什么是架构
前言:软体设计师中有一些技术水平较高、经验较为丰富的人,他们需要承担软件系统的架构设计,也就是需要设计系统的元件如何划分、元件之间如何发生相互作用,以及系统中逻辑的、物理的、系统的重要决定的作出。在很多公司中,架构师不是一个专门的和正式的职务。通常在一个开发小组中,最有经验的程序员会负责一些架构方面的工作。在一个部门中,最有经验的项目经理会负责一些架构方面的工作。但是,越来越多的公司体认到架构工作的重要性。
什么是软件系统的架构(Architecture)?一般而言,架构有两个要素:
·它是一个软件系统从整体到部分的最高层次的划分。
一个系统通常是由元件组成的,而这些元件如何形成、相互之间如何发生作用,则是关于这个系统本身结构的重要信息。
详细地说,就是要包括架构元件(Architecture Component)、联结器(Connector)、任务流(Task-flow)。所谓架构元素,也就是组成系统的核心"砖瓦",而联结器则描述这些元件之间通讯的路径、通讯的机制、通讯的预期结果,任务流则描述系统如何使用这些元件和联结器完成某一项需求。
·建造一个系统所作出的最高层次的、以后难以更改的,商业的和技术的决定。
在建造一个系统之前会有很多的重要决定需要事先作出,而一旦系统开始进行详细设计甚至建造,这些决定就很难更改甚至无法更改。显然,这样的决定必定是有关系统设计成败的最重要决定,必须经过非常慎重的研究和考察。
计算机软件的历史开始于五十年代,历史非常短暂,而相比之下建筑工程则从石器时代就开始了,人类在几千年的建筑设计实践中积累了大量的经验和教训。建筑设计基本上包含两点,一是建筑风格,二是建筑模式。独特的建筑风格和恰当选择的建筑模式,可以使一个独一无二。
下面的照片显示了中美洲古代玛雅建筑,Chichen-Itza大金字塔,九个巨大的石级堆垒而上,九十一级台阶(象征着四季的天数)夺路而出,塔顶的神殿耸入云天。所有的数字都如日历般严谨,风格雄浑。难以想象这是石器时代的建筑物。

图1、位于墨西哥Chichen-Itza(在玛雅语中chi意为嘴chen意为井)的古玛雅建筑。(摄影:作者)
软件与人类的关系是架构师必须面对的核心问题,也是自从软件进入历史舞台之后就出现的问题。与此类似地,自从有了建筑以来,建筑与人类的关系就一直是建筑设计师必须面对的核心问题。英国首相丘吉尔说,我们构造建筑物,然后建筑物构造我们(We shape our buildings, and afterwards our buildings shape us)。英国下议院的会议厅较狭窄,无法使所有的下议院议员面向同一个方向入座,而必须分成两侧入座。丘吉尔认为,议员们入座的时候自然会选择与自己政见相同的人同时入座,而这就是英国政党制的起源。Party这个词的原意就是"方"、"面"。政党起源的关键就是建筑物对人的影响。
在软件设计界曾经有很多人认为功能是最为重要的,形式必须服从功能。与此类似地,在建筑学界,现代主义建筑流派的开创人之一Louis Sullivan也认为形式应当服从于功能(Forms follows function)。
几乎所有的软件设计理念都可以在浩如烟海的建筑学历史中找到更为遥远的历史回响。最为著名的,当然就是模式理论和XP理论。
架构的目标是什么
正如同软件本身有其要达到的目标一样,架构设计要达到的目标是什么呢?一般而言,软件架构设计要达到如下的目标:
·可靠性(Reliable)。软件系统对于用户的商业经营和管理来说极为重要,因此软件系统必须非常可靠。
·安全行(Secure)。软件系统所承担的交易的商业价值极高,系统的安全性非常重要。
·可扩展性(Scalable)。软件必须能够在用户的使用率、用户的数目增加很快的情况下,保持合理的性能。只有这样,才能适应用户的市场扩展得可能性。
·可定制化(Customizable)。同样的一套软件,可以根据客户群的不同和市场需求的变化进行调整。
·可扩展性(Extensible)。在新技术出现的时候,一个软件系统应当允许导入新技术,从而对现有系统进行功能和性能的扩展
·可维护性(Maintainable)。软件系统的维护包括两方面,一是排除现有的错误,二是将新的软件需求反映到现有系统中去。一个易于维护的系统可以有效地降低技术支持的花费
·客户体验(Customer Experience)。软件系统必须易于使用。
·市场时机(Time to Market)。软件用户要面临同业竞争,软件提供商也要面临同业竞争。以最快的速度争夺市场先机非常重要。
架构的种类
根据我们关注的角度不同,可以将架构分成三种:
·逻辑架构、软件系统中元件之间的关系,比如用户界面,数据库,外部系统接口,商业逻辑元件,等等。
比如下面就是笔者亲身经历过的一个软件系统的逻辑架构图
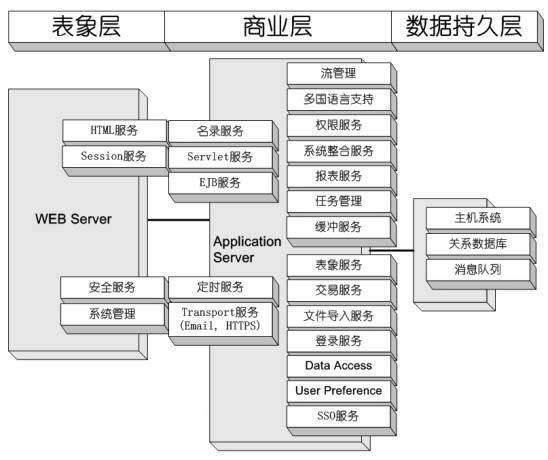
图2、一个逻辑架构的例子
从上面这张图中可以看出,此系统被划分成三个逻辑层次,即表象层次,商业层次和数据持久层次。每一个层次都含有多个逻辑元件。比如WEB服务器层次中有HTML服务元件、Session服务元件、安全服务元件、系统管理元件等。
·物理架构、软件元件是怎样放到硬件上的。
比如下面这张物理架构图描述了一个分布于北京和上海的分布式系统的物理架构,图中所有的元件都是物理设备,包括网络分流器、代理服务器、WEB服务器、应用服务器、报表服务器、整合服务器、存储服务器、主机等等。

图3、一个物理架构的例子
·系统架构、系统的非功能性特征,如可扩展性、可靠性、强壮性、灵活性、性能等。
系统架构的设计要求架构师具备软件和硬件的功能和性能的过硬知识,这一工作无疑是架构设计工作中最为困难的工作。
此外,从每一个角度上看,都可以看到架构的两要素:元件划分和设计决定。
首先,一个软件系统中的元件首先是逻辑元件。这些逻辑元件如何放到硬件上,以及这些元件如何为整个系统的可扩展性、可靠性、强壮性、灵活性、性能等做出贡献,是非常重要的信息。
