GlusterFS部署
转载:https://www.cnblogs.com/fansik/p/9868831.html
注意区分复制卷和分布式复制卷的区别?
答:纯复制卷brick=replica,分布式复制卷中brick数是replica倍数!
一、GlusterFS简介
PB级容量、高可用、读写性能、基于文件系统级别共享、分布式、无metadata(元数据)的存储方式。
GlusterFS(GNU ClusterFile System)是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点全部平等。GlusterFS配置方便,稳定性好,可轻松达到PB级容量,数千个节点。
2011年被红帽收购,之后推出了基于GlusterFS的Red Hat Storage Server,增加了针对KVM的许多特性,可用作为KVM存储image存储集群,也可以为LB或HA提供存储。
二、GlusterFS重要特性
全对称架构、支持多种卷类型(类似RAID0/1/5/10/01)、支持卷级别的压缩、支持FUSE、支持NFS、支持SMB、支持Hadoop、支持OpenStack、与oVirt深度整合(对应RHEL红帽企业级虚拟化)
三、GlusterFS重要概念
birck:GlusterFS的基本元素,以节点服务器目录形式展现;
volume:多个brick的逻辑集合;
metadata:元数据,用于描述文件、目录等的信息;
self-heal:用于后台运行检测副本卷中文件和目录的不一致性并解决这些不一致;
FUSE:Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接;
Gluster Server:数据存储服务器,即组成GlusterFS存储集群的节点;
Gluster Client:使用GlusterFS存储服务的服务器,如KVM、OpenStack、LB RealServer、HA node。
四、GlusterFS内部架构
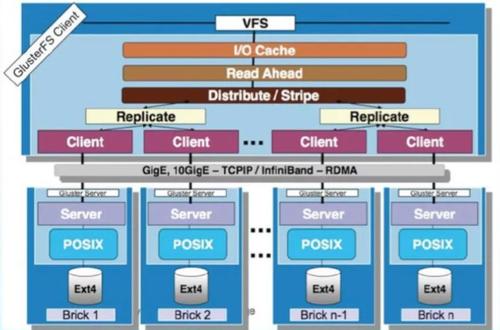
GlusterFS是模块化堆栈式的架构设计,如上图所示。模块称为Translator是GlusterFS提供的一种强大机制,借助这种良好定义的接口可以高效简便地扩展文件系统的功能。
1、服务端与客户端模块接口是兼容的,同一个translator可同时在两边加载。
2、GlusterFS中所有的功能都是通过translator实现,如Cluster, Storage,Performance, Protocol, Features等。
3、重点是GlusterFSClient端。
五、GlusterFS部署
1、环境准备
操作系统:CentOS Linux release 7.4.1708 (Core)
内核版本:3.10.0-693.el7.x86_64
能互相解析,并且添加互信机制,防火墙的24007端口,selinux关闭
192.168.1.191 node1
192.168.1.192 node2
192.168.1.193 node3
192.168.1.194 node4
192.168.1.195 node5
...
