数据库-MySQL约束-笔记
MySQL约束
回顾
MySQL管理数据库
创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;
删除数据库
DROP DATABASE 数据库名;
表的管理
查看所有表
use 数据库名; 选中一个数据库
show tables;
创建表:student(整数id,字符串name,整数age)
CREATE TABLE sutdent (id int, name varchar(20), age int);
查看一个表结构
desc 表名;
查看创建表的sql语句
SHOW CREATE TABLE 表名;
修改表结构
ALTER TABLE 表名 …
向学生表中添加1列remark varchar(100)
ALTER TABLE student ADD remark varchar(100)
删除学生表列remark
ALTER TABLE student DROP remark;
修改表student名字为student1
REANME TABLE sutdent TO student1;
删除表
DROP TABLE 表名;
管理数据:数据增删改DML
插入数据
INSERT INTO 表名 (字段名1, 字段名2..) VALUES (值1, 值2...);
修改数据
UPDATE 表名 SET 字段名=新的值 WHERE 条件;
删除表中的所有数据
DELETE FROM 表名;
学习目标
- 能够使用SQL语句进行排序(掌握)
- 能够使用聚合函数(掌握)
- 能够使用SQL语句进行分组查询(掌握)
- 能够完成数据的备份和恢复
- 能够使用SQL语句添加主键、外键、唯一、非空约束(掌握)
- 能够说出多表之间的关系及其建表原则
第1章 DQL语句
1、DQL查询语句-条件查询(掌握)
目标
能够掌握条件查询语法格式
讲解
前面我们的查询都是将所有数据都查询出来,但是有时候我们只想获取到满足条件的数据
语法格式:
SELECT 字段名... FROM 表名 WHERE 条件;
流程:取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回
准备数据
CREATE TABLE student3 (
id int,
name varchar(20),
age int,
sex varchar(5),
address varchar(100),
math int,
english int
);
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (1,'马云',55,'男','杭州',66,78),(2,'马化腾',45,'女','深圳',98,87),(3,'马景涛',55,'男','香港',56,77),(4,'柳岩',20,'女','湖南',76,65),(5,'柳青',20,'男','湖南',86,NULL),(6,'刘德华',57,'男','香港',99,99),(7,'马德',22,'女','香港',99,99),(8,'德玛西亚',18,'男','南京',56,65);
比较运算符
>大于
<小于
<=小于等于
>=大于等于
=等于
<>、!=不等于
具体操作:
- 查询math分数大于80分的学生
SELECT * FROM student3 WHERE math>80;

- 查询english分数小于或等于80分的学生
SELECT * FROM student3 WHERE english<=80;

- 查询age等于20岁的学生
SELECT * FROM student3 WHERE age=20;
![[外链图片转存失败(img-yPn1c1LU-1562504575228)(img/where查询03.png)]](http://img.e-com-net.com/image/info8/d9a0d98b115b4283917769cdfc438a23.png)
- 查询age不等于20岁的学生
SELECT * FROM student3 WHERE age!=20;
SELECT * FROM student3 WHERE age<>20;

逻辑运算符
and(&&) 多个条件同时满足 一假即假
or(||) 多个条件其中一个满足 一真即真
not(!) 不满足
具体操作:
- 查询age大于35且性别为男的学生(两个条件同时满足)
SELECT * FROM student3 WHERE age>35 AND sex='男';
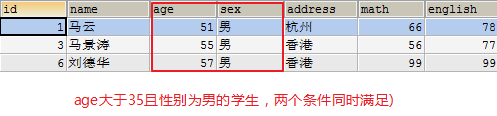
- 查询age大于35或性别为男的学生(两个条件其中一个满足)
SELECT * FROM student333 WHERE age>35 OR sex='男';

- 查询id是1或3或5的学生
SELECT * FROM student3 WHERE id=1 OR id=3 OR id=5;
![[外链图片转存失败(img-WRjCH1QD-1562504575229)(img/where查询08.png)]](http://img.e-com-net.com/image/info8/aa3e11c4095449158b28adc0fa0bd41e.png)
in关键字
语法格式:
SELECT * FROM 表名 WHERE 字段 in (值1, 值2, 值3);
in里面的每个数据都会作为一次条件,只要满足条件的就会显示
具体操作:
- 查询id是1或3或5的学生
SELECT * FROM student3 WHERE id IN (1,3,5);
![[外链图片转存失败(img-9NeNqK3l-1562504575230)(img/where查询08.png)]](http://img.e-com-net.com/image/info8/8d182d10caa7464c8c209f63b51d2054.png)
- 查询id不是1或3或5的学生
SELECT * FROM student3 WHERE id NOT IN (1,3,5);
![[外链图片转存失败(img-ZEUHEIkp-1562504575230)(img/where查询07.png)]](http://img.e-com-net.com/image/info8/1226d74841ce4cefbd70b44faebea71c.png)
范围
BETWEEN 值1 AND 值2 -- 表示从值1到值2范围,包头又包尾
比如:age BETWEEN 80 AND 100
相当于: age>=80 && age<=100
具体操作:
- 查询english成绩大于等于75,且小于等于90的学生
SELECT * FROM student3 WHERE english>=75 AND english<=90;
SELECT * FROM student3 WHERE english BETWEEN 75 AND 90;
![[外链图片转存失败(img-2gUhZydb-1562504575230)(img/where查询09.png)]](http://img.e-com-net.com/image/info8/b372e5bdba2542008957297b4dc542d5.png)
2、模糊查询like(掌握)
目标
能够掌握模糊查询语法格式
![[外链图片转存失败(img-h6dhkXuH-1562504575231)(img/where查询11.png)]](http://img.e-com-net.com/image/info8/304e1ebdd18b417096c463b841e40efc.png)
讲解
LIKE表示模糊查询
SELECT * FROM 表名 WHERE 字段名 LIKE '通配符字符串';
满足通配符字符串规则的数据就会显示出来
所谓的通配符字符串就是含有通配符的字符串
MySQL通配符有两个:
%: 表示零个一个多个字符(任意多个字符)
_: 表示一个字符
例如: name like '张%' 所有姓张学员。
name like '%张%' 只要有张就可以。
name like '张_' 所有姓张名字为两个字学员。
name like '_张_' 只有中间是张,前面一个字,后面一个字。
具体操作:
- 查询姓马的学生
SELECT * FROM student3 WHERE NAME LIKE '马%';
![[外链图片转存失败(img-j9RSB5XD-1562504575231)(img/where查询10.png)]](http://img.e-com-net.com/image/info8/f569280a8a0e47f1ad6e9a1b4f77c896.png)
- 查询姓名中包含’德’字的学生
SELECT * FROM student3 WHERE NAME LIKE '%德%';
![[外链图片转存失败(img-bcHuZUXI-1562504575231)(img/where查询11.png)]](http://img.e-com-net.com/image/info8/3b40121c02a84d60ab6648658c2a3247.png)
- 查询姓马,且姓名有三个字的学生
SELECT * FROM student3 WHERE NAME LIKE '马__';
![[外链图片转存失败(img-arWGiulp-1562504575232)(img/where查询12.png)]](http://img.e-com-net.com/image/info8/03df1ad869dc44ad9197fefd8df47ee7.png)
小结
模糊查询格式: SELECT 字段 FROM 表名 WHERE 字段 LIKE ‘通配符字符串’;
%:表示零个一个多个字符(任意多个字符)
_:表示一个字符
3、DQL查询语句-排序(掌握)
目标
- 能够掌握对查询的数据进行排序
讲解
通过ORDER BY子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)
SELECT 字段 FROM 表名 ORDER BY 排序的字段 [ASC|DESC];
ASC: 升序排序(默认)
DESC: 降序排序
- 单列排序
单列排序就是使用一个字段排序
具体操作:
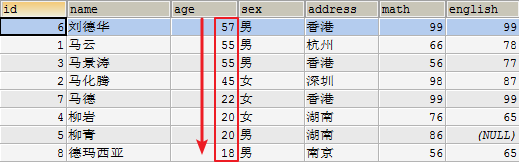
- 查询所有数据,使用年龄降序排序
SELECT * FROM student3 ORDER BY age DESC;
[外链图片转存失败(img-C2NihSaq-1562504575232)(img/orderby01.png)]
1.2.2 组合排序
组合排序就是先按第一个字段进行排序,如果第一个字段相同,才按第二个字段进行排序,依次类推。
上面的例子中,年龄是有相同的。当年龄相同再使用math进行排序
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];
注意: order by a asc,b asc
a, b
1, 2
1, 3
4, 5
3, 1
结果:
1,2
1,3
3,1
4,5

