基于深度学习的Action Recognition(行为识别)【二】
本文发表在: 知乎专栏
看了近一个月的论文,对行为识别领域中目前主流的基于深度学习的方法算是有了基本的认识。但今天只做总结,关于每一篇论文的详细理解,之后有时间补上。也欢迎指正交流。
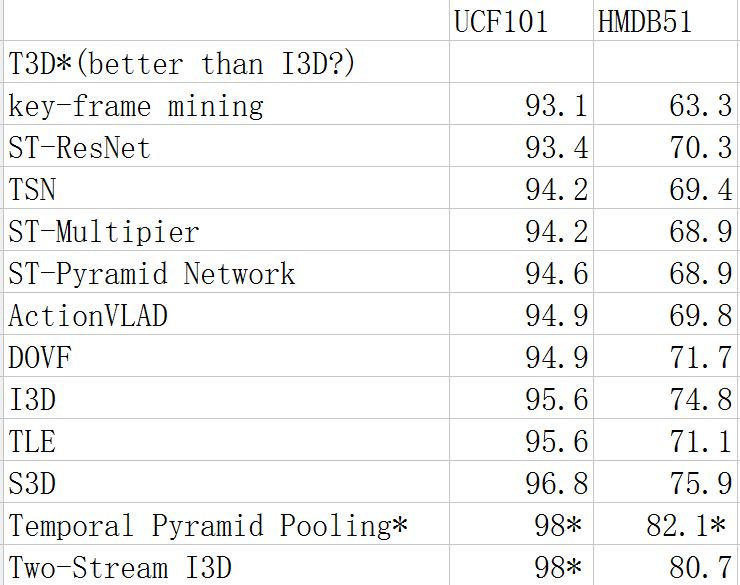
下图为目前主流模型的比较。其中T3D标称效果好于I3D,但由于结果是作者复现得来,故在这里不做比较。顺序自上向下按UCF101的准确率排列。
首先,我把目前Action Recognition的研究方向(发论文的方向)分为三大类。
-
Structure
-
Inputs
-
Connection
下面依次用各类中典型的网络模型举例说明,文末会附上各类较为全面的论文/代码链接。注意,各类存在部分重叠。
Structure
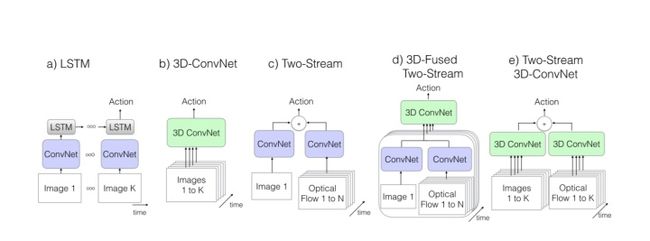
这里的结构主要指网络结构。目前,主流的结构都是基于
Two-Stream Convolutional Networks
和
C3D
发展而来,所以这一块内容也主要讨论这两种结构的各种演化中作为benchmark的一些结构,详细的list参见文末。
首先讨论TSN模型,这是港中文汤晓鸥组的论文,也是目前的benchmark之一,许多模型也是在TSN的基础上进行了后续的探索。
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
【ECCV2016】
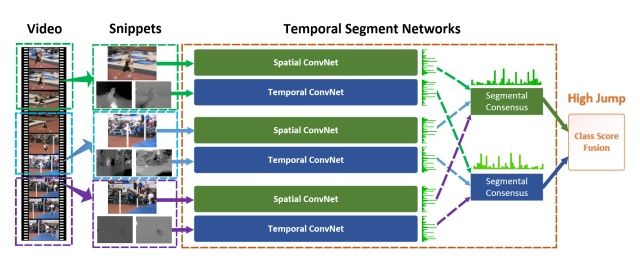
该论文继承了双流网络的结构,但为了解决long-term的问题,作者提出使用多个双流网络,分别捕捉不同时序位置的short-term信息,然后进行融合,得到最后结果。
Deep Local Video Feature for Action Recognition
【CVPR2017】
TSN改进版本之一。
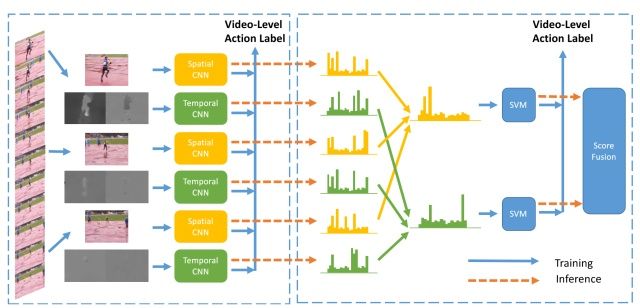
改进的地方主要在于fusion部分,不同的片段的应该有不同的权重,而这部分由网络学习而得,最后由SVM分类得到结果。
