python:免费看无广告小说之爬取全本免费小说网的小说
每天多地铁的时候网络差,网页都看不开,准备看点小说,阅读器上都只免费前几十章节,网上搜了搜,没找到能用的脚本,自己就简单写了一下
一、工作流程
1.打开网站:小说网站
2.搜到要看的小说
3.获取每章节的url
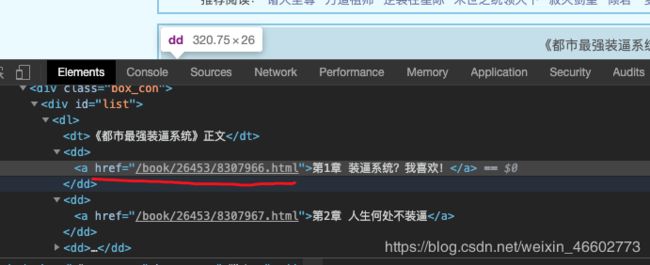
4.打开链接获取章节文本内容即可

5.写入txt文件内。

二、话不多少,直接上代码
自己用的,所以代码写的相对来说简单。因为一个网站上不一定会有所有想要的小说,所以写了两个网站的爬取,这样应该能搜到你想要的小说,爬取主模块是代码一样的
- 笔趣* 爬取代码
import re
import urllib.request
import ssl
#定义一个爬取网络小说的函
pageUrl = "https://www.biquge.com.cn/book/26453/";
txtName = "都市最强装逼系统1";
def getNovelContent():
ssl._create_default_https_context = ssl._create_unverified_context
html = urllib.request.urlopen(pageUrl).read()
html = html.decode("utf-8", 'ignore') #转成该网址的格式
reg = r'(.*?) ' #正则表达的匹配
reg = re.compile(reg) #可添加可不添加,增加效率
urls = re.findall(reg, html)
fileUrl = "/Users//Desktop/" + txtName + ".txt"
f = open(fileUrl, 'w')
for index in range(len(urls)):
# if(index != 0 and index <173):
# continue
url = urls[index]
# print(url)
str = url[0].replace("book/26453/", "")
str = str.replace("\"", "")
chapter_url = pageUrl + str
chapter_title = url[1] #章节的名字
print(chapter_title + "----", index)
try:
chapter_html = urllib.request.urlopen(chapter_url).read() #正文内容源代码
chapter_html = chapter_html.decode("utf-8", 'ignore')
chapter_content = re.findall('(.*?)', chapter_html, re.S)
except Exception as e:
print(e.message)
for content in chapter_content: #打印章节的内容
content = content.replace(" ", "\r") #把" "字符全部替换为""
content = content.replace("
", "\n") #把"
"字符全部替换为""
content = content.replace("
", "\n")
# content = content.replace("
", "\n")
content = content.replace("
", "")
#保存到文本
# print(content)
f.write("\n")
f.write(chapter_title)
f.write("\n")
f.write(content)
f.write("\n")
f.write("\n")
f.close()
if __name__ == '__main__':
getNovelContent()
- 88读*网的爬取代码
import re
import urllib.request
import ssl
#定义一个爬取网络小说的函数
pageUrl = "https://www.88dutxt.com/jipinzhuoyaoxitong/";
txtName = "极品捉妖系统";
def getNovelContent():
headers = {"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"}
ssl._create_default_https_context = ssl._create_unverified_context
req = urllib.request.Request(url=pageUrl, headers=headers)
html = urllib.request.urlopen(req).read()
html = html.decode("utf-8", 'ignore') #转成该网址的格式
reg = r'(.*?)'
content = re.findall(reg, html, re.S)[0]
# 1.第1章 我是特种兵
# 第一章 捉妖装逼系统
reg = re.compile(r'(.*?) ')
urls = re.findall(reg, content)
fileUrl = "/Users/xxxx/Desktop/" + txtName + ".txt"
f = open(fileUrl, 'w')
for index in range(len(urls)):
# if(index != 0 and index < 576):
# continue
url = urls[index]
# print(url)
chapter_url = pageUrl + url[0] + ".html"
chapter_title = url[2] #章节的名字
print(chapter_title + "----", index)
try:
chapter_req = urllib.request.Request(url=chapter_url, headers=headers)
chapter_html = urllib.request.urlopen(chapter_req).read() #正文内容源代码
chapter_html = chapter_html.decode("utf-8",'ignore')
chapter_content = re.findall('(.*?)', chapter_html, re.S)
except Exception as e:
print(e.message)
for content in chapter_content: #打印章节的内容
content = content.replace(" ", "\r") #把" "字符全部替换为""
content = content.replace("
", "\n") #把"
"字符全部替换为""
content = content.replace("
", "\n")
#保存到文本
# print(content)
f.write("\n")
f.write(chapter_title)
f.write("\n")
f.write(content)
f.write("\n")
f.write("\n")
f.close()
if __name__ == '__main__':
getNovelContent()
三、使用流程
1.笔趣* 小说网站
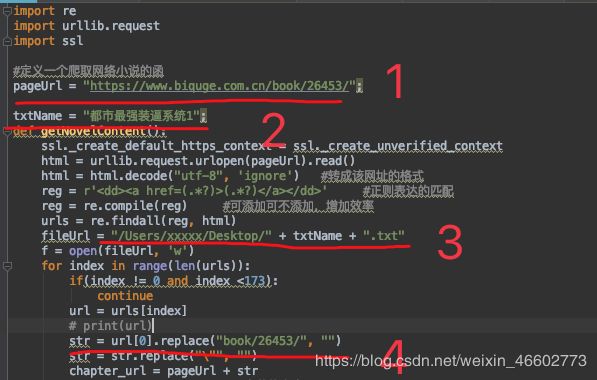
1.小说主页链接 ------ 就是带目录的那个页面
2.小说名字 ------ 要保存的文件名
3.文件写入路径 ------ 修改成你要的路径就行
4.保持和1的后缀一样即可 ------ 拼接章节链接用的
然后开始执行就行了
2.88读*网 小说网站