其次,进行软件设计需要做出的决定中,必然会包括逻辑结构、物理结构,以及它们如何影响到系统的所有非功能性特征。这些决定中会有很多是一旦作出,就很难更改的。
根据作者的经验,一个基于数据库的系统架构,有多少个数据表,就会有多少页的架构设计文档。比如一个中等的数据库应用系统通常含有一百个左右的数据表,这样的一个系统设计通常需要有一百页左右的架构设计文档。
架构师
软体设计师中有一些技术水平较高、经验较为丰富的人,他们需要承担软件系统的架构设计,也就是需要设计系统的元件如何划分、元件之间如何发生相互作用,以及系统中逻辑的、物理的、系统的重要决定的作出。
这样的人就是所谓的架构师(Architect)。在很多公司中,架构师不是一个专门的和正式的职务。通常在一个开发小组中,最有经验的程序员会负责一些架构方面的工作。在一个部门中,最有经验的项目经理会负责一些架构方面的工作。
但是,越来越多的公司体认到架构工作的重要性,并且在不同的组织层次上设置专门的架构师位置,由他们负责不同层次上的逻辑架构、物理架构、系统架构的设计、配置、维护等工作。
软件的架构设计
好的开始相当于成功一半
开始之初的架构设计决定着软件产品的生死存亡。“好的开始相当于成功一半”。
开始的架构设计也是最难的,需要调研同类产品的情况以及技术特征,了解当前世界上对这种产品所能提供的理论支持和技术平台支持。再结合自己项目的特点(需要透彻的系统分析),才能逐步形成自己项目的架构蓝图。
比如要开发网站引擎系统,就从Yahoo的个人主页生成工具到虚拟主机商提供的网站自动生成系统,以及IBM Webphere Portal的特点和局限 从而从架构设计角度定立自己产品的位置。
好的设计肯定需要经过反复修改,从简单到复杂的循环测试是保证设计正确的一个好办法
由于在开始选择了正确的方向,后来项目的实现过程也验证了这种选择,但在一些架构设计的细部方面,还需要对方案进行修改,属于那种螺旋上升的方式,显然这是通过测试第一的思想和XP工程方法来实现的。
如果我们开始的架构设计在技术平台定位具有一定的世界先进水平,那么,项目开发实际有一半相当于做实验,是研发,存在相当的技术风险。
因此,一开始我们不可能将每个需求都实现,而是采取一种简单完成架构流程的办法,使用最简单的需求将整个架构都简单的完成一遍(加入人工干预),以检验各个技术环节是否能协调配合工作(非常优秀先进的两种技术有时无法在一起工作),同时也可以探知技术的深浅,掌握项目中的技术难易点。这个过程完成后,我们就对设计方案做出上面的重大修改,丰富完善了设计方案。
设计模式是支撑架构的重要组件
架构设计也类似一种工作流,它是动态的,这点不象建筑设计那样,一开始就能完全确定,架构设计伴随着整个项目的进行过程之中,有两种具体操作保证架构设计的正确完成,那就是设计模式(静态)和工程项目方法(RUP或XP 动态的)。
设计模式是支撑架构的一种重要组件,这与建筑有很相象的地方,一个建筑物建立设计需要建筑架构设计,在具体施工中,有很多建筑方面的规则和模式。
我们从J2EE蓝图模式分类http://java.sun.com/blueprints/patterns/catalog.html中就可以很清楚的看到J2EE这样一个框架软件的架构与设计模式的关系。
架构设计是骨架,设计模式就是肉
这样,一个比较丰富的设计方案可以交由程序员进一步完成了,载辅助以适当的工程方法,这样就可保证项目的架构设计能正确快速的完成。
时刻牢记架构设计的目标
由于架构设计是在动态中完成的,因此在把握架构设计的目标上就很重要,因此在整个项目过程中,甚至每一步我们都必须牢记我们架构设计的总体目标,可以概括下面几点:
1. 最大化的重用:这个重用包括组件重用 和设计模式使用等多个方面。
比如,我们项目中有用户注册和用户权限系统验证,这其实是个通用课题,每个项目只是有其内容和一些细微的差别,如果我们之前有这方面成功研发经验,可以直接重用,如果没有,那么我们就要进行这个子项目的研发,在研发过程中,不能仅仅看到这个项目的需求,也要以架构的概念去完成这个可以称为组件的子项目。
2. 尽可能的简单明了:我们解决问题的总方向是将复杂问题简单化,其实这也是中间件或多层体系技术的根本目标。但是在具体实施设计过程中,我们可能会将简单问题复杂化,特别是设计模式的运用上很容易范这个错误,因此如何尽可能的做到设计的简单明了是不容易的。
我认为落实到每个类的具体实现上要真正能体现系统事物的本质特征,因为事物的本质特征只有一个,你的代码越接近它,表示你的设计就是简单明了,越简单明了,你的系统就越可靠。更多情况是,一个类并不能反应事物本质,需要多个类的组合协调,那么能够正确使用合适的设计模式就称为重中之重。
我们看一个具备好的架构设计的系统代码时,基本看到的都是设计模式,宠物店(pet store)就是这样的例子。或者可以这样说,一个好的架构设计基本是由简单明了的多个设计模式完成的。
3. 最灵活的拓展性:架构设计要具备灵活性 拓展性,这样,用户可以在你的架构上进行二次开发或更加具体的开发。
要具备灵活的拓展性,就要站在理论的高度去进行架构设计,比如现在工作流概念逐步流行,因为我们具体很多实践项目中都有工作流的影子,工作流中有一个树形结构权限设定的概念就对很多领域比较通用。
树形结构是组织信息的基本形式,我们现在看到的网站或者ERP前台都是以树形菜单来组织功能的,那么我们在进行架构设计时,就可以将树形结构和功能分开设计,他们之间联系可以通过树形结构的节点link在一起,就象我们可以在圣诞树的树枝上挂各种小礼品一样,这些小礼品就是我们要实现的各种功能。
有了这个概念,通常比较难实现的用户级别权限控制也有了思路,将具体用户或组也是和树形结构的节点link在一起,这样就间接实现了用户对相应功能的权限控制,有了这样的基本设计方案的架构无疑具备很灵活的拓展性。
如何设计架构?
