使用Python对淘宝用户行为进行数据分析
淘宝用户数据分析
- 1 分析背景与意义
- 2 分析思路
- 3 分析内容
- 3.1 提出问题
- 3.2 理解数据
- 3.3 数据清洗
- 3.3.1 数据导入
- 3.3.2 缺失值分析
- 3.3.3 选取时间范围
- 3.3.4 时间格式处理
- 3.4 构建模型
- 3.4.1 用户行为转化(AARRR模型)
- 3.4.2 用户活跃时间
- 3.4.3 用户价值分析(RFM模型)
- 3.4.4 用户产品偏好
- 4 结论与建议
- 参考资料
1 分析背景与意义
淘宝网是中国深受欢迎的网购零售平台,拥有近5亿的注册用户数,每天有超过6000万的固定访客,同时每天的在线商品数已经超过了8亿件,平均每分钟售出4.8万件商品。
用户行为分析则是电商平台的重要事务,通过对用户行为的分析,有助于企业根据用户的行为习惯,找出网站、推广渠道等企业营销环境存在的问题,从而让企业的营销更加精准、有效,提升企业的广告收益。
2 分析思路
针对数据集中的用户、商品、商品种类、用户行为、时间等信息,使用Python对数据进行切片分类汇总等多种数据分析手段,从不同角度挖掘蕴含的价值。本次通过以下四个方向探索淘宝用户行为:

3 分析内容
3.1 提出问题
本次通过对淘宝用户行为数据分析,期望解决以下业务问题:
1) 用户从浏览到最终购买整个过程的流失情况,确定夹点位置。
2) 找出用户最活跃的日期以及活跃时间段,了解用户的行为时间模式。
3) 找出最具价值的核心付费用户群。
4) 找出最受用户青睐的产品。
3.2 理解数据
数据集:UserBehavior.csv。本次报告随机采集了在2017年11月25日至2017年12月3日之间,淘宝用户的行为,其中行为包括浏览、加购物车、收藏、购买等。数据集主要包含:用户数量约3万(37,376),商品数量约9万(930,607),商品类目数量7106以及总的淘宝用户行为记录数量为3百万(3,835,329)。
数据来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1
字段含义:
| 列名称 | 说明 |
|---|---|
| User ID | 整数类型,序列化后的用户ID |
| Item ID | 整数类型,序列化后的商品ID |
| Category ID | 整数类型,序列化后的商品所属类目ID |
| Behavior type | 字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| Timestamp | 行为发生的时间戳 |
用户行为类型共有四种,它们分别是:
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
3.3 数据清洗
3.3.1 数据导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
path = './data/UserBehavior.csv'
data_user = pd.read_csv(path)
cols = ['UserID', 'ItemID', 'CatogoryID', 'BehaviorType', 'TimeStamps']
data_user.columns = cols
data_user.head()
3.3.2 缺失值分析
data_user.apply(lambda x: sum(x.isnull()))
仅一条数据含有缺失值,删除即可。
3.3.3 选取时间范围
import time
def get_unixtime(timeStr):
