6.HDFS文件系统剖析
- 读写流程
- 结构
- 写流程
- 读流程
- 元数据节点
- 存储方式
- 数据结构
- 安全模式
- 高可用
- 机架管理
- 参考资料
Hadoop三大组件:HDFS/MR/Yarn,前面已经详述了计算模型MR的全过程,都说Hadoop的思想是移动计算而不移动数据,这一切基于hadoop的分布式文件系统HDFS。这两节详述hdfs的的工作过程/原理和注意事项。
读写流程
结构
首先看下HDFS的构成如下图
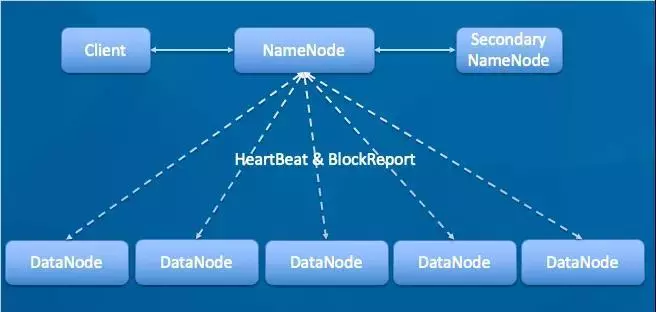
Client:客户端。
NameNode:master,它是一个主管、管理者,存储元数据。
DataNode:slave,NameNode 下达命令,DataNode 执行操作并存储实际数据。DataNode会定期心跳汇报节点状态和Block信息。
SecondaryNameNode:NameNode配合管理元数据。
写流程
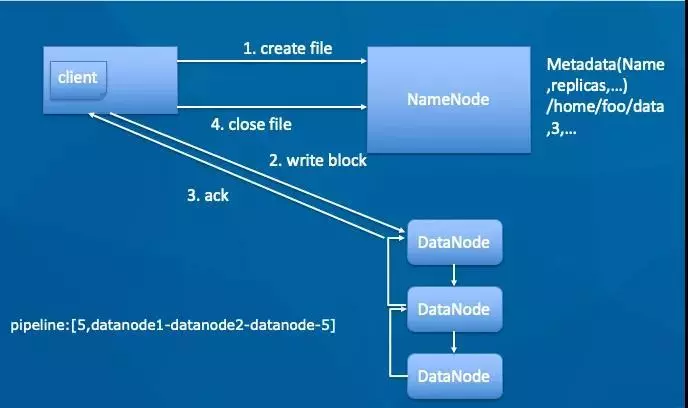
写入时,需要先登记登记元信息,再具体写入,如下
-
客户端create一个新的文件;NameNode会做各种校验,比如文件是否已经存在,客户端是否有权限等。
-
如果校验通过,客户端开始写数据到DN(DataNode),文件会按照block大小进行切块,默认128M(可配置)。具体配置参数为hdfs-site.xml中如下参数:
<property>
<name>dfs.blocksizename>
<value>128mvalue>
property>
-
每个DataNode写完一个块后,返回确认信息。
-
写完数据,关闭文件
读流程
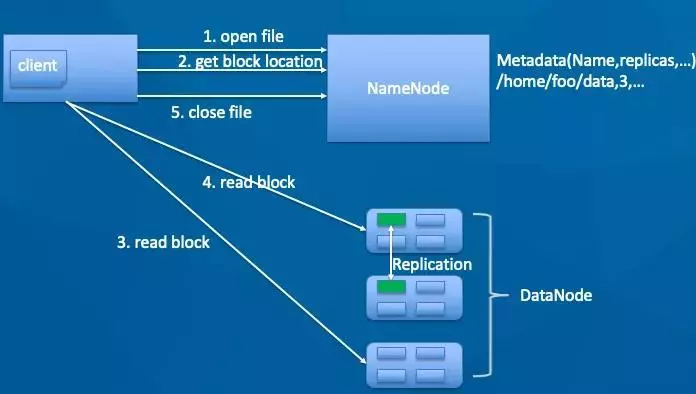
读取时,需要先从NameNode读取对应文件的元信息,对应具体的Block分布,然后客户端直接从DataNode读取对应数据,如下
-
客户端调用open方法,打开一个文件。访问NN,获取block的location,即block所在的DN,NN(NameNode)会根据拓扑结构返回距离客户端最近的DN。
-
客户端直接访问DN读取block数据并计算校验和,整个数据流不经过NN。
-
所有block读取完成,关闭文件
元数据节点
存储方式
可以看到,元数据节点是非常重要的部分,那么具体元数据是如何保存和管理的呢。考虑如下两点:
- 首先,每次读写时都要读写元数据,所以必须要快,在内存中有一份全量元数据(Meta data)
- 其次,元数据是极其重要的,必须保证各种情况下不能丢,采用常用的WAL方式保证,具体由Edits.log和fsimage文件保存。每次写入时先写入到Edits.log,然后再写内存返回,间歇合并log到fsimage中,保证fsimage是一个近全量的元数据集;加载时,先加载fsimage数据,再从Edits.log中恢复数据。
具体过程示意如下:
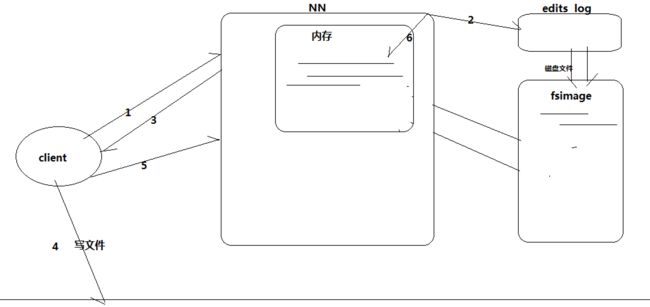
- 上传数据时,NN先往edits log文件中记录元数据日志
- 上传文件成功后,返回信息给NN,NN就在内存中写入本次元数据信息
- 党editslog写满或指定间隔时,log的新元数据刷到fsimage中。具体的配置checkpoint的触发条件:
- 满足dfs.namenode.checkpoint.preiod【默认1小时】时间点