2007-07-19 11:11 来源: 作者: 网友评论 0 条 浏览次数 26
Part 1 层
层(layer)这个概念在计算机领域是非常了不得的一个概念。计算机本身就体现了一种层的概念:系统调用层、设备驱动层、操作系统层、CPU指令集。每个层都负责自己的职责。网络同样也是层的概念,最著名的TCP/IP的七层协议。
层到了软件领域也一样好用。为什么呢?我们看看使用层技术有什么好处:
● 你使用层,但是不需要去了解层的实现细节。
● 可以使用另一种技术来改变基础的层,而不会影响上面的层的应用。
● 可以减少不同层之间的依赖。
● 容易制定出层标准。
● 底下的层可以用来建立顶上的层的多项服务。
当然,层也有弱点:
● 层不可能封装所有的功能,一旦有功能变动,势必要波及所有的层。
● 效率降低。
当然,层最难的一个问题还是各个层都有些什么,以及要承担何种责任。
典型的三层结构
三层结构估计大家都很熟悉了。就是表示(presentation)层, 领域(domain)层, 以及基础架构(infrastructure)层。
表示层逻辑主要处理用户和软件的交互。现在最流行的莫过于视窗图形界面(wimp)和基于html的界面了。表示层的主要职责就是为用户提供信息,以及把用户的指令翻译。传送给业务层和基础架构层。
基础架构层逻辑包括处理和其他系统的通信,代表系统执行任务。例如数据库系统交互,和其他应用系统的交互等。大多数的信息系统,这个层的最大的逻辑就是存储持久数据。
还有一个就是领域层逻辑,有时也被叫做业务逻辑。它包括输入和存储数据的计算。验证表示层来的数据,根据表示层的指令指派一个基础架构层逻辑。
领域逻辑中,人们总是搞不清楚什么事领域逻辑,什么是其它逻辑。例如,一个销售系统中有这样一个逻辑:如果本月销售量比上个月增长10%,就要用红色标记。要实现这个功能,你可能会把逻辑放在表示层中,比较两个月的数字,如果超出10%,就标记为红色。
这样做,你就把领域逻辑放到了表示层中了。要分离这两个层,你应该现在领域层中提供一个方法,用来比较销售数字的增长。这个方法比较两个月的数字,并返回boolean类型。表示层则简单的调用该方法,如果返回true,则标记为红色。
例子
层技术不存在说永恒的技巧。如何使用都要看具体的情况才能够决定,下面我就列出了三个例子:
例子1:一个电子商务系统。要求能够同时处理大量用户的请求,用户的范围遍及全球,而且数字还在不断增长。但是领域逻辑很简单,无非是订单的处理,以及和库存系统的连接部分。这就要求我们1、表示层要友好,能够适应最广泛的用户,因此采用html技术;2、支持分布式的处理,以胜任同时几千的访问;3、考虑未来的升级。
例子2:一个租借系统。系统的用户少的多,但是领域逻辑很复杂。这就要求我们制作一个领域逻辑非常复杂的系统,另外,还要给他们的用户提供一个方便的输入界面。这样,wimp是一个不错的选择。
例子3:简单的系统。非常简单,用户少、逻辑少。但是也不是没有问题,简单意味着要快速交付,并且还要充分考虑日后的升级。因为需求在不断的增加之中。
何时分层
这样的三个例子,就要求我们不能够一概而论的解决问题,而是应该针对问题的具体情况制定具体的解决方法。这三个例子比较典型。
第二个例子中,可能需要严格的分成三个层次,而且可能还要加上另外的中介(mediating)层。例3则不需要,如果你要做的仅是查看数据,那仅需要几个server页面来放置所有的逻辑就可以了。
我一般会把表示层和领域层/基础架构层分开。除非领域层/基础架构层非常的简单,而我又可以使用工具来轻易的绑定这些层。这种两层架构的最好的例子就是在VB、PB的环境中,很容易就可以构建出一个基于SQL数据库的windows界面的系统。这样的表示层和基础架构层非常的一致,但是一旦验证和计算变得复杂起来,这种方式就存在先天缺陷了。
很多时候,领域层和基础架构层看起来非常类似,这时候,其实是可以把它们放在一起的。可是,当领域层的业务逻辑和基础架构层的组织方式开始不同的时候,你就需要分开二者。
更多的层模式
三层的架构是最为通用的,尤其是对IS系统。其它的架构也有,但是并不适用于任何情况。
第一种是Brown model [Brown et al]。它有五个层:表示层(Presentation),控制/中介层(Controller/Mediator),领域层(Domain), 数据映射层(Data Mapping), 和数据源层(Data Source)。它其实就是在三层架构种增加了两个中间层。控制/中介层位于表示层和领域层之间,数据映射层位于领域层和基础架构层之间。
表示层和领域层的中介层,我们通常称之为表示-领域中介层,是一个常用的分层方法,通常针对一些非可视的控件。例如为特定的表示层组织信息格式,在不同的窗口间导航,处理交易边界,提供Server的facade接口(具体实现原理见设计模式)。最大的危险就是,一些领域逻辑被放到这个层里,影响到其它的表示层。
我常常发现把行为分配给表示层是有好处的。这可以简化问题。但表示层模型会比较复杂,所以,把这些行为放到非可视化的对象中,并提取出一个表示-领域中介层还是值得的。
Brown ISA
表示层 表示层
控制/中介层 表示-领域中介层
领域层 领域层
数据映射层 数据库交互模式中的Database Mapper
数据源层 基础架构层
领域层和基础架构层之间的中介层属于本书中提到的Database Mapper模式,是三种领域层到数据连接的办法之一。和表示-领域中介层一眼,有时候有用,但不是所有时候都有用。
还有一个好的分层架构是J2EE的架构,这方面的讨论可以见『J2EE核心模式』一书。他的分层是客户层(Client),表示层(Presentation),业务层(Business ),整合层(Integration),资源层(Resource)。差别如下图:
J2EE核心 ISA
客户层 运行在客户机上的表示层
表示层 运行在服务器上的表示层
业务层 领域层
整合层 基础架构层
资源层 基础架构层通信的外部数据
微软的DNA架构定义了三个层:表示层(presentation),业务层(business),和数据存储层(data access),这和我的架构相似,但是在数据的传递方式上还有很大的不同。在微软的DNA中,各层的操作都基于数据存储层传出的SQL查询结果集。这样的话,实际上是增加了表示层和业务层同数据存储层之间的耦合度。
DNA的记录集在层之间的动作类似于Data Transfer Object。
Part 2 组织领域逻辑
要组织基于层的系统,首要的是如何组织领域逻辑。领域逻辑的组织有好几种模式。但其中最重要的莫过于两种方法:Transation Script和Domain Model。选定了其中的一种,其它的都容易决定。不过,这两者之间并没有一条明显的分界线。所以如何选取也是门大学问。一般来说,我们认为领域逻辑比较复杂的系统可以采用Domain Model。
Transation Script就是对表示层用户输入的处理程序。包括验证和计算,存储,调用其它系统的操作,把数据回传给表示层。用户的一个动作表示一个程序,这个程序可以是script,也可以是transation,也可以是几个子程序。在例子1中,检验,在购物车中增加一本书,显示递送状态,都可以是一个Transation Script。
Domain Model是要建立对应领域名词的模型,例如例1中的书、购物车等。检验、计算等处理都放到领域模型中。
Transation Script属于结构性思维,Domain Model属于OO思维。Domain Model比较难使用,一旦习惯,你能够组织更复杂的逻辑,你的思想会更OO。到时候,即使是小的系统,你也会自然的使用Domain Model了。
但如何抉择呢?如果逻辑复杂,那肯定用Domain Model:如果只需要存取数据库,那Transation Script会好一些。但是需求是在不断进化的,你很难保证以后的需求还会如此简单。如果你的团队不善于使用Domain Model,那你需要权衡一下投入产出比。另外,即使是Transation Script,也可以做到把逻辑和基础架构分开,你可以使用Gateway。
对例2,毫无疑问要使用Domain Model。对例1就需要权衡了。而对于例3,你很难说它将来会不会像例2那样,你现在可以使用Transation Script,但未来你可能要使用Domain Model。所以说,架构的决策是至关紧要的。
除了这两种模式,还有其它中庸的模式。Use Case Controller就是处于两者之间。只有和单个的用例相关的业务逻辑才放到对象中。所以大致上他们还是在使用Transation Script,而Domain Model只是Database Gateway的一组集合而已。我不太用这种模式。
Table Module是另一个中庸模式。很多的GUI环境依托于SQL查询的返回结果。你可以建立内存中的对象,来把GUI和数据库分开来。为每个表写一个模块,因此每一行都需要关键字变量来识别每一个实例。
Table Module适用于很多的组件构建于一个通用关系型数据库之上,而且领域逻辑不太复杂的情况。Microsoft COM 环境,以及它的带ADO.NET的.NET环境都适合使用这种模式。而对于Java,就不太适用了。
领域逻辑的一个问题是领域对象非常的臃肿。因为对象的行为太多了,类也就太大了。它必须是一个超集。这就要考虑哪些行为是通用的,哪些不是,可以由其它的类来处理,可能是Use Case Controller,也可能是表示层。
还有一个问题,复制。他会导致复杂和不一致。这比臃肿的危害更大。所以,宁可臃肿,也不要复制。等到臃肿为害时再处理它吧。
选择一个地方运行领域逻辑
我们的精力集中在逻辑层上。领域逻辑要么运行在Client上,要么运行在Server上。
比较简单的做法是全部集中在Server上。这样你需要使用html的前端以及web server。这样做的好处是升级和维护都非常的简单,你也不用考虑桌面平台和Server的同步问题,也不用考虑桌面平台的其它软件的兼容问题。
运行在Client适合于要求快速反应和没有联网的情况。在Server端的逻辑,用户的一个再小的请求,也需要信息从Client到Server绕一圈。反应的速度必然慢。再说,网络的覆盖程度也不是说达到了100%。
对于各个层来说,又是怎么样的呢?