Temporal Relational Reasoning in Videos
TSN改进版本二。
这篇是MIT周博磊大神的论文,作者是也是最近提出的数据集
Moments in time
的作者之一。
该论文关注时序关系推理。对于哪些仅靠关键帧(单帧RGB图像)无法辨别的动作,如摔倒,其实可以通过时序推理进行分类。如下图。

除了两帧之间时序推理,还可以拓展到更多帧之间的时序推理。
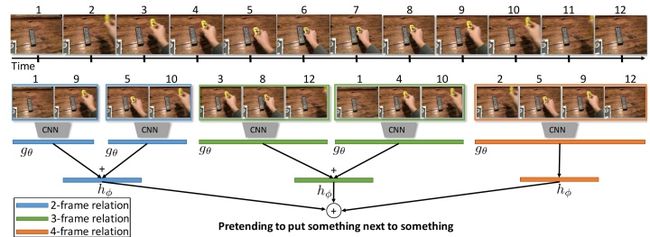
通过对不同长度视频帧的时序推理,最后进行融合得到结果。
该模型建立TSN基础上,在输入的特征图上进行时序推理。增加三层全连接层学习不同长度视频帧的权重,及上图中的函数g和h。
除了上述模型外,还有更多关于时空信息融合的结构。这部分与connection部分有重叠,所以仅在这一部分提及。这些模型结构相似,区别主要在于融合module的差异,细节请参阅论文。
I3D[Facebook]
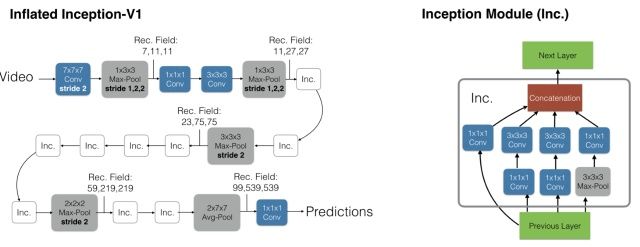
即基于inception-V1模型,将2D卷积扩展到3D卷积。
T3D
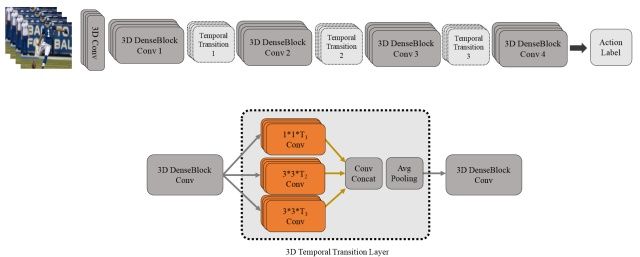
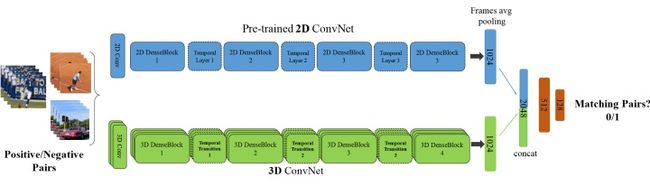
该论文值得注意的,一方面是采用了3D densenet,区别于之前的inception和Resnet结构;另一方面,TTL层,即使用不同尺度的卷积(inception思想)来捕捉讯息。
P3D[MSRA]
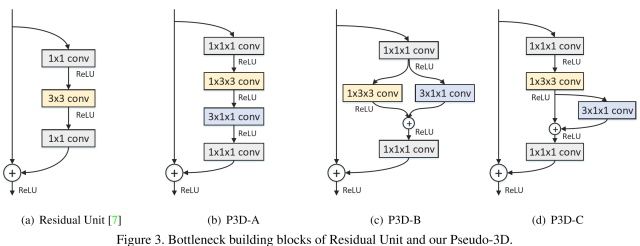
改进ResNet内部连接中的卷积形式。然后,超深网络,一般人显然只能空有想法,望而却步。
Temporal Pyramid Pooling

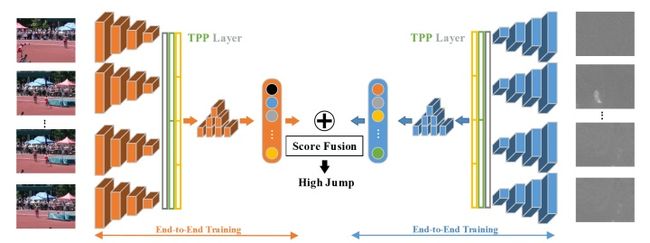
Pooling。时空上都进行这种pooling操作,旨在捕捉不同长度的讯息。
TLE

TLE层的核心。
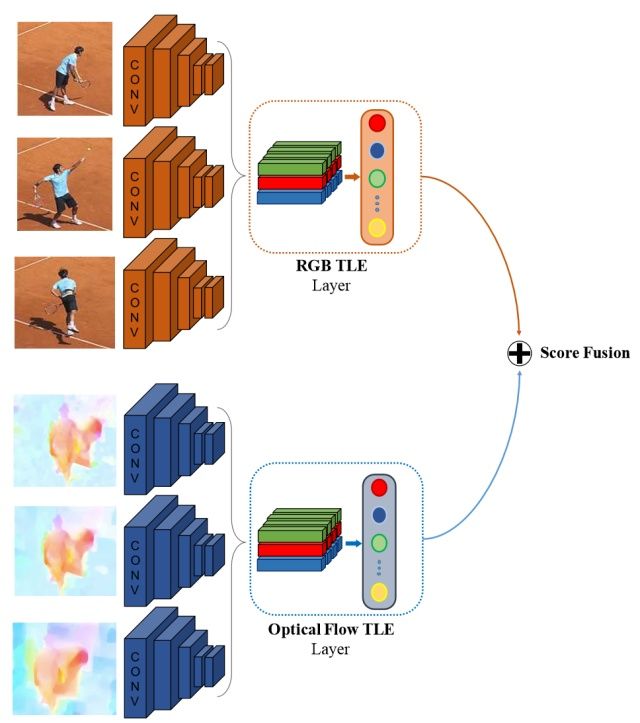
TLE层在双流网络中的使用。
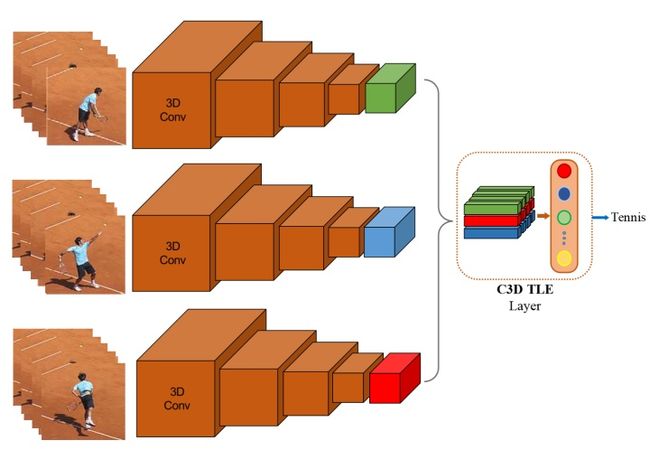
