R语言决策树分析
A:分类树判别
一、数据读入及转化
以R中Titanic数据为例。
> data(Titanic) #数据读入
> str(Titanic)
'table' num [1:4, 1:2, 1:2, 1:2] 0 0 35 0 0 0 17 0 118 154 ...
- attr(*, "dimnames")=List of 4
..$ Class : chr [1:4] "1st" "2nd" "3rd" "Crew"
..$ Sex : chr [1:2] "Male" "Female"
..$ Age : chr [1:2] "Child" "Adult"
..$ Survived: chr [1:2] "No" "Yes"
> install.packages('epitools')
> library(epitools)
> Titanic.df<-expand.table(Titanic) #转化成数据框"data.frame"
二、决策树判别
> library(rpart)
> Titanic.tree<-rpart(Survived`.,data=Titanic.df,method='class‘') #rpart()函数
> summary(Titanic.tree) #summary()查看
Call:
rpart(formula = Survived~., data = Titanic.df, method = 'class')
n= 2201
CP nsplit rel error xerror xstd
1 0.30661041 0 1.0000000 1.0000000 0.03085662
2 0.02250352 1 0.6933896 0.6933896 0.02750982
3 0.01125176 2 0.6708861 0.6835443 0.02736973
4 0.01000000 4 0.6483826 0.6652602 0.02710334
Variable importance
Sex Class Age
73 23 4
Node number 1: 2201 observations, complexity param=0.3066104
predicted class=No expected loss=0.323035 P(node) =1
class counts: 1490 711
probabilities: 0.677 0.323
left son=2 (1731 obs) right son=3 (470 obs)
Primary splits:
Sex splits as LR, improve=199.821600, (0 missing)
Class splits as RRLL, improve= 69.684100, (0 missing)
Age splits as RL, improve= 9.165241, (0 missing)
Node number 2: 1731 observations, complexity param=0.01125176
predicted class=No expected loss=0.2120162 P(node) =0.7864607
class counts: 1364 367
probabilities: 0.788 0.212
left son=4 (1667 obs) right son=5 (64 obs)
Primary splits:
Age splits as RL, improve=7.726764, (0 missing)
Class splits as RLLL, improve=7.046106, (0 missing)
Node number 3: 470 observations, complexity param=0.02250352
predicted class=Yes expected loss=0.2680851 P(node) =0.2135393
class counts: 126 344
probabilities: 0.268 0.732
left son=6 (196 obs) right son=7 (274 obs)
Primary splits:
Class splits as RRLR, improve=50.015320, (0 missing)
Age splits as LR, improve= 1.197586, (0 missing)
Surrogate splits:
Age splits as LR, agree=0.619, adj=0.087, (0 split)
Node number 4: 1667 observations
predicted class=No expected loss=0.2027594 P(node) =0.757383
class counts: 1329 338
probabilities: 0.797 0.203
Node number 5: 64 observations, complexity param=0.01125176