- 或者满足dfs.namenode.checkpoint.txns【默认100万次txns id】
当元数据较大时,合并会耗时,而且为了保证元数据节点本身的性能,需要一个备份节点来完成合并工作,这就是常说的SecondaryNamenode的工作,示意如下:
Secondary namenode工作流程:
- secondary通知namenode切换edits文件
- secondary通过http请求从namenode获得fsimage和edits文件
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage
数据结构
具体的元数据存储目录一般在dfs.namenode.name.dir中,如下
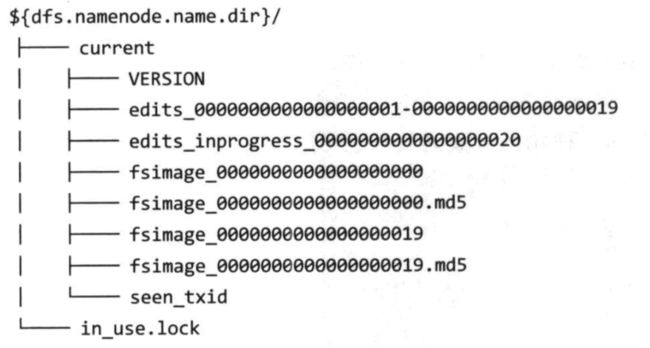
具体来说,可以分别使用如下命令导出对应fsimage和edieslog数据
dfs oiv -p XML -i fsimage_0000000000000000660 -o fsimage.xml
hdfs oev -i edits_inprogress_0000000000000000666 -o edit.xml
fsimage结构如下,保存的时对应的结构和文件块信息块信息
<inode>
<id>16388id>
<type>DIRECTORYtype>
<name>outputname>
<mtime>1557901778514mtime>
<permission>wenzhou:supergroup:rwxr-xr-xpermission>
<nsquota>-1nsquota>
<dsquota>-1dsquota>
inode>
<inode>
<id>16389id>
<type>DIRECTORYtype>
<name>dataname>
<mtime>1567214197491mtime>
<permission>wenzhou:supergroup:rwxr-xr-xpermission>
<nsquota>-1nsquota>
<dsquota>-1dsquota>
inode>
<inode>
<id>16419id>
<type>DIRECTORYtype>
<name>aname>
<mtime>1557901778861mtime>
<permission>wenzhou:supergroup:rwxr-xr-xpermission>
<nsquota>-1nsquota>
<dsquota>-1dsquota>
inode>
<inode>
<id>16424id>
<type>FILEtype>
<name>part-00000name>
<replication>3replication>
<mtime>1557901778851mtime>
<atime>1557901778803atime>
<perferredBlockSize>134217728perferredBlockSize>
<permission>wenzhou:supergroup:rw-r--r--permission>
<blocks>
<block>
<id>1073741831id>
<genstamp>1007genstamp>
<numBytes>8numBytes>
block>
blocks>
inode>
editlog结构如下,保存的是具体操作和对应的信息
<RECORD>