formatStr = "%Y-%m-%d %H:%M:%S"
tmObject = time.strptime(timeStr, formatStr)
tmStamp = time.mktime(tmObject)
return int(tmStamp)
# 数据集描述的时间范围
startTime = get_unixtime("2017-11-25 00:00:00")
endTime = get_unixtime("2017-12-3 23:59:59")
# 筛选出符合时间范围的数据
data_user['TimeStamps'] = data_user['TimeStamps'].astype('int64')
data_user = data_user.loc[(data_user['TimeStamps'] >= startTime) & (data_user['TimeStamps'] <= endTime)]
3.3.4 时间格式处理
#时间处理
data_user['time'] = data_user['TimeStamps'].apply(lambda t: time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(t)))
data_user['date'] = data_user['time'].str[0:10]
data_user['hour'] = data_user['time'].str[11:13].astype(int)
data_user['date'] = pd.to_datetime(data_user['date'])
data_user.head()

3.4 构建模型
3.4.1 用户行为转化(AARRR模型)
跳失率计算:
跳失率 = 只浏览一个页面就离开的访问次数 / 该页面的全部访问次数
结果显示只有点击行为没有收藏、加购物车以及购买行为的总用户数是2196,除以总用户数37376得到跳失率为5.88%。说明用户对商品详情页的关注很大,商品详情页的商品描述,细节等吸引点不足,是流失用户的的重要原因之一。具体造成用户在浏览商品详情页后流失的原因,要根据实际情况分析,建议可以采用在线问卷调查的方式get用户的痛点,针对性调整。
日ARPPU计算:
ARPPU全称为Average Revenue Per Paying User,也就是每付费用户平均收益。这个指标考核的是某时间段内平均每个付费用户为应用创造的收入。在用户数量上,ARPPU只考虑某一时间段内的付费用户,而非该时间段内所有的活跃用户。
对于同一时间的同一应用而言,ARPPU的数值会明显高于ARPU。
ARPPU能够反映付费用户为你的应用带来了多少收益,显示出一个忠诚付费用户实际上愿意支付的金额。同时,这个指标也可以显示用户对一些付费项目的反应。
data_user_buy1 = data_user[data_user.BehaviorType == 'buy'].groupby(['date','UserID']).count()['BehaviorType'].reset_index().rename(columns={'BehaviorType':'total'})
data_user_buy2 = data_user_buy1.groupby('date').sum()['total'] / data_user_buy1.groupby('date').count()['total']
plt.figure(figsize=(10,7))
data_user_buy2.plot()
