savepoint依靠常规的Checkpoint机制 所谓的Checkpoint指的是程序在执行期间 程序会定期在工作节点上快照并产生Checkpoint 为了进行恢复 仅需要获取最后一次完成的Checkpoint即可 并且可以在新的Checkpoint完成后立即安全地丢弃较旧的Checkpoint
Savepoint与这些定期Checkpoint类似 Savepoint由用户触发并且更新的Checkpoint完成时不会自动过期 用户可以使用命令行通过REST API取消作业时创建Savepoint
由于Flink中的Checkpoint机制默认时不开启的 需要用户通过调用以下方法开启检查点机制
env.enableCheckpointing(1000)
为了控制检查点执行的一些细节 Flink支持用户定制Checkpoint的一些行为
//间隔5s执行一次checkpoint 精确一次
env.enableCheckPointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时 4s
env.getCheckpointConfig.setCheckpointTimeout(4000)
//开启本次检查点 与上一次完成的检查点时间间隔不得小于 2s 优先级高于 checkpoint interval
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//如果检查点失败 任务宣告退出 setFailOnCheckpointingErrors(true)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置如果任务取消 系统该如何处理检查点数据
//RETAIN_ON_CANCELLATION:如果取消任务的时候 没有加--savepoint 系统会保留检查点数据
//DELETE_ON_CANCELLATION:取消任务 自动是删除检查点(不建议使用)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.REETAIN_ON_CANCELLATION)
State Backend
Flink指定多种State Backend实现 State Backend指定了状态数据 (检查点数据) 存储的位置信息 配置Flink的状态后端的方式有两种:
- 每个计算独立状态后端
val env = StreamExecutionEnviroment.getExecutionEnviroment()
env.setStateBackend(...)
- 全局默认状态后端 需要在flink-conf.yaml配置
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# .
#
state.backend: rocksdb
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs:///flink-checkpoints
# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs:///flink-savepoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
state.backend.incremental: false
Node
由于状态后端需要将数据同步到HDFS 因此Flink必须能够连接HDFS 所以需要在~/.bashrc配置HADOOP_CLASSPATH
JAVA_HOME=/usr/java/latest
HADOOP_HOME=/usr/hadoop-2.9.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export CLASSPATH
export PATH
export HADOOP_HOME
export HADOOP_CLASSPATH=`hadoop classpath`
MemoryStateBackend(jobmanager)
MemoryStateBackend使用内存存储内部状态数据 将状态数据存储在Java的heap中 在Checkpoint时候 此状态后端将对该状态进行快照 并将其作为检查点确认消息的一部分发送给JobManager(主服务器) 该JobManager也将其存储在其堆中
val env = StreamExecutionEnvironment.getExecutionEvironment()
env.setStateBackend(new MemoryStateBackend(MAX_MEM_STATE_SIZE,true))
限制:
-
The size of each individual state is by default limited to 5 MB. This value can be increased in the
constructor of the MemoryStateBackend.
-
Irrespective of the configured maximal state size, the state cannot be larger than the akka frame size
(see Configuration ).
-
The aggregate state must fit into the JobManager memory.
**场景: **① 本地部署进行debug调试的可以使用 ② 不涉及太多的状态管理
FsStateBackend(filesystem)
该种状态后端实现是将数据的状态存储在TaskManager(计算节点)的内存 在执行检查点的时候会将TaskManager内存的数据写入远程的文件系统 非常少量的元数据信息会存储在JobManager的内存种
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStateBackend(new FsStateBackend("hdfs:///flink-checkpoints",true))
场景: ① 当用户有非常大的状态需要管理 ② 所有生产环境
RocksDBStateBackend(rocksdb)
该种状态后端实现是将数据的状态存储在TaskManager(计算节点)的本地RocksDB数据文件中 在执行检查点的时候会将TaskManager本地的RocksDB数据库写入远程的文件系统 非常少量的元数据信息会存储在JobManager的内存中
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_2.11artifactId>
<version>1.10.0version>
dependency>
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new RocksDBStateBackend("hdfs:///flink-rocksdb-checkpoints",true))
限制:
- As RocksDB’s JNI bridge API is based on byte[], the maximum supported size per key and per value is 2^31 bytes each. IMPORTANT: states that use merge operations in RocksDB (e.g. ListState) can silently accumulate value sizes > 2^31 bytes and will then fail on their next retrieval. This is currently a limitation of RocksDB JNI.
场景 : ① 当用户有超大的状态需要管理 ② 所有生产环境
Note that the amount of state that you can keep is only limited by the amount of disk space
available. This allows keeping very large state, compared to the FsStateBackend that keeps state in memory. This also means, however, that the maximum throughput that can be achieved will be lower with this state backend. All reads/writes from/to this backend have to go through de- /serialization to retrieve/store the state objects, which is also more expensive than always working with the on-heap representation as the heap-based backends are doing.
Managed Operator State(操作符状态)-不懂
Flink提供了基于keyed stream操作符状态为keyed state 对于一些非keyed stream地操作中使用地状态统称为Operator State 如果用户希望使用Operator State需要实现通用的CheckpointedFunction接口或者ListCheckpointed
CheckpointedFunction
其中CheckpointedFunction接口提供non-keyed-state的不同状态分发策略 用户在实现该接口的时候需要实现以下两个方法:
public interface CheckpointedFunction {
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception; }
- snapshotState:当系统进行Checkpoint的时候 系统回调用该方法 通常用户需要将持久化的状态数据存储到状态中
- initializeState:当第一次启动的时候系统自动调用initializeState 进行状态初始化 或者系统在故障恢复的时候进行状态的恢复
Whenever a checkpoint has to be performed,
snapshotState()is called. The counterpart,initializeState(), is called every time the user-defined function is initialized, be that when the function is first initialized or be that when the function is actually recovering from an earlier checkpoint. Given this,initializeState()is not only the place where different types of state are initialized, but also where state recovery logic is included.
当前 Operator State支持list-style的Managed State 该状态应为彼此独立的可序列化对象的列表 因此在系统故障恢复的时候才有可能进行重新分配 目前Flink针对于Operator State分配方案有以下两种:
- **Even-split redistribution -**每一个操作符实例都会保留一个List的状态 因此Operator State逻辑上是该Operator的并行实例的所有的List状态拼接成一个完成的List State 当系统在恢复 重新分发状态的时候 系统会根据当前Operator实例并行度 对当前的状态进行均分 例如 如果在并行度为1的情况下 Operator的检查点状态包含元素element1和element2 则在将Operator并行度提高到2时 elementl1可能会分配给Operator Instance0 而element2将进入Operator Instance1
- **Union redistribution - **每一个操作符实例都会保留一个List的状态 因此Operator State逻辑上是将该Operator的并行实例的所有的List状态拼接一个完成的List State 在还原/重新分发状态时 每个Operator实例都会获得状态元素的完整列表
class UserDefineBufferSinkEvenSplit(threshold: Int = 0) extends SinkFunction[(String,
Int)] with CheckpointedFunction{
@transient
private var checkpointedState: ListState[(String, Int)] = _
private val bufferedElements = ListBuffer[(String, Int)]()
//复写写出逻辑
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
bufferedElements += value
if(bufferedElements.size >= threshold){
for(e <- bufferedElements){
println("元素:"+e)
}
bufferedElements.clear()
}
}
//需要将状态数据存储起来
override def snapshotState(context: FunctionSnapshotContext): Unit = {
checkpointedState.clear()
checkpointedState.update(bufferedElements.asJava)//直接将状态数据存储起来
}
//初始化状态逻辑、状态恢复逻辑
override def initializeState(context: FunctionInitializationContext): Unit = {
//初始化状态、也有可能是故障恢复
val lsd=new ListStateDescriptor[(String, Int)]("liststate",createTypeInformation[(String,Int)])
checkpointedState = context.getOperatorStateStore.getListState(lsd) //默认均分⽅式恢复
//context.getOperatorStateStore.getUnionListState(lsd) //默认⼴播⽅式恢复
if(context.isRestored){ //实现故障恢复逻辑
bufferedElements.appendAll(checkpointedState.get().asScala.toList)
}
}
}
object FlinkWordCountValueStateCheckpoint {
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new RocksDBStateBackend("hdfs:///flink-rocksdbcheckpoints",true))
//间隔5s执⾏⼀次checkpoint 精准⼀次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时 4s
env.getCheckpointConfig.setCheckpointTimeout(4000)
//开启本次检查点 与上⼀次完成的检查点时间间隔不得⼩于 2s 优先级⾼于 checkpoint interval
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//如果检查点失败,任务宣告退出 setFailOnCheckpointingErrors(true)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置如果任务取消,系统该如何处理检查点数据