<OPCODE>OP_START_LOG_SEGMENTOPCODE>
<DATA>
<TXID>666TXID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_MKDIROPCODE>
<DATA>
<TXID>667TXID>
<LENGTH>0LENGTH>
<INODEID>16484INODEID>
<PATH>/test3PATH>
<TIMESTAMP>1569642205798TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>wenzhouUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>493MODE>
PERMISSION_STATUS>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ADDOPCODE>
<DATA>
<TXID>668TXID>
<LENGTH>0LENGTH>
<INODEID>16485INODEID>
<PATH>/test3/edit.xml._COPYING_PATH>
<REPLICATION>1REPLICATION>
<MTIME>1569642220389MTIME>
<ATIME>1569642220389ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_759388144_1CLIENT_NAME>
<CLIENT_MACHINE>127.0.0.1CLIENT_MACHINE>
<OVERWRITE>trueOVERWRITE>
<PERMISSION_STATUS>
<USERNAME>wenzhouUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
<RPC_CLIENTID>7e15e3a5-a0f1-4cd6-9cb2-969812945d5bRPC_CLIENTID>
<RPC_CALLID>3RPC_CALLID>
DATA>
RECORD>
安全模式
值得注意的是,上述文件并没有保存Block和对应DN节点的映射,实际上这个也不是namenode元数据保存的,namenode只负责保存文件结构和block信息,具体的block和DN是由DN自己上报的。
如下,实际上,namenode刚开始启动时,加载fsimage合并edit这一过程中始终处于安全模式,也就是hdfs对于客户端是只读的。

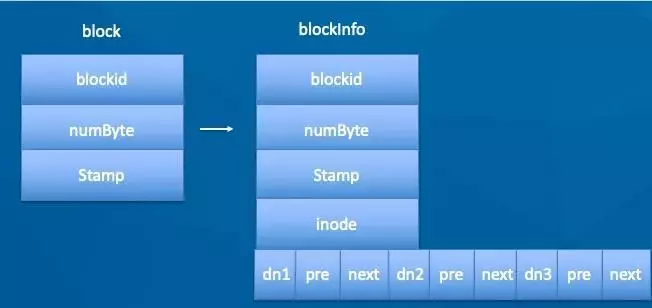
具体DN向NN(NameNode)汇报,此过程为z之前说的BlockReport,通过blockReport构建BlocksMap的结构如下,此时内存中维护block->DN的映射。
可以通过hdfs dfsadmin -safemode查看和进入进出安全模式状态。
高可用
通过元数据的WAL方式可以保证数据的可靠性,但是没法保证NN挂掉时的可用性,为了解决这个问题,hadoop 2.X引入HA机制,简单来说就是维护active和standby两个NN节点,当active挂掉时立即用standby替换。
示意图如下

- AB都是NN节点,同一时刻只能有一个active,一个为standby