plt.ylabel('日ARPPU')
plt.title('ARPPU变化情况')
plt.savefig('ARPPU变化情况')
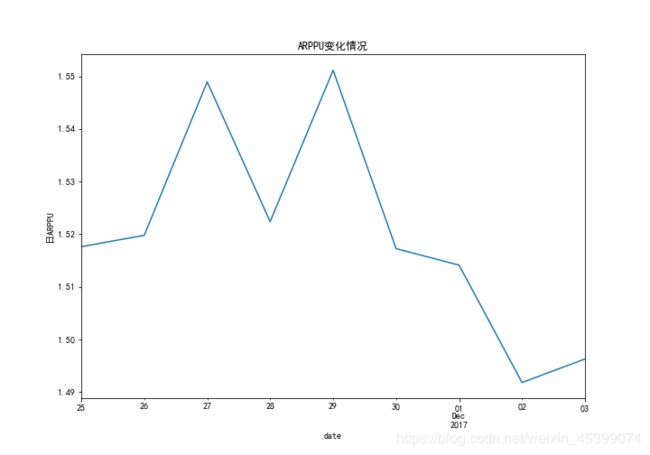

由图像可以看出,在12月2日及12月3日的日ARPPU为最低位,分析可能是由于高的PV值但实际消费的用户数并不多。
日ARPU计算:
ARPU的全称是Average Revenue Per User,也就是每用户平均收入。这个指标计算的是某时间段内平均每个活跃用户为应用创造的收入。
ARPU的计算中,所有的用户都被纳入了计算范围——无论是付费用户或非付费用户。ARPU是评估应用变现有效性的指标:ARPU越高,就代表用户在这段时间内为应用带来的变现收入就越多。
ARPU可用于评估应用中的变动是否能有效提升变现收益:如果ARPU提升,证明应用的变动有利于提升应用变现收益;如果ARPU不升反降,应用开发者可能就需要确认一下变动的有效性了。
data_user['operation'] = 1
data_user_buy2 = data_user.groupby(['date', 'UserID', 'BehaviorType'])['operation'].count().reset_index().rename(columns = {'operation':'total'})
#每天消费总次数/每天总活跃人数
data_user_buy2.groupby('date').apply(lambda x: x[x['BehaviorType'] == 'buy'].total.sum()/len(x.UserID.unique()) ).plot()
plt.ylabel('日ARPU')
plt.title('ARPU变化情况')
plt.savefig('ARPU变化情况')
#(付费率)每天消费人数/每天总活跃人数
data_user_buy2.groupby('date').apply(lambda x: x[x['BehaviorType'] == 'buy'].total.count()/len(x.UserID.unique()) ).plot()
plt.ylabel('付费率')
plt.title('付费率变化情况')
plt.savefig('付费率变化情况')

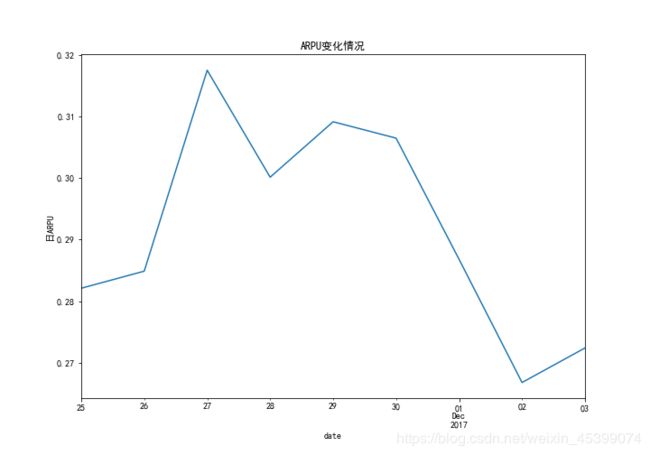
日ARPU图像、付费率图像相似,均在12月2日和12月3日处于低位,而在工作日处于较高的水平。
用户行为情况
# 多子图绘制 如:将上面用到的图形一起绘制
# 导入subplots(类似matplotlib)
from plotly.subplots import make_subplots
labels = df_userbehavior['behavior']
# Create subplots: use 'domain' type for Pie subplot
fig = make_subplots(rows=1, cols=2, specs=[[{'type':'domain'}, {'type':'domain'}]])
fig.add_trace(go.Pie(labels=labels, values=data_user_count.values, name="淘宝用户行为"),
1, 1)
fig.add_trace(go.Pie(labels=labels, values=df_userbehavior['count'], name="淘宝独立用户行为"),
1, 2)