//RETAIN_ON_CANCELLATION:如果取消任务的时候,没有加--savepoint,系统会保留检查点数据
//DELETE_ON_CANCELLATION:取消任务,⾃动是删除检查点(不建议使⽤)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.R
ETAIN_ON_CANCELLATION)
//2.创建DataStream - 细化
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.map(new WordCountMapFunction)
.uid("wc-map")
//4.将计算的结果在控制打印
counts.addSink(new UserDefineBufferSinkEvenSplit(3))
.uid("buffer-sink")
//5.执⾏流计算任务
env.execute("Stream WordCount")
}
}
class WordCountMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
var vs:ValueState[Int]=_
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
val vsd = new ValueStateDescriptor[Int]("wordcount", createTypeInformation[Int])
//2.获取RuntimeContext
var context: RuntimeContext = getRuntimeContext
//3.获取指定类型状态
vs=context.getState(vsd)
}
override def map(value: (String, Int)): (String, Int) = {
//获取历史值
val historyData = vs.value()
//更新状态
vs.update(historyData+value._2)
//返回最新值
(value._1,vs.value())
}
}
Broadcast State Pattern
广播状态是Flink提供的第三种状态共享的场景 通常需要将一个吞吐量比较小的流中状态数据进行广播给下游的任务 另外一个流可以以只读的形式读取广播状态
第三种支持的操作符状态是广播状态 将支持来自一个流且需要广播一些数据到所有下游任务的案例引进广播状态 它存储在本地 并用于处理其他流上的所有传入元素 例如:广播状态可以自然地出现 我们希望根据来自另一个流的所有元素对这些低吞吐量流包含的一组规则进行评估 记住以下的用例类型 广播状态与其他操作符状态区别在于:
①it has a map format,
②作为输入一个广播流和一个非广播流 它只对特定的opertors可用
③这样的操作符可以具有多个不同名称的广播状态
案例剖析
DataStream连接BroadcastStream
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
//仅仅输出满足规则的数据
object FlinkBroadcastNonKeyedStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//吞吐量高
val inputs = env.socketTextStream("hbase",9999)
//定义需要广播流 吞吐量低
val bcsd = new MapStateDescriptor[String,String]("bcsd",createTypeInformation[String],createTypeInformation[String])
val broadcaststream = env.socketTextStream("hbase",8888)
.broadcast(bcsd)
val tag = new OutputTag[String]("notmatch")
val datastream = inputs.connect(broadcaststream)
.process(new UserDefineBroadcastProcessFunction(tag,bcsd))
datastream.print("满足条件")
datastream.getSideOutput(tag).print("不满足")
env.execute("window stream wordcount")
}
}
class UserDefineBroadcastProcessFunction(tag:OutputTag[String],msd:MapStateDescriptor[String
,String]) extends BroadcastProcessFunction[String,String,String]{
//处理正常流 高吞吐 通常在改法读取广播状态
override def processElement(value: String, ctx: BroadcastProcessFunction[String, String, String]#ReadOnlyContext, out: Collector[String]): Unit = {
//获取状态 只读
val readOnlyMapstate = ctx.getBroadcastState(msd)
if(readOnlyMapstate.contains("rule")){
val rule=readOnlyMapstate.get("rule")
if(value.contains(rule)){//将数据写出去
out.collect(rule+"\t"+value)
}else{
ctx.output(tag,rule+"\t"+value)
}
}else{//使⽤Side out将数据输出
ctx.output(tag,value)
}
}
//处理广播流 通常在这里修改需要广播的状态 低吞吐
override def processBroadcastElement(value: String, ctx: BroadcastProcessFunction[String, String, String]#Context, out: Collector[String]): Unit = {
val mapstate = ctx.getBroadcastState(msd)
mapstate.put("rule",value)
}
}
[root@hbase ~]# nc -lk 9999
this is spark
[root@hbase ~]# nc -lk 8888
this
[root@hbase ~]# nc -lk 9999
this is flink
hello this is window
不满足:2> this is spark
满足条件:3> this this is flink
满足条件:4> this hello this is window
KeyedStream连接BroadcastStream
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{MapStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
case class OrderItem(id: String, name: String, category: String, count: Int, price: Double)
case class Rule(category: String, threshold: Double)
case class User(id: String, name: String)
//输出满足规则的数据
object FlinkBroadcastKeyedStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
/**
* id name 品类 数量 单价 --订单项目
* 1 海绵 可比克 2 10 吞吐高
**/
val inputs = env.socketTextStream("hbase", 9999)
.map(line => line.split("\\s+"))
.map(ts => OrderItem(ts(0), ts(1), ts(2), ts(3).toInt, ts(4).toDouble))
.keyBy(orderItem => orderItem.category + ":" + orderItem.id)
/**
* 品类 阈值 --奖励
* 可比克 20 吞吐低
**/
val bcsd = new MapStateDescriptor[String, Double]("bcsd", createTypeInformation[String], createTypeInformation[Double])
val broadcaststream = env.socketTextStream("hbase", 8888)
.map(line => line.split("\\s+"))
.map(ts => Rule(ts(0), ts(1).toDouble))
.broadcast(bcsd)
inputs.connect(broadcaststream)
.process(new UserDefineKeyedBroadcastProcessFunction(bcsd))
.print("奖励")
env.execute("window stream wordcount")
}
}
//泛型:[key类型,第一个流类型,第二个流类型,输出类型]
class UserDefineKeyedBroadcastProcessFunction(msd: MapStateDescriptor[String, Double]) extends KeyedBroadcastProcessFunction[String, OrderItem, Rule, User] {
//用户消费总价
var userTotalCost: ReducingState[Double] = _
override def open(parameters: Configuration): Unit = {
//1.创建对应状态描述符
val rsd = new ReducingStateDescriptor[Double]("userTotalCost",
new ReduceFunction[Double] {
override def reduce(t: Double, t1: Double): Double = t + t1
}, createTypeInformation[Double])
//获取RuntimeContext 并且获取指定类型状态
userTotalCost = getRuntimeContext.getReducingState(rsd)
}
//处理正常流 高吞吐 通常在该方法读取广播状态
override def processElement(value: OrderItem, ctx: KeyedBroadcastProcessFunction[String, OrderItem, Rule, User]#ReadOnlyContext, out: Collector[User]): Unit = {
//计算出当前品类别下⽤户的总消费
userTotalCost.add(value.count * value.price)
val ruleState = ctx.getBroadcastState(msd)
var u = User(value.id, value.name)
//设定的有奖励规则
if (ruleState != null && ruleState.contains(value.category)) {
if (userTotalCost.get() >= ruleState.get(value.category)) { //达到了奖励阈值
out.collect(u)
userTotalCost.clear()
} else {
println("不满足条件:" + u + "当前总消费:" + userTotalCost.get() + "threshold:" + ruleState.get(value.category))
}
}
}
//处理广播流 通常在这里修改需要广播的状态 低吞吐 规则
override def processBroadcastElement(value: Rule, ctx:
KeyedBroadcastProcessFunction[String, OrderItem, Rule, User]#Context, out:
Collector[User]): Unit = {
val broadcastState = ctx.getBroadcastState(msd)
broadcastState.put(value.category, value.threshold)
}
}
[root@hbase ~]# nc -lk 8888
可比克 20
[root@hbase ~]# nc -lk 9999
1 小黑 可比克 1 10
2 张三 可比克 1 10
奖励:4> User(1,小黑)
不满足条件:User(2,张三)当前总消费:10.0threshold:20.0
Queryable State
Architecture
Client连接其中的一个代理服务区然后发送查询请求给Proxy服务器 查询指定key所对应的状态数据 底层Flink按照KeyGroup的方式管理KeyedState 这些KeyGroup被分配给了所有的TaskManager的服务 每个TaskManage服务多个KeyGroup状态的存储 为了找到查询key所在的KeyGroup所属地TaskManager服务 Proxy服务会去询问JobManager查询TaskManager的信息 然后直接访问TaskManager上的QueryableStateServer服务器获取状态数据 最后将获取的状态数据返回给Client端
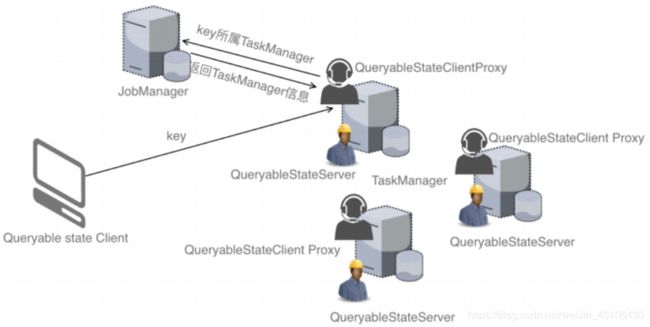
- **QueryableStateClient:**运行在Flink集群以外 负责提交用户的查询给Flink集群
- **QueryableStateClientProxy:**运行在Flink集群中的TaskManager中的一个代理服务 负责接收客户端的查询 代理负责相应TaskManager获取请求的state 并将其state返回给客户端
- **QueryableStateServer:**运行在Flink集群中的TaskManager中服务 仅仅负责读取当前TaskManage主机上存储的状态数据
The client connects to one of the proxies and sends a request for the state associated with a specific
key,
k. As stated in Working with State , keyed state is organized in Key Groups , and each
TaskManageris assigned a number of these key groups. To discover whichTaskManagerisresponsible for the key group holding
k, the proxy will ask theJobManager. Based on theanswer, the proxy will then query the
QueryableStateServerrunning on thatTaskManagerfor the state associated with
k, and forward the response back to the client.
