【Python爬虫实战】爬取彼岸图库高清图片
利用Python爬取彼岸图库高清图片
让你每天一张壁纸不重样,今天利用Python爬取 彼岸图库 http://pic.netbian.com/
分析网页
通过首页可以看到要获取全站图片必须先抓取各个4k图片目录的连接,以次抓取4k风景、4k美女、4k游戏…
要获取这一栏的数据就要对首页进行请求,分析出各个分类的首页连接!!!
打开开发者工具(F12)对网页进行分析
打开开发者工具点击Elements进入元素列表,在点击Elements左边的斜箭头进行网页元素定位找到需要的元素。此时就可以发现所有元素都存放在以下目录中:
"classify clearfix">
"/4kfengjing/" title="4K风景图片">4K风景
"/4kmeinv/" title="4K美女图片">4K美女
"/4kyouxi/" title="4K游戏图片">4K游戏
"/4kdongman/" title="4K动漫图片">4K动漫
"/4kyingshi/" title="4K影视图片">4K影视
"/4kmingxing/" title="4K明星图片">4K明星
"/4kqiche/" title="4K汽车图片">4K汽车
"/4kdongwu/" title="4K动物图片">4K动物
"/4krenwu/" title="4K人物图片">4K人物
"/4kmeishi/" title="4K美食图片">4K美食
"/4kzongjiao/" title="4K宗教图片">4K宗教
"/4kbeijing/" title="4K背景图片">4K背景代码实现
分析完网页内容,选择就通过Pycharm对网页进行请求获取每一栏的url
下载相关的库
在Pycharm命令终端中输入
1 pip install requests
2 pip install lxmlPython 代码
import os
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
}
def title_href():
url = 'http://pic.netbian.com/'
response = requests.get(url).content.decode('gbk')
# print(response)
html = etree.HTML(response)
divs = html.xpath('//*[@id="main"]/div[2]/a')
for div in divs:
title = div.xpath('./@title')[0]
href = 'http://pic.netbian.com/' + div.xpath('./@href')[0]
# print(title, href)
name_link(title, href) # 传参栏的网页地址,在分析每一栏的网页信息。
![]()
![]()
通过这两张图片可以看出只需要修改index_5.html中的数字就可以实现翻页操作
再次通过开发者工具进行网页分析
此时在对网页进行请求,获取到每一张图片的连接和名字。代码如下:
def name_link(title, href):
for i in range(1, 5): # 需要全站图片, 扩大循环范围即可
if i == 1:
url = href
else:
url = href + 'index_{}.html'.format(i)
# print(title, url)
response = requests.get(url, headers=headers).content.decode('gbk')
# print(response)
html = etree.HTML(response)
lis = html.xpath('//*[@id="main"]/div[3]/ul/li')
for li in lis:
img_name = li.xpath('./a/img/@alt')[0]
img_href = 'http://pic.netbian.com' + li.xpath('./a/@href')[0]
# print(img_name, img_href)
img_name_url(title, img_name, img_href) # 传参url和name,继续请求获取到图片的下载地址
继续分析分析图片页面的信息
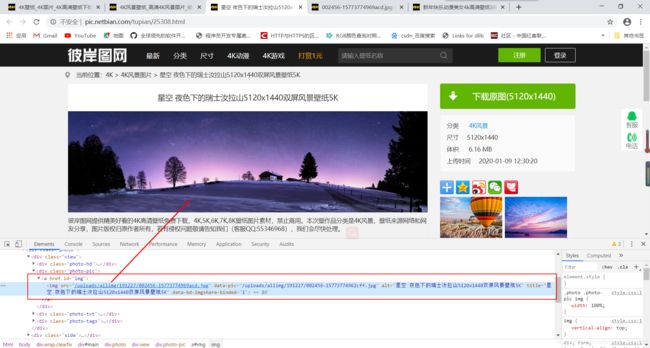
通过页面分析可以看出src中存放的就是图片的真正地址,只需要得到src即可。代码如下:
def img_name_url(title, name, url):
response = requests.get(url, headers=headers).content.decode('gbk')
# print(response)
html = etree.HTML(response)
image_url = 'http://pic.netbian.com/' + html.xpath('//*[@id="img"]/img/@src')[0]
# print(name, image_url)
download(title, name, image_url) # 传参到现在已经获取到了图片的url,请求写入文件就完成了。代码如下:
count = 1
def download(title, img_name, img_url):
global count
path = '彼岸图库/{}'.format(title)
if not os.path.exists(path):
os.makedirs(path)
print('-------[{}]文件夹已经创建成功,开始下载图片-------'.format(title))
print('正在下载{}, 这是第{}张图片'.format(img_name, count))
response = requests.get(img_url, headers=headers)
with open('彼岸图库/{}/{}.jpg'.format(title, img_name), 'wb')as f:
count += 1
f.write(response.content)
print('{}已经成功下载, 这是第{}张图片'.format(img_name, count))
title_href()
抓取所有的网页都是类似的思路,一步一步分析网页。