# Use `hole` to create a donut-like pie chart
fig.update_traces(hole=.4, hoverinfo="label+percent+name")
fig.update_layout(
title_text="淘宝用户行为情况 | 左:淘宝用户行为, 右:淘宝独立用户行为",
# Add annotations in the center of the donut pies.
annotations=[dict(text='非独立', x=0.18, y=0.5, font_size=20, showarrow=False),
dict(text='独立', x=0.8, y=0.5, font_size=20, showarrow=False)])
fig.show()

用户点击行为占总行为数的89.5%,收藏和加购行为加起来的行为数只占总行为数的8.47%,而对于独立用户来说,点击行为的占比明显缩小为35.2%。推测用户可能在挑选产品环节浪费了较多的时间。
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker
attr = ['浏览', '放入购物车', '收藏', '购买']
value = [3431904, 213634, 111140, 76707] #这里有个bug
funnel = Funnel()
funnel.add("淘宝用户行为", [list(z) for z in zip(attr, value)])
funnel.set_global_opts(title_opts=opts.TitleOpts(title="淘宝用户行为"))
funnel.render("funnel_base.html")
funnel.render_notebook()

| 项目 | 流失率 |
|---|---|
| pv_to_cart | 93.78% |
| cart_to_fav | 47.98% |
| fav_to_buy | 30.98% |
| pv_to_buy | 97.76% |
从点击到购买的全过程中,流失率主要集中在点击到加入购物车这一环节,流失率高达93.78%,收藏及加入购物车后购买商品的可能性增大。
用户留存率
留存用户:在某段时间开始使用产品,经过一段时间后仍然继续使用产品的用户,即为留存用户。
留存率=仍旧使用产品的用户量/最初的总用户量。
根据时间维度进行分类,留存率经常分为次日留存、3日留存、7日留存以及30日留存等。
from datetime import timedelta
#建立n日留存率计算函数
def cal_retention(data,n): #n为n日留存
user=[]
date=pd.Series(data.date.unique()).sort_values()[:-n] #时间截取至最后一天的前n天
retention_rates=[]
new_users=[]
retention_user=[]
for i in date:
new_user=set(data[data.date==i].UserID.unique())-set(user) #识别新用户,本案例中设初始用户量为零
user.extend(new_user) #将新用户加入用户群中
#第n天留存情况
user_nday=data[data.date==i+timedelta(n)].UserID.unique() #第n天登录的用户情况
a=0
for UserID in user_nday:
if UserID in new_user:
a+=1
b = len(new_user)