激活 Queryable State
① 将Flink的opt/拷贝flink-queryable-state-runtime_2.11-1.10.0.jar到Flink的lib/目录
[root@hbase flink-1.10.0]# cp opt/flink-queryable-state-runtime_2.11-1.10.0.jar lib/
② 在Flink的flink-conf.yaml配置文件中添加以下配置
#========================================================================
# Queryable State
#========================================================================
queryable-state.enable: true
tip:注释是自己加上去的
③ 重启Flink服务 为了校验服务是否开启你可以查看task manager日志 可以看到Started the Queryable State Proxy Server@...
[root@hbase flink-1.10.0]# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host 主机名.
Starting taskexecutor daemon on host 主机名.
查看TaskManager启动日志
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vZhY1nOX-1584445132504)(C:\Users\YT\AppData\Roaming\Typora\typora-user-images\1583930630216.png)]
Making State Queryable
为了使State对外界可见 需要使用以下命令显示地使其可查询:
- 创建QueryableStateStream 该QueryableStateStream充当一个Sink的输出 仅仅是将数据存储到state中
- 或者stateDescriptor.setQueryable(String queryableStateName)方法使得我们的状态可查询
Queryable State Stream
用户可以调用keyedstream的.asQueryableState(stateName,stateDescriptor)方法 提供一个可以查询状态
// ValueState
QueryableStateStream asQueryableState(
String queryableStateName,
ValueStateDescriptor stateDescriptor)
// Shortcut for explicit ValueStateDescriptor variant
QueryableStateStream asQueryableState(String queryableStateName)
// FoldingState
QueryableStateStream asQueryableState(
String queryableStateName,
FoldingStateDescriptor stateDescriptor)
// ReducingState
QueryableStateStream asQueryableState(
String queryableStateName,
ReducingStateDescriptor stateDescriptor)
Note: There is no queryable
ListStatesink as it would result in an ever-growing list which may not be cleaned up and thus will eventually consume too much memory.
返回的Queryable StateStream可以看作是一个Sink 因为无法对QueryableStateStream进一步转换 在内部 QueryableStateStream被转换为运算符 该运算符使用所有传入记录来更新可查询zhua状态实例 更新逻辑由asQureyableState调用中提供的StateDescriptor的类型隐含 在类似以下的程序中 keyedstream的所有记录将通过ValueState.update(value)用于更新状态实例:
stream.keyBy(0).asQueryableState("query-name")
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.ReducingStateDescriptor
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object FlinkWordCountQueryableStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//间隔5s执行一次checkpoint 精确一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时 4s
env.getCheckpointConfig.setCheckpointTimeout(4000)
//开启本次检查点 与上一次完成的检查点时间间隔不得小于 2s 优先级高于 checkpoint interval
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//如果检查点失败 任务宣告退出 setFailOnCheckpointingErrors(true)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置如果任务取消 系统该如何处理检查点数据
//RETAIN_ON_CANCELLATION:如果取消任务的时候 没有加--savepoint 系统会保留检查点数据
//DELETE_ON_CANCELLATION:取消任务 自动删除检查点-不建议
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
var rsd = new ReducingStateDescriptor[(String,Int)]("reducestate",new ReduceFunction[(String, Int)] {
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
(v1._1,(v1._2+v2._2))
}
},createTypeInformation[(String,Int)])
env.socketTextStream("hbase",9999)
.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.asQueryableState("wordcount",rsd) //状态名字 后期查询需要
env.execute("wordcount")
}
}
Managed Keyed State
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object FlinkWordCountQueryable {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//间隔5s执行一次checkpoint 精确一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时 4s
env.getCheckpointConfig.setCheckpointTimeout(4000)
//开启本次检查点 与上一次完成的检查点时间间隔不得小于 2s 优先级高于 checkpoint interval
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//如果检查点失败 任务宣告退出 setFailOnCheckpointingErrors(true)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置如果任务取消 系统该如何处理检查点数据
//RETAIN_ON_CANCELLATION:如果取消任务的时候 没有加--savepoint 系统会保留检查点数据
//DELETE_ON_CANCELLATION:取消任务 自动删除检查点-不建议
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
var rsd = new ReducingStateDescriptor[(String,Int)]("reducestate",new ReduceFunction[(String, Int)] {
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
(v1._1,(v1._2+v2._2))
}
},createTypeInformation[(String,Int)])
env.socketTextStream("hbase",9999)
.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.asQueryableState("wordcount",rsd) //状态名字 后期查询需要
env.execute("wordcount")
}
}
class WordCountMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
var vs:ValueState[Int]=_
override def open(parameters: Configuration): Unit = {
//创建对应状态描述符
val vsd = new ValueStateDescriptor[Int]("wordcount",createTypeInformation[Int])
vsd.setQueryable("query-wordcount")
//获取runtimecongtext
val context: RuntimeContext = getRuntimeContext
//获取指定类型状态
vs = context.getState(vsd)
}
override def map(value: (String, Int)): (String, Int) = {
//获取历史值
val historyData = vs.value()
//更新状态
vs.update(historyData+value._2)
//返回最新值
(value._1,vs.value())
}
}
Querying State
- 引依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>1.10.0version>
dependency> <dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-queryable-state-client-javaartifactId>
<version>1.10.0version>
dependency>
- 查询代码
import org.apache.flink.api.common.JobID
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.queryablestate.client.QueryableStateClient
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.createTypeInformation
object QueryState {
def main(args: Array[String]): Unit = {
//连接proxy服务器
val client = new QueryableStateClient("hbase",9069)
var jobID = JobID.fromHexString("5d3bc73f5cf410f3a5daa8d5d9eb6160")
var queryName="wordcount" //状态名字
var queryKey = "this" //用户需要查询的key
var rsd = new ReducingStateDescriptor[(String,Int)]("reducestate",new ReduceFunction[(String, Int)] {
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
(v1._1,(v1._2+v2._2))
}
},createTypeInformation[(String,Int)])
val resultFuture = client.getKvState(jobID,queryName,queryKey,createTypeInformation[String],rsd)
//同步获取结果
val state: ReducingState[(String, Int)] = resultFuture.get()
println("结果"+state.get())
client.shutdownAndWait()
}
}
[root@hbase ~]# nc -lk 9999
this is demo
flink
this flink
结果(this,2)
Process finished with exit code 0
异步获取结果
import java.util.function.Consumer
import org.apache.flink.api.common.JobID
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.queryablestate.client.QueryableStateClient
import org.apache.flink.streaming.api.scala.createTypeInformation
object QueryState {
def main(args: Array[String]): Unit = {
//连接proxy服务器
val client = new QueryableStateClient("hbase",9069)
var jobID = JobID.fromHexString("5d3bc73f5cf410f3a5daa8d5d9eb6160")
var queryName="wordcount" //状态名字
var queryKey = "this" //用户需要查询的key
var rsd = new ReducingStateDescriptor[(String,Int)]("reducestate",new ReduceFunction[(String, Int)] {
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
(v1._1,(v1._2+v2._2))
}
},createTypeInformation[(String,Int)])
val resultFuture = client.getKvState(jobID,queryName,queryKey,createTypeInformation[String],rsd)
//异步获取结果
resultFuture.thenAccept(new Consumer[ReducingState[(String, Int)]] {
override def accept(t: ReducingState[(String, Int)]): Unit = {
println("结果:"+t.get())
}
})
Thread.sleep(10000)
client.shutdownAndWait()
}
}
Windows
窗口计算是流计算的核心 窗口将流数据切分成有限大小的 buckets 我们可以对这个 buckets 中的有限数据做运算
Windows are at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size, over which we can apply computations.
在Flink中整体将窗口计算按分为两大类:keyedstream窗口 datastream窗口 以下是代码结构:
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- 必须指定: "window assigner"
[.trigger(...)] <- 可选: "trigger" (else default trigger) 决定了窗⼝何
时触发计算
[.evictor(...)] <- 可选: "evictor" (else no evictor) 剔除器,剔除窗⼝内
的元素
[.allowedLateness(...)] <- 可选: "lateness" (else zero) 是否允许有迟到
[.sideOutputLateData(...)] <- 可选: "output tag" (else no side output for late
data)
.reduce/aggregate/fold/apply() <- 必须: "Window Function" 对窗⼝的数据做运算
[.getSideOutput(...)] <- 可选: "output tag" 获取迟到的数据
Non-Keyed Windows
stream
.windowAll(...) <- 必须指定: "window assigner"
[.trigger(...)] <- 可选: "trigger" (else default trigger) 决定了窗⼝何
时触发计算
[.evictor(...)] <- 可选: "evictor" (else no evictor) 剔除器,剔除窗⼝内
的元素
[.allowedLateness(...)] <- 可选: "lateness" (else zero) 是否允许有迟到
[.sideOutputLateData(...)] <- 可选: "output tag" (else no side output for late
data)
.reduce/aggregate/fold/apply() <- 必须: "Window Function" 对窗⼝的数据做运算
[.getSideOutput(...)] <- 可选: "output tag" 获取迟到的数据
Window Lifecycle(生命周期)
当有第一个元素落入到窗口中的时候窗口就被创建 当时间(水位线)越过窗口的EndTime的时候 该窗口认定为是就绪状态 可以应用WindowFunction对窗口中的元素进行运算 当前的时间(水位线)越过了窗口的EndTime+allowed lateness时间 该窗口会被删除 只有time-based window才有生命周期的概念 因为Flink还有一种类型的窗口global window不是基于时间的 因此没有生命周期的概念
In a nutshell, a window is created as soon as the first element that should belong to this window arrives, and the window is completely removed when the time (event or processing time) passes its end timestamp plus the user-specified allowed lateness (see Allowed Lateness ). Flink guarantees removal only for time-based windows and not for other types, e.g. global windows
例如 采用基于Event-Time的窗口化策略 该策略每5分钟创建一次不重叠(或翻滚)的窗口 并允许延迟为1分钟 Flink将为12:00至12:05之间的间隔创建一个新窗口:当带有时间戳的第一个元素落入此时间间隔时中 且水位线经过12:06时间戳时 12:00至12:05窗口将被删除
每一种窗口都有一个Trigger和function与之绑定 function的作用是用于对窗口中的内容实现运算 而Trigger决定了窗口什么时候是就绪的 因为只有就绪的窗口才会运用function做运算
In addition, each window will have a
Trigger(see Triggers ) and a function (ProcessWindowFunction,ReduceFunction,AggregateFunctionorFoldFunction) (see Window Functions ) attached to it. The function will contain the computation to be applied to the contents of the window, while theTriggerspecifies the conditions under which the window is considered ready for the function to be applied.
