快速上手百度大脑EasyDL专业版·物体检测模型(附代码)
作者:才能我浪费99
1. 简介:
1.1. 什么是EasyDL专业版
EasyDL专业版是EasyDL在2019年10月下旬全新推出的针对AI初学者或者AI专业工程师的企业用户及开发者推出的AI模型训练与服务平台,目前支持视觉及自然语言处理两大技术方向,内置百度海量数据训练的预训练模型,可灵活脚本调参,只需少量数据可达到优模型效果。
适用人群:
专业AI工程师且追求灵活、深度调参的企业或个人开发者
支持定制模型类型。
1.2. 支持视觉及自然语言处理两大技术方向:
视觉:支持图像分类及物体检测两类模型训练。
任务类型: 预置算法
图像分类: Resnet(50,101)、Se_Resnext(50,101)、Mobilenet Nasnet
物体检测: FasterRCNN、YoloV3、mobilenetSSD
自然语言处理:支持文本分类及短文本匹配两类模型训练,内置百度百亿级数据所训练出的预训练模型ENNIE.
ERNIE(艾尼)是百度自研持续学习语义理解框架,该框架可持续学习海量数据中的知识。基于该框架的ERNIE2.0预训练模型,已累计学习10亿多知识,中英文效果全面领先,适用于各类NLP应用场景。
任务类型 :预置网络
文本分类: BOW、CNN、GRU、TextCNN、LSTM、BiLSTM
短文本匹配:SimNet(BOW、CNN、GRU、LSTM)、FC
1.3. EasyDL专业版特点
预置百度百亿级数据规模的预训练模型,包括丰富的视觉模型及自然语言处理模型ERNIE,训练效果更突出。
对比经典版,支持代码级调整模型参数和模型结构,封装底层算法逻辑细节,代码行数更少,更易有算法基础的开发者上手。
支持从数据管理,模型训练到模型部署一站式AI服务。
如果说EasyDL经典版是倚天剑,PaddlePaddle是屠龙刀,那么EasyDL专业版就是刀剑合璧。
2. 评测案例
该应用为一个特种车辆识别的应用,主要识别邮车和消防车,未来可以扩展加入更多的车辆种类,对于特种车辆管理有很好的应用价值。
2.1. 整体说明
EasyDL专业版的工作流程如下图所示:

EasyDL专业版的主界面如下图所示:

2.2. 业务需求:
需要对各种特种车辆进行识别,在本评测中为邮车、消防车两种。
2.3. 上传并标注数据:
首先需要建立特种车辆数据集,在主界面上点击“数据管理/标注”就可以进入数据管理界面,具体步骤如下:
- 设计标签
在上传之前确定想要识别哪几种物体,并上传含有这些物体的图片。每个标签对应想要在图片中识别出的一种物体。在本例中只有2个标签,就是邮车(标签:youche)和消防车(标签:xiaofang)。
例如:

- 准备图片
基于设计好的标签准备图片:
每种要识别的物体在所有图片中出现的数量最好大于50
如果某些标签的图片具有相似性,需要增加更多图片
一个模型的图片总量限制4张~10万张
图片格式要求:
• 目前支持图片类型为png、jpg、bmp、jpeg,图片大小限制在4M以内
• 图片长宽比在3:1以内,其中最长边小于4096px,最短边大于30px
图片内容要求:
• 训练图片和实际场景要识别的图片拍摄环境一致,举例:如果实际要识别的图片是摄像头俯拍的,那训练图片就不能用网上下载的目标正面图片。
• 每个标签的图片需要覆盖实际场景里面的可能性,如拍照角度、光线明暗的变化,训练集覆盖的场景越多,模型的泛化能力越强。
本例中从网上找了30多张不同角度的特种车辆图片。(因为是测试版,所以图片较少,实际应用的时候每种标签的图片不应少于50)
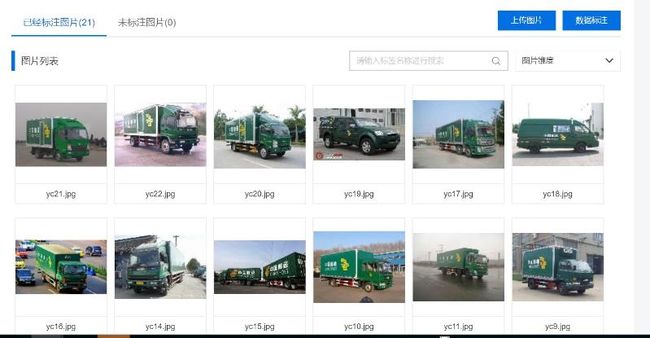
3. 上传和标注图片
先在【创建数据集】页面创建数据集:
如果训练数据需要多人分工标注,可以创建多个数据集。将训练数据分批上传到这些数据集后,再将数据集"共享"给自己的小伙伴,同步进行标注。
再进入【数据标注/上传】:
- 选择数据集
- 上传已准备好的图片
- 在标注区域内进行标注
首先在标注框上方找到工具栏,点击标注按钮在图片中拖动画框,圈出要识别的目标。
如下图所示:

然后在右侧的标签栏中,增加新标签,或选择已有标签
2.4. 创建项目和任务
在主界面点击“全部训练任务”即可进入项目界面:
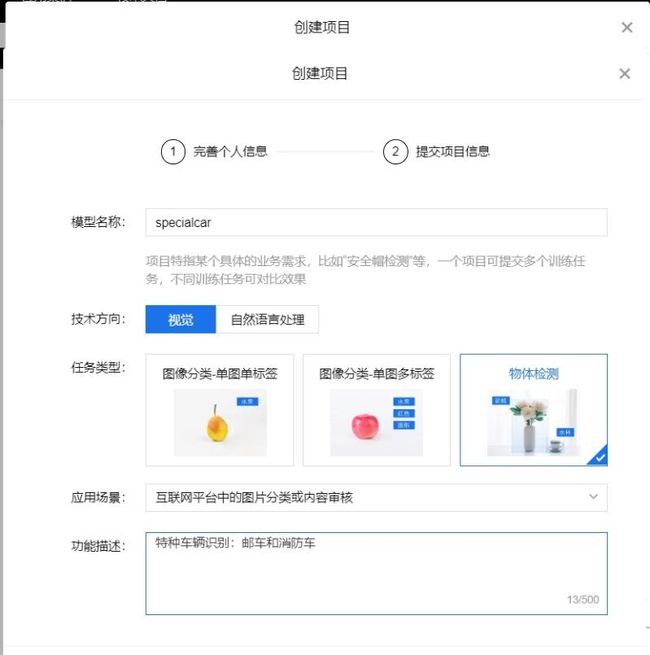
点击新建项目,填写相关信息信息,即可创建项目。

在本次评测中我们使用物体检测。
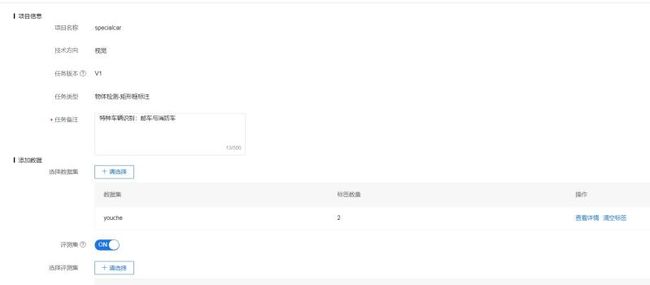
创建项目后在新建的项目内选择创建任务,以建立一个新的任务:

按要求输入信息,数据集及验证集选择我们上一步建立的数据集youche和youchevalid。
网络方面,因为我们这次主要是对位置进行确认,对BoundingBox要求不高,所以先选用YOLO。