基础架构层:一般都是在Server啦,不过有时候也会把数据复制到合适的高性能桌面机,但这是就要考虑同步的问题了。
表示层在何处运行取决于用户界面的设计。一个Windows界面只能在Client运行。而一个Web界面就是在Server运行。也有特别的例子,在桌面机上运行web server的,例如X Server。但这种情况少的多。
在例1中,没有更多的选择了,只能选在Server端。因此你的每一个bit都会绕一个大圈子。为了提高效率,尽量使用一些纯html脚本。
人们选用Windows界面的原因主要就是需要执行一些非常复杂的任务,需要一个合适的应用程序,而web GUI则无法胜任。这就是例2的做法。不过,人们应该会渐渐适应web GUI,而web GUI的功能也会越来越强大。
剩下的是领域逻辑。你可以全部放在Server,也可以全部放在Client,或是两边都放。
如果是在Client端,你可以考虑全部逻辑都放在Client端,这样至少保证所有的逻辑都在一个地方。而把web server移至Client,是可以解决没有联网的问题,但对反应时间不会有多大的帮助。你还是可以把逻辑和表示层分离开来。当然,你需要额外的升级和维护的工作。
在Client和Server端都具有逻辑并不是一个好的处理办法。但是对于那些仅有一些领域逻辑的情况是适用的。有一个小窍门,把那些和系统的其它部分没有联系的逻辑封装起来。
领域逻辑的接口
你的Server上有一些领域逻辑,要和Client通信,你应该有什么样的接口呢?要么是一个http接口,要么是一个OO接口。
http接口适用于web browser,就是说你要选择一个html的表示层。最近的新技术就是web service,通过基于http、特别是XML进行通信。XML有几个好处:通信量大,结构好,仅需一次的回路。这样远程调用的的开销就小了。同时,XML还是一个标准,支持平台异构。XML又是基于文本的,能够通过防火墙。
虽然XML有那么多的好处,不过一个OO的接口还是有它的价值的。hhtp的接口不明显,不容易看清楚数据是如何处理的。而OO的接口的方法带有变量和名字,容易看出处理的过程。当然,它无法通过防火墙,但可以提供安全和事务之类的控制。
最好的还是取二者所长。OO接口在下,http接口在上。但这样做就会使得实现机制非常的复杂。
Part 3 组织web Server
很多使用html方式的人,并不能真正理解这种方式的优点。我们有各种各样好用的工具,但是却搞到让程序难以维护。
在web server上组织程序的方式大致可以分为两种:脚本和server page。
脚本方式就是一个程序,用函数和方法来处理http调用。例如CGI脚本和java servlet。它和普通的程序并没有什么两样。它从web页面上获得html string形态的数据,有时候还要做一些表达式匹配,这正是perl能够成为CGI脚本的常用语言的原因。而java servelet则是把这种分析留给程序员,但它允许程序员通过关键字接口来访问信息,这样就会少一些表达式的判断。这种格式的web server输出是另一种html string,称为response,可以通过流数据来操作。
糟糕的是流数据是非常麻烦的,因此就导致了server page的产生,例如PHP,ASP,JSP。
server page的方式适合回应(response)的处理比较简单的情况。例如“显示歌曲的明细”,但是你的决策取决于输入的时候,就会比较杂乱。例如“通俗和摇滚的显示格式不同”。
脚步擅长于处理用户交互,server page擅长于处理格式化回应信息。所以很自然的就会采用脚本处理请求的交互,使用server page处理回应的格式化。这其实就是著名的MVC(Model View Controller)模式中的view/controller的处理。
web server端的MVC工作流程示意图
应用Model View Controller模式首要的一点就是模型要和web服务完全分离开来。使用Transaction Script或Domain Model模式来封装处理流程。
接下来,我们就把剩余的模式归入两类模式中:属于Controller的模式,以及属于View的模式。
View模式
View这边有三种模式:Transform View,Template View和Two Step View。Transform View和Template View的处理只有一步,将领域数据转换为html。Two Step View要经过两步的处理,第一步把领域数据转换为逻辑表示形式,第二步把逻辑表示转换为html。
两步处理的好处是可以将逻辑集中于一处,如果只有一步,变化发生时,你就需要修改每一个屏幕。但这需要你有一个很好的逻辑屏幕结构。如果一个web应用有很多的前端用户时,两步处理就特别的好用。例如航空订票系统。使用不同的第二步处理,就可以获得不同的逻辑屏幕。
使用单步方法有两个可选的模式:Template View,Transform View。Template View其时就是把代码嵌入到html页面中,就像现在的server page技术,如ASP,PHP,JSP。这种模式灵活,强大,但显得杂乱无章。如果你能够把逻辑程序逻辑在页面结构之外进行很好的组织,这种模式还是有它的优点的。
Transform View使用翻译方式。例如XSLT。如果你的领域数据是用XML处理的,那这种模式就特别的好用。
Controller模式
Controller有两种模式。一般我们会根据动作来决定一项控制。动作可能是一个按钮或链接。所这种模式就是Action Controller模式。
Front Controller更进一步,它把http请求的处理和处理逻辑分离开来。一般是只有一个web handle来处理所有的请求。你的所有的http请求的处理都由一个对象来负责。你改变动作结构的影响就会降到最小
架构设计的方法学
约公元前25年,古罗马建筑师维特鲁威说:“理想的建筑师应该既是文学家又是数字家,他还应通晓历史,热衷于哲学研究,精通音乐,懂得医药知识,具有法学造诣,深谙天文学及天文计算。”(好难哪,软件构架设计师的要求呢?大家好好想想吧。)
本文目录
一、与构架有关的几个基本概念;
二、构架设计应考虑的因素概揽;
三、程序的运行时结构方面的考虑;
四、源代码的组织结构方面的考虑;
五、写系统构架设计文档应考虑的问题
六、结语
一、与构架有关的几个基本概念:
1、模块(module):一组完成指定功能的语句,包括:输入、输出、逻辑处理功能、内部信息、运行环境(与功能对应但不是一对一关系)。
2、组件(component):系统中相当重要的、几乎是独立的可替换部分,它在明确定义的构架环境中实现确切的功能。
3、模式(pattern):指经过验证,至少适用于一种实用环境(更多时候是好几种环境)的解决方案模板(用于结构和行为。在 UML中:模式由参数化的协作来表示,但 UML 不直接对模式的其他方面(如使用结果列表、使用示例等,它们可由文本来表示)进行建模。存在各种范围和抽象程度的模式,例如,构架模式、分析模式、设计模式和代码模式或实施模式。模式将可以帮助我们抓住重点。构架也是存在模式的。比如,对于系统结构设计,我们使用层模式;对于分布式系统,我们使用代理模式(通过使用代理来替代实际的对象,使程序能够控制对该对象的访问);对于交互系统,我们使用MVC(M模型(对象)/V视图(输出管理)/C控制器(输入处理))模式。模式是针对特定问题的解,因此,我们也可以针对需求的特点采用相应的模式来设计构架。