除了指定以上的策略以外 我们还可以指定Evictor 该Evictor可以在窗口就绪以后且在function运行之前或者之后删除窗口中的元素
Apart from the above, you can specify an Evictor (see Evictors ) which will be able to remove elements from the window a"er the trigger fires and before and/or a"er the function is applied.
Keyed VS Non-Keyed Windows
keyed windows:在某一时刻 会触发多个window任务 取决于key的种类
Non-Keyed windows:因为没有key概念 所以任何时刻只有一个window任务执行
In the case of keyed streams, any attribute of your incoming events can be used as a key (more details here ). Having a keyed stream will allow your windowed computation to be performed in parallel by multiple tasks, as each logical keyed stream can be processed independently from the rest. All elements referring to the same key will be sent to the same parallel task. In case of non-keyed streams, your original stream will not be split into multiple logical streams and all the windowing logic will be performed by a single task, i.e. with parallelism of 1.
Window Assigners(分配)
Window Assigner定义了如何将元素分配给窗口 这是通过window(...)/windowAll()指定一个Window Assigners实现
The window assigner defines how elements are assigned to windows. This is done by specifying the
WindowAssignerof your choice in thewindow(...)(for keyed streams) or thewindowAll()(for non-keyed streams) call.
Window Assigner负责接收的数据分配给1~N窗口 Flink中预定义了一些Eindow Assigner分如下tumbling windows,sliding windows,session windows和global windows 用户可以同时实现WindowAssigner类自定义窗口 除了global windows以外其他窗口都是基于时间TimeWindow Time based窗口都有start timestamp(包含)和end timestamp(排除)属性描述一个窗口的大小
Time-based windows have a start timestamp (inclusive) and an end timestamp (exclusive) that together describe the size of the window. In code, Flink uses TimeWindow when working with time-based windows which has methods for querying the start- and end-timestamp and also an additional method maxTimestamp() that returns the largest allowed timestamp for a givenwindows
Tumbling Windows-滚动
滚动窗⼝分配器将每个元素分配给指定窗⼝⼤⼩的窗⼝。滚动窗⼝具有固定的⼤⼩,并且不重叠。例如,如果您指定⼤⼩为5分钟的翻滚窗⼝,则将评估当前窗⼝,并且每五分钟将启动⼀个新窗⼝,如下图所示
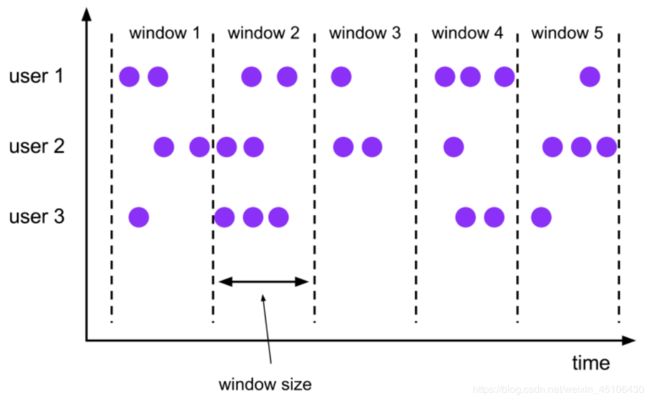
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("CentOS", 9999)
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((v1,v2)=>(v1._1,v1._2+v2._2))
.print()
env.execute("Tumbling Window Stream WordCount")
Sliding Windows-滑动
滑动窗⼝分配器将元素分配给固定⻓度的窗⼝。类似于滚动窗⼝分配器,窗⼝的⼤⼩由窗⼝⼤⼩参数配置。附加的窗⼝滑动参数控制滑动窗⼝启动的频率。因此,如果幻灯⽚⼩于窗⼝⼤⼩,则滑动窗⼝可能会重叠。在这种情况下,元素被分配给多个窗⼝。
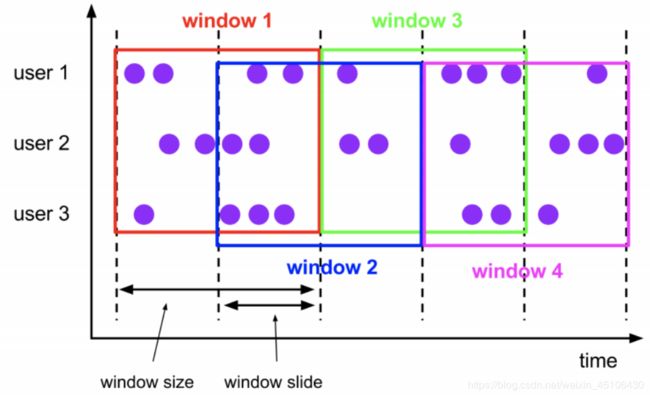
object FlinkProcessingTimeSlidingWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.window(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.aggregate(new UserDefineAggregateFunction)
.print()
//5.执⾏流计算任务
env.execute("Sliding Window Stream WordCount")
}
}
class UserDefineAggregateFunction extends AggregateFunction[(String,Int),(String,Int),
(String,Int)]{
override def createAccumulator(): (String, Int) = ("",0)
override def add(value: (String, Int), accumulator: (String, Int)): (String, Int) = {
(value._1,value._2+accumulator._2)
}
override def getResult(accumulator: (String, Int)): (String, Int) = accumulator
override def merge(a: (String, Int), b: (String, Int)): (String, Int) = {
(a._1,a._2+b._2)
}
}
Session Windows
会话窗⼝分配器按活动会话对元素进⾏分组。与滚动窗⼝和滑动窗⼝相⽐,会话窗⼝不重叠且没有固定的开始和结束时间。相反,当会话窗⼝在⼀定时间段内未接收到元素时(即,发⽣不活动间隙时),它 将关闭。

object FlinkProcessingTimeSessionWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
Global Windows
全局窗⼝分配器将具有相同键的所有元素分配给同⼀单个全局窗⼝。仅当您还指定⾃定义触发器时,此
窗⼝⽅案才有⽤。否则,将不会执⾏任何计算,因为全局窗⼝没有可以处理聚合元素的⾃然终点。
.keyBy(t=>t._1)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
.apply(new UserDefineWindowFunction)
.print()
//5.执⾏流计算任务
env.execute("Session Window Stream WordCount")
}
}
class UserDefineWindowFunction extends WindowFunction[(String,Int),
(String,Int),String,TimeWindow]{
override def apply(key: String,
window: TimeWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
var start=sdf.format(window.getStart)
var end=sdf.format(window.getEnd)
var sum = input.map(_._2).sum
out.collect((s"${key}\t${start}~${end}",sum))
}
}
Global Windows-全局
全局窗⼝分配器将具有相同键的所有元素分配给同⼀单个全局窗⼝。仅当您还指定⾃定义触发器时,此窗⼝⽅案才有⽤。否则,将不会执⾏任何计算,因为全局窗⼝没有可以处理聚合元素的⾃然终点。

object FlinkGlobalWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(GlobalWindows.create())
.trigger(CountTrigger.of(4))
.apply(new UserDefineGlobalWindowFunction)
.print()
//5.执⾏流计算任务
env.execute("Global Window Stream WordCount")
}
}
class UserDefineGlobalWindowFunction extends WindowFunction[(String,Int),
(String,Int),String,GlobalWindow]{
override def apply(key: String,
window: GlobalWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
var sum = input.map(_._2).sum
out.collect((s"${key}",sum))
}
}
Window Function
定义窗口分配器后 我们需要指定要在每个窗口上执行的计算 这是Window Function的职责 一旦系统确定窗口已准备好进行处理 就可以处理每个窗口的元素 窗口函数可以是ReduceFunction, AggregateFunction,FoldFunction、ProcessWindowFunction或WindowFunction(古董)之一 其中ReduceFunction和AggregateFunction在运行效率上比ProcessWindowFunction要高 因为前两个方法执行的是增量计算 只要有数据抵达窗口 系统就会调用ReduceFunction 只有当窗口就绪的时候才会对窗口中的元素做批量计算 但是该方法可以获取窗口的元数据信息 但是可以通过将ProcessWindowFunction与ReduceFunction,AggregateFunction或FoldFunction 结合使用来获得窗口元素的增量聚合以及ProcessWindowFunction接收的其他窗口元数据 从而减去这种情况
ReduceFunction
object FlinkProcessingTimeTumblingWindowWithReduceFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new UserDefineReduceFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineReduceFunction extends ReduceFunction[(String,Int)]{
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
println("reduce"+v1+"\t"+v2)
(v1._1,v2._2+v1._2)
}
}
[root@hbase ~]# nc -lk 9999
this is
this is demo
reduce(is,1) (is,1)
reduce(this,1) (this,1)
4> (is,2)
1> (this,2)
2> (demo,1)
AggregateFunction
object FlinkProcessingTimeTumblingWindowWithAggregateFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new UserDefineAggregateFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineAggregateFunction extends AggregateFunction[(String,Int),(String,Int),(String,Int)]{
override def createAccumulator(): (String, Int) = ("",0)
override def add(value: (String, Int), acc: (String, Int)): (String, Int) = {
println("add"+value+"\t"+acc)
(value._1,value._2+acc._2)
}
override def getResult(acc: (String, Int)): (String, Int) = acc
override def merge(acc: (String, Int), acc1: (String, Int)): (String, Int) = {
println("merge"+acc+"\t"+acc1)
(acc._1,acc._2+acc1._2)
}
}
[root@hbase ~]# nc -lk 9999
hello flink
hello spark
add(spark,1) (,0)
add(hello,1) (,0)
add(hello,1) (hello,1)
add(flink,1) (,0)
4> (flink,1)
2> (hello,2)
1> (spark,1)
FoldFunction
object FlinkProcessingTimeTumblingWindowWithAggregateFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.fold(("",0),new UserDefineFoldFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineFoldFunction extends FoldFunction[(String,Int),(String,Int)]{