大家看脚本编辑框里面的内容可以发现就是采用PaddlePaddle实现模型功能的Python代码。点击脚本编辑框里面的立即编辑按钮可以对生成的脚本进行编辑,方便进行客户化的定制。
选择保存就可以将任务保存。
2.5. 训练模型
在任务界面中点击提交训练任务,就可以开始训练模型,因为我们这次准备的数据不多,所以有一个提示,点击继续训练就好:
运行开始后可以看到本任务的状态为运行中:
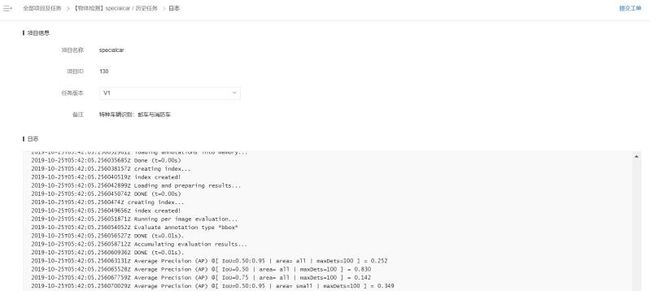
可以点击日志,查看运行情况:
训练时间与数据量大小有关,1000张图片可能需要几个小时训练,不过本评测案例因为只有不到40张图,所以速度很快。运行成功有界面如图:
2.6. 校验模型效果
可通过模型评估报告或模型校验了解模型效果:
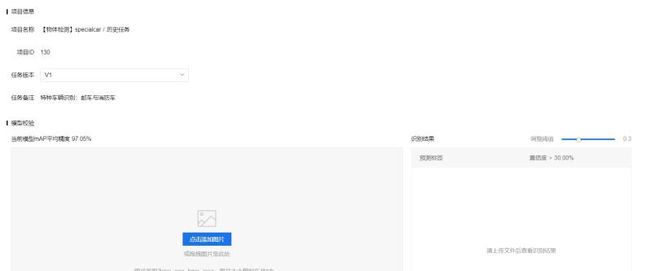
选择一张测试图:


感觉效果还可以,虽然BoundingBox有点偏差,不过主要是因为训练集太小以及采用了追求速度的YOLO算法。如果增加训练集以及采用FastRCNN会有不小的提升。
还可以选择“模型效果”查看模型信息:


2.7. 模型部署
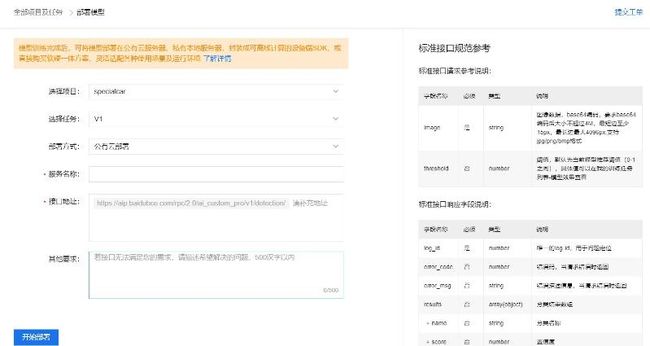
为了应用模型,需要对模型进行部署,点击“部署”按钮进入部署界面:

本次选择公有云部署,录入相关的信息,发布模型生成在线API:

发布后的服务,可以在“我的服务”中进行查看,修改:
2.8. 接口赋权
在正式使用之前,还需要做的一项工作为接口赋权,需要登录EasyDL控制台中创建一个应用,获得由一串数字组成的appid,然后就可以参考接口文档正式使用了
也可以直接点击服务界面的"立即使用"进入赋权界面:
3. 测试不同算法:
现在物体检测支持 FasterRCNN、YoloV3、mobilenetSSD,三种算法。我们在第2章使用的是YoloV3,在本章我们将对其他两种算法建立不同版本的服务,并互相进行对比。
3.1. 算法简介:
目标检测可以理解为是物体识别和物体定位的综合,不仅仅要识别出物体属于哪个分类,更重要的是得到物体在图片中的具体位置。因为具体算法内容很长,在这里只能进行一个简单的说明。
为了完成这两个任务,目标检测模型分为两类。一类是two-stage,将物体识别和物体定位分为两个步骤,分别完成,这一类的典型代表是R-CNN, fast R-CNN, faster-RCNN家族。他们识别错误率低,漏识别率也较低,但速度较慢,不能满足实时检测场景。为了解决这一问题,另一类方式出现了,称为one-stage, 典型代表是Yolo, YoloV2, YoloV3等。他们识别速度很快,可以达到实时性要求,而且准确率也基本能达到faster R-CNN的水平。
Faster R-CNN准确率mAP较高,漏检率recall较低,但速度较慢。而yolo则相反,速度快,但准确率和漏检率不尽人意。SSD综合了他们的优缺点。它的贡献在于它利用了多层网络特征,而不仅仅是FC7。
3.2. V2版(Fast RCNN):
在任务界面选择新建任务:
具体操作参考第2章的内容即可,区别在于网络选择Faster_R-CNN-ResNet50-FPN。训练后的模型效果如下所示:

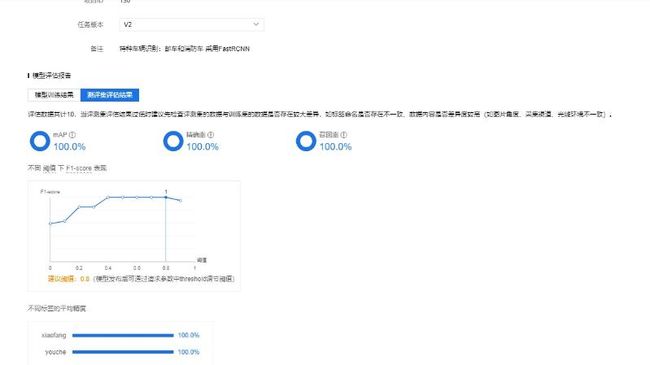
可以发现在评测集上,FasterRCNN算法的效果很好,让我们验证一下具体的效果。选择与V1版一样的图片进行验证,效果如下:

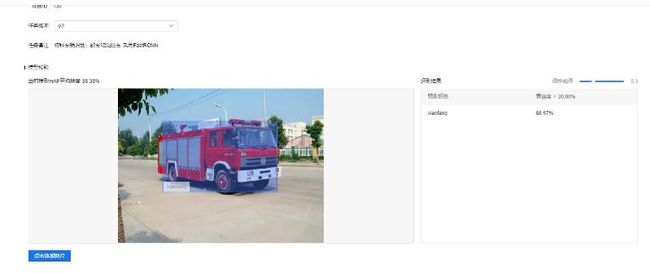
可以看到,效果的确比YOLOV3的效果要好一些,圈取的内容更加准确。
3.3. V3版(SSD):
具体操作参考第2章的内容即可,区别在于网络选择SSD。训练后的模型效果如下所示:
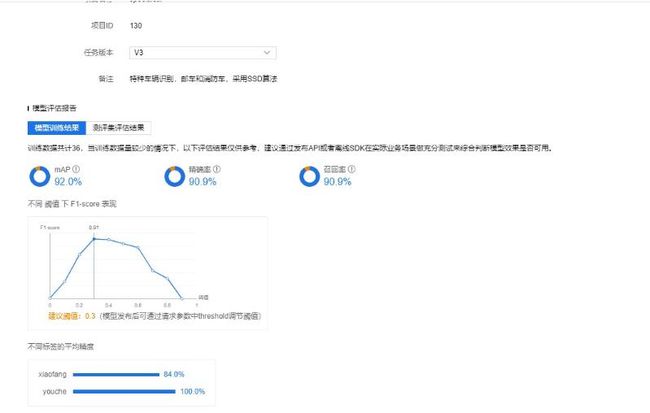
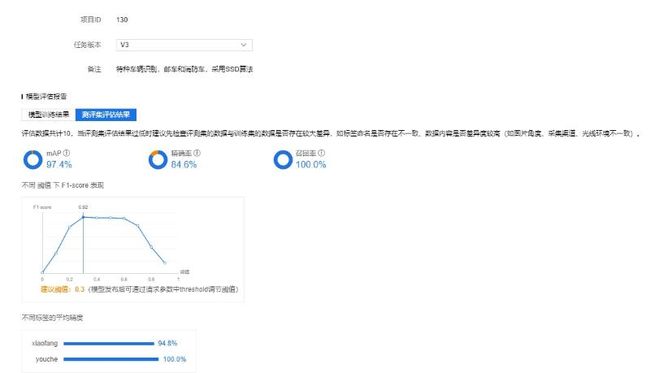
选择与V1版一样的图片进行验证,效果如下:
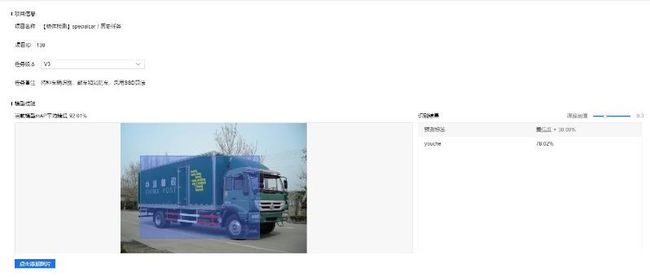

