本周AI热点回顾:文章自动变视频、无人出租今起免费坐、YOLO v4复活

01
YOLO项目复活,大神接过衣钵!
两个月前,YOLO 之父 Joseph Redmon 表示,由于无法忍受自己工作所带来的的负面影响,决定退出计算机视觉领域。此事引发了极大的热议,当我们都以为再也没有希望的时候,YOLO v4 却悄无声息地来了。这一目标检测神器出现了新的接棒者!
本月24日,YOLO 的官方 Github 账号更新了 YOLO v4 的 arXiv 链接与开源代码链接,迅速引起了 CV 社区的关注。YOLO v4 的作者共有三位:Alexey Bochkovskiy、Chien-Yao Wang 和 Hong-Yuan Mark Liao。其中一作 Alexey Bochkovskiy 是位俄罗斯开发者,此前曾做出 YOLO 的 windows 版本。
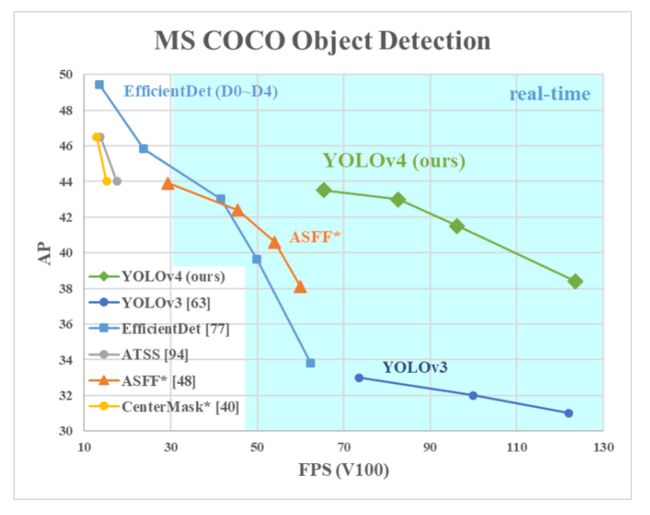
在相关论文中,研究者对比了 YOLOv4 和当前最优目标检测器,发现 YOLOv4 在取得与 EfficientDet 同等性能的情况下,速度是 EfficientDet 的二倍!此外,与 YOLOv3 相比,新版本的 AP 和 FPS 分别提高了 10% 和 12%。
许多特征可以提高 CNN 的准确率,然而真正实行起来,还需要在大型数据集上对这些特征组合进行实际测试,并且对测试结果进行理论验证。某些特征仅在某些模型上运行,并且仅限于特定的问题,或是只能在小型数据集上运行;而另外有些特征(如批归一化和残差连接)则适用于大多数模型、任务和数据集。
那么,如何利用这些特征组合呢?
YOLOv4 使用了以下特征组合,实现了新的 SOTA 结果:
加权残差连接(WRC)
Cross-Stage-Partial-connection,CSP
Cross mini-Batch Normalization,CmBN
自对抗训练(Self-adversarial-training,SAT)
Mish 激活(Mish-activation)
Mosaic 数据增强
DropBlock 正则化
CIoU 损失
据介绍,YOLOv4 在 MS COCO 数据集上获得了 43.5% 的 AP 值 (65.7% AP50),在 Tesla V100 上实现了 ∼65 FPS 的实时速度。
该研究的主要贡献如下:
建立了一个高效强大的目标检测模型。它使得每个人都可以使用 1080Ti 或 2080Ti 的 GPU 来训练一个快速准确的目标检测器。
验证了当前最优 Bag-of-Freebies 和 Bag-of-Specials 目标检测方法在检测器训练过程中的影响。
修改了 SOTA 方法,使之更加高效,更适合单 GPU 训练。这些方法包括 CBN、PAN、SAM 等。
YOLO v4 论文:
https://arxiv.org/abs/2004.10934
YOLO v4 开源代码:
https://github.com/AlexeyAB/darknet
信息来源:机器之心
02
我什么都没做,文章就自动变成了视频?丨百度研究院出品