4、构架模式(architectural pattern):表示软件系统的基本结构组织方案。它提供了一组预定义的子系统、指定它们的职责,并且包括用于组织其间关系的规则和指导。
5、层(layer):对模型中同一抽象层次上的包进行分组的一种特定方式。通过分层,从逻辑上将子系统划分成许多集合,而层间关系的形成要遵循一定的规则。通过分层,可以限制子系统间的依赖关系,使系统以更松散的方式耦合,从而更易于维护。(层是对构架的横向划分,分区是对构架的纵向划分)。
6、系统分层的几种常用方法:
1) 常用三层服务:用户层、业务逻辑层、数据层;
2) 多层结构的技术组成模型:表现层、中间层、数据层;
3) 网络系统常用三层结构:核心层、汇聚层和接入层;
4) RUP典型分层方法:应用层、专业业务层、中间件层、系统软件层;
5) 基于Java的B/S模式系统结构:浏览器端、服务器端、请求接收层、请求处理层;
6) 某六层结构:功能层(用户界面)、模块层、组装层(软件总线)、服务层(数据处理)、数据层、核心层;
7、构架(Architecture,愿意为建筑学设计和建筑物建造的艺术与科学): 在RUP中的定义:软件系统的构架(在某一给定点)是指系统重要构件的组织或结构,这些重要构件通过接口与不断减小的构件与接口所组成的构件进行交互;《软件构架实践》中的定义:某个软件或者计算系统的软件构架即组成该系统的一个或者多个结构,他们组成软件的各个部分,形成这些组件的外部可见属性及相互间的联系;IEEE 1471-2000中的定义:the fundamental organization of a system emboided in its components,their relationships to each other,and to the enviroment and the principles guiding its design and evolution,构架是系统在其所处环境中的最高层次的概念。软件系统的构架是通过接口交互的重要构件(在特定时间点)的组织或结构,这些构件又由一些更小的构件和接口组成。(“构架”可以作为名词,也可作为动词,作为动词的“构架”相当于“构架设计”)
8、构架的描述方式:“4+1”视图(用例视图、设计视图、实现视图、过程视图、配置视图)是一个被广为使用的构架描述的模型;RUP过程的构架描述模板在“4+1”视图的基础上增加了可选的数据视图(从永久性数据存储方面来对系统进行说明);HP公司的软件描述模板也是基于“4+1”视图。
9、结构:软件构架是多种结构的体现,结构是系统构架从不同角度观察所产生的视图。就像建筑物的结构会随着观察动机和出发点的不同而有多种含义一样,软件构架也表现为多种结构。常见的软件结构有:模块结构、逻辑或概念结构、进程或协调结构、物理结构、使用结构、调用结构、数据流、控制流、类结构等等。
二、构架设计应考虑的因素概揽:
模块构架设计可以从程序的运行时结构和源代码的组织结构方面考虑。
1、程序的运行时结构方面的考虑:
1) 需求的符合性:正确性、完整性;功能性需求、非功能性需求;
2) 总体性能(内存管理、数据库组织和内容、非数据库信息、任务并行性、网络多人操作、关键算法、与网络、硬件和其他系统接口对性能的影响);
3) 运行可管理性:便于控制系统运行、监视系统状态、错误处理;模块间通信的简单性;与可维护性不同;
4) 与其他系统接口兼容性;
5) 与网络、硬件接口兼容性及性能;
6) 系统安全性;
7) 系统可靠性;
8) 业务流程的可调整性;
9) 业务信息的可调整性
10) 使用方便性
11) 构架样式的一致性
注:运行时负载均衡可以从系统性能、系统可靠性方面考虑。
2、源代码的组织结构方面的考虑:
1) 开发可管理性:便于人员分工(模块独立性、开发工作的负载均衡、进度安排优化、预防人员流动对开发的影响)、利于配置管理、大小的合理性与适度复杂性;
2) 可维护性:与运行可管理性不同;
3) 可扩充性:系统方案的升级、扩容、扩充性能;
4) 可移植性:不同客户端、应用服务器、数据库管理系统;
5) 需求的符合性(源代码的组织结构方面的考虑)。
三、程序的运行时结构方面的考虑:
1、 需求的符合性:正确性、完整性;功能性需求、非功能性需求
软件项目最主要的目标是满足客户需求。在进行构架设计的时候,大家考虑更多的是使用哪个运行平台、编成语言、开发环境、数据库管理系统等问题,对于和客户需求相关的问题考虑不足、不够系统。如果无论怎么好的构架都无法满足客户明确的某个功能性需求或非功能性需求,就应该与客户协调在项目范围和需求规格说明书中删除这一需求。否则,架构设计应以满足客户所有明确需求为最基本目标,尽量满足其隐含的需求。(客户的非功能性需求可能包括接口、系统安全性、可靠性、移植性、扩展性等等,在其他小节中细述)
一般来说,功能需求决定业务构架、非功能需求决定技术构架,变化案例决定构架的范围。需求方面的知识告诉我们,功能需求定义了软件能够做些什么。我们需要根据业务上的需求来设计业务构架,以使得未来的软件能够满足客户的需要。非功能需求定义了一些性能、效率上的一些约束、规则。而我们的技术构架要能够满足这些约束和规则。变化案例是对未来可能发生的变化的一个估计,结合功能需求和非功能需求,我们就可以确定一个需求的范围,进而确定一个构架的范围。(此段From林星)
这里讲一个前几年因客户某些需求错误造成构架设计问题而引起系统性能和可靠性问题的小小的例子:此系统的需求本身是比较简单的,就是将某城市的某业务的全部历史档案卡片扫描存储起来,以便可以按照姓名进行查询。需求阶段客户说卡片大约有20万张,需求调研者出于对客户的信任没有对数据的总量进行查证。由于是中小型数据量,并且今后数据不会增加,经过计算20万张卡片总体容量之后,决定使用一种可以单机使用也可以联网的中小型数据库管理系统。等到系统完成开始录入数据时,才发现数据至少有60万,这样使用那种中小型数据库管理系统不但会造成系统性能的问题,而且其可靠性是非常脆弱的,不得不对系统进行重新设计。从这个小小的教训可以看出,需求阶段不仅对客户的功能需求要调查清楚,对于一些隐含非功能需求的一些数据也应当调查清楚,并作为构架设计的依据。
对于功能需求的正确性,在构架设计文档中可能不好验证(需要人工、费力)。对于功能需求完整性,就应当使用需求功能与对应模块对照表来跟踪追溯。对于非功能需求正确性和完整性,可以使用需求非功能与对应设计策略对照表来跟踪追溯评估。
“软件设计工作只有基于用户需求,立足于可行的技术才有可能成功。”
2、 总体性能
性能其实也是客户需求的一部分,当然可能是明确的,也有很多是隐含的,这里把它单独列出来在说明一次。性能是设计方案的重要标准,性能应考虑的不是单台客户端的性能,而是应该考虑系统总的综合性能;
性能设计应从以下几个方面考虑:内存管理、数据库组织和内容、非数据库信息、任务并行性、网络多人操作、关键算法、与网络、硬件和其他系统接口对性能的影响;