2、软件包准备
yum -y install centos-release-gluster
yum -y install glusterfs glusterfs-server glusterfs-fuse
客户端只需要
glusterfs
glusterfs-fuse
3、创建集群
分别启动glusterd服务(并添加开机自启动):
systemctl start glusterd
systemctl enable glusterd
创建集群(任意节点上执行一下操作,向集群中添加节点):
gluster peer probe node2
gluster peer probe node5
从集群中去除节点(该节点中不能存在卷中正在使用的brick)
gluster peer detach node5
不需要添加自己,只需要添加其他节点即可
查看集群状态:
gluster peer status
4、分布卷

分布式卷也成为哈希卷,多个文件以文件为单位在多个brick上,使用哈希算法随机存储。
应用场景:大量小文件
优点:读/写性能好
缺点:如果存储或服务器故障,该brick上的数据将丢失
不指定卷类型,默认是分布式卷
brick数量没有限制
创建分布式卷:
gluster volume create volume_name node1:/data/br1 node2:/data/br1
volumn_name:卷名
node1:节点名
/data/br1:可以理解为节点上的目录,这个目录最好是一个单独的分区(分区类型最好为逻辑卷的方式,这样易于操作系统级别的存储空间扩展)
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
5、复制卷

多个文件在多个brick上复制多份,brick的数目要与需要复制的份数相等,建议brick分布在不同的服务器上。
应用场景:对可靠性高和读写性能要求高的场景
优点:读写性能好
缺点:写性能差
replica = brick
创建复制卷:
gluster volume create volume_name replica 2 node1:/data/br1 node2:/data/br1
replica:文件保存的份数
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
6、条带卷

将文件分成条带,存放在多个brick上,默认条带大小128k
应用场景:大文件
优点:适用于大文件存储
缺点:可靠性低,brick故障会导致数据全部丢失
stripe = birck
创建条带卷:
gluster volume create volume_name stripe 2 node1:/data/br1 node2:/data/br1
stripe:条带个数
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
7、分布式条带卷
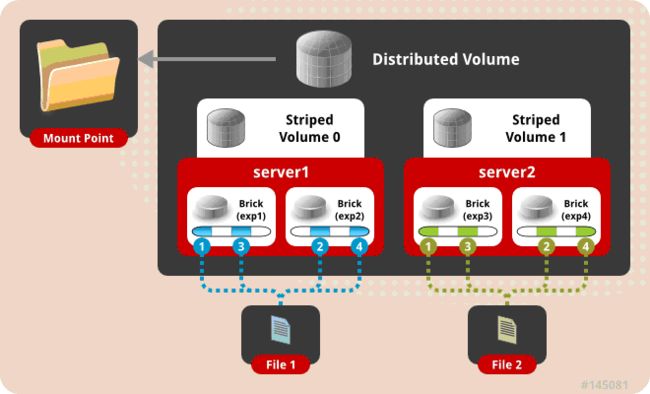
多个文件在多个节点哈希存储,每个文件再多分条带在多个brick上存储
应用场景:读/写性能高的大量大文件场景
优点:高并发支持
缺点:没有冗余,可靠性差
brick数是stripe的倍数
创建分布式条带卷:
gluster volume create volume_name stripe 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
创建时没有具体的选项,来指定卷的类型,只根据stripe和brick数量分配
8、分布式复制卷
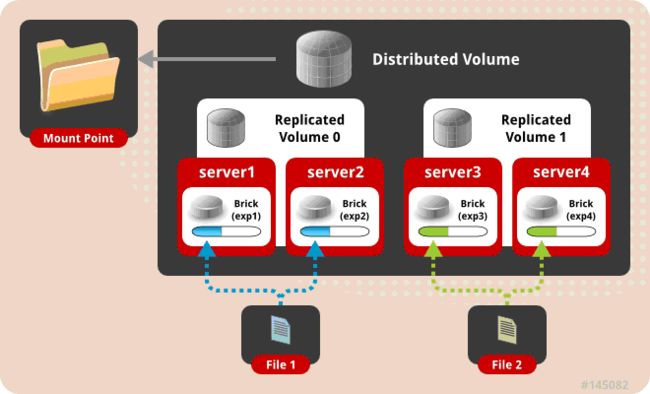
多个文件在多个节点上哈希存储,在多个brick复制多份存储。
应用场景:大量文件读和可靠性要求高的场景
优点:高可靠,读性能高
缺点:牺牲存储空间,写性能差
brick数量是replica的倍数
gluster volume create volume_name replica 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
创建时没有具体的选项,来指定卷的类型,只根据replica和brick数量分配
9、条带式复制卷
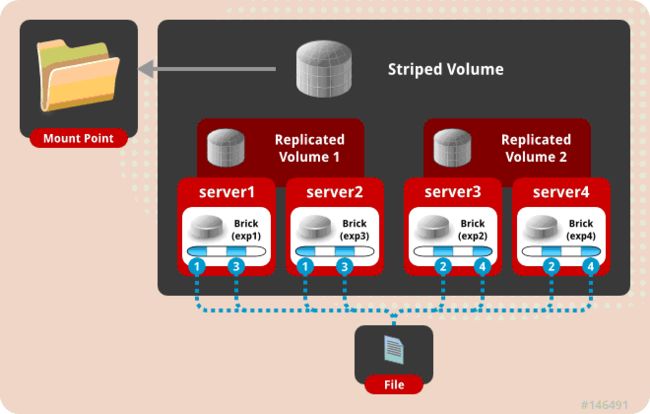
一个大文件存储的时候划分条带,并且保存多份
应用场景:超大文件,并且对可靠性要求高
优点:大文件存储,可靠性高
缺点:牺牲空间写性能差
brick数量是stripe、replica的乘积
gluster volume create volume_name stripe 2 replica 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