4. 应用评测及结论
4.1. 评测代码
按照服务API的说明,针对V1版(YOLOV3)的服务,编写调用代码(Python3)。需要注意的是与其他图像识别服务不同的是定制化图像识别服务以json方式请求。
Body请求示例:
{
“image”: “”
}
具体代码如下:
import urllib
import base64
import json
import time
import urllib3
#获取token
def get_token():
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret
request = urllib.request.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib.request.urlopen(request)
token_content = response.read()
#print (token_content)
if token_content:
token_info = json.loads(token_content)
token_key = token_info['access_token']
return token_key
#保存图片
def save_base_image(img_str,filename):
img_data = base64.b64decode(img_str)
with open(filename, 'wb') as f:
f.write(img_data)
#画识别结果
def draw_result(originfilename,results,resultfilename,fontsize):
from PIL import Image, ImageDraw,ImageFont
image_origin = Image.open(originfilename)
draw =ImageDraw.Draw(image_origin)
setFont = ImageFont.truetype('C:/windows/fonts/simhei.ttf', fontsize)
for result in results:
location=result['location']
draw.rectangle((location['left'],location['top'],location['left']+location['width'],location['top']+location['height']),outline = "red")
draw.text((location['left'],location['top']), result['name']+', Score:'+str(round(result['score'],3)),"blue",font=setFont)
image_origin.save(resultfilename, "JPEG")
def specialcar(filename,resultfilename,fontsize):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom_pro/v1/detection/specialcar"
# 二进制方式打开图片文件
f = open(filename, 'rb')
img = base64.b64encode(f.read())
access_token = get_token()
url=url+'?access_token='+access_token
begin = time.perf_counter()
#img参数进行一下str转换
params={'image':''+str(img,'utf-8')+''}
#对参数params数据进行json处理
encoded_data = json.dumps(params).encode('utf-8')
request=urllib3.PoolManager().request('POST',
url,
body=encoded_data,
headers={'Content-Type':'application/json'})
#对返回的byte字节进行处理。Python3输出位串,而不是可读的字符串,需要进行转换
content = str(request.data,'utf-8')
end = time.perf_counter()
print('处理时长:'+'%.2f'%(end-begin)+'秒')
if content:
#print(content)
data = json.loads(content)
#print(data)
results=data['results']
print(results)
draw_result(filename,results,resultfilename,fontsize)
4.2 测试结果:
首先是消防车及识别结果::


邮车及识别结果:


速度非常快,效果也很不错,虽然BoundingBox有点偏差,不过主要是因为训练集太小以及采用了追求速度的YOLO算法。如果增加训练集以及采用FasterRCNN会有不小的提升。
4.3. 评测结论
EasyDL专业版定会是深度学习开发者非常喜欢的一个功能,它将EasyDL图形开发的易用性及编程的灵活性结合在一起。在提供了很多便利的同时,又将控制权交给了客户,让客户可以更加灵活的使用深度学习技术,激发无限可能,感觉非常棒。后续我准备增加训练集再试一下,看看能提高多少,然后再尝试一下离线部署成Docker的效果,建议大家都试一下。
4.4. 评测后的优化建议:
希望百度后续能增加更多的模型,比如Mask RCNN等;
希望能支持不规则形状的BoundingBox。
希望后续增加数据导入导出功能。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
近期《百度大脑EasyDL深度实战营》专业版课程从3月4日至25日,每周三/四 晚8点在线直播,感兴趣的同学可以加入专业版QQ群:868826008进行学习讨论。