几点提示:算法优化及负载均衡是性能优化的方向。经常要调用的模块要特别注意优化。占用内存较多的变量在不用时要及时清理掉。需要下载的网页主题文件过大时应当分解为若干部分,让用户先把主要部分显示出来。
3、 运行可管理性
系统的构架设计应当为了使系统可以预测系统故障,防患于未然。现在的系统正逐步向复杂化、大型化发展,单靠一个人或几个人来管理已显得力不从心,况且对于某些突发事件的响应,人的反应明显不够。因此通过合理的系统构架规划系统运行资源,便于控制系统运行、监视系统状态、进行有效的错误处理;为了实现上述目标,模块间通信应当尽可能简单,同时建立合理详尽的系统运行日志,系统通过自动审计运行日志,了解系统运行状态、进行有效的错误处理;(运行可管理性与可���护性不同)
4、 与其他系统接口兼容性(解释略)
5、 与网络、硬件接口兼容性及性能(解释略)
6、 系统安全性
随着计算机应用的不断深入和扩大,涉及的部门和信息也越来越多,其中有大量保密信息在网络上传输,所以对系统安全性的考虑已经成为系统设计的关键,需要从各个方面和角度加以考虑,来保证数据资料的绝对安全。
7、 系统可靠性
系统的可靠性是现代信息系统应具有的重要特征,由于人们日常的工作对系统依赖程度越来越多,因此系统的必须可靠。系统构架设计可考虑系统的冗余度,尽可能地避免单点故障。系统可靠性是系统在给定的时间间隔及给定的环境条件下,按设计要求,成功地运行程序的概率。成功地运行不仅要保证系统能正确地运行,满足功能需求,还要求当系统出现意外故障时能够尽快恢复正常运行,数据不受破坏。
8、 业务流程的可调整性
应当考虑客户业务流程可能出现的变化,所以在系统构架设计时要尽量排除业务流程的制约,即把流程中的各项业务结点工作作为独立的对象,设计成独立的模块或组件,充分考虑他们与其他各种业务对象模块或组件的接口,在流程之间通过业务对象模块的相互调用实现各种业务,这样,在业务流程发生有限的变化时(每个业务模块本身的业务逻辑没有变的情况下),就能够比较方便地修改系统程序模块或组件间的调用关系而实现新的需求。如果这种调用关系被设计成存储在配置库的数据字典里,则连程序代码都不用修改,只需修改数据字典里的模块或组件调用规则即可。
9、 业务信息的可调整性
应当考虑客户业务信息可能出现的变化,所以在系统构架设计时必须尽可能减少因为业务信息的调整对于代码模块的影响范围。
10、 使用方便性
使用方便性是不须提及的必然的需求,而使用方便性与系统构架是密切相关的。WinCE(1.0)的失败和后来改进版本的成功就说明了这个问题。WinCE(1.0)有太多层次的视窗和菜单,而用户则更喜欢简单的界面和快捷的操作。失败了应当及时纠正,但最好不要等到失败了再来纠正,这样会浪费巨大的财力物力,所以在系统构架阶段最好能将需要考虑的因素都考虑到。当然使用方便性必须与系统安全性协调平衡统一,使用方便性也必须与业务流程的可调整性和业务信息的可调整性协调平衡统一。“满足用户的需求,便于用户使用,同时又使得操作流程尽可能简单。这就是设计之本。”
11、构架样式的一致性
软件系统的构架样式有些类似于建筑样式(如中国式、哥特式、希腊复古式)。软件构架样式可分为数据流构架样式、调用返回构架样式、独立组件构架样式、以数据为中心的构架样式和虚拟机构架样式,每一种样式还可以分为若干子样式。构架样式的一致性并不是要求一个软件系统只能采用一种样式,就像建筑样式可以是中西结合的,软件系统也可以有异质构架样式(分为局部异质、层次异质、并行异质),即多种样式的综合,但这样的综合应该考虑其某些方面的一致性和协调性。每一种样式都有其使用的时机,应当根据系统最强调的质量属性来选择。
四、源代码的组织结构方面的考虑:
1、 开发可管理性
便于人员分工(模块独立性、开发工作的负载均衡、进度安排优化、预防人员流动对开发的影响:一个好的构架同时应有助于减少项目组的压力和紧张,提高软件开发效率)、利于配置管理、大小的合理性、适度复杂性;
1)便于人员分工-模块独立性、层次性
模块独立性、层次性是为了保证项目开发成员工作之间的相对独立性,模块联结方式应该是纵向而不是横向, 模块之间应该是树状结构而不是网状结构或交叉结构,这样就可以把开发人员之间的通信、模块开发制约关系减到最少。同时模块独立性也比较利于配置管理工作的进行。现在有越来越多的的软件开发是在异地进行,一个开发组的成员可能在不同城市甚至在不同国家,因此便于异地开发的人员分工与配置管理的源代码组织结构是非常必要的。
2)便于人员分工-开发工作的负载均衡
不仅仅是开发出来的软件系统需要负载均衡,在开发过程中开发小组各成员之间工作任务的负载均衡也是非重要的。所谓工作任务的负载均衡就是通过合理的任务划分按照开发人员特点进行分配任务,尽量让项目组中的每个人每段时间都有用武之地。这就需要在构架设计时应当充分考虑项目组手头的人力资源,在实现客户需求的基础上实现开发工作的负载均衡,以提高整体开发效率。
3)便于人员分工-进度安排优化;
进度安排优化的前提是模块独立性并搞清楚模块开发的先后制约关系。利用工作分解结构对所有程序编码工作进行分解,得到每一项工作的输入、输出、所需资源、持续时间、前期应完成的工作、完成后可以进行的工作。然后预估各模块需要时间,分析各模块的并行与串行(顺序制约),绘制出网络图,找出影响整体进度的关键模块,算出关键路径,最后对网络图进行调整,以使进度安排最优化。
有个家喻户晓的智力题叫烤肉片策略:约翰逊家户外有一个可以同时烤两块肉片的烤肉架,烤每块肉片的每一面需要10分钟,现要烤三块肉片给饥肠辘辘急不可耐的一家三口。问题是怎样才能在最短的时间内烤完三片肉。一般的做法花20分钟先烤完前两片,再花20分钟烤完第三片。有一种更好的方法可以节省10分钟,大家想想。
4)便于人员分工-预防员工人员流动对开发的影响
人员流动在软件行业是司空见惯的事情,已经是一个常见的风险。作为对这一风险的有效的防范对策之一,可以在构架设计中考虑到并预防员工人员流动对开发的影响。主要的思路还是在模块的独立性上(追求高内聚低耦合),组件化是目前流行的趋势。
5)利于配置管理(独立性、层次性)
利于配置管理与利于人员分工有一定的联系。除了逻辑上的模块组件要利于人员分工外,物理上的源代码层次结构、目录结构、各模块所处源代码文件的部署也应当利于人员分工和配置管理。(尽管现在配置管理工具有较强大的功能,但一个清楚的源码分割和模块分割是非常有好处的)。
6)大小的合理性与适度复杂性
大小的合理性与适度复杂性可以使开发工作的负载均衡,便于进度的安排,也可以使系统在运行时减少不必要的内存资源浪费。对于代码的可阅读性和系统的可维护性也有一定的好处。另外,过大的模块常常是系统分解不充分,而过小的模块有可能降低模块的独立性,造成系统接口的复杂。
2、 可维护性
便于在系统出现故障时及时方便地找到产生故障的原因和源代码位置,并能方便地进行局部修改、切割;(可维护性与运行可管理性不同)
3、 可扩充性:系统方案的升级、扩容、扩充性能
系统在建成后会有一段很长的运行周期,在该周期内,应用在不断增加,应用的层次在不断升级,因此采用的构架设计等方案因充分考虑升级、扩容、扩充的可行性和便利
4、 可移植性