人工智能技术,现在可以实现自动剪视频了。只要有一篇现成的图文链接,AI就可以根据图文描述的主题,重新组织语言,自动搜寻素材,剪出一条短视频。换句话说,如果看到有意思的新闻却懒得读文章,那就把你在读的这篇文章的地址输入给AI,文章就自动变成了短视频。
而且,这个过程只需要几分钟的时间,完全无人化自动操作,你下楼买了杯咖啡,视频就自动做好了。这个“AI做视频”技术来自百度研究院,产品的名字,叫做VidPress。
本质上,VidPress是做的事情是“图文转视频”,把人类写好的图文稿件重新编辑成视频:

比较之下,你会发现视频和文章的文案部分都是类似的,但视频中用到的素材却远不止文章中这么少,增加了许多人物和场景的动态镜头,而且相当契合主题。整个视频都是AI生成的,视频编辑只需要给出一篇文章的链接,过几分钟,热腾腾的视频就出锅了。
用VidPress来做视频,不需要视频编辑有任何技术背景,会复制粘贴就行。
首先,把需要改成视频的文章地址复制,粘贴到VidPress。
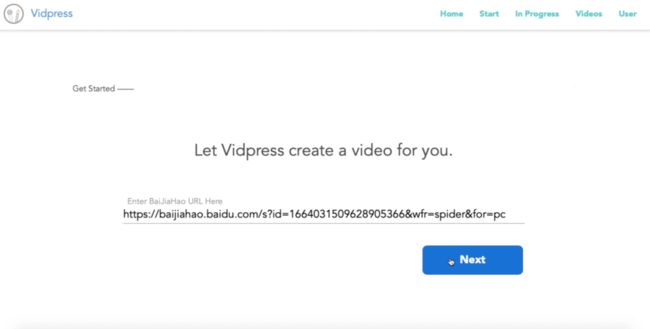
然后,选择用哪个声音合成,确定所需视频的长度以及分辨率。
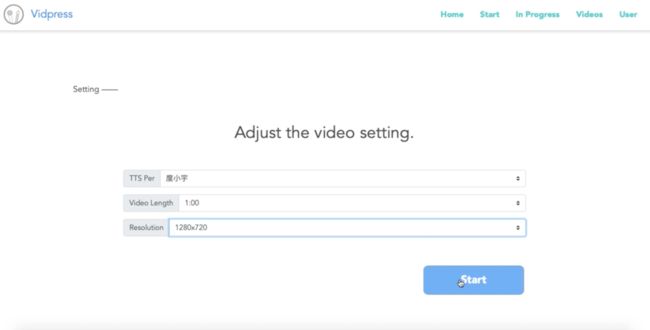
现在,视频编辑就可以放手让AI开始工作了。
获得图文内容后,AI会借助NLP模型进行语义理解,用主题模型聚合相关新闻和素材。
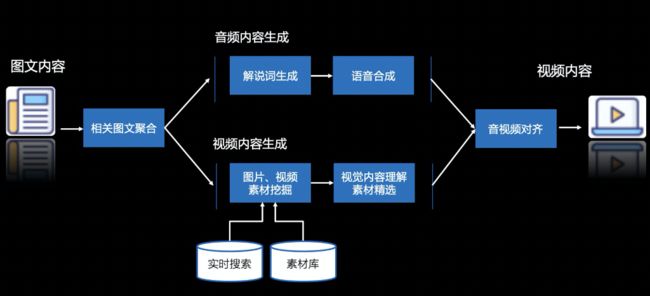
之后,需要分别完成音频和图像的编辑工作。
音频方面,系统会用多种语言模型处理解析原文,生成解说词,之后借助语音合成技术变成音频。
而图像方面,原文中的图片肯定是不太够的,需要再搜寻更多视频和图片素材。素材的来源可以是视频编辑自己的素材库,也可以直接实时的用百度搜索来找素材。
有了视频素材和解说词音频文件,需要把两者合二为一。在这个任务上,百度自研了两代对齐算法,第一代对齐算法是基于段落的对齐,第二代则是基于锚点的时间轴对齐算法。
第二代对齐的算法首先需要找出解说词里观众的兴趣点,然后再将搜到的素材和这些兴趣点,进行相关度打分,综合考虑素材的来源、相似度、图片/视频内容的贴合度、内容质量等方面。
之后,得分高的素材就率先被翻牌子,放到视频时间轴里兴趣点的位置。而剩下的素材就会被填充到空隙里,最后再对整个时间轴的内容分布进行调整。
现在,AI就把视频做好了,渲染一下,就是一个完整的视频。
信息来源:量子位
03
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
PaddleHub为开发者提供了飞桨生态下的各类高质量预训练模型,涵盖了图像分类、目标检测、图像生成、图像分割、语义模型、词法分析、情感分析、文本审核、视频分类、关键点检测等场景。开发者可以直接使用这些预训练模型结合PaddleHub Fine-tune API快速完成迁移学习到应用部署的全流程工作。
如今,PaddleHub经过去年一年的打磨,变得更加成熟,最新的1.6版本震撼来袭,新增五大亮点!
