Python DataFarme 存取数据库方式及其性能
前言
在实际开发过程中发现Python Pandas.DataFrame 包含直接读取MySQL表及存储MySQL表的函数,于是测试了不同方式读数据、写MySQL表数据的代码简易性及性能的研究。
1. 读数据
1.1 原有读数据方式:
def query_to_df(query, conn):
try:
cur = conn.cursor()
cur.execute(query)
r = cur.fetchall()
cols = [n[0] for n in cur.description]
arr = list(r)
data = pd.DataFrame.from_records(arr, columns=cols)
except:
raise
finally:
close_conn_resource(conn, cur)
return data
1.2 Pandas自带读数据方式:
def read_df_by_pd(query, conn):
try:
data = pd.read_sql(query, conn)
except:
raise
finally:
close_conn_resource(conn, None)
return data
1.3 性能比较:
测试时发现,当加载的数据量较小(5k以内)时,原来自有加载数据的速度更快,当数据量更大时,pd自带的函数速度更快。


2. 写数据
2.1 构建字典方式写数据库:
def save_df_by_dict_execute(table_name, df):
'''save pd.dataframe to MySQL table
Parameters
----------
table_name: str, MySQL table name, like 'tporthold_test'
df : pd.DataFrame
Returns
-------
None
'''
# np.nan to None
df = df.astype(object).where(pd.notnull(df), None)
# get columns
columns = list(df.columns)
# generate insert sql like insert into table (A,B,C) values(%(parakey1)s, %(parakey2)s, %(parakey3)s)
col_names = []
for col in columns:
col_names.append("%(" + col + ")s")
param_dct = {'table_name': table_name,
'cols': ', '.join(columns),
'col_names': ', '.join(col_names)}
sql = "replace into %(table_name)s(%(cols)s) values(%(col_names)s)" % param_dct
# generate data params list of dict like [{parakey1:val1,...}, {parakey1:val1,...}]
data_param_lst = []
map(lambda x: data_param_lst.append(dict(zip(columns, x))), df.values)
# save df data to db
excute_to_db(sql, data_param_lst)
2.2 构建Tuple方式写数据库:
def save_df_by_tuple_execute(table_name, df):
'''save pd.dataframe to MySQL table
Parameters
----------
table_name: str, MySQL table name, like 'tporthold_test'
df : pd.DataFrame
Returns
-------
None
'''
# np.nan to None
df = df.astype(object).where(pd.notnull(df), None)
# get columns
columns = list(df.columns)
# generate insert sql like insert into table (A,B,C) values(%(parakey1)s, %(parakey2)s, %(parakey3)s)
col_names = []
for col in columns:
col_names.append("%(" + col + ")s")
param_dct = {'table_name': table_name,
'cols': ', '.join(columns),
'col_names': ', '.join(['%s' for i in columns])}
sql = "replace into %(table_name)s(%(cols)s) values(%(col_names)s)" % param_dct
# generate data params list of tupe like [(val1, val2, ..), (val1, val2, ...))]
data_param_lst = [tuple(i) for i in df.values]
# save df data to db
excute_to_db(sql, data_param_lst)
2.3 Pandas自带存数据方式:
def save_by_to_sql(table_name, df, config):
host = config['host']
port = config['port']
user = config['user']
passwd = config['password']
db = config['database']
astr = r"mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8" % (user, passwd, host, port, db)
engine = create_engine(astr)
df.to_sql(table_name, engine, index=False, if_exists="append")
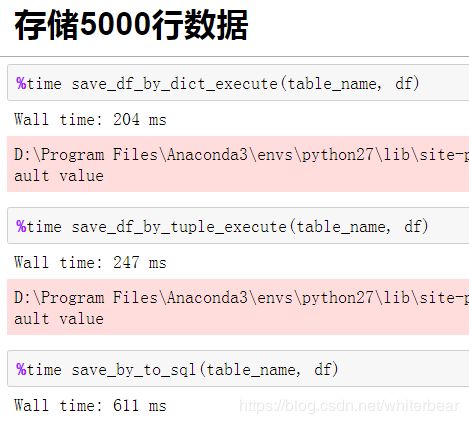
2.4性能比较
测试时发现,写字典的方式比写元组的方式在数据量较大时耗时更少,这两种方式都比Pandas自带存数据to_sql方式更快,约快了50%。
目前觉得 Pandas自带存数据的方式优点在于代码简单,支持np.nan的处理,支持Series等,缺点可能是速度相对较慢,,不支持replace into等。