不同客户端、应用服务器、数据库管理系统:如果潜在的客户使用的客户端可能使用不同的操作系统或浏览器,其可移植性必须考虑客户端程序的可移植性,或尽量不使业务逻辑放在客户端;数据处理的业务逻辑放在数据库管理系统中会有较好的性能,但如果客户群中不能确定使用的是同一种数据库管理系统,则业务逻辑就不能数据库管理系统中;
达到可移植性一定要注重标准化和开放性:只有广泛采用遵循国际标准,开发出开放性强的产品,才可以保证各种类型的系统的充分互联,从而使产品更具有市场竞争力,也为未来的系统移植和升级扩展提供了基础。
5、 需求的符合性
从源代码的组织结构看需求的符合型主要考虑针对用户需求可能的变化的软件代码及构架的最小冗余(同时又要使得系统具有一定的可扩展性)。
五、写系统构架设计文档应考虑的问题
构架工作应该在需求开发完成约80%的时候开始进行,不必等到需求开发全部完成,需要项目经理以具体的判断来评估此时是否足以开始构建软件构架。
给出一致的轮廓:系统概述。一个系统构架需要现有概括的描述,开发人员才能从上千个细节甚至数十个模块或对象类中建立一致的轮廓。
构架的目标应该能够清楚说明系统概念,构架应尽可能简化,最好的构架文件应该简单、简短,清晰而不杂乱,解决方案自然。
构架应单先定义上层的主要子系统,应该描述各子系统的任务,并提供每个子系统中各模块或对象类的的初步列表。
构架应该描述不同子系统间相互通信的方式,而一个良好的构架应该将子系统间的通信关系降到最低。
成功构架的一个重要特色,在于标明最可能变更的领域,应当列出程序中最可能变更的部分,说明构架的其他部分如何应变。
复用分析、外购:缩短软件开发周期、降低成本的有效方案未必是自行开发软件,可以对现有软件进行复用或进行外购。应考虑其对构架的影响。
除了系统组织的问题,构架应重点考虑对于细节全面影响的设计决策,深入这些决策领域:外部软件接口(兼容性、通信方式、传递数据结构)、用户接口(用户接口和系统层次划分)、数据库组织和内容、非数据库信息、关键算法、内存管理(配置策略)、并行性、安全性、可移植性、网络多人操作、错误处理。
要保证需求的可追踪性,即保证每个需求功能都有相应模块去实现。
构架不能只依据静态的系统目标来设计,也应当考虑动态的开发过程,如人力资源的情况,进度要求的情况,开发环境的满足情况。构架必须支持阶段性规划,应该能够提供阶段性规划中如何开发与完成的方式。不应该依赖无法独立运行的子系统构架。将系统各部分的、依赖关系找出来,形成一套开发计划。
六、结语
系统构架设计和千差万别的具体的开发平台密切相关,因此在此无法给出通用的解决方案,主要是为了说明哪些因素是需要考虑的。对于每个因素的设计策略和本文未提到的因素需要软件构架设计师在具体开发实践中灵活把握。不同因素之间有时是矛盾的,构架设计时需要根据具体情况进行平衡。
架构设计中的方法学
架构设计是一种权衡(trade-off)。一个问题总是有多种的解决方案。而我们要确定唯一的架构设计的解决方案,就意味着我们要在不同的矛盾体之间做出一个权衡。我们在设计的过程总是可以看到很多的矛盾体:开放和整合,一致性和特殊化,稳定性和延展性等等。任何一对矛盾体都源于我们对软件的不同期望。可是,要满足我们希望软件稳定运行的要求,就必然会影响我们对软件易于扩展的期望。我们希望软件简单明了,却增加了我们设计的复杂度。没有一个软件能够满足所有的要求,因为这些要求之间带有天生的互斥性。而我们评价架构设计的好坏的依据,就只能是根据不同要求的轻���缓急,在其间做出权衡的合理性。
1. 目标
我们希望一个好的架构能够:
重用:为了避免重复劳动,为了降低成本,我们希望能够重用之前的代码、之前的设计。重用是我们不断追求的目标之一,但事实上,做到这一点可没有那么容易。在现实中,人们已经在架构重用上做了很多的工作,工作的成果称为框架(Framework),比如说Windows的窗口机制、J2EE平台等。但是在企业商业建模方面,有效的框架还非常的少。
透明:有些时候,我们为了提高效率,把实现的细节隐藏起来,仅把客户需求的接口呈现给客户。这样,具体的实现对客户来说就是透明的。一个具体的例子是我们使用JSP的tag技术来代替JSP的嵌入代码,因为我们的HTML界面人员更熟悉tag的方式。
延展:我们对延展的渴求源于需求的易变。因此我们需要架构具有一定的延展性,以适应未来可能的变化。可是,如上所说,延展性和稳定性,延展性和简单性都是矛盾的。因此我们需要权衡我们的投入/产出比。以设计出具有适当和延展性的架构。
简明:一个复杂的架构不论是测试还是维护都是困难的。我们希望架构能够在满足目的的情况下尽可能的简单明了。但是简单明了的含义究竟是什么好像并没有一个明确的定义。使用模式能够使设计变得简单,但这是建立在我熟悉设计模式的基础上。对于一个并不懂设计模式的人,他会认为这个架构很复杂。对于这种情况,我只能对他说,去看看设计模式。
高效:不论是什么系统,我们都希望架构是高效的。这一点对于一些特定的系统来说尤其重要。例如实时系统、高访问量的网站。这些值的是技术上的高效,有时候我们指的高效是效益上的高效。例如,一个只有几十到一百访问量的信息系统,是不是有必要使用EJB技术,这就需要我们综合的评估效益了。
安全:安全并不是我们文章讨论的重点,却是架构的一个很重要的方面。
规则
为了达到上述的目的,我们通常需要对架构设计制定一些简单的规则:
功能分解
顾名思义,就是把功能分解开来。为什么呢?我们之所以很难达到重用目标就是因为我们编写的程序经常处于一种好像是重复的功能,但又有轻微差别的状态中。我们很多时候就会经不住诱惑,用拷贝粘贴再做少量修改的方式完成一个功能。这种行为在XP中是坚决不被允许的。XP提倡"Once and only once",目的就是为了杜绝这种拷贝修改的现象。为了做到这一点,我们通常要把功能分解到细粒度。很多的设计思想都提倡小类,为的就是这个目的。
所以,我们的程序中的类和方法的数目就会大大增长,而每个类和方法的平均代码却会大大的下降。可是,我们怎么知道这个度应该要如何把握呢,关于这个疑问,并没有明确的答案,要看个人的功力和具体的要求,但是一般来说,我们可以用一个简单的动词短语来命名类或方法的,那就会是比较好的分类方法。
我们使用功能分解的规则,有助于提高重用性,因为我们每个类和方法的精度都提高了。这是符合大自然的原则的,我们研究自然的主要的一个方向就是将物质分解。我们的思路同样可以应用在软件开发上。除了重用性,功能分解还能实现透明的目标,因为我们使用了功能分解的规则之后,每个类都有自己的单独功能,这样,我们对一个类的研究就可以集中在这个类本身,而不用牵涉到过多的类。
根据实际情况决定不同类间的耦合度
虽然我们总是希望类间的耦合度比较低,但是我们必须客观的评价耦合度。系统之间不可能总是松耦合的,那样肯定什么也做不了。而我们决定耦合的程度的依据何在呢?简单的说,就是根据需求的稳定性,来决定耦合的程度。对于稳定性高的需求,不容易发生变化的需求,我们完全可以把各类设计成紧耦合的(我们虽然讨论类之间的耦合度,但其实功能块、模块、包之间的耦合度也是一样的),因为这样可以提高效率,而且我们还可以使用一些更好的技术来提高效率或简化代码,例如Java中的内部类技术。可是,如果需求极有可能变化,我们就需要充分的考虑类之间的耦合问题,我们可以想出各种各样的办法来降低耦合程度,但是归纳起来,不外乎增加抽象的层次来隔离不同的类,这个抽象层次可以是具体的类,也可以是接口,或是一组的类(例如Beans)。我们可以借用Java中的一句话来概括降低耦合度的思想:"针对接口编程,而不是针对实现编程。