override def fold(t: (String, Int), o: (String, Int)): (String, Int) = {
println("fold"+t+"\t"+o)
(o._1,t._2+o._2)
}
}
[root@hbase ~]# nc -lk 9999
hello flink
hello spark
fold(,0) (hello,1)
fold(,0) (flink,1)
2> (hello,1)
4> (flink,1)
fold(,0) (hello,1)
fold(,0) (spark,1)
1> (spark,1)
2> (hello,1)
注意:FoldFunction不可以用在Session Window中
ProcessWindowFunction
object FlinkProcessingTimeTumblingWindowWithAggregateFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new UserDefineProcessWindowFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineProcessWindowFunction extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
val sdf=new SimpleDateFormat("HH:mm:ss")
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val w = context.window //获取窗口元素
val start = sdf.format(w.getStart)
val end = sdf.format(w.getEnd)
val total = elements.map(_._2).sum
out.collect((key+"\t["+start+"~"+end+"]",total))
}
}
[root@hbase ~]# nc -lk 9999
this is flink
this is spark
4> (is [21:08:30~21:08:35],2)
1> (this [21:08:30~21:08:35],2)
4> (flink [21:08:30~21:08:35],1)
1> (spark [21:08:30~21:08:35],1)
ProcessWindowFunction & Reduce/Aggregte/Fold
object FlinkProcessingTimeTumblingWindowWithReduceFucntionAndProcessWindowFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new UserDefineReduceFunction,new UserDefineProcessWindowFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineProcessWindowFunction extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
val sdf=new SimpleDateFormat("HH:mm:ss")
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val w = context.window //获取窗口元素
val start = sdf.format(w.getStart)
val end = sdf.format(w.getEnd)
val list = elements.toList
println("list"+list)
val total = list.map(_._2).sum
out.collect((key+"\t["+start+"~"+end+"]",total))
}
}
class UserDefineReduceFunction extends ReduceFunction[(String,Int)]{
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
println("reduce:"+v1+"\t"+v2)
(v1._1,v2._2+v1._2)
}
}
[root@hbase ~]# nc -lk 9999
hello world
hello flume
reduce:(hello,1) (hello,1)
listList((hello,2))
listList((flume,1))
listList((world,1))
2> (hello [21:16:15~21:16:20],2)
3> (world [21:16:15~21:16:20],1)
4> (flume [21:16:15~21:16:20],1)
Per(线)-window state In ProcessWindowFunction
object FlinkProcessingTimeTumblingWindowWithProcessWindowFunctionState {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new UserDefineProcessWindowFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineProcessWindowFunction extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
val sdf=new SimpleDateFormat("HH:mm:ss")
var wvsd:ValueStateDescriptor[Int]=_
var gvsd:ValueStateDescriptor[Int]=_
override def open(parameters: Configuration): Unit = {
wvsd= new ValueStateDescriptor[Int]("ws",createTypeInformation[Int])
gvsd=new ValueStateDescriptor[Int]("gs",createTypeInformation[Int])
}
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val w = context.window //获取窗口元素
val start = sdf.format(w.getStart)
val end = sdf.format(w.getEnd)
val list = elements.toList
val total = list.map(_._2).sum
var wvs : ValueState[Int]=context.windowState.getState(wvsd)
var gvs : ValueState[Int]=context.globalState.getState(gvsd)
wvs.update(wvs.value()+total)
gvs.update(gvs.value()+total)
println("Window Count"+wvs.value()+"\t"+"Global Count"+gvs.value())
out.collect((key+"\t["+start+"~"+end+"]",total))
}
}
[root@hbase ~]# nc -lk 9999
this is
this is demo
Window Count2 Global Count2
Window Count2 Global Count2
1> (this [21:23:35~21:23:40],2)
4> (is [21:23:35~21:23:40],2)
Window Count1 Global Count1
2> (demo [21:23:35~21:23:40],1)
WindowFunction(Legacy-古董)
在某些可以使用ProcessWindowFunction的地方 你也可以使用WindowFunction 这是ProcessWindowFunction的较久版本 提供的上下文信息较少 并且没有某些高级功能 例如:每个窗口的Keyed State
object FlinkProcessingTimeSessionWindowWithWindowFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new UserDefineWindowFunction)
.print()
env.execute("Tumbling window stream")
}
}
class UserDefineWindowFunction extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def apply(key: String,
window: TimeWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
var start = sdf.format(window.getStart)
var end = sdf.format(window.getEnd)
var sum = input.map(_._2).sum
out.collect((s"${key}\t${start}\t${end}",sum))
}
}
[root@hbase ~]# nc -lk 9999
hello spark
hello flink
1> (spark 21:32:00 21:32:05,1)
4> (flink 21:32:00 21:32:05,1)
2> (hello 21:32:00 21:32:05,2)
Trigger(触发器)
Trigger决定了什么时候窗口准备就绪 一旦窗口准备就绪就可以使用WindowFunction进行计算 每一个WindowAssigner都会有一个默认的Trigger 如果默认的Trigger不满足用户的需求 用户可以自定义Trigger
A
Triggerdetermines when a window (as formed by the window assigner ) is ready to be processed by the window function . EachWindowAssignercomes with a default Trigger . If the default trigger does not fit your needs, you can specify a custom trigger usingtrigger(...).
| 窗口类型 | 触发器 | 触发时机 |
|---|---|---|
| EventTime(Tumblng/Sliding/Session) | EvenTimeTrigger | 一旦Watermarker没过窗口的EndTime 该窗口认定为就绪 |
| ProcessingTime(Tumblng/Sliding/Session) | ProcessingTimeTrigger | 一旦计算节点系统时钟没过窗口的EndTime该触发器便触发 |
| ClobalWindow | NeverTrigger | 永不触发 |
触发器接口具有五种方法 这些方法允许触发器对不同时间做出反应:
public abstract class Trigger implements Serializable {
/**
只要有元素落⼊到当前窗⼝, 就会调⽤该⽅法
* @param element 收到的元素
* @param timestamp 元素抵达时间.
* @param window 元素所属的window窗⼝.
* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.
*/
public abstract TriggerResult onElement(T element, long timestamp, W window,
TriggerContext ctx) throws Exception;
/**
* processing-time 定时器回调函数
*
* @param time 定时器触发的时间.
* @param window 定时器触发的窗⼝对象.
* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.
*/
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext
ctx) throws Exception;
/**
* event-time 定时器回调函数
*
* @param time 定时器触发的时间.
* @param window 定时器触发的窗⼝对象.
* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.
*/
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx)
throws Exception;
/**
* 当 多个窗⼝合并到⼀个窗⼝的时候,调⽤该⽅法,例如系统SessionWindow
* {@link org.apache.flink.streaming.api.windowing.assigners.WindowAssigner}.
*
* @param window 合并后的新窗⼝对象
* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime)回调以及访问
状态
*/
public void onMerge(W window, OnMergeContext ctx) throws Exception {
throw new UnsupportedOperationException("This trigger does not support merging.");
}
/**
* 当窗⼝被删除后执⾏所需的任何操作。例如:可以清除定时器或者删除状态数据
*/
public abstract void clear(W window, TriggerContext ctx) throws Exception; }
关于上述方法 需要主要两件事
- 前三个方法决定如何通过返回TriggerResult来决定窗口是否就绪
public enum TriggerResult {
/**
* 不触发,也不删除元素
*/
CONTINUE(false, false),
/**
* 触发窗⼝,窗⼝出发后删除窗⼝中的元素
*/
FIRE_AND_PURGE(true, true),
/**
* 触发窗⼝,但是保留窗⼝元素
*/
FIRE(true, false),
/**
* 不触发窗⼝,丢弃窗⼝,并且删除窗⼝的元素
*/
PURGE(false, true);
private final boolean fire;//是否触发窗⼝
private final boolean purge;//是否清除窗⼝元素
...
