分布式架构设计之基础软件系统架构
分布式架构设计之基础软件系统架构
原创文章来之不易,转载请注明出处:
http://blog.csdn.net/why_2012_gogo/article/details/74137631
一个好的系统架构需要从三方面进行设计:首先,我们必须明确系统的整体需求功能是什么,进而再对这些需求分模块以及构建模块间的交互设计,同时要明确相关技术的选型;然后,针对物理节点上的拓扑结构是必不可少的,比如:Web Server的负载分发、数据的集群等,这部分是属于架构的“硬实现”部分;最后,就是整体的软件系统的设计,这部分是整个系统架构的“软实现”,主要从系统内部软件系统角度实现设计,比如:基础通信服务、数据安全服务等。对于前两者的设计,读者可以参考上一篇文章《分布式架构设计之电商平台》中提到的业务架构和物理拓扑角度的设计,而这里主要介绍的是软件层面的技术架构设计。好了,还是和往常一样,对于架构的设计,这里不做细节的实现介绍(读者可参考相关资料学习),只介绍核心的技术实现点。
l 体系架构
l 注意事项
l 总结小序
一、体系架构
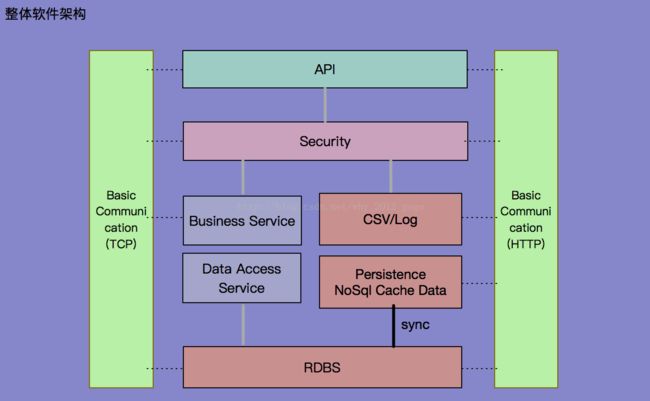
本部分为通用的软件整体架构设计,至于不同行业的软件架构设计是不同的,基础部分均可在此基础上进行拓展设计,而拓展部分与行业紧密相关。这里我主要从八个部分来介绍软件的整体架构设计、各部分的实现机制及相关的技术选型。
1、基础通信(Basic Communication Service)
基础通信是整个系统软件的通信机制,主要支持长短连接两种类型,其通信协议分别为基于TCP和基于HTTP的通信。对于Java语言环境,我们一般选用Nio或是Netty来实现,而后者就是普遍使用的HTTP通信。
上面是基础实现部分,可以满足多线程并发访问的需求,而如果想要以消息驱动并可监控执行线程次序的方式实现软件通信的话,我们可选用MQ技术实现,但需要注意的是MQ的即时和非即时通信的区别实现。
2、API通信(RestfulAPI)
这里的API指的是供前端调取,并渲染其返回数据的接口服务。在这里,我个人建议采用独立的API服务,并且基于Rest风格的资源定位进行API设计,大大提高API的通用和拓展。如果可以的话,我们也可以自行实现或约定通信规则,定义自己的通信协议,采用目前高性能的数据格式。这里以json数据为例,我们可以选用阿里开源的fastjson,也可以选用谷歌的protobuf等数据格式,作为通信内容的载体协议格式,他们都具备易用,高性能的特性。
3、安全处理(Security)
软件的安全处理是一个很重要的部分,如果未作安全防护或是防护出现漏洞,那么面临的就是资金、信息的流失,造成不可弥补的损失。所以,一个合理的架构设计,其中必有一安全处理的模块,专门处理相关安全的问题。
软件安全处理,一般包含自定义处理和安全框架处理。前者主要是我们自行对敏感或重要的数据进行加密处理,比如:md5和base64等。后者则是引用市面开源的安全框架,比如:Spring Security,虽然存在相关的漏洞,但可以解决很多系统漏洞,并且我们都会有针对性的优化漏洞问题。
4、业务服务(Business Service)
顾名思义,该层主要负责业务逻辑的计算实现,并与数据访问层沟通,实现业务数据到缓存及持久化存储介子中。当然,一般第三方的服务也可以包含在这里,并与系统原生的服务区分开来。
5、数据访问(Data Access Service)
数据访问层,主要是用来处理业务层的业务数据,并将该业务数据存储到RDBS介子中的通道,它不负责业务逻辑,只负责与数据库API接口对接,一般被称之为DAO层。
6、文件日志(CSV/Log)
这里的文件日志比较简单,指的是程序或是业务操作产生的日志信息,报表数据等,它与下面的缓存数据及数据存储共同构成庞大的“数据中心”,主要供在后续的大数据分析使用。需要说明的是,日志信息的搜集并非业务操作,需要与程序软件流分离开来,不要阻塞主程序流的执行,比如:在Spring中,一般使用Aop技术实现。
7、缓存机制(Cache Data)
缓存机制,是软件架构设计必不可少的环节,它一般用来缓解关系型持久化数据库的IO压力而来,也有用在某些业务数据的持久化存储方面,比如:Redis、Memcached及Mongo等。而对于大数据方面,Redis和Mongo的使用比较多,当然也需要结合HBase、Hive及Hadoop等一同完成大数据的搜集和分析工作。另外,分布式软件架构中,我们必须考虑到缓存的集群搭建。
8、数据存储(RDBS)
数据存储,目前一般指的是关系型数据存储,如:Mysql、Oracle等,而现在流行的非关系型存储机制,如:Redis、Mongo等,一般只用在缓存的场景,持久化方面,也局限在某些数据领域。而我个人也建议,将某些非敏感数据和配置数据存放在非关系存储介子中。当然,RDBS也必须考虑主备、集群的设计,以便适应分布式系统的需求及高并发访问带来的压力冲击。
二、注意事项
这里谈到的注意事项,主要包括两方面,分别为分布式相关和大数据相关。那么,具体内容如下:
1、分布式相关
第一部分主要介绍的是单机环境下的软件架构设计,而多机环境的设计,略有不同,主要体现在多机环境的数据同步方面,比如:单点登录、Session共享及多个RDBS实例的ID序列等问题,而对于多个机器的数据同步问题,我们可以采用Keepalived技术解决,这些方面的设计后续文章中会一一介绍。
2、大数据相关
正如第一部分的架构图所示,橙色部分代表的是“数据中心”,它存储记录了所有的数据(业务及程序),完全可以作为后期大数据分析的数据源头。
三、总结小序
本篇文章的架构设计,主要指在软件系统的角度设计,其中包含了基础通信服务、数据安全、数据中心及独立API等方面,同时,也提出了在分布式环境及大数据环境的架构引导设计,但只是介绍了架构每个层面的一个点,距离实际设计,还有不少工作要做,这里只是一个方向的引导和某些注意事项的说明。
一个软件架构的设计,并没有上面架构图所展示的那么简单,而这个架构图设计的背后,隐藏了许多方面的考虑和思索,所以就本文而言,并没有全面的介绍,需要各位读者,将此文章作为一个好的引导,慢慢踏进架构师之路。
由于作者水平有限,如有不正确或是误导的地方,请不吝指出讨论(技术交流群:497552060(新))