具体操作:
- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩降序排序
SELECT * FROM student3 ORDER BY age DESC, math DESC;

小结
- 排序的关键字:ORDER BY 字段名
- 升序:ASC 默认的
- 降序:DESC
4、DQL查询语句-聚合函数(掌握)
目标
能够掌握五个聚合函数的使用
讲解
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。另外聚合函数会忽略空值。对于null不作为统计。
五个聚合函数:
count:在根据指定的列统计的时候,如果这一列中有null的行,该行 不会被统计在其中。按照列去统计有多少行数据。
sum: 计算指定列的数值和,如果不是数值类型,那么计算结果为0
max: 计算指定列的最大值
min: 计算指定列的最小值
avg: 计算指定列的平均值
聚合函数的使用:写在 SQL语句SELECT后 字段名的地方
SELECT 字段名... FROM 表名;
SELECT 聚合函数(字段) FROM 表名;
具体操作:
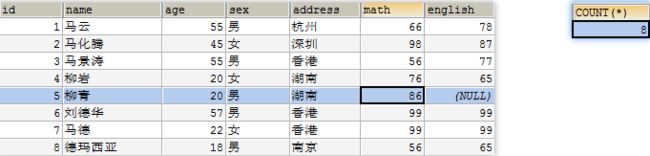
- 查询学生总数
SELECT COUNT(english) FROM student3;

我们发现对于NULL的记录不会统计.
统计数量常用:
SELECT COUNT(*) FROM student3;
- 查询年龄大于40的总数
SELECT COUNT(*) FROM student3 WHERE age>40;

- 查询数学成绩总分
SELECT SUM(math) FROM student3;

-
统计数学与英语的总和值。
方法一:
-- 统计数学与英语的总和值 select sum(math) + sum(english) from student3;![[外链图片转存失败(img-GR3AGAKn-1562504575234)(img/总和值.bmp)]](http://img.e-com-net.com/image/info8/63bd12aad3424352af2ea964c6398d35.png)
方法二:
-- 统计数学与英语的总和值 select sum(math + english) from student3;![[外链图片转存失败(img-hLNYfJG4-1562504575234)(img/总和值2.bmp)]](http://img.e-com-net.com/image/info8/3ac953539a654c91a066e9879837a5d3.png)
我们发现按照方法二的做法,结果是有问题的。结果少了86。
产生问题的原因:
上述写法会先将每一行的数学分数值和英语分数值进行相加,然后再把每一行的数学分数值和英语分数值相加后的值进行求和。
这样写会出现一个问题,因为在mysql中null值和任何值相加为null,导致在进行柳青的数学和英语相加的时候,柳青的数学和英语和值就变为了null。而最后sum求和的时候,就把柳青的数学和英语和值null给排除,因此最后的和值会缺少柳青的数学和英语和值86。
解决方案:在sql语句中我们可以使用数据库提供的函数ifnull(列名, 默认值)来解决上述问题。
ifnull(列名, 默认值)函数表示判断该列名是否为null,如果为null,返回默认值,如果不为null,返回实际的值。
例子:
english 的值是null
ifnull(english,2) ====english列的值是null,返回值是 2
english的值是3
ifnull(english,2) ===== age列的值不是null,返回实际值是3

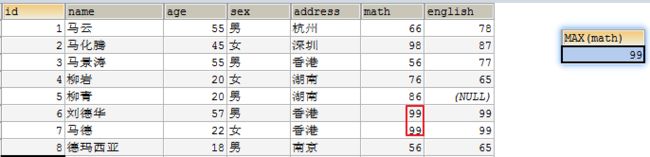
- 查询数学成绩最高分
SELECT MAX(math) FROM student3;
- 查询数学成绩最低分
SELECT MIN(math) FROM student3;