retention_rate=a/b #计算该天第n日留存率
retention_rates.append(retention_rate) #汇总n日留存数据
new_users.append(b) #汇总n日的新用户数
retention_user.append(a) #汇总n日留存的用户数
data_new_user = pd.Series(new_users, index=date)
data_retention_user = pd.Series(retention_user, index=date)
data_retention_rate = pd.Series(retention_rates,index=date)
data_retention = pd.concat([data_new_user,data_retention_user,data_retention_rate], axis=1)
data_retention.columns=['new_user','retention_user','retention_rate']
return data_retention
data_retention1=cal_retention(data_user,1)
data_retention2=cal_retention(data_user,2)
data_retention6=cal_retention(data_user,6)
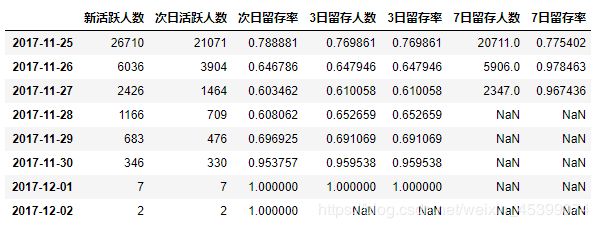
用户的次日留存率及3日留存率均约为60%-70%的范围内,现有数据可以看出7日的留存率较高,推测是由于临近双十二,商家纷纷举办活动,促使留存率提高。可继续观测留存率等指标,以确定留存率的变化规律。
复购

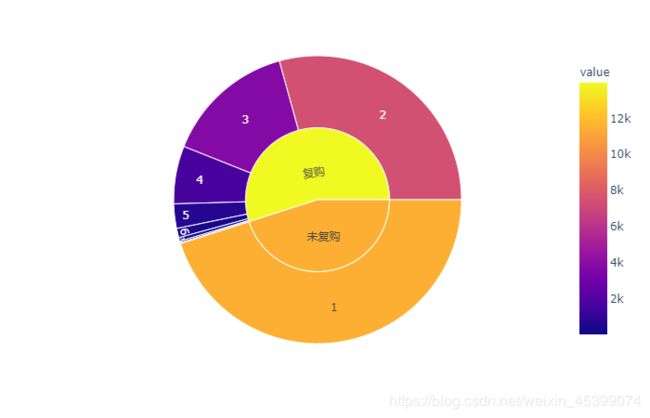
data_rebuy[data_rebuy>=2].count()/data_rebuy.count()
复购率=54.94%


淘宝平台和用户的粘性很高,9日内的复购率达到54.94%。但有的用户购买次数高达到84次。9天里有84次的购买行为,平均一天有9次购买行为,这不符合常理,为什么他们的购买次数如此高呢?是否存在刷单现象?进一步分析验证购买次数较高的用户平时购买情况,以及账户,购物,物流等信息才能判断。这里数据有限,不深入探究其原由。
3.4.2 用户活跃时间
找出用户最活跃的日期以及活跃时间段,了解用户的行为时间模式。
按日统计流量指标
pv_daily = data_user.groupby('date').count()['UserID']
uv_daily = data_user.groupby('date')['UserID'].apply(lambda x: x.drop_duplicates().count())
pv_uv_daily = pd.concat([pv_daily,uv_daily], axis=1)
pv_uv_daily.columns=['pv','uv']
pv_uv_daily
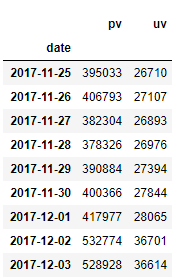


可以发现,PV与UV的每日变化趋势大致相同:工作日维持在低值,其中周二(11-27)的访问量达到统计范围内最低值;而11月25日、11月26日和12月2日、12月3日同为周末,但后者却有更多的活跃用户,环比增长率约为32%,推测可能是平台做促销活动。检索可知正值“双十二”前夕,各类预热活动促进用户访问增长。
按小时统计流量指标

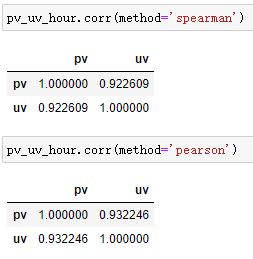