- 为了处理无缝切换,需要做两件事,一是两个节点数据完全一致,这是通过edit日志直接写入基于Zookeeper实现的分布式journalNodes节点来实现,二是状态的监控确认何时发生切换,这是通过基于Zookeeper的zkfc本地监控汇报状态来实现
- 防止切换时脑裂,用两种手段保证,比如切换到B时为了防止A假死,B先通过ssh kill A,等待一段时间确认A被杀死,如果不能杀死就再执行自定义的脚本来处理,这叫fencing机制
- 同一集群可以配置多对NN,每对叫做一个Namespace,多个Namespace共存可以按照业务划分,也可以解决同一namenode数据过大内存放不下的问题,这一般叫做Hadoop Federation(联邦机制))
根据上述原理,具体配置包括
- core-site.xml
- hdfs位置不再指向单台机器而是一个namespace
- 指定zookeeper和journalNode机器位置
- hdfs-site.xml
- namespace名称和对应机器配置
- edits在journalnode存储位置
- fencing配置
- 自动故障转移配置
具体配置参考https://www.cnblogs.com/dflmg/p/10167879.html和https://www.cnblogs.com/jifengblog/p/9307702.html
机架管理
实际大型hadoop集群都是由很多机器组成的,具体对应到机房不同机架的机器,通常单个机架30-40共享一个交换机(10-40G),各机架又通过上行链路与一个核心交换机或路由器互联,典型结构如下。同一机架内部的带宽远高于机架间的,因此我们期望hdfs在存取文件时优先选用同一机架的。

默认hdfs是随机存取的,为了让hdfs感知到机架结构,必须我们告诉它对应的网络拓扑结构才行。
- 可通过实现DNSToSwitchMapping来指定节点位置和网络拓扑位置的映射(参考),比如/switch1/rack1和/switch1/rack2。具体需要打包源代码,将jar包发送到所以集群节点hadoop/common/lib下,然后core-site.xml如下配置
<property>
<name>net.topology.node.switch.mapping.implname>
<value>实现接口的类的全路径value>
property>
- 最简单的就是通过配置脚本实现(参考),hadoop-site.xml如下配置
<property>
<name>topology.script.file.namename>
<value>/path/to/RackAware.pyvalue>
此脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
目前使用的机架存储方案如下,这样保证本客户端再次读取新写的数据时,直接从本地读取,这样延迟最小,读取速度最快。
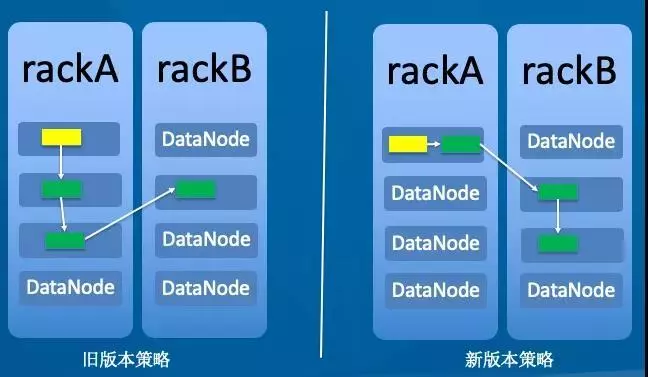
- 副本1:同Client的节点。
- 副本2:不同机架的节点。
- 副本3:同第2副本相同机架的不同节点。
- 如果还有其他副本:随机。
参考资料
- https://mp.weixin.qq.com/s/dKfP8W6DuJHGWfGYVYXfiQ
- 《Hadoop权威指南》-管理Hadoop-HDFS
- http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html