启动这个卷:
gluster volume start volume_name
查看这个卷的信息:
gluster volume info volume_name
10、分布式条带复制卷
多个大文件在多个节点哈希存储,存储是分成条带,并且保存多份
应用场景:大量大文件并且对可靠性要求高的场景
优点:读/写/可靠性比较均匀
缺点:牺牲存储空间,写性能相对差
brick的数量是stripe、replica的乘积的倍数
gluster volume create volume_name stripe 2 replica 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1 node5:/data/br1 node6:/data/br1 node7:/data/br1 node8:/data/br1
11、配置客户端使用卷
将卷挂载到本地的mysql目录:
mount –t glusterfs node1:/volume_name /mysql
设置开机自动挂载
vim /etc/fstab加入:
node1:/volume_name /mysql glusterfs defaults,_netdev 0 0
使用mount -a检测并挂载测试
其他挂在方式(NFS、Samba)参考:
http://www.mamicode.com/info-detail-1925105.html
六、卷管理
1、扩容卷(Expanding Volumes)
您可以根据需要扩展卷,而集群是联机和可用的。例如,你可能想添加一个砖的分布量,从而增加了分配和增加的GlusterFS卷的容量。
同样,你可能想添加一组砖分布式复制量,增加的GlusterFS卷的容量。
注意:
在扩展分布式复制和分布式分散卷时,需要添加多个副本或离散计数的砖块。例如,要使用复制计数为2扩展分布式复制卷,需要在2的倍数(例如4, 6, 8)中添加砖块。
(1)、将节点添加到集群中
gluster peer probe node3
gluster peer probe node4
(2)、扩展volume
gluster volume add-brick volume_name node3:/data/br1 node4:/data/br1
(3)、检查添加信息
gluster volume info volume_name
(4)、Rebalance(不要在业务繁忙的情况下进行)
gluster volume rebalance volume_name start
(5)、查看rebalance的状态
gluster volume rebalance volume_name status
2、缩减卷(Shrinking Volumes)
您可以根据需要缩小卷,而集群是联机和可用的。例如,您可能需要删除由于硬件或网络故障而在分布式卷中无法访问的砖块。
注意:
只有配置信息被删除——您可以继续从砖块直接访问数据。
当收缩分布式复制和分布式离散卷时,需要删除多个副本或条形数的多个砖块。例如,如果以复制计数2缩小分布式复制卷,则需要以2的倍数删除砖块(例如4, 6, 8)。另外,您要移除的砖块必须来自相同的子卷(相同的副本或分散集)。
使用“开始选项”运行“移除砖块”将自动触发重新平衡操作,将数据从已移除的砖块迁移到卷的其余部分。
(1)、移除brick
gluster volume remove-brick volume_name node3:/data/br1 node4:/data/br1 start
(2)、查看移除状态
gluster volume remove-brick volume_name node3:/data/br1 node4:/data/br1 status
(3)、提交
gluster volume remove-brick volume_name node3:/data/br1 node4:/data/br1 commit
(4)、查看brick是否被移除
gluster volume info volume_name
(5)、Reblance(不要在业务繁忙的情况下进行)
gluster volume rebalance volume_name start
3、Replace brick
(1)、将节点添加到集群中
gluster peer probe node3
(2)、替换brick
gluster volume replace-brick volume_name node1:/data/br1 node5:/data/br1 commit force
(3)、查看卷的状态
gluster volume info volume_name