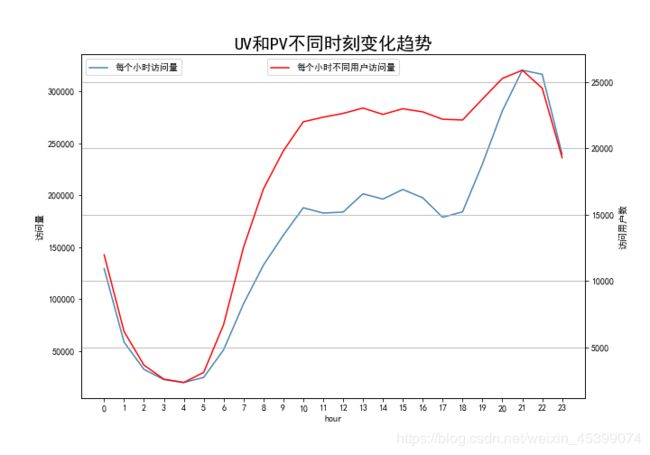
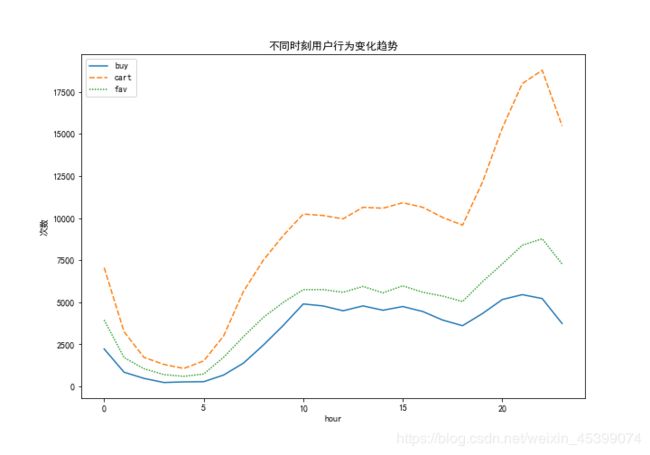
结合人们日常作息规律,0点至6点是休息时间,点击量处于低谷阶段;6点至10点,人们慢慢开始工作,点击量开始回暖;10点至18点为正常工作时间,点击量保持平稳;18点至20点,人们相继下班休息,点击量不断升高;在21点至22点期间,点击量到达高峰。
| 项目 | 数值 |
|---|---|
| pv | 3833385 |
| uv | 264304 |
| pv/uv | 14.50 |
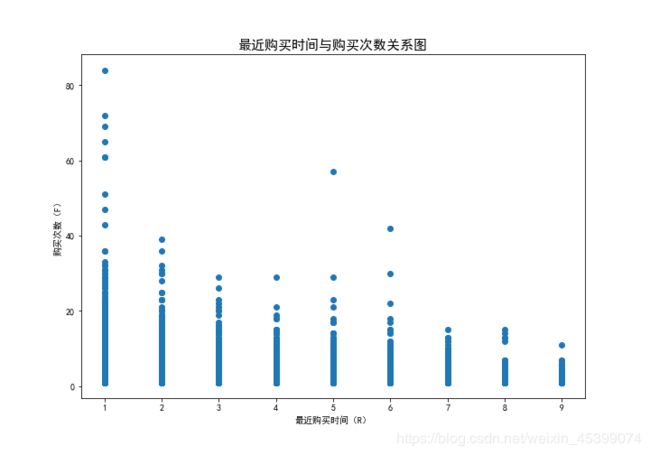
3.4.3 用户价值分析(RFM模型)
因为本数据集没有提供M(消费金额)列,因此只能通过R(最近一次购买时间)和F(消费频率)的数据对客户价值进行打分。
| RFM | 业务含义 | 1分 | 2分 |
|---|---|---|---|
| R | 最近交易日期与2017.12.4距离天数 | 3~9 | 0~3 |
| F | 购买次数 | 0~2 | 2~84 |
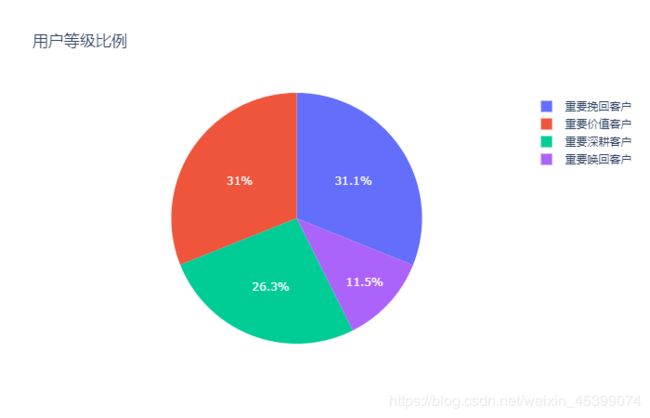
其中,
RF=11为重要挽回客户;
RF=12为重要唤回客户;
RF=21为重要深耕客户:
RF=22为重要价值客户。
trace_basic = [go.Bar(x = rfm['rank'].value_counts().index,
y = rfm['rank'].value_counts().values,
marker = dict(color='orange'), opacity=0.50)]
layout = go.Layout(title='用户等级情况', xaxis=dict(title='用户重要度'))
figure_basic = go.Figure(data=trace_basic, layout=layout)
figure_basic
trace = [go.Pie(labels=rfm['rank'].value_counts().index,
values = rfm['rank'].value_counts().values,
textfont = dict(size=12,color='white'))]
layout = go.Layout(title='用户等级比例')
figure_pie = go.Figure(data=trace, layout=layout)
figure_pie

3.4.4 用户产品偏好
商品
fig = plt.figure(figsize=(16,12))
#柱形图
ax1 = fig.add_subplot(111)
ax1.bar(data_item_count.index, data_item_count.values)
for a,b in zip(data_item_count.index,data_item_count.values):
plt.text(a, b+100,'%s'% b, ha='center', va= 'bottom',fontsize=10)
#平滑化
from scipy import interpolate
x = data_item_count.index
y = df_item_count['percentage']
tck = interpolate.splrep(x, y, s=0)
xnew = np.linspace(x.min(),x.max(),100)