TLE层在C3D结构网络中的使用。
Inputs
输入一方面指输入的数据类型和格式,也包括数据增强的相关操作。
双流网络中,空间网络通道的输入格式通常为单RGB图像或者是多帧RGB堆叠。而空间网络一般是直接对ImageNet上经典的网络进行finetune。虽然近年来对motion信息的关注逐渐上升,指责行为识别过度依赖背景和外貌特征,而缺少对运动本身的建模,但是,事实上,运动既不是名词,也不应该是动词,而应该是动词+名词的形式,例如:play+basketball,也可以是play+football。所以,个人认为,虽然应该加大的时间信息的关注,但不可否认空间特征的重要作用。
空间网络主要捕捉视频帧中重要的物体特征。目前大部分公开数据集其实可以仅仅依赖单图像帧就可以完成对视频的分类,而且往往不需要分割,那么,在这种情况下,空间网络的输入就存在着很大的冗余,并且可能引入额外的噪声。
是否可以提取出视频中的关键帧来提升分类的水平呢?下面这篇论文就提出了一种提取关键帧的方法。
A Key Volume Mining Deep Framework for Action Recognition
【CVPR2016】
虽然上面的方法可以集成到一个网络中训练,但是思路是按照图像分类算法RCNN中需要分步先提出候选框,挑选出关键帧。既然挑选前需要输入整个视频,可不可以省略挑选这个步骤,直接在卷积/池化操作时,重点关注那些关键帧,而忽视那些冗余帧呢?去年就有人提出这样的解决方法。
AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos
【CVPR2017】
注:AdaScan的效果一般,关键帧的质量比上面的Key Volume Mining效果要差一点。不过模型整体比较简单。
输入方面,空间网络目前主要集中在关键帧的研究上。而对于temporal通道而言,则是更多人的关注焦点。首先,光流的提取需要消耗大量的计算力和时间(有论文中提到几乎占据整个训练时间的90%);其次,光流包含的未必是最优的的运动特征。
On the Integration of Optical Flow and Action Recognition
那么,光流这种运动特征可不可以由网络自己学呢?