1. 助力抗疫,新增口罩佩戴检测模型和CT影像肺炎分割模型。
在全国人民紧张抗疫的时刻,2月13日飞桨PaddleHub开源了业界首个口罩人脸检测及分类模型。基于该模型检测设备可以在公共场所中扫描大量人脸的同时,把佩戴口罩和未佩戴口罩的人脸分别标注出来,快速识别出不重视、不注意病毒防护、心存侥幸的人员,减少公众的防疫安全隐患,同时构建更多的防疫公益应用。
模型在线体验:
https://www.paddlepaddle.org.cn/hub/scene/maskdetect
模型使用示例:
https://aistudio.baidu.com/aistudio/projectdetail/267322
2. NLP预训练模型升级,增加文本鉴黄模型,助力文本审查工作。
随着AI技术的发展,人力成本不断提高,深度学习模型在各行各业的应用领域越来越广阔,用户对于深度学习模型的应用与性能需求也在不断的增多。因此PaddleHub与时俱进,将应用较为广泛的自然语言处理(NLP)领域的模型库全面升级。
Porn Detection模型介绍:
https://www.paddlepaddle.org.cn/hublist?filter=en_category&value=TextCensorship
3. 全面集成Paddle Inference原生推理库,预测性能提升50%以上。
对于工业级部署而言,要求的条件往往非常繁多而且苛刻,例如推理速度快、内存占用小等等。新版本PaddleHub内置了飞桨原生推理库Paddle Inference。通过飞桨核心框架的计算图优化技术,针对不同平台和不同应用场景深度适配和优化,具备高吞吐、低时延的特点,使飞桨模型在服务器端可完成高性能预测部署。如图6所示,与升级前相比,无论是可直接推理模型(例如LAC、Senta),还是Fine-tune后的模型(例如ERNIE),其推理性能均提升50%以上。
4. 开放预训练模块制作流程,支持开发者贡献模块至PaddleHub平台。
在过去的一年中,PaddleHub的Fine-tune API功能受到广大用户的好评。同时了解到用户对于训练好的模型如何做到通过hub.Module(name="***")实现一键加载也十分感兴趣,而且将Fine-tune后模型用于部署推理成为了很多用户的刚需。相信有不少用户希望这道封印能够消失!

现在告诉大家一个“喜大普奔”的好消息!新版本PaddleHub开放预训练模型和Fine-tune模型转化为Module的流程,并且可以使用一键加载功能。
预训练模型转化为module教程:
https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/contribution/contri_pretrained_model.md
Fine-tune模型转化为module教程:
https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/finetuned_model_to_module.md
5. 新增Bert Service文本向量服务,支持对任意文本获得高质量语义表示。
对句子的向量化表达提取是文本理解任务中的重要环节。Bert Service是基于Paddle Serving框架的快速模型部署远程计算服务方案,如下所示,它可以让开发者仅使用一行命令,就可将PaddleHub中丰富的语义预训练模型转换为文本向量服务。然后用户可以通过远程调用API接口的方式使任务文本转换为高质量的向量表达,完成特征提取工作。
信息来源:飞桨PaddlePaddle
04
无人出租今起免费坐,只恨不是长沙人
从今天起,出门打出租不仅不花钱,还是无人驾驶的那种。
4月19日,百度Apollo——就那个自动驾驶业务,决定在推出3周年之际,送出自己的羊毛和福利:
RoboTaxi——无人驾驶出租,人人可坐,一律免单,长沙人民率先尝鲜。
还有长沙妹子夸赞:“在长沙可以打无人车啦,太靓赛啦!”