ynew = interpolate.splev(xnew, tck, der=0)
#折线图
ax2 = ax1.twinx()
ax2.plot(xnew, ynew, label="percentage", color='red')
ax1.set_ylabel('商品数目')
ax2.set_ylabel('所占百分比')
ax2.set_xlabel('购买次数')
plt.title('商品销售分布', fontsize=25)
plt.savefig('商品销售分布')
plt.show()
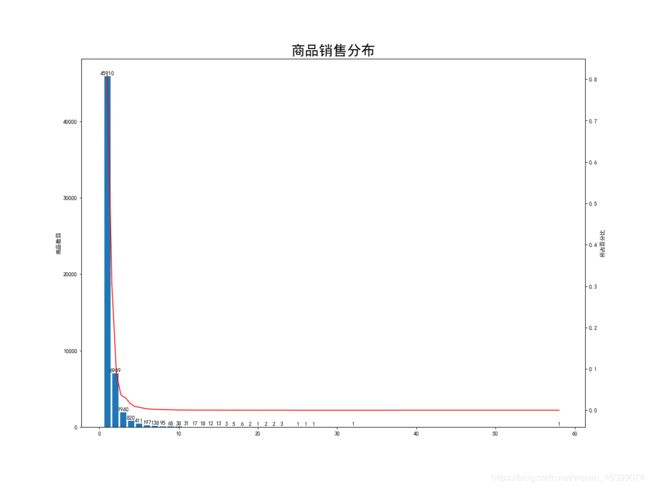
没有出现购买数量非常集中的商品,说明店铺盈利主要依靠长尾商品的累积效应。在电子商务行业中,相较于传统零售行业成本减少,使得后80%的商品也可以销售出去,并且实现盈利,因此将长尾部分的商品优化推荐好,能够给企业带来更大的收益。
商品种类
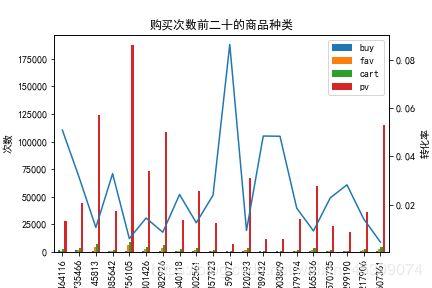
ax1 = df_catogory_buy[['buy', 'fav', 'cart', 'pv']].plot.bar()
ax2 = ax1.twinx()
df_catogory_buy.index = df_catogory_buy.index.astype(str)
ax2.plot(df_catogory_buy.index, df_catogory_buy[['buy/pv']])
ax1.set_ylabel('次数')
ax2.set_ylabel('转化率')
plt.title('购买次数前二十的商品种类')
plt.savefig('购买次数前二十的商品种类')
import plotly.express as px
fig = px.treemap(
df_buy, path=['CatogoryID'], values='购买次数', title='购买次数前二十的商品种类'
)
fig.show()
fig = px.treemap(
df_item_buy, path=['CatogoryID','ItemID'], values='count', title='商品购买情况(销量前100)'
)
fig.show()


4 结论与建议
本报告基于AARRR模型和RFM模型,从四个维度提出关于淘宝业务问题。
A. 通过AARRR模型分析用户行为转化的各个环节
获取用户(Acquisition)
根据12月2日和12月3日活跃用户明显增长,推测在此期间店铺举办了营销活动。检索可知正值“双十二”前夕,各类预热活动促进用户访问增长。
获取用户意味着需要拓展页面流量,相对较大型的电商营销活动至少可以从以下三个方面获取流量:
- 充分利用站内资源
- 跨行合作
- 产品功能辅助流量增长(场次预约、SNS后置奖品分享)
激活用户(Activation)
计算跳失率为5.88%,独立访客从浏览到购买的转化率为xxx%,说明产品详情页对用户有着不错的吸引力;但从用户行为转化漏斗来看,用户行为转化夹点位置在点击-加购环节,其中用户点击行为占总行为数的89.50%,而收藏和加购行为加起来的行为数只占总行为数的8.47%,推测用户可能在挑选产品环节浪费了较多的时间,另外低购买意愿转化率还可能与刚完成的双11大促有关。
提高加购转化率的建议:
- 优化搜索引擎,利用用户画像优化商品匹配,个性化地推荐用户感兴趣的商品
- 优化商品界面加购与收藏按键布局,以便用户触达
- 分析双十一活动对双十二的影响,合理设置活动内容
留存用户(Retention)