Hidden Two-Stream Convolutional Networks for Action Recognition

该论文主要参考了flownet,即使用神经网络学习生成光流图,然后作为temporal网络的输入。该方法提升了光流的质量,而且模型大小也比flownet小很多。有论文证明,光流质量的提高,尤其是对于边缘微小运动光流的提升,对分类有关键作用。
另一方面,该论文中也比较了其余的输入格式,如RGB diff。但效果没有光流好。
目前,除了可以考虑尝试新的数据增强方法外,如何训练出替代光流的运动特征应该是接下来的发展趋势之一。
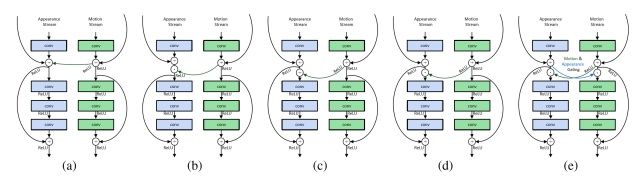
Connection
这里连接主要是指双流网络中时空信息的交互。一种是单个网络内部各层之间的交互,如ResNet/Inception;一种是双流网络之间的交互,包括不同fusion方式的探索,目前值得考虑的是参照ResNet的结构,连接双流网络。
这里主要讨论双流的交互。不同论文之间的交互方式各有不同。
Spatiotemporal Multiplier Networks for Video Action Recognition
【CVPR2017】
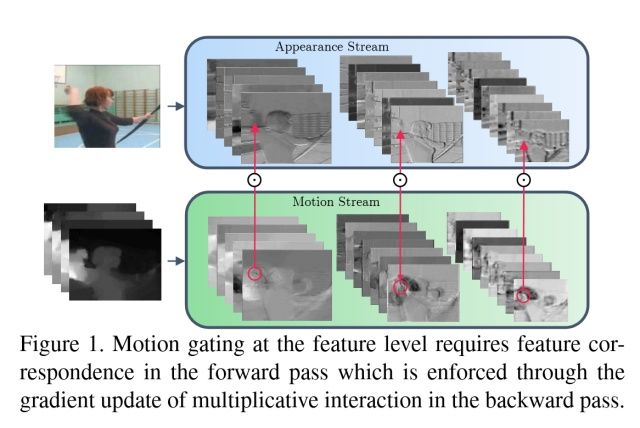
网络的结构如上图。空间和时序网络的主体都是ResNet,增加了从Motion Stream到Spatial Stream的交互。论文还探索多种方式。
Spatiotemporal Pyramid Network for Video Action Recognition
【CVPR2017】
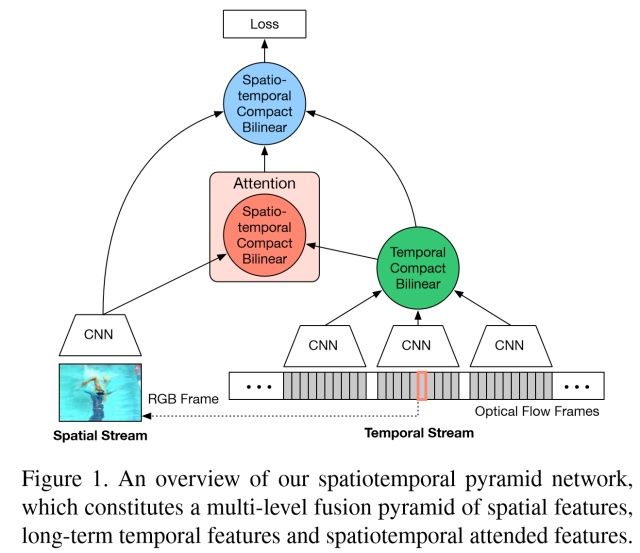
论文作者认为,行为识别的关键就在于如何很好的融合空间和时序上的特征。作者发现,传统双流网络虽然在最后有fusion的过程,但训练中确实单独训练的,最终结果的失误预测往往仅来源于某一网络,并且空间/时序网络各有所长。论文分析了错误分类的原因:空间网络在视频背景相似度高的时候容易失误,时序网络在long-term行为中因为snippets length的长度限制容易失误。那么能否通过交互,实现两个网络的互补呢?