- 查询数学成绩平均分
SELECT AVG(math) FROM student3;
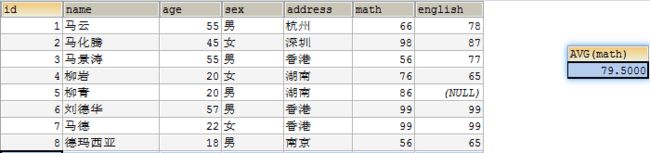
小结
| sum(列名) | 求和 |
|---|---|
| count(列名) | 统计数量 |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| avg(列名) | 平均值 |
5、DQL查询语句-分组(掌握)
目标
能够对查询后的结果进行分组
讲解
1.官方定义:分组: 按照某一列或者某几列。把相同的数据,进行合并输出。
2.完整写法:select … from … group by 列名,列名
按照某一列进行分组。
目的:仍然是统计使用。
3.分组生活举例:假设去超市买东西,我买了肥皂、洗衣粉、洗衣液、苹果、香蕉、葡萄等。我们在计算总价格之前先对所买的商品进行分类计算价格,然后在相加计算总价格。比如我们先将肥皂、洗衣粉、洗衣液分为一组计算出价格,然后再将苹果、香蕉、葡萄分为一组计算出价格,最后将两组的价格相加就是商品的总价格。
说明:分组其实就是按列进行分类,然后可以对分类完的数据使用聚合函数进行运算。
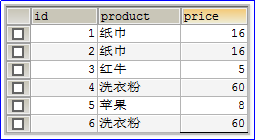
上述数据表示纸巾和洗衣粉属于不同品牌,但是价格是一样的。
注意:
1、聚合函数:分组之后进行计算;
2、通常 select后面的内容是被分组的列,以及聚合函数;
4.数据准备:
create table orders(
id int,
product varchar(20),
price float
);
insert into orders(id,product,price) values(1,'纸巾',16);
insert into orders(id,product,price) values(2,'纸巾',16);
insert into orders(id,product,price) values(3,'红牛',5);
insert into orders(id,product,price) values(4,'洗衣粉',60);
insert into orders(id,product,price) values(5,'苹果',8);
insert into orders(id,product,price) values(6,'洗衣粉',60);
5.需求1:查询购买的每种商品的总价。
分析:
查询的内容:product,sum(price) 按照商品名称进行分类。
按照商品分组,应该分成如下几组数据:

分组之后查询的结果应该是:
苹果 8
纸巾 32
红牛 5
洗衣粉 120
最终答案:

说明:先按照product进行分组,分组完成之后再给每一组进行求和。
注意:分组有一个特点:
一旦使用了分组函数,那么最终在显示的时候,只能显示被分组的列或者聚合函数。
举例:修改上述的查询语句:查询结果添加一个id。
select id,product,sum(price) from orders group by product;
结果如下所示:

原来的数据:
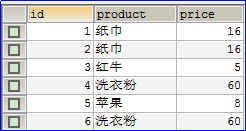
说明:
通过查询的结果和原来的数据比较发现,虽然添加id之后可以查询出结果,但是对于纸巾商品来说有问题,查询结果显示id是1,而纸巾的结果的id除了1还有2,同是纸巾,牌子还不一样,所以查询结果有问题。
修改上述数据库表中的数据:
将纸巾id为2的price价格修改为20。
![[外链图片转存失败(img-B74PWCq4-1562504575237)(img/分组图解6.bmp)]](http://img.e-com-net.com/image/info8/1b56d63a2fd24356b356083dc1c76828.png)
然后修改查询语句,要求是先按照商品名分组,然后在按照价格进行分组。

出现上述结果的原因是:
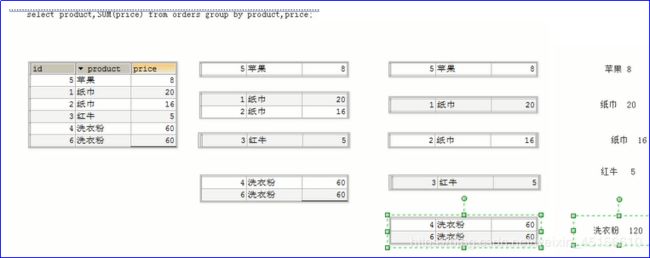
说明:先按照商品名字进行分组,然后再按照商品的价格进行分组。
需求2:查询每一种商品的总价大于30的商品,并显示总价。
分析:
显示商品和总价,要求条件是商品的总价大于30的商品。
书写的sql语句如下所示:

可是执行上述sql语句时,会报如下错误:
![[外链图片转存失败(img-JF9p7kjH-1562504575237)(img/分组图解10.bmp)]](http://img.e-com-net.com/image/info8/2bc0b58f3f1e461b87166f29b4d73d4d.png)
是因为上述的sql语句的使用有错误。
主要原因:在sql语句中的where 后面不允许添加聚合函数,添加就会报上述错误。
那么既然这里不能使用where来解决问题,但是我们还依然要进行过滤,所以在sql语句中,如果分组之后,还需要一些条件。
可以使用having条件,表示分组之后的条件,在having后面可以书写聚合函数。
关于 having 的用法解释:
having必须和group by 一起使用,having和where的用法一模一样,where怎么使用having就怎么使用,where不能使用的,having也可以使用,比如说where后面不可以使用聚合函数,但是在having后面是可以使用聚合函数的。
修改后的sql语句如下所示:
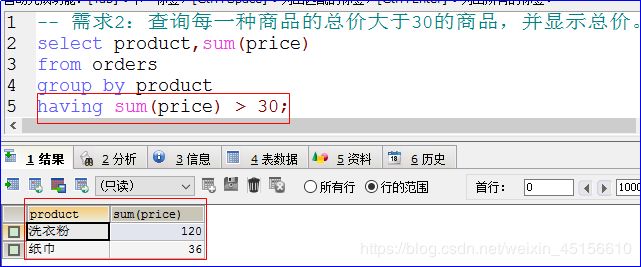
关于以上sql语句可以实现的最终结果的原因如下所示:

总结:
一、关于group by 和having一起使用的规则如下所示:
group by 列名 having 条件
分组之后加过滤条件。
二、where 和 having 的区别。
1、having 通常与group by 分组结合使用。 where 和分组无关。
2、having 可以书写聚合函数 (聚合函数出现的位置: having 之后)
例如having中的 聚合函数(count,sum,avg,max,min),是不可以出现where条件中。
3、where 是在分组之前进行过滤的。having 是在分组之后进行过滤的。
sql语句举例:
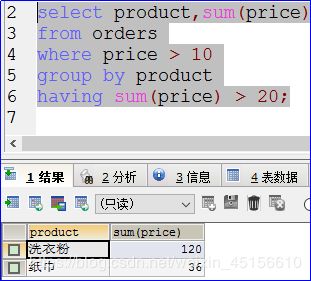
上述sql语句执行顺序如下图所示:

select … from … where 条件1 … group by … having 条件2 order by…
执行顺序:
条件1 会先执行过滤
进行分组
条件2进行过滤
开发中什么情况下使用分组?小技巧。
当在需求中遇到每种,每个等字眼的时候就使用分组。
小结
-
分组的语法格式?SELECT 字段5 FROM 表名1 WHERE 条件2 GROUP BY 字段3 HAVING 条件4 order by6… ;
123456
-
分组的原理?先将相同数据作为一组,返回每组的第一条数据,单独分组没有意义,分组后跟聚合函数操作
-
where和having的区别?
having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
having后面可以使用聚合函数
where后面不可以使用聚合函数 -
分组使用:只要带每就分组。
6、DQL查询语句-limit语句(掌握)
目标
能够掌握limit语句的使用
讲解
作用:
LIMIT是限制的意思,所以LIMIT`的作用就是限制查询记录的条数。
LIMIT语句格式:
select * from 表名 limit offset, row_count;
mysql中limit的用法:返回前几条或者中间某几行数据
select * from 表名limit 1,4。
1表示索引,注意这里的索引从0开始。对应表中第一行数据
4表示查询记录数。
上述就表示从第2条记录开始查询,一共查询4条,即到第5条。
具体步骤:
- 查询学生表中数据,跳过前面1条,显示4条
我们可以认为跳过前面1条,取4条数据
SELECT * FROM student3 LIMIT 1,4;
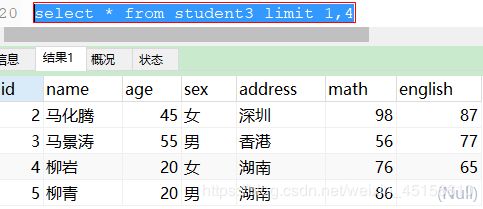
LIMIT的使用场景:分页
比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。假设我们一每页显示5条记录的方式来分页。
假设我们一每页显示5条记录的方式来分页,SQL语句如下:
-- 每页显示5条
-- 第一页: LIMIT 0,5; 跳过0条,显示5条
-- 第二页: LIMIT 5,5; 跳过5条,显示5条
-- 第三页: LIMIT 10,5; 跳过10条,显示5条
SELECT * FROM student3 LIMIT 0,5;
SELECT * FROM student3 LIMIT 5,5;
SELECT * FROM student3 LIMIT 10,5;

注意:
- 如果第一个参数是0可以简写:
SELECT * FROM student3 LIMIT 0,5;
SELECT * FROM student3 LIMIT 5;- LIMIT 10,5; – 不够5条,有多少显示多少
小结
-
LIMIT语句的使用格式?
SELECT 字段 FROM 表名 LIMIT 跳过的条数, 显示条数; 跳过的条数:表示索引,从0开始,一直变化 显示条数:每页显示的行数,固定不变的 -
SELECT 字段名(5) FROM 表名(1) WHERE 条件(2) GROUP BY 分组列名(3) HAVING 条件(4) ORDER BY 排序列名(6) LIMIT 跳过行数, 返回行数(7);
7、数据库备份和还原(理解)
目标
- 能够使用命令行的方式备份和还原表中的数据
- 能够使用图形客户端来备份和还原数据
讲解
备份的应用场景
在服务器进行数据传输、数据存储和数据交换,就有可能产生数据故障。比如发生意外停机或存储介质损坏。这时,如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失,造成的损失是无法弥补与估量的。

命令行方式备份与还原
备份格式:
mysqldump -u 用户名 -p 数据库名 > 磁盘SQL文件路径
注意:这个操作不用登录.由于mysqldump命令不是sql命令,需要在dos窗口下使用在mysql的安装目录的bin目录下有mysqldump命令,可以完成对数据库的备份。
还原格式:
注意:恢复数据库,需要手动的先创建数据库:
create database heima;
恢复数据库语法:mysql -u 用户名 -p 导入库名 < 硬盘SQL文件绝对路径
具体操作:
一、需求:
1、重新开启一个新的dos窗口。
2、将day02数据库导出到硬盘文件e:\day02 .sql 中。
具体的执行命令如下所示:
![]()
说明:在备份数据的时候,数据库不会被删除。可以手动删除数据库。同时在恢复数据的时候,不会自动的给我们创建数据库,仅仅只会恢复数据库中的表和表中的数据。
二、需求:
1、创建heima数据库。
2、重新开启一个新的dos窗口。将day02备份的数据表和表数据 恢复到heima中。
具体做法如下所示:
1)创建heima数据库。
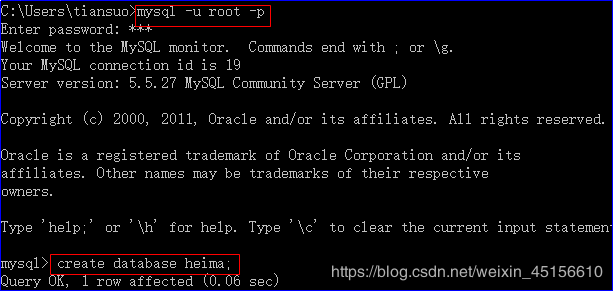
2)重新开启一个新的dos窗口。将day02备份的数据表和表数据 恢复到heima中。
注意:在cmd下使用,不是登录mysql后使用,和备份比较类似,只不过mysql后面不带dump,并且箭头是<,指向需要导入数据的新的数据库。这种恢复的方式,也需要数据库提前存在。
恢复数据库语法:mysql -u 用户名 -p 导入库名 < 硬盘SQL文件绝对路径
这里导入的一定是之前命令窗口备份的文件。
![]()
导入后的表结构:
![[外链图片转存失败(img-E1KZT2uH-1562504575240)(img/还原数据库3.bmp)]](http://img.e-com-net.com/image/info8/8aa274e4a71944d4bffd94cc3dbc1183.png)
图形化界面备份与还原
使用可视化工具可以实现对数据库表中的数据进行备份和恢复。
-
备份:
1)
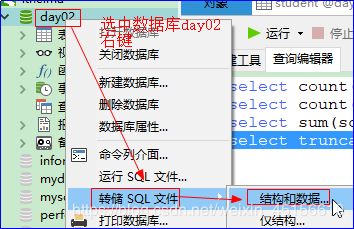
2)
[外链图片转存失败(img-M112O6Qn-1562504575241)(img/可视化工具备份2.bmp)]
3)
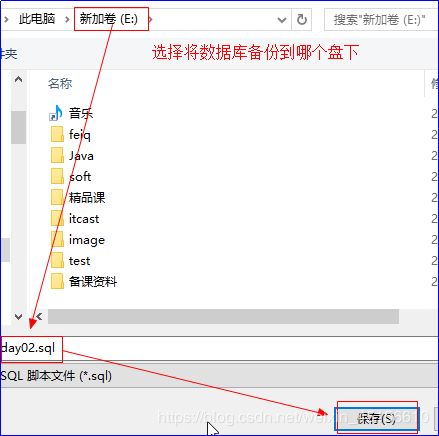