用户留存其指标之于电商就是回访率。用户的次日留存率及3日留存率均约为60%-70%的范围内,现有数据可以看出7日的留存率较高,推测是由于临近双十二,商家纷纷举办活动,促使留存率提高。
活动基本都会划分为三个阶段:
- 预热期:预约造势,通过sns、定金裂变等玩法吸引用户关注
- 正式期:前面如果证实是好的激励体系,可以让活动健康持续发展
- 高潮期:进一步引爆高潮,使用的激励方式,成长值会员体系、签到体系、积分任务体系等
增加收入(Revenue)
在有购买行为的用户中,54.94%的用户选择重复购买。
对于用户复购情况,9天内网站有复购现象的用户数接近60%,但是总体上约30%的用户产生了80%的消费次数,复购次数多的用户偏少,可能与双11刚结束,双12未开始的特殊时段有关,建议拉长分析区间分析复购情况。
提高收入的建议:
- 开展营销活动,比如淘宝的达成金主的条件限制,鼓励用户复购
- 在客户发生首购行为后,定时通过客服/短信发放特殊优惠,以提高复购率
- 优惠券的和优惠策略的在制定时需考虑成本,充分使用推广资金
自传播(Refer)
通过自传播获取用户的成本很低,而且效果有可能非常好,唯一的前提是产品自身要足够好,有很好的口碑。因此平台需要建立对产品的质量监控机制,如在产品的差评率较高时需对产品进行检测。
- 优化产品,保证产品的质量
- 提高服务售前及售后质量
B. 研究用户时间模式,找到用户在不同时间周期下的活跃规律
a) 分析2017年11月25日至12月3日9天里用户每天的点击量:
发现工作日维持在低值,其中周二(11-27)的访问量达到统计范围内最低值;而11月25日、11月26日和12月2日、12月3日同为周末,但后者却有更多的活跃用户,环比增长率约为32%,推测可能是平台做促销活动。检索可知正值“双十二”前夕,各类预热活动促进用户访问增长。
b) 分析2017年11月25日至12月3日9天里用户每时段的点击量:
结合人们日常作息规律,0点至6点是休息时间,点击量处于低谷阶段;6点至10点,人们慢慢开始工作,点击量开始回暖;10点至18点为正常工作时间,点击量保持平稳;18点至20点,人们相继下班休息,点击量不断升高;在21点至22点期间,点击量到达高峰。高峰期用户最活跃,建议商家在用户该时段,经常更新产品信息,黄金展位,活动推荐商品等 。
C. 通过RFM模型对用户价值分层
通过RFM模型分析得到的不同类型的用户,应该采取不同的激励方案。
对于RF=22的重要价值客户,应该提高满意度,增加留存。
对于RF=21的重要深耕客户,可通过折扣或捆绑销售等活动,提高购买频率。
对于RF=12的重要唤回客户,分析其偏好,更精准地推送商品,以防流失。
对于RF=11的重要挽回客户,可考虑发放限时优惠券,促进关注与消费。
D. 找出用户产品偏好,制定商品营销策略
用户偏好商品类别里并没有出现购买数量非常集中的商品,说明商品售卖主要依靠长尾商品的累积效应,而非爆款商品的带动,这也是双11之后用户的补充采买的特征,同时发现此时用户购买的品类以及商品的浏览量很低,用户的个人喜好特征表现明显,同时浏览量高的商品购买转化率低。
对于高浏览量商品,可以将重心转移至定价上,实行差异化定价,同时改善商品页面、详情页以及评论区的管理,以提高购买量
对于高购买率商品,建议提高曝光率,结合多平台宣传,提高浏览量
对于明星商品,建议平台给予表扬与内部公开,以保证持续的优质
参考资料
[1] http://www.zuopm.com/data/188.html
[2] https://blog.csdn.net/MsSpark/article/details/86727058
[3] https://zhuanlan.zhihu.com/p/63853715