ELK日志分析平台加入Kafka消息队列
在之前的搭建elk环境中,日志的处理流程为:filebeat --> logstash --> elasticsearch,随着业务量的增长,需要对架构做进一步的扩展,引入kafka集群。日志的处理流程变为:filebeat --> kafka --> logstash --> elasticsearch。架构图如下所示:
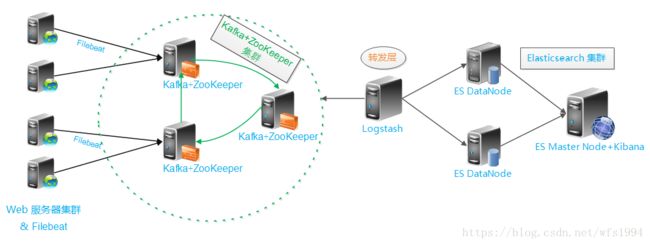
Kafka: 数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
版本说明:
Kafka:kafka_2.12-1.1.0
Zookeeper:zookeeper-3.4.12
ELK组件版本为6.2.3
Kafka集群环境的搭建可以参考:
ZooKeeper基础知识及环境搭建
Kafka基础知识及环境搭建
配置filebeat输出到kafka集群:
修改filebeat配置文件,配置输出到kafka:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /tmp/test.log
output.kafka:
enabled: true
hosts: ["192.168.20.201:9092", "192.168.20.203:9092", "192.168.20.56:9092"]
topic: 'test-log'重启filebeat服务,并尝试向/tmp/test.log文件中追加一些测试数据,在kafka集群任意节点查看主题,并消费这些数据。
#filebeat客户端模拟生成日志:
echo "111" >>/tmp/test.log
#在kafka集群任意节点查看是否生成对应topic:
# ./bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
test-log
#尝试能否消费该主题下的数据
# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.20.203:9092 --topic test-log --from-beginning
{"@timestamp":"2018-06-03T06:15:35.800Z","@metadata":{"beat":"filebeat","type":"doc","version":"6.2.3","topic":"test-log"},"message":"111","prospector":{"type":"log"},"beat":{"hostname":"ELK","version":"6.2.3","name":"192.168.20.60"},"source":"/tmp/test.log","offset":379}
#如果不指定codec,默认为json格式到此filebeat输出到kafka配置完成,详细用法参数可以参考官方文档
Logstsh从kafka读取数据,并输出到es:
先配置输出到标准输出:
# cat kafka.conf
input {
kafka {
codec => "json"
bootstrap_servers => "192.168.10.201:9092,192.168.20.203:9092,192.168.20.56:9092"
topics => "test-log"
consumer_threads => 2
}
}
output {
stdout { codec => rubydebug }
}检查配置语法,没问题启动logstash:
#检查语法
/usr/local/elk/logstash-6.2.3/bin/logstash -f kafka.conf -t
#启动
/usr/local/elk/logstash-6.2.3/bin/logstash -f kafka.conf --config.reload.automatic同样先模式向日志文件中插入一条数据,查看logstash输出是否正常:
#filebeat客户端模拟生成日志:
echo "222" >>/tmp/test.log
#logstash端输出结果:
...
{
"offset" => 383,
"@version" => "1",
"prospector" => {
"type" => "log"
},
"beat" => {
"name" => "192.168.20.60",
"hostname" => "ELK",
"version" => "6.2.3"
},
"message" => "222",
"@timestamp" => 2018-06-03T06:27:55.820Z,
"source" => "/tmp/test.log"
}
到目前为止,整体流程已经走通,kafka集群成功的加入到elk平台中。更多关于kafka输入插件的资料可以参考官方文档
filebeat收集不同日志输出到kafka不同的topic中:
深入了解一下,如何将不同log输出到不同到kafka topics中呢?
对于6.0以后的版本,可以使用fields。然后通过%{[]}获取对应的值
filebeat配置文件如下所示:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /tmp/access.log
fields:
log_topics: apache-access
- type: log
enabled: true
paths:
- /tmp/error.log
fields:
output.kafka:
enabled: true
hosts: ["192.168.20.201:9092", "192.168.20.203:9092", "192.168.20.56:9092"]
#topic: 'test-log'
topic: '%{[fields][log_topics]}'对应的,在logstash上,如果要分别解释对应的topic:
input {
kafka {
codec => "json"
bootstrap_servers => "192.168.10.201:9092,192.168.20.203:9092,192.168.20.56:9092"
topics => ["apache-access","apache-error"]
consumer_threads => 2
}
}
filter {
if[fields][log_topics] == "apache-access" {
grok {...}
}
if[fields][log_topics] == "apache-error" {
grok {...}
}
}
output {
stdout { codec => rubydebug }
}参考链接:
http://blog.51cto.com/tchuairen/1861167?utm_source=tuicool&utm_medium=referral
https://blog.csdn.net/u013613428/article/details/78665081
https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html