4)在硬盘路径下多了一个文件:
![[外链图片转存失败(img-IhoSGug8-1562504575241)(img/可视化工具备份4.bmp)]](http://img.e-com-net.com/image/info8/ac8f0f429ffa498b85ebee7ed44de4c5.png)
-
使用可视化工具将之前备份的数据导入:
1)点击右键新创建一个数据库
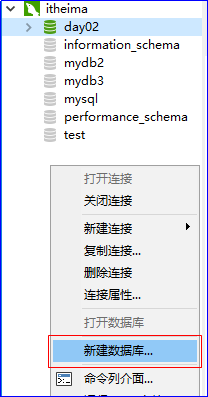
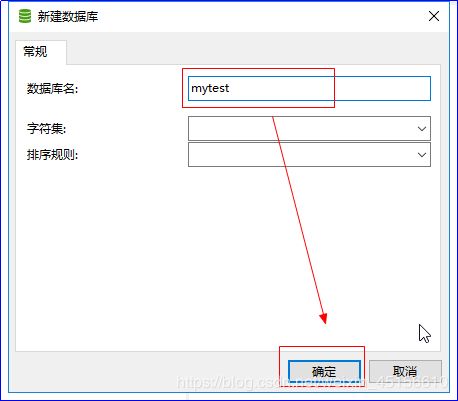
2)双击新创键的mytest数据库,然后选中新创建的数据库,在数据库上点击右键

3)在弹出框中选择之前备份好好的day02.sql文件

4)选择好之后点击开始按钮
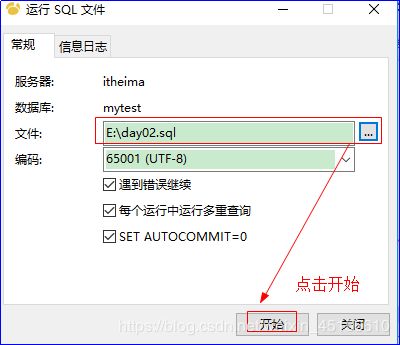
5)完成之后选择关闭

6)恢复后的结果:
![[外链图片转存失败(img-ybQ72sSN-1562504575242)(img/可视化工具还原7.bmp)]](http://img.e-com-net.com/image/info8/2b0d1d430edc4320b9ac775ae6638bce.png)
小结
-
使用命令行的方式备份和还原表中的数据

-
使用图形客户端来备份和还原数据
8、数据库约束的概述
目标
能够说出数据库约束的作用
讲解
数据库约束的作用
对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性。
约束种类
PRIMARY KEY: 主键约束UNIQUE: 唯一约束NOT NULL: 非空约束DEFAULT: 默认值 了解FOREIGN KEY: 外键约束
小结
- 数据库约束的作用?
对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性。
9、主键约束(掌握)
目标
- 能够说出主键约束的作用
- 能够添加主键
讲解
主键的作用
用来唯一标识一条记录。
为什么需要主键约束
有些记录的 name,age,score 字段的值都一样时,那么就没法区分这些数据,造成数据库的记录不唯一,这样就不方便管理数据。
![[外链图片转存失败(img-8BLJXLeM-1562504575243)(img/主键01.png)]](http://img.e-com-net.com/image/info8/54444fbfdce644eda85de610d0fd9e42.png)
![[外链图片转存失败(img-UiY3FmVq-1562504575243)(img/主键02.png)]](http://img.e-com-net.com/image/info8/a9aae6d62ae748d6bb1b8667ffab0a8a.png)
每张表都应该有一个主键,并且每张表只能有一个主键。
哪个字段作为表的主键
通常不用业务字段作为主键,单独给每张表设计一个id的字段,把id作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
创建主键
主键:PRIMARY KEY
主键的特点:
- 主键必须包含唯一的值
- 主键列不能包含NULL值
创建主键方式:
-
在创建表的时候给字段添加主键
字段名 字段类型 PRIMARY KEY -
在已有表中添加主键
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);
具体操作:
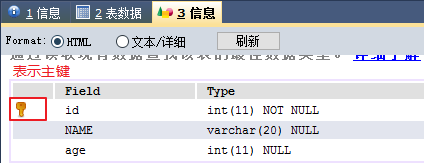
- 创建表学生表st5, 包含字段(id, name, age)将id做为主键
CREATE TABLE st5 (
id INT PRIMARY KEY, -- id是主键
NAME VARCHAR(20),
age INT
);
- 添加数据
INSERT INTO st5 (id, NAME,age) VALUES (1, '唐伯虎',20);
INSERT INTO st5 (id, NAME,age) VALUES (2, '周文宾',24);
INSERT INTO st5 (id, NAME,age) VALUES (3, '祝枝山',22);
INSERT INTO st5 (id, NAME,age) VALUES (4, '文征明',26);
- 插入重复的主键值
-- 主键是唯一的不能重复:Duplicate entry '1' for key 'PRIMARY'
INSERT INTO st5 (id, NAME,age) VALUES (1, '文征明2',30);
- 插入NULL的主键值
-- 主键是不能为空的:Column 'id' cannot be null
INSERT INTO st5 (id, NAME,age) VALUES (NULL, '文征明3',18);
小结
-
说出主键约束的作用?唯一区分一条记录
-
主键的特点?唯一,不能为NULL
-
添加主键?
字段名 字段类型 PRIMARY KEYALTER TABLE 表名 ADD PRIMARY KEY(字段名);
10、主键自增
目标
能够设置主键为自动增长
讲解
主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值
字段名 字段类型 PRIMARY KEY AUTO_INCREMENT
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
具体操作:
- 创建学生表st6, 包含字段(id, name, age)将id做为主键并自动增长
CREATE TABLE st6 (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT
);
- 插入数据
-- 主键默认从1开始自动增长
INSERT INTO st6 (NAME, age) VALUES ('唐僧', 22);
INSERT INTO st6 (NAME, age) VALUES ('孙悟空', 26);
INSERT INTO st6 (NAME, age) VALUES ('猪八戒', 25);
INSERT INTO st6 (NAME, age) VALUES ('沙僧', 20);