}
2)这些方法中的任何一种都可以用于注册处理或事件时间计时器以用来将来的操作
案例使用
object FlinkTumblingWindowWithCountTrigger {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.trigger(new UserDefineCountTrigger(4L))
.apply(new UserDefineGlobalWindowFunction)
.print()
//5.执⾏流计算任务
env.execute("Global Window Stream WordCount")
}
}
class UserDefineCountTrigger(maxCount:Long) extends Trigger[String,TimeWindow]{
var rsd:ReducingStateDescriptor[Long]=new ReducingStateDescriptor[Long]("rsd",new ReduceFunction[Long] {
override def reduce(t: Long, t1: Long): Long = t+t1
},createTypeInformation[Long])
override def onElement(element: String,
Long: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext): TriggerResult = {
val state:ReducingState[Long]=ctx.getPartitionedState(rsd)
state.add(1L)
if(state.get()>=maxCount){
state.clear()
return TriggerResult.FIRE_AND_PURGE
}else{
return TriggerResult.CONTINUE
}
}
override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
override def onEventTime(l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {
println("==clear==")
ctx.getPartitionedState(rsd).clear()
}
}
DeltaTrigger(学习任务)
Evictors-剔除器
Flink的窗口模型允许除了WindowAssigner和Trigger之外还指定一个可选的Evictor 可以使用evictor(…)方法来完成此操作 Evictors可以在触发器触发后 应用Window Function之前或之后从窗口中删除元素
public interface Evictor<T, W extends Window> extends Serializable {
/**
* 在调⽤windowing function之前被调⽤.
*
* @param 当前窗⼝中的所有元素
* @param size 当前窗⼝元素的总数
* @param window The {@link Window}
* @param evictorContext Evictor上下⽂对象
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window,
EvictorContext evictorContext);
/**
* 在调⽤ windowing function之后调⽤.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window,
EvictorContext evictorContext);
}
evictBefore()包含要在窗口函数之前应用的剔除逻辑 而evictAfter()包含要在窗口函数之后应用的剔除逻辑 应用窗口功能之前剔除的元素将不会被其处理
Fliink附带了三个预先实施的驱逐程序 这些是:
CountEvictor
从窗口中保留用户指定数量的元素 并从窗口缓冲区的开头丢弃其余的元素
private void evict(Iterable<TimestampedValue<Object>> elements, int size,EvictorContext ctx) {
if (size <= maxCount) {
return;
} else {
int evictedCount = 0;
for (Iterator<TimestampedValue<Object>> iterator = elements.iterator();
iterator.hasNext();){
iterator.next();
evictedCount++;
if (evictedCount > size - maxCount) {
break;
} else {
iterator.remove();
}
}
}
}
DeltaEvictor
采用DeltaFunction和阈值 计算窗口缓冲区中最后一个元素与其余每个元素之间的增量 并删除增量大于或等于阈值的元素
private void evict(Iterable<TimestampedValue<T>> elements, int size, EvictorContext
ctx) {
TimestampedValue<T> lastElement = Iterables.getLast(elements);
for (Iterator<TimestampedValue<T>> iterator = elements.iterator();
iterator.hasNext();){
TimestampedValue<T> element = iterator.next();
//如果最后⼀个元素和前⾯元素差值⼤于threshold
if (deltaFunction.getDelta(element.getValue(), lastElement.getValue()) >=
this.threshold) {
iterator.remove();
}
}
}
TimeEvictor
以毫秒为单位的间隔作为参数 对于给定的窗口 它将在其元素中找到最大时间戳max_ts 并删除所有时间戳小于max_ts-interval的元素 只要最新的一段时间间隔的数据
private void evict(Iterable<TimestampedValue<Object>> elements, int size,
EvictorContext ctx) {
if (!hasTimestamp(elements)) {
return;
}
//获取最⼤时间戳
long currentTime = getMaxTimestamp(elements);
long evictCutoff = currentTime - windowSize;
for (Iterator<TimestampedValue<Object>> iterator = elements.iterator();
iterator.hasNext(); ) {
TimestampedValue<Object> record = iterator.next();
if (record.getTimestamp() <= evictCutoff) {
iterator.remove();
}
}
}
private boolean hasTimestamp(Iterable<TimestampedValue<Object>> elements) {
Iterator<TimestampedValue<Object>> it = elements.iterator();
if (it.hasNext()) {
return it.next().hasTimestamp();
}
return false;
}
private long getMaxTimestamp(Iterable<TimestampedValue<Object>> elements) {
long currentTime = Long.MIN_VALUE;
for (Iterator<TimestampedValue<Object>> iterator = elements.iterator();
iterator.hasNext();){
TimestampedValue<Object> record = iterator.next();
currentTime = Math.max(currentTime, record.getTimestamp());
}
return currentTime;
}
UserDefineEvictor
import org.apache.flink.streaming.api.windowing.evictors.Evictor;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue;
import java.util.Iterator;
public class UserDefineEvictor implements Evictor<String, TimeWindow>{
private Boolean isEvictorAfter = false;
private String excludeContent = null;
public UserDefineEvictor(Boolean isEvictorAfter, String excludeContent) {
this.isEvictorAfter = isEvictorAfter;
this.excludeContent = excludeContent;
}
@Override
public void evictBefore(Iterable<TimestampedValue<String>> elements, int size, TimeWindow window, EvictorContext evictorContext) {
if(!isEvictorAfter){
evict(elements,size,window,evictorContext);
}
}
@Override
public void evictAfter(Iterable<TimestampedValue<String>> elements, int size, TimeWindow window, EvictorContext evictorContext) {
if(isEvictorAfter){
evict(elements,size,window,evictorContext);
}
}
private void evict(Iterable<TimestampedValue<String>> elements,int size,TimeWindow window,EvictorContext evictorContext) {
for(Iterator<TimestampedValue<String>> iterator = elements.iterator();iterator.hasNext();){
TimestampedValue<String> element = iterator.next();
//将包含的元素删除
if(element.getValue().contains(excludeContent)){
iterator.remove();
}
}
}
}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.AllWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkSlidingWindowWithUserDefineEvictor {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("hbase",9999)
//执行DataStream的转换算子
val counts = text.windowAll(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.evictor(new UserDefineEvictor(false,"error"))
.apply(new UserDefineSlidingWindowFunction)
.print()
//执行流计算任务
env.execute("sliding window stream wordcount")
}
}
class UserDefineSlidingWindowFunction extends AllWindowFunction[String,String,TimeWindow]{
override def apply(window: TimeWindow,
input: Iterable[String],
out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
var start = sdf.format(window.getStart)
var end = sdf.format(window.getEnd)
var windowCount = input.toList
println("window:"+start+"\t"+end+" "+windowCount.mkString("|"))
}
}
测试结果
[root@hbase ~]# nc -lk 9999
this is ok
this is error
window:13:56:56 13:57:00 this is ok
window:13:56:58 13:57:02 this is ok
window:13:57:00 13:57:04
window:13:57:06 13:57:10
EventTime Window
Flink流计算传输中支持多种时间概念:ProcessingTime/EventTime/IngestionTime
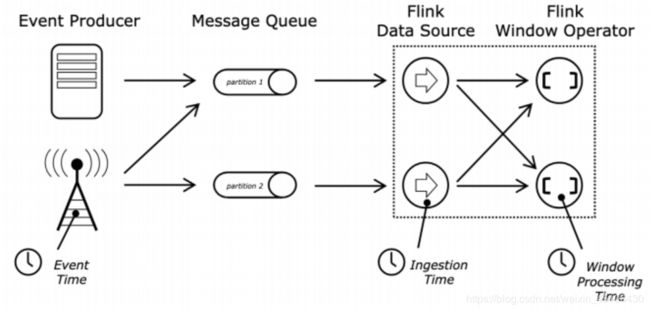
如果Flink使用的时候不做特殊设定 默认使用的是ProcessingTime 其中和ProcessingTime类似IngestionTime都是由系统自动产生 不同是是IngestionTime是由DataSource源产生而ProcessingTime由计算算子产生 因此以上两种时间策略都不能很好的表达在流计算中的事件产生时间(考虑网络传输延迟)
Flink中支持基于EventTime语义的窗口计算 Flink会使用Watermarker机制去衡量事件事件推进进度 Watermarker会在作为数据流的一部分随着数据而流动Watermarker包含有一个时间t 这就表明流中不会再有事件事件t’<=t的元素存在
#计算节点所看到的最大事件时间 - 最大允许的乱序数据
Watermarker(t)=Max event time seen by Procee Node - MaxAllowOrderless