predicted class=No expected loss=0.453125 P(node) =0.02907769
class counts: 35 29
probabilities: 0.547 0.453
left son=10 (48 obs) right son=11 (16 obs)
Primary splits:
Class splits as RRL-, improve=12.76042, (0 missing)
Node number 6: 196 observations
predicted class=No expected loss=0.4591837 P(node) =0.08905043
class counts: 106 90
probabilities: 0.541 0.459
Node number 7: 274 observations
predicted class=Yes expected loss=0.0729927 P(node) =0.1244889
class counts: 20 254
probabilities: 0.073 0.927
Node number 10: 48 observations
predicted class=No expected loss=0.2708333 P(node) =0.02180827
class counts: 35 13
probabilities: 0.729 0.271
Node number 11: 16 observations
predicted class=Yes expected loss=0 P(node) =0.007269423
class counts: 0 16
probabilities: 0.000 1.000
三、可视化
> install.packages('partykit')
> library(partykit)
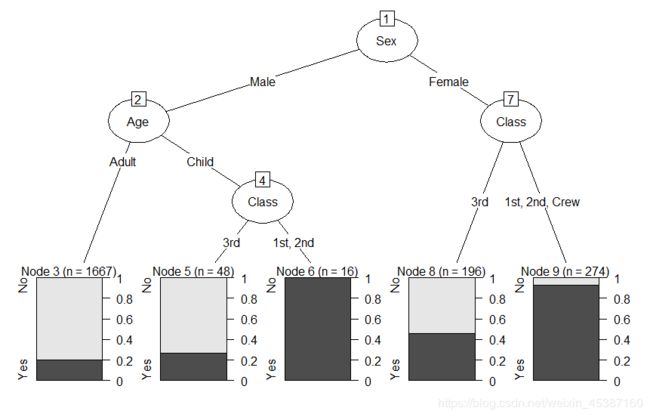
> plot(as.party(Titanic.tree)) #首先换成成party形式
结果如下:
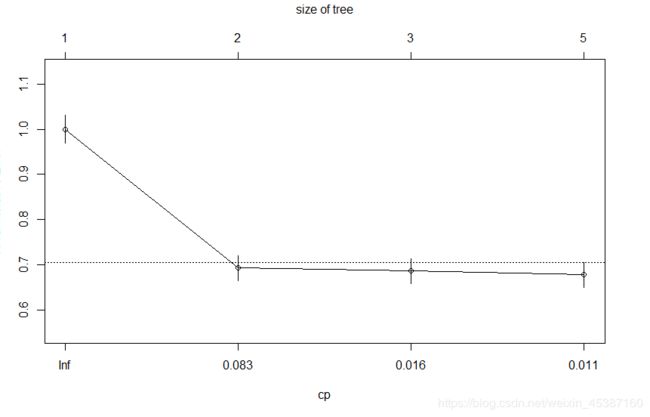
> plotcp(Titanic.tree) #cp复杂性参数
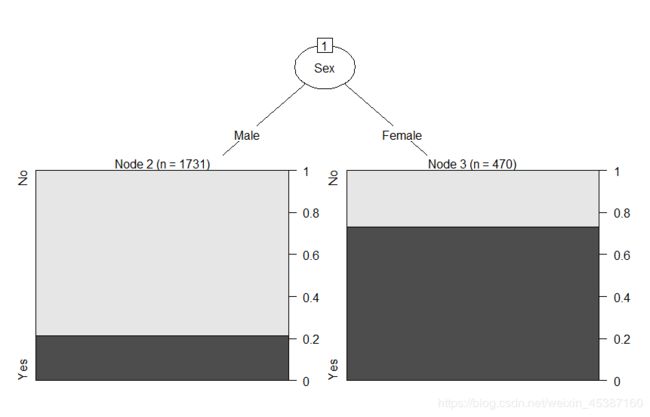
> Titanic.tree2<-rpart(Survived~.,data=Titanic.df,method='class',cp=0.083)
> plot(as.party(Titanic.tree2))#需要转化成party格式
B:回归树预测
以R中diamonds数据为例。
一、数据读入及处理:
> library(ggplot2)
> data("diamonds")
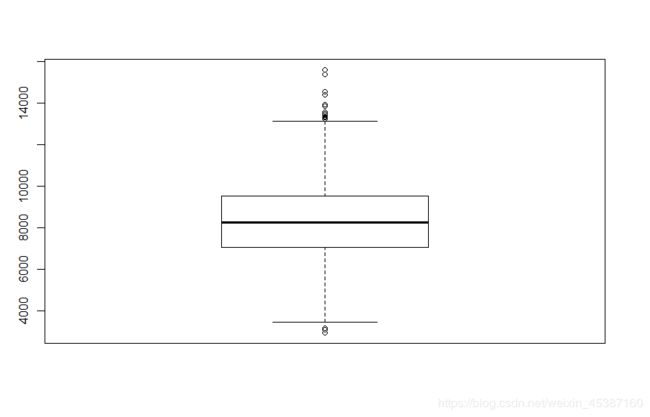
> diamonds2<-subset(diamonds,subset=carat>=1.5 & carat< 2 & clarity %in% c('I1','SI2'))
#由于数据量大,所以通过subset()取小范围数字
> boxplot(diamonds2$price) #boxplot观察price分布情况。
二、决策树分析
> str(diamonds)
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 53940 obs. of 10 variables:
$ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num 55 61 65 58 58 57 57 55 61 61 ...
$ price : int 326 326 327 334 335 336 336 337 337 338 ...
$ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
> diamonds.tree<-rpart(formula=price~carat+cut+color+clarity,data=diamonds,method='anova')
>#注意上面函数的参数使用
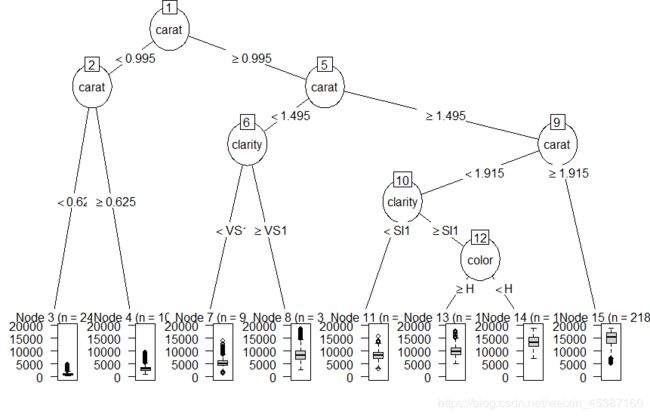
> plot(as.party(diamonds.tree))
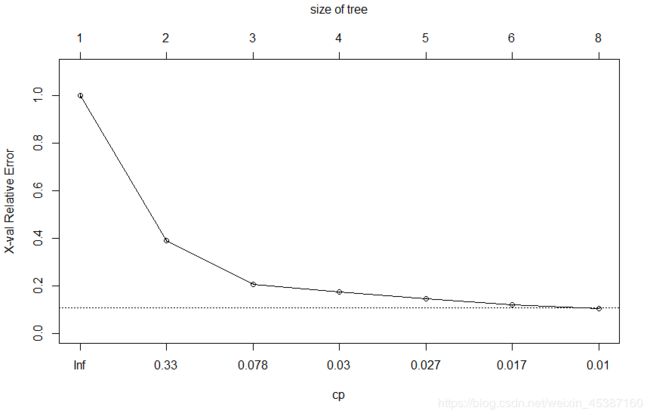
> plotcp(diamonds.tree)
三、执行预测
> train<-diamonds[1:50000,] #训练数据
> test<-diamonds[50001:nrow(diamonds),] #测试数据
> diamonds.tree2<-rpart(formula=price~carat+cut+color+clarity,data=train,method='anova',cp=0.078)
>
> p<-predict(diamonds.tree2,newdata=test)
> > head(p,5)
1 2 3 4 5
1551.48 1551.48 1551.48 1551.48 1551.48