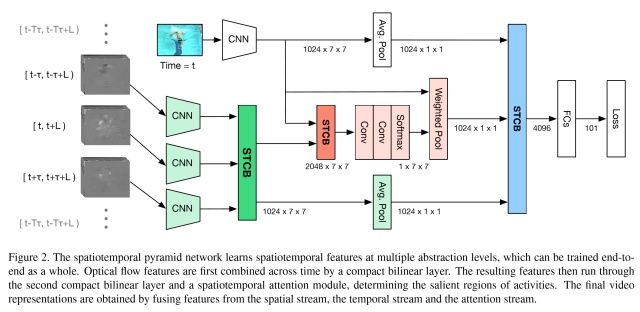
该论文重点在于STCB模块,详情请参阅论文。交互方面,在保留空间、时序流的同时,对时空信息进行了一次融合,最后三路融合,得出最后结果。
Attentional pooling for action recognition
【NIPS2017】
ActionVLAD for video action classification
【CVPR2017】
这两篇论文从pooling的层面提高了双流的交互能力,这两篇笔者还在看,有兴趣的读者请自行参阅论文。后期会附上论文的解读。
Deep Convolutional Neural Networks with Merge-and-Run Mappings
这篇论文也是基于ResNet的结构探索新的双流连接方式。
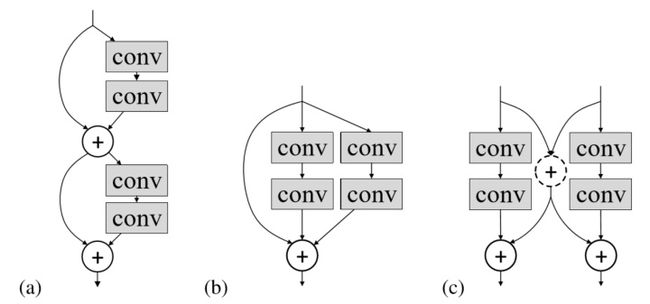
个人讨论:
-
在motion特征被理解之前,双流网络可能仍然是主流。
-
时空信息交互仍然有探索的余地,个人看来也是最有可能发论文的重点领域。
-
输入方面,替代光流的特征值得期待。
附录:
论文列表(顺序不分先后):
Structure:
-
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition 【ECCV2016】
-
Temporal Relational Reasoning in Videos
-
Deep Temporal Linear Encoding Networks 【CVPR2017】
-
End-to-end Video-level Representation Learning for Action Recognition
-
Rethinking Spatiotemporal Feature Learning For Video Understanding
-
Spatiotemporal Residual Networks for Video Action Recognition 【NIPS2016】
-
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
-
Video Classification via Relational Feature Encoding Networks
-
I3D
-
Hidden Two-Stream Convolutional Networks for Action Recognition
-
Learning Gating ConvNet for Two-Stream based Methods in Action Recognition
-
Deep Local Video Feature for Action Recognition 【CVPR2017】
-
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks 【ICCV2017】
-
Convolutional Two-Stream Network Fusion for Video Action Recognition 【CVPR2016】
Inputs:
-
AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos 【CVPR2017】
-
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
-
A Key Volume Mining Deep Framework for Action Recognition 【CVPR2016】
Connection:
-
Spatiotemporal Multiplier Networks for Video Action Recognition 【CVPR2017】
-
Beyond Gaussian Pyramid: Multi-skip Feature Stacking for Action Recognition 【CVPR2015】
-
Deep Convolutional Neural Networks with Merge-and-Run Mappings
-
Human Action Recognition using Factorized Spatio-Temporal Convolutional Networks 【ICCV2015】
-
Attentional pooling for action recognition 【NIPS2017】
-
Spatiotemporal Pyramid Network for Video Action Recognition 【CVPR2017】
-
ActionVLAD for video action classification 【CVPR2017】