Watermarker
在Flink中常见的水位线的计算方式:
- 固定频次计算水位线(推荐)
//用户自定义定期水位线的分配器
class UserDefineAssignerWithPeriodicWatermarks extends AssignerWithPeriodicWatermarks[(String,Long)]{
var maxAllowOrderness=2000L
var maxSeenEventTime=0L
//系统定期的调用 计算当前的水位线值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新水位线的值 同时提取EventTime
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
//始终将最大的事件返回
maxSeenEventTime = Math.max(maxSeenEventTime,element._2)
val sdf = new SimpleDateFormat("HH:mm:ss")
println("EventTime:"+(element._1,sdf.format(element._2))+"Watermarker"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._2
}
}
注意:用任意一个无穷小的值减去任意值 会向高借位 得到一个最大值 负数变正数
(Byte.MIN_VALUE-1).toByte = +127
Integer.MAX_VALUE+1 用最大值加1会得到一个小值 负数
- Per Event计算水位线(不推荐)
//用户定义不时打断水位线的分配器
class UserDefineAssignerWithPunctuatedWatermarks extends AssignerWithPunctuatedWatermarks[(String,Long)]{
var maxAllowOrderness=2000L
var maxSeenEventTime=Long.MinValue
val sdf = new SimpleDateFormat("HH:mm:ss")
//每接收一条记录 系统计算一次
override def checkAndGetNextWatermark(lastElement: (String, Long), extractedTimestamp: Long): Watermark = {
maxSeenEventTime=Math.max(maxSeenEventTime,lastElement._2)
println("EvenTime"+(lastElement._1,sdf.format(lastElement._2))+"Watermarker"+sdf.format(maxSeenEventTime-maxAllowOrderness))
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
//始终将最大的时间返回
element._2
}
}
测试案例
object FlinkEventTimeTumblingWindow{
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //方便测试
//默认事件特性是ProcessingTime 需要设置为EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置定期调用水位线频次 1s
env.getConfig.setAutoWatermarkInterval(1000)
//字符 时间戳
env.socketTextStream("hbase",9999)
.map(line=>line.split("\\s+"))
.map(ts=>(ts(0),ts(1).toLong))
.assignTimestampsAndWatermarks(new UserDefineAssignerWithPeriodicWatermarks)
.windowAll(TumblingEventTimeWindows.of(Time.seconds(2)))
.apply(new UserDefineAllWindowFunction)
.print("输出")
env.execute("Tumbling event Time window stream")
}
}
class UserDefineAllWindowFunction extends AllWindowFunction[(String,Long),String,TimeWindow]{
var sdf = new SimpleDateFormat("HH:mm:ss")
override def apply(window: TimeWindow,
input: Iterable[(String, Long)],
out: Collector[String]): Unit = {
var start = sdf.format(window.getStart)
var end = sdf.format(window.getEnd)
println(start+"~"+end+"\t"+input.map(t=>t._1+":"+sdf.format(t._2).mkString("")))
}
}
测试数据
[root@hbase ~]# nc -lk 9999
a 1584172350000
a 1584172351000
a 1584172352000
a 1584172353000
a 1584172354000
固定频次计算水位线结果
EventTime:(a,15:52:30)Watermarker15:52:28
EventTime:(a,15:52:31)Watermarker15:52:29
EventTime:(a,15:52:32)Watermarker15:52:30
EventTime:(a,15:52:33)Watermarker15:52:31
EventTime:(a,15:52:34)Watermarker15:52:32
15:52:30~15:52:32 List(a:15:52:30, a:15:52:31)
Per Event计算水位线测试结果
EvenTime(a,15:52:30)Watermarker15:52:28
EvenTime(a,15:52:31)Watermarker15:52:29
EvenTime(a,15:52:32)Watermarker15:52:30
EvenTime(a,15:52:33)Watermarker15:52:31
迟到数据
在Flink中 水位线一旦没过窗口的EndTime 这个时候如果还有数据落入到已经被水位线淹没的窗口 则定义该数据为迟到的数据 这些数据在Spark是没法进行任何处理的 在Flink中用户可以定义窗口元素的迟到时间t’
- 如果Watermarker时间t<窗口EndTime t’’ +t’ 则该数据还可以参与窗口计算
object FlinkEventTimeTumblingWindowLateData {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//默认时间特性是ProcessingTime 需要设置为EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//字符 时间戳
env.socketTextStream("hbase", 9999)
.map(line=>line.split("\\s+"))
.map(ts=>(ts(0),ts(1).toLong))
.assignTimestampsAndWatermarks(new
UserDefineAssignerWithPunctuatedWatermarks)
.windowAll(TumblingEventTimeWindows.of(Time.seconds(2)))
.allowedLateness(Time.seconds(2))
.apply(new UserDefineAllWindowFucntion)
.print("输出结果")
env.execute("Tumbling Event Time Window Stream")
}
}
class UserDefineAllWindowFucntion extends AllWindowFunction[(String,Long),String,TimeWindow]{
var sdf = new SimpleDateFormat("HH:mm:ss")
override def apply(window: TimeWindow,
input: Iterable[(String, Long)],
out: Collector[String]): Unit = {
var start=sdf.format(window.getStart)
var end=sdf.format(window.getEnd)
println("开始:"+start+"~"+"结束:"+end,input.map(t=>t._1+":"+sdf.format(t._2).mkString("")))
}
}
测试数据
[root@hbase ~]# nc -lk 9999
a 1584172351000
a 1584172352000
a 1584172353000
a 1584172354000
a 1584172355000
a 1584172356000
a1 1584172353000
EventTime(a,15:52:30)Watermarker15:52:28
EventTime(a,15:52:31)Watermarker15:52:29
EventTime(a,15:52:32)Watermarker15:52:30
EventTime(a,15:52:33)Watermarker15:52:31
EventTime(a,15:52:34)Watermarker15:52:32
(开始:15:52:30~结束:15:52:32,List(a:15:52:30, a:15:52:31))
EventTime(a,15:52:35)Watermarker15:52:33
EventTime(a,15:52:36)Watermarker15:52:34
(开始:15:52:32~结束:15:52:34,List(a:15:52:32, a:15:52:33))
EventTime(a1,15:52:33)Watermarker15:52:34
(开始:15:52:32~结束:15:52:34,List(a:15:52:32, a:15:52:33, a1:15:52:33))
- 如果Watermarker时间他>=窗口endtime t’ + t’则该数据默认情况下Flink会丢弃 当然用户可以将toolast数据通过sede out输出获取 以便用户知道哪些迟到的数据没能加入正常计算
测试数据
[root@hbase ~]# nc -lk 9999
a 1584172350000
a 1584172351000
a 1584172352000
a 1584172353000
a 1584172354000
a 1584172355000
a 1584172356000
a1 1584172353000
a 1584172357000
a 1584172358000
a1 1584172353000
测试结果
EventTime(a,15:52:30)Watermarker15:52:28
EventTime(a,15:52:31)Watermarker15:52:29
EventTime(a,15:52:32)Watermarker15:52:30
EventTime(a,15:52:33)Watermarker15:52:31
EventTime(a,15:52:34)Watermarker15:52:32
(开始:15:52:30~结束:15:52:32,List(a:15:52:30, a:15:52:31))
EventTime(a,15:52:35)Watermarker15:52:33
EventTime(a,15:52:36)Watermarker15:52:34
(开始:15:52:32~结束:15:52:34,List(a:15:52:32, a:15:52:33))
EventTime(a1,15:52:33)Watermarker15:52:34
(开始:15:52:32~结束:15:52:34,List(a:15:52:32, a:15:52:33, a1:15:52:33))
EventTime(a,15:52:37)Watermarker15:52:35
EventTime(a,15:52:38)Watermarker15:52:36
(开始:15:52:34~结束:15:52:36,List(a:15:52:34, a:15:52:35))
EventTime(a1,15:52:33)Watermarker15:52:36
迟到> (a1,1584172353000)
Joining连接
Window Join
窗口join将共享相同key并位于同一窗口中的两个流的元素连接在一起 可以使用窗口分配器定义这些窗口 并根据两个流中的元素对其进行评估 然后将双方的元素传递到用户定义的JoinFunction或FlatJoinFunction 在此用户可以发出满足连接条件的结果
stream.join(otherStream)
.where()
.equalTo()
.window()
.apply()
Note
- 创建两个流的元素的成对组合的行为就像一个内部连接 这意味着如果一个流中的元素没有与另一流中要连接的元素对应得元素 则不会发出该元素
- 那些确实加入的元素将以最大的时间戳(仍位于相应窗口中)作为时间戳 例如 以[5,10)为边界的窗口将导致连接的元素具有9作为其时间戳
Tumbling Window Join
当执行滚动窗口连接时 所有具有公共键和公共滚动窗口的元素都按成对组合连接 并传递到JoinFunction或FlatJoinFunction 因为它的行为就像一个内部连接 所以在其滚动窗口中不发射一个流中没有其他流元素的元素
When performing a tumbling window join, all elements with a common key and a common tumbling window are joined as pairwise combinations and passed on to a
JoinFunctionorFlatJoinFunction. Because this behaves like an inner join, elements of one stream that do not have elements from another stream in their tumbling window are not emitted!