DELETE和TRUNCATE的区别
-
DELETE 删除表中的数据,但不重置AUTO_INCREMENT的值。
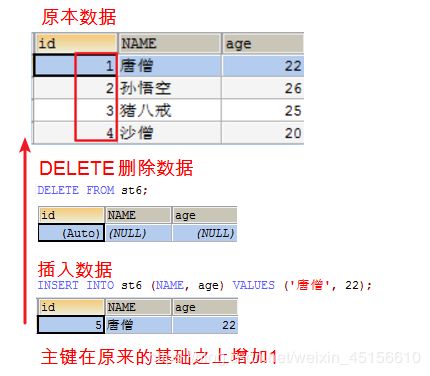
-
TRUNCATE 摧毁表,重建表,AUTO_INCREMENT重置为1
[外链图片转存失败(img-Mt8yGJQi-1562504575244)(img/主键07.png)]
小结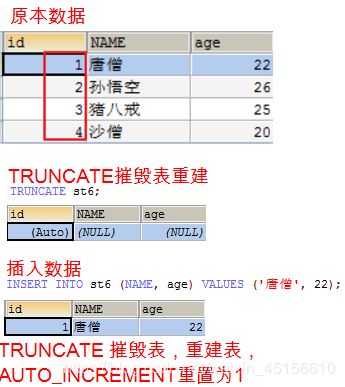
- 设置主键为自动增长格式?
字段名 数据类型 PRIMARY KEY AUTO_INCREMENT
11、唯一约束
目标
- 能够说出唯一约束的作用
- 能够添加唯一约束
讲解
唯一约束的作用
在这张表中这个字段的值不能重复
唯一约束的基本格式
字段名 字段类型 UNIQUE
具体步骤:
- 创建学生表st7, 包含字段(id, name),name这一列设置唯一约束,不能出现同名的学生
CREATE TABLE st7 (
id INT,
NAME VARCHAR(20) UNIQUE
);
- 添加一些学生
INSERT INTO st7 VALUES (1, '貂蝉');
INSERT INTO st7 VALUES (2, '西施');
INSERT INTO st7 VALUES (3, '王昭君');
INSERT INTO st7 VALUES (4, '杨玉环');
-- 插入相同的名字出现name重复: Duplicate entry '貂蝉' for key 'name'
INSERT INTO st7 VALUES (5, '貂蝉');
-- 出现多个null的时候会怎样?因为null是没有值,所以不存在重复的问题
INSERT INTO st3 VALUES (5, NULL);
INSERT INTO st3 VALUES (6, NULL);
小结
- 说出唯一约束的作用?让这个字段的值不能重复
- 添加唯一约束格式?字段名 字段类型 UNIQUE
12、非空约束
目标
- 能够说出非空约束的作用
- 能够添加非空约束
讲解
非空约束的作用
这个字段必须设置值,不能是NULL
非空约束的基本语法格式
字段名 字段类型 NOT NULL
具体操作:
- 创建表学生表st8, 包含字段(id,name,gender)其中name不能为NULL
CREATE TABLE st8 (
id INT,
NAME VARCHAR(20) NOT NULL,
gender CHAR(2)
);
- 添加一些完整的记录
INSERT INTO st8 VALUES (1, '郭富城', '男');
INSERT INTO st8 VALUES (2, '黎明', '男');
INSERT INTO st8 VALUES (3, '张学友', '男');
INSERT INTO st8 VALUES (4, '刘德华', '男');
-- 姓名不赋值出现姓名不能为null: Column 'name' cannot be null
INSERT INTO st8 VALUES (5, NULL, '男');
小结
非空约束的格式:
字段名 数据类型 NOT NULL
13、默认值(了解)
目标
- 能够说出默认值的作用
- 能够给字段添加默认值
讲解
默认值的作用
往表中添加数据时,如果不指定这个字段的数据,就使用默认值
默认值格式
字段名 字段类型 DEFAULT 默认值
具体步骤:
- 创建一个学生表 st9,包含字段(id,name,address), 地址默认值是广州
CREATE TABLE st9 (
id INT,
NAME VARCHAR(20),
address VARCHAR(50) DEFAULT '广州'
);
- 添加一条记录,使用默认地址
INSERT INTO st9 (id, NAME) VALUES (1, '刘德华');

- 添加一条记录,不使用默认地址
INSERT INTO st9 VALUES (2, '张学友', '香港');
面试题:
如果一个字段设置了非空与唯一约束,该字段与主键的区别?
1.一张表只有一个主键
2.一张表可以多个字段添加非空与唯一约束
3.主键可以自动增长,自己添加的非空与唯一约束字段无法自动增长
小结
- 说出默认值的作用?不添加这个字段,就会使用默认值
- 给字段添加默认值格式? 字段名 字段类型 DEFAULT 默认值
14、表关系的概念和外键约束
在真实的开发中,一个项目中的数据,一般都会保存在同一个数据库中,但是不同的数据需要保存在不同的数据表中。这时不能把所有的数据都保存在同一张表中。
那么在设计保存数据的数据表时,我们就要根据具体的数据进行分析,然后把同一类数据保存在同一张表中,不同的数据进行分表处理。
数据之间必然会有一定的联系,我们把不同的数据保存在不同的数据表中之后,同时还要在数据表中维护这些数据之间的关系。这时就会导致表和表之间必然会有一定的联系。这时要求设计表的人员,就需要考虑不同表之间的具体关系。
在数据库中,表总共存在三种关系,这三种关系如下描述:真实的数据表之间的关系:
多对多关系、一对多(多对一)、一对一(极少)。(一对一关系就是我们之前学习的Map集合的key-value关系)
多对多(掌握)
例如:程序员和项目的关系、老师和学生,学生和课程,顾客和商品的关系等

分析:
程序员和项目:
一个程序员可以参与多个项目的开发,一个项目可以由多个程序员来开发。这种关系就称为多对多关系。
当我们把数据之间的关系分析清楚之后,一般我们需要通过E(Entity)-R(relation)图来展示。 实体 关系 图
一个Java对象,可以对应数据库中的一张表,而Java中类的属性,可以对应表中的字段。
而在E-R图中:
一张表,可以称为一个实体,使用矩形表示,每个实体的属性(字段,表的列),使用椭圆表示。
表和表之间的关系,使用菱形表示。
实体(程序员):编号、姓名、薪资。
实体(项目):编号、名称。
程序员和项目存在关系:一个程序员可以开发多个项目,一个项目可以被多个程序员开发。
说明:如果两张表是多对多的关系,需要创建第三张表,并在第三张表中增加两列,引入其他两张表的主键作为自己的外键。
关系图总结:

创建表的sql语句:
-- 创建程序员表
create table coder(
id int primary key auto_increment,
name varchar(50),
salary double
);
-- 创建项目表
create table project(
id int primary key auto_increment,
name varchar(50)
);
-- 创建中间关系表
create table coder_project(
coder_id int,
project_id int
);
-- 添加测试数据
insert into coder values(1,'张三',12000);
insert into coder values(2,'李四',15000);
insert into coder values(3,'王五',18000);
insert into project values(1,'QQ项目');
insert into project values(2,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,2);
外键约束(掌握)
创建第三张关系表即中间表,来维护程序员表和项目表之间的关系。
使用中间表的目的是维护两表多对多的关系:
1 中间表插入的数据 必须在多对多的主表中存在。
2 如果主表的记录在中间表维护了关系,就不能随意删除。如果可以删除,中间表就找不到对应的数据了,这样就没有意义了。
上述是中间表存在的意义,可是我们这里所创建的中间表并没有起到上述的作用,而是存在缺点的:
缺点1: 我们是可以向中间表插入不存在的项目编号和程序员编号的。

说明:在程序员和项目表中是不存在编号是30和20的,但是这里依然可以插入不存在的编号。这样做是不可以的,失去了中间表的意义。
缺点2 : 如果中间表存在程序员的编号, 我们是可以删除程序员表对应的记录的。
在中间表中是存在编号为1的程序员的:
![[外链图片转存失败(img-woI1p973-1562504575245)(img/3.bmp)]](http://img.e-com-net.com/image/info8/2f42960b440b4049800090a90ca88d19.png)
可是我们却可以删除程序员表coder中的编号为1的程序员:

编号为1的程序员张三已经被我们删除,但是在中间表coder_project中仍然还存在编号为1的程序员,这样对于中间表没有意义了。
说明:
创建第三张表的语句:
create table coder_project(
coder_id int ,--这个外键来自于coder表中的主键
project_id int--这个外键来自于project表中的主键
);
我们在创建第三张关系表时,表中的每一列,都是在使用其他两张表中的列,这时我们需要对第三张表中的列进行相应的约束。
当前第三张表中的列由于都是引用其他表中的列,我们把第三张表中的这些列称为引用其他表的外键约束。
给某个表中的某一列添加外键约束:
简化语法:
foreign key( 当前表中的列名 ) references 被引用表名(被引用表的列名);
注意:一般在开发中,被引用表的列名都是被引用表中的主键。
举例:
constraint [外键约束名称] foreign key(当前表中的列名) references 被引用表名(被引用表的列名)
举例:constraint coder_project_id foreign key(coder_id) references coder(id);
关键字解释:
constraint: 添加约束,可以不写
foreign key(当前表中的列名): 将某个字段作为外键
references 被引用表名(被引用表的列名) : 外键引用主表的主键
给第三张表添加外键约束有两种方式:
第一种方式:给已经存在的表添加外键约束:
-- 来自于程序员表
alter table coder_project add constraint c_id_fk foreign key(coder_id) references coder(id);
-- 来自于项目表
alter table coder_project add constraint p_id_fk foreign key(project_id) references project(id);
第二种方式:创建表时就添加外键约束:
create table coder_project(
coder_id int,
project_id int,
constraint c_id_fk foreign key(coder_id) references coder(id),
constraint p_id_fk foreign key(project_id) references project(id)
);
了解完如何给第三张表添加外键约束以后,我们就开始给上述创建好的第三张表添加外键约束。
在添加外键约束之前,由于刚才已经修改了表中的数据,所以我们先清空三张表,然后在添加外键约束。
操作步骤:
1、清空上述三张表:
![[外链图片转存失败(img-ezAkT2A9-1562504575246)(img/5.bmp)]](http://img.e-com-net.com/image/info8/8edd9963668c4316961cdc08f93e4dd6.png)
2、增加外键约束:
![]()
3、添加完外键约束以后,就会在可视化工具中的架构设计器上查看表之间的关系
先选中表
然后点击右下角:
最后的表关系如下:

3、向三张表中分别插入数据:
-- 插入数据
insert into coder values(null,'张三',12000);
insert into coder values(null,'李四',15000);
insert into coder values(null,'王五',18000);
insert into project values(null,'QQ项目');
insert into project values(null,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,1);
4、测试外键约束是否起到作用:
A:执行以下语句:
[外链图片转存失败(img-zZIKz3Ai-1562504575248)(img/10.bmp)]
B:执行以下语句: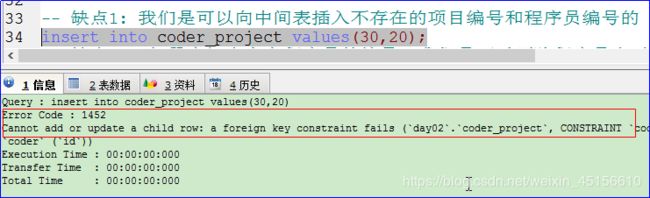
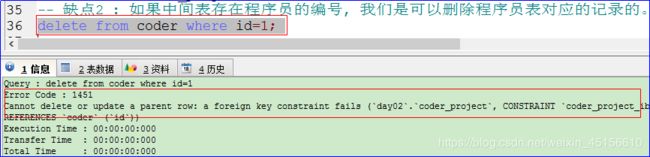
再次执行上述语句的时候,发现报错了,而数据库表中的数据都没有改变,说明外键约束起到了作用。
外键的级联(掌握)
在修改和删除主表的主键时,同时更新或删除从表的外键值,称为级联操作
ON UPDATE CASCADE – 级联更新,主键发生更新时,外键也会更新
ON DELETE CASCADE – 级联删除,主键发生删除时,外键也会删除
具体操作:
- 删除三张表coder、coder_project、project表
- 重新创建三张表,添加级联更新和级联删除
-- 创建程序员表
create table coder(
id int primary key auto_increment,
name varchar(50),
salary double
);
-- 创建项目表
create table project(
id int primary key auto_increment,
name varchar(50)
);
create table coder_project(
coder_id int,
project_id int,
-- 添加外键约束,并且添加级联更新和级联删除
constraint c_id_fk foreign key(coder_id) references coder(id) ON UPDATE CASCADE ON DELETE CASCADE,
constraint p_id_fk foreign key(project_id) references project(id) ON UPDATE CASCADE ON DELETE CASCADE
);
再次添加数据到三张表:
-- 添加测试数据
insert into coder values(1,'张三',12000);
insert into coder values(2,'李四',15000);
insert into coder values(3,'王五',18000);
insert into project values(1,'QQ项目');
insert into project values(2,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,2);
需求1:修改主表coder表的id为3变为4.
![[外链图片转存失败(img-92VLRwlK-1562504575248)(img/12.bmp)]](http://img.e-com-net.com/image/info8/f0b972dd62684ee8b2bee580d1d57b60.png)
需求2:删除主表coder表的id是4的行数据。
![[外链图片转存失败(img-mjPNszZI-1562504575248)(img/12.bmp)]](http://img.e-com-net.com/image/info8/d4529e5814a941cdbdafa123c8804ef2.png)
小结:
级联更新:ON UPDATE CASCADE 主键修改后,外键也会跟着修改
级联删除:ON DELETE CASCADE 主键删除后,外键对应的数据也会删除
一对多
一对多的关系表:其中也有2个实体,但是其中A实体中的数据可以对应另外B实体中的多个数据,反过来B实体中的多个数据只能对应A实体中的一个数据。
例如:作者和小说关系,班级和学生,部门和员工,客户和订单
分析:
作者和小说:
一个作者可以写多部小说,但每一部小说,只能对应具体的一个作者。
具体的关系如下图所示:

注意:如果是一对多的关系,那么设计表的时候需要在多的一方增加一列,引入一的一方的主键作为自己的外键。
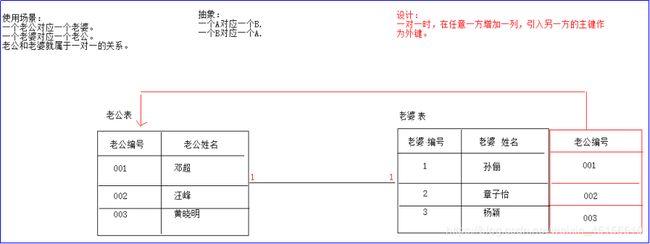
一对一
一对一关系表在实际开发中使用的并不多,其中也是2个实体,其中A实体中的数据只能对应B实体中的一个数据,同时B实体中的数据也只能对应A实体中的一个数据。例如:人和身份证对应关系,老公和老婆的对应关系。
而一对一在建表的时候,可以在任意一方的表中添加另外一方的主键作为外键即可。
建表原理如下图所示:
17、表设计案例(练习)
目标
设计学生成绩管理系统数据表(按照给定需求设计即可)
1、每个教师可以教多门课程
2、每个课程由一个老师负责
3、每门课程可以由多个学生选修
4、每个学生可以选修多门课程
5、学生选修课程要有成绩
讲解
具体操作:
1)分析:
当我们拿到一个需求之后,首先应该分析这个需求中到底有多少名词,或者是当前这个需求中可以抽象出具体几个E-R图中的实体对象。
分析需求中存在的实体: 实体使用矩形表示。
学生、课程、老师。
当分析清楚具体的实体之后,接着要分析实体具备哪些属性?属性使用椭圆形表示。
学生:学号、姓名等。
课程:课程编号、课程名称等。
老师:工号、姓名等。
最后就要考虑实体和实体之间的关系问题:
老师和课程之间:一对多关系。一个老师可以教授多门课程,一个课程只能由一个老师负责。
学生和课程之间:多对多关系。每个学生可以选修多门课程,每门课程可以被多个学生来选修。
2)关于设计学生成绩管理系统的数据表的E-R图如下所示:

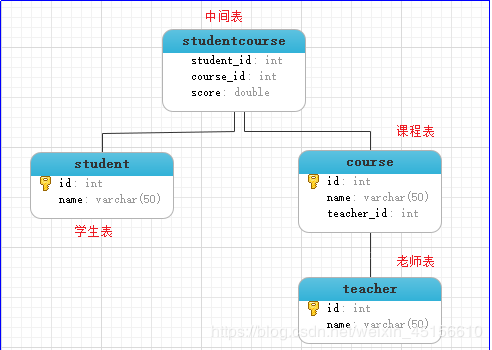
3)创建表sql语句:
画完E-R图之后,接下来我们就根据E-R图来创建具体的数据库表了。
学生选课管理系统的表创建:
思考:先创建哪张表?
不能先创建课程表,因为课程表需要有教师的工号,也不能创建中间表,因为中间表需要课程表和学生表的id,所以我们可以创建表的顺序如下:
– 1、教师表
– 2、课程表
– 3、学生表
– 4、学生课程表(中间关系表要有成绩属性)
创建表的语句如下:
-- 1、教师表
create table teacher(
id int primary key auto_increment,
name varchar(50)
);
-- 2、课程表
create table course(
id int primary key auto_increment,
name varchar(50),
teacher_id int,
foreign key(teacher_id) references teacher(id)
);
-- 3、学生表
create table student(
id int primary key auto_increment,
name varchar(50)
);
-- 4、学生课程表(中间关系表要有成绩属性)
create table studentcourse(
student_id int,
course_id int,
score double,
foreign key(student_id) references student(id),
foreign key(course_id) references course(id)
);
创建表之后的结构:
总结
-
能够使用SQL语句进行排序
SELECT 字段 FROM 表名 WHERE 条件 ORDER BY 字段 [ASC|DESC];
ASC:升序
DESC:降序 -
能够使用聚合函数
count: 统计数量
sum:求和
max:获取最大值
min:获取最小值
avg:获取平均值 -
能够使用SQL语句进行分组查询
SELECT 字段 FROM 表名 WHERE 条件 GROUP BY 字段;
分组是将相同数据作为一组,返回每组第一条数据(没有意义), 通常分组后使用聚合函数 -
能够完成数据的备份和恢复
命令行的方式
备份:不要登录:mysqldump -uroot -proot 数据库 > 文件名图形界面的方式
-
能够使用SQL语句添加主键、外键、唯一、非空约束
主键: 字段名 字段类型 PRIMARY KEY
外键: CONSTRAINT 外键名 FOREIGN KEY(字段) REFERENCES 主表(主键)
唯一: 字段名 字段类型 UNIQUE
非空约束: 字段名 字段类型 NOT NULL
默认约束: 字段名 字段类型 DEFAULT 默认值 -
能够说出多表之间的关系及其建表原则
1对1(1:1)
1对多(1:n)
多对多(m:n)1对多:多方这张表建立外键引用一方的主键(先建立一方主表,后建立多方从表)
多对多:建立中间表,中间表的字段引用某张表的主键(外键)