1.小说主页链接 ------ 就是带目录的那个页面
2.小说名字 ------ 要保存的文件名
3.文件写入路径 ------ 修改成你要的路径就行
四、 解决问题
1.网络不好爬取中断
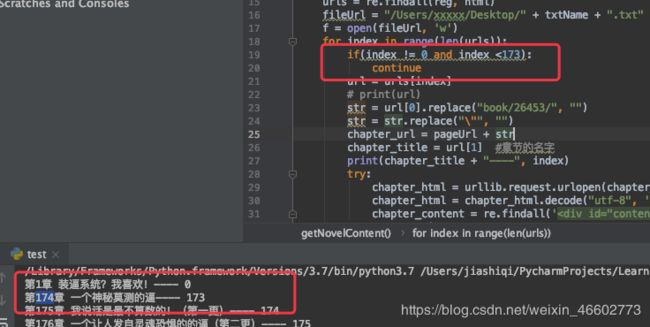
因为爬取有打印有下标,所以可以把图中注释解除,然后跳过之前爬取过得章节,不过记得修改一下上边第2点(2.小说名字 ------ 要保存的文件名)文件名,不然会之前爬取的文件会被覆盖掉。
当然,你可以优化一下代码。
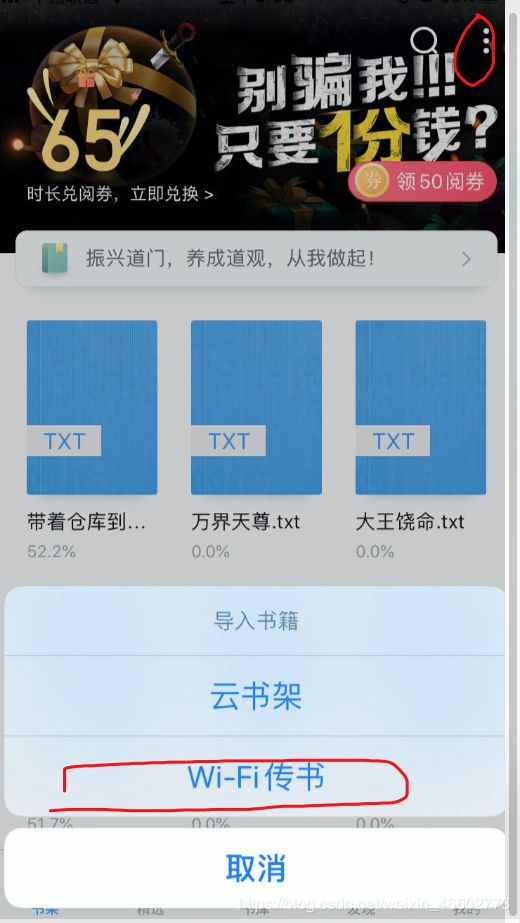
2. 爬取完,怎么导入到阅读器
本人用的是QQ阅读器,用wifi传书即可
- 打开wifi传书
- 电脑浏览器输入对应地址
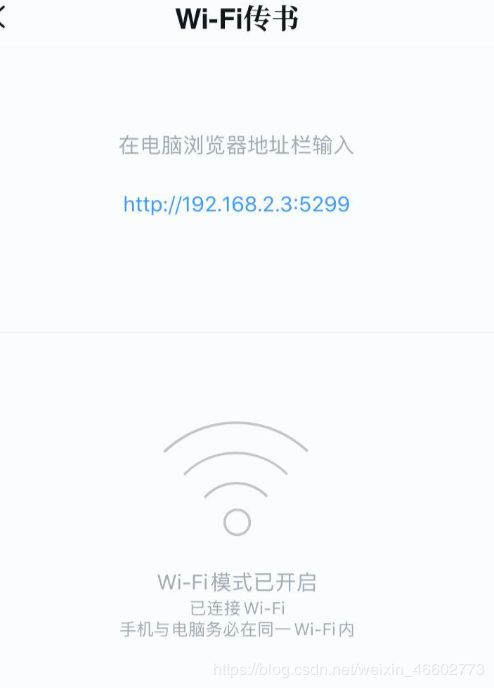
3.选择文件上传

4.当然是开始阅读了。
教程结束了,如有其它问题,可留言。