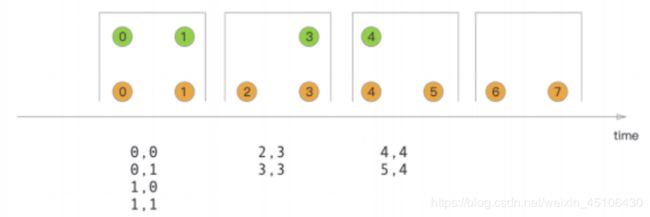
class TumblingAssignerWithPeriodicWatermarks extends
AssignerWithPeriodicWatermarks[(String,String,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println("ET:"+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
object FlinkTumblingWindowJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new TumblingAssignerWithPeriodicWatermarks)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
TumblingAssignerWithPeriodicWatermarks)
stream1.join(stream2)
.where(t=>t._1) //stream1 ⽤户ID
.equalTo(t=> t._2) //stream2 ⽤户ID
.window(TumblingEventTimeWindows.of(Time.seconds(2)))
.apply((s1,s2,out:Collector[(String,String,String)])=>{
out.collect(s1._1,s1._2,s2._1)
})
.print("join结果")
env.execute("FlinkTumblingWindowJoin")
}
}
Sliding Window Join
执⾏滑动窗⼝连接时,所有具有公共键和公共滑动窗⼝的元素都按成对组合进⾏连接,并传递给JoinFunction或FlatJoinFunction。在当前滑动窗⼝中,⼀个流中没有其他流元素的元素不会被发出.请注意,某些元素可能在⼀个滑动窗⼝中连接,但不能在另⼀个窗⼝中连接
When performing a sliding window join, all elements with a common key and common sliding window are joined as pairwise combinations and passed on to the JoinFunction or FlatJoinFunction . Elements of one stream that do not have elements from the other stream in the current sliding window are not emitted! Note that some elements might be joined in one sliding window but not in another!

class SlidlingAssignerWithPeriodicWatermarks extends
AssignerWithPeriodicWatermarks[(String,String,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println("ET:"+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
object FlinkSlidlingWindowJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new SlidlingAssignerWithPeriodicWatermarks)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
SlidlingAssignerWithPeriodicWatermarks)
stream1.join(stream2)
.where(t=>t._1) //stream1 ⽤户ID
.equalTo(t=> t._2) //stream2 ⽤户ID
.window(SlidingEventTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.apply((s1,s2,out:Collector[(String,String,String)])=>{
out.collect(s1._1,s1._2,s2._1)
})
.print("join结果")
env.execute("FlinkSlidlingWindowJoin")
}
}
Session Window Join
在执⾏会话窗⼝连接时,具有“组合”时满⾜会话条件的相同键的所有元素将以成对组合的⽅式连接在⼀起,并传递给JoinFunction或FlatJoinFunction。再次执⾏内部联接,因此,如果有⼀个会话窗⼝仅包含⼀个流中的元素,则不会发出任何输出!
When performing a session window join, all elements with the same key that when “combined” fulfill the session criteria are joined in pairwise combinations and passed on to the JoinFunction or FlatJoinFunction . Again this performs an inner join, so if there is a session window that only contains elements from one stream, no output will be emitted!

class SessionAssignerWithPeriodicWatermarks extends
AssignerWithPeriodicWatermarks[(String,String,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println("ET:"+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
object FlinkSessionWindowJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new SessionAssignerWithPeriodicWatermarks)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
SessionAssignerWithPeriodicWatermarks)
stream1.join(stream2)
.where(t=>t._1) //stream1 ⽤户ID
.equalTo(t=> t._2) //stream2 ⽤户ID
.window(EventTimeSessionWindows.withGap(Time.seconds(2)))
.apply((s1,s2,out:Collector[(String,String,String)])=>{
out.collect(s1._1,s1._2,s2._1)
})
.print("join结果")
env.execute("FlinkSessionWindowJoin")
}
}
Interval Join(区间join)
间隔连接使⽤公共key连接两个流(现在将它们分别称为A和B)的元素,并且流B的元素时间位于流A的元素时间戳的间隔之中,则A和B的元素就可以join
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
或者
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
interval join使用一个公共键将两个流的元素(现在我们称它们为A和B)连接起来,其中流B的元素具有时间戳,这些时间戳位于流A中元素的相对时间间隔内.
这个也可以更正式的表示为b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] – a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
其中a和b是a和b的元素.它们公用一个键.只要下界总是小于或等于上界,下界和上界都可以是负的或正的.间隔连接目前仅执行内部连接
当将一对元素传递给ProcessJoinFunction时,它们将被分配更大的时间戳(可以通过ProcessJoinFunction访问该时间戳).两个元素的上下文
Note- interval连接目前只支持事件时间
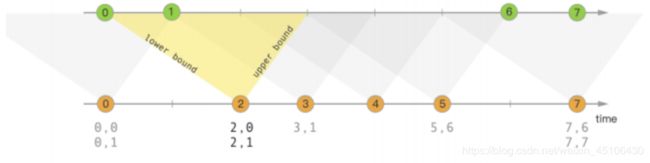
class IntervaAssignerWithPeriodicWatermarks extends
AssignerWithPeriodicWatermarks[(String,String,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println("ET:"+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
object FlinkIntervalJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new IntervaAssignerWithPeriodicWatermarks)
.keyBy(t=>t._1)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
IntervaAssignerWithPeriodicWatermarks)
.keyBy(t=>t._2)
stream1.intervalJoin(stream2)
.between(Time.seconds(0),Time.seconds(2))//默认是边界包含
//.lowerBoundExclusive() 排除下边界
//.upperBoundExclusive() 排除上边界
.process(new ProcessJoinFunction[(String,String,Long),
(String,String,Long),String] {
override def processElement(left: (String, String, Long),
right: (String, String, Long),
ctx: ProcessJoinFunction[(String, String,
Long), (String, String, Long), String]#Context,
out: Collector[String]): Unit = {
println("l:"+ctx.getLeftTimestamp+" "+"r:"+ctx.getRightTimestamp+",t:"+ctx.getTimestamp)
out.collect(left._1+" "+left._2+" "+right._1)
}
})
.print()
env.execute("FlinkIntervalJoin")
}
}
ring,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”)
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println(“ET:”+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
```scala
object FlinkSessionWindowJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new SessionAssignerWithPeriodicWatermarks)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
SessionAssignerWithPeriodicWatermarks)
stream1.join(stream2)
.where(t=>t._1) //stream1 ⽤户ID
.equalTo(t=> t._2) //stream2 ⽤户ID
.window(EventTimeSessionWindows.withGap(Time.seconds(2)))
.apply((s1,s2,out:Collector[(String,String,String)])=>{
out.collect(s1._1,s1._2,s2._1)
})
.print("join结果")
env.execute("FlinkSessionWindowJoin")
}
}
Interval Join(区间join)
间隔连接使⽤公共key连接两个流(现在将它们分别称为A和B)的元素,并且流B的元素时间位于流A的元素时间戳的间隔之中,则A和B的元素就可以join
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
或者
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
interval join使用一个公共键将两个流的元素(现在我们称它们为A和B)连接起来,其中流B的元素具有时间戳,这些时间戳位于流A中元素的相对时间间隔内.
这个也可以更正式的表示为b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] – a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
其中a和b是a和b的元素.它们公用一个键.只要下界总是小于或等于上界,下界和上界都可以是负的或正的.间隔连接目前仅执行内部连接
当将一对元素传递给ProcessJoinFunction时,它们将被分配更大的时间戳(可以通过ProcessJoinFunction访问该时间戳).两个元素的上下文
Note- interval连接目前只支持事件时间
[外链图片转存中…(img-hEdaeEWT-1584445132523)]
class IntervaAssignerWithPeriodicWatermarks extends
AssignerWithPeriodicWatermarks[(String,String,Long)] {
var maxAllowOrderness=2000L
var maxSeenEventTime= 0L //不可以取Long.MinValue
var sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//系统定期的调⽤ 计算当前的⽔位线的值
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenEventTime-maxAllowOrderness)
}
//更新⽔位线的值,同时提取EventTime
override def extractTimestamp(element: (String,String, Long),
previousElementTimestamp: Long): Long = {
//始终将最⼤的时间返回
maxSeenEventTime=Math.max(maxSeenEventTime,element._3)
println("ET:"+(element._1,element._2,sdf.format(element._3))+"
WM:"+sdf.format(maxSeenEventTime-maxAllowOrderness))
element._3
}
}
object FlinkIntervalJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//001 zhansgan 时间戳
val stream1 = env.socketTextStream("CentOS", 9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new IntervaAssignerWithPeriodicWatermarks)
.keyBy(t=>t._1)
//apple 001 时间戳
val stream2 = env.socketTextStream("CentOS", 8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new
IntervaAssignerWithPeriodicWatermarks)
.keyBy(t=>t._2)
stream1.intervalJoin(stream2)
.between(Time.seconds(0),Time.seconds(2))//默认是边界包含
//.lowerBoundExclusive() 排除下边界
//.upperBoundExclusive() 排除上边界
.process(new ProcessJoinFunction[(String,String,Long),
(String,String,Long),String] {
override def processElement(left: (String, String, Long),
right: (String, String, Long),
ctx: ProcessJoinFunction[(String, String,
Long), (String, String, Long), String]#Context,
out: Collector[String]): Unit = {
println("l:"+ctx.getLeftTimestamp+" "+"r:"+ctx.getRightTimestamp+",t:"+ctx.getTimestamp)
out.collect(left._1+" "+left._2+" "+right._1)
}
})
.print()
env.execute("FlinkIntervalJoin")
}
}