去年,百度就在长沙率先投放了第一批RoboTaxi,而且所用车辆,均是与一汽红旗专门打造的L4量产车型。
而现在,初步运营期已过,从安全到驾驶体验都得到验证。
于是百度借着Apollo三周年之庆,给长沙——从市民到游客,只要来长沙,就能免费呼叫无人驾驶出租车:
Apollo的Robotaxi服务,正式接入百度App和百度地图两大应用,全面开放给长沙这座城市。无论是长沙本地的人民,还是来到长沙的客人们,都可以在130平方公里的范围内乘坐自动驾驶出租车出行。
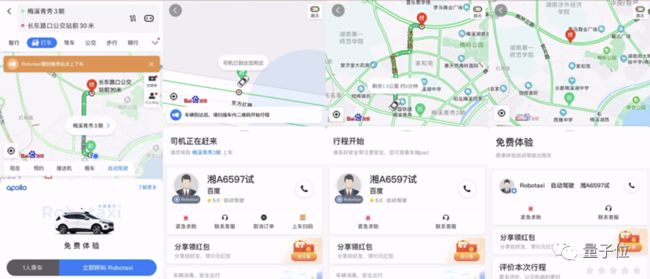
与之前面向种子用户的试运营不同,现在,只要人在长沙,不需要经过报名、筛选等流程,享受自动驾驶的服务没有任何门槛。而乘客安全一样会得到保障,有安全员坐镇,并且还是免费乘坐。

这也意味着,人们期盼多年的自动驾驶,现在终于落地成真了。
这也是首个通过国民级应用向公众开放的无人驾驶出租服务。从中不仅可以看出百度Apollo的诚意——毕竟人人可坐全部免费,更能看出自信——对安全和体验的绝对信心。
信息来源:量子位
05
本周论文推荐
【ACL 2020 | 百度】Conversational Graph Grounded Policy Learning for Open-Domain Conversation Generation
作者:Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
论文介绍:
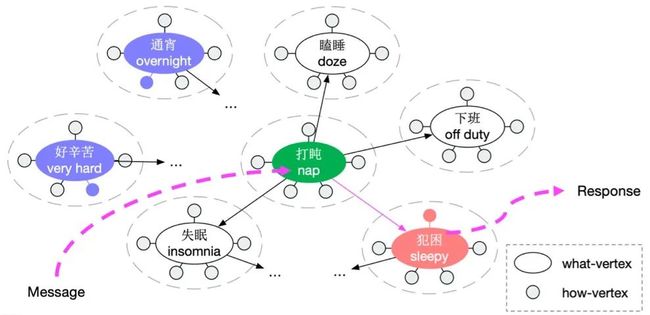
本论文提出用图的形式捕捉对话转移规律作为先验信息,用于辅助开放域多轮对话策略学习。
基于图,本论文设计策略学习模型指导更加连贯和可控的多轮对话生成。首先,从对话语料库中构造一个对话图(CG),其中顶点表示“what to say”和“how to say”,边表示对话当前句与其回复句之间的自然转换。然后,本论文提出了一个基于 CG 的策略学习框架,该框架通过图形遍历进行对话流规划,学习在每轮对话时从 CG 中识别出哪个顶点和如何从该顶点来指导回复生成。
本方法可以有效地利用CG来促进对话策略学习,具体而言:
(1)可以基于它设计更有效的长期奖励;
(2)它提供高质量的候选操作;
(3)它让我们对策略有更多的控制。
本论文经过两个基准语料库上进行了实验,结果证明了本文所提框架的有效性。
END