设计不同的耦合度有利于实现透明和延展。对于类的客户(调用者)来说,他不需要知道过多的细节(实现),他只关心他感兴趣的(接口)。这样,目标类对客户来说就是一个黑盒子。如果接口是稳定的,那么,实现再怎么扩展,对客户来说也不会有很大的影响。以前那种牵一发而动全身的问题完全可以缓解甚至避免。
其实,我们仔细的观察GOF的23种设计模式,没有一种模式的思路不是从增加抽象层次入手来解决问题的。同样,我们去观察Java源码的时候,我们也可以发现,Java源码中存在着大量的抽象层次,初看之下,它们什么都不干,但是它们对系统的设计起着重大的作用。
够用就好 :
我们在上一章中就谈过敏捷方法很看重刚好够用的问题,现在我们结合架构设计来看:在同样都能够满足需要的情况下,一项复杂的设计和一项简单的设计,哪一个更好。从敏捷的观点来看,一定是后者。因为目前的需求只有10项,而你的设计能够满足100项的需求,只能说这是种浪费。你在设计时完全没有考虑成本问题,不考虑成本问题,你就是对开发组织的不负责,对客户的不负责。
应用模式
这篇文章的写作思路很多来源于对模式的研究。因此,文章中到处都可以看到模式思想的影子。模式是一种整理、传播思想的非常优秀的途径,我们可以通过模式的方式学习他人的经验。一个好的模式代表了某个问题研究的成果,因此我们把模式应用在架构设计上,能够大大增强架构的稳定性。
抽象
架构的本质在于其抽象性。它包括两个方面的抽象:业务抽象和技术抽象。架构是现实世界的一个模型,所以我们首先需要对现实世界有一个很深的了解,然后我们还要能够熟练的应用技术来实现现实世界到模型的映射。因此,我们在对业务或技术理解不够深入的情况下,就很难设计出好的架构。当然,这时候我们发现一个问题:怎样才能算是理解足够深入呢。我认为这没有一个绝对的准则。
一次,一位朋友问我:他现在做的系统有很大的变化,原先设计的工作流架构不能满足现在的要求。他很希望能够设计出足够好的工作流架构,以适应不同的变化。但是他发现这样做无异于重新开发一个lotus notes。我听了他的疑问之后觉得有两点问题:
首先,他的开发团队中并没有工作流领域的专家。他的客户虽然了解自己的工作流程,但是缺乏足够的理论知识把工作流提到抽象的地步。显然,他本身虽然有技术方面的才能,但就工作流业务本身,他也没有足够的经验。所以,设计出象notes那样的系统的前提条件并不存在。
其次,开发一个工作流系统的目的是什么。原先的工作流系统运作的不好,其原因是有变化发生。因此才有改进工作流系统的动机出现。可是,毕竟notes是为了满足世界上所有的工作流系统而开发的,他目前的应用肯定达不到这个层次。
因此,虽然做不到最优的业务抽象,但是我们完全可以在特定目的下,特定范围内做到最优的业务抽象。比如说,我们工作流可能的变化是工组流路径的变化。我们就完全可以把工作流的路径做一个抽象,设计一个可以动态改变路径的工作流架构。
有些时候,我们虽然在技术上和业务上都有所欠缺,没有办法设计出好的架构。但是我们完全可以借鉴他人的经验,看看类似的问题别人是如何解决的。这就是我们前面提到的模式。我们不要把模式看成是一个硬性的解决方法,它只是一种解决问题的思路。Martin Fowler曾说:"模式和业务组件的区别就在于模式会引发你的思考。
在《分析模式》一书中,Martin Fowler提到了分析和设计的区别。分析并不仅仅只是用用例列出所有的需求,分析还应该深入到表面需求的的背后,以得到关于问题本质的Mental Model。然后,他引出了概念模型的概念。概念模型就类似于我们在讨论的抽象。Martin Fowler提到了一个有趣的例子,如果要开发一套软件来模拟桌球游戏,那么,用用例来描述各种的需求,可能会导致大量的运动轨迹的出现。如果你没有了解表面现象之后隐藏的运动定律的本质,你可能永远无法开发出这样一个系统。
关于架构和抽象的问题,在后面的文章中有一个测量模式的案例可以很形象的说明这个问题。
架构的一些误解
我们花了一些篇幅来介绍架构的一些知识。现在回到我们的另一个主题上来。对于一个敏捷开发过程,架构意味着什么,我们该如何面对架构。这里我们首先要澄清一些误解:
误解1:架构设计需要很强的技术能力。从某种程度来说,这句话并没有很大的错误。毕竟,你的能力越强,设计出优秀架构的几率也会上升。但是能力和架构设计之间并没有一个很强的联系。即使是普通的编程人员,他一样有能力设计出能实现目标的架构。
误解2:架构由专门的设计师来设计,设计出的蓝图交由程序员来实现。我们之所以会认为架构是设计师的工作,是因为我们喜欢把软件开发和建筑工程做类比。但是,这两者实际上是有着很大的区别的。关键之处在于,建筑设计已经有很长的历史,已经发展出完善的理论,可以通过某些理论(如力学原理)来验证设计蓝图。可是,对软件开发而言,验证架构设计的正确性,只能够通过写代码来验证。因此,很多看似完美的架构,往往在实现时会出现问题。
误解3:在一开始就要设计出完善的架构。这种方式是最传统的前期设计方式。这也是为XP所摒弃的一种设计方式。主要的原因是,在一开始设计出完美的架构根本就是在自欺欺人。因为这样做的基本假设就是需求的不变性。但需求是没有不变的(关于需求的细节讨论,请参看拙作『需求的实践』)。这样做的坏处是,我们一开始就限制了整个的软件的形状。而到实现时,我们虽然发现原来的设计有失误之处,但却不愿意面对现实。这使得软件畸形的生长。原本一些简单的问题,却因为别扭的架构,变得非常的复杂。这种例子我们经常可以看到,例如为兼容前个版本而导致的软件复杂性。而2000年问题,TCP/IP网络的安全性问题也从一个侧面反映了这个问题的严重性。
误解4:架构蓝图交给程序员之后,架构设计师的任务就完成了。和误解2一样,我们借鉴了建筑工程的经验。我们看到建筑设计师把设计好的蓝图交给施工人员,施工人员就会按照图纸建造出和图纸一模一样的大厦。于是,我们也企图在软件开发中使用这种模式。这是非常要命的。软件开发中缺乏一种通用的语言,能够充分的消除设计师和程序员的沟通隔阂。有人说,UML不可以吗?UML的设计理念是好的,可以减轻沟通障碍问题。可是要想完全解决这个问题,UML还做不到。首先,程序员都具有个性化的思维,他会以自己的思维方式去理解设计,因为从设计到实现并不是一项机械的劳动,还是属于一项知识性的劳动(这和施工人员的工作是不同的)。此外,对于程序员来说,他还极有可能按照自己的想法对设计图进行一定的修改,这是非常正常的一项举动。更糟的是,程序员往往都比较自负,他们会潜意识的排斥那些未经过自己认同的设计。
架构设计的过程模式
通常我们认为模式都是用在软件开发、架构设计上的。其实,这只是模式的一个方面。模式的定义告诉我们,模式描述了一个特定环境的解决方法,这个特定环境往往重复出现,制定出一个较好的解决方法有利于我们在未来能有效的解决类似的问题。其实,在管理学上,也存在这种类似的这种思维。称为结构性问题的程序化解决方法。所以呢,我们完全可以把模式的思想用在其它的方面,而目前最佳的运用就是过程模式和组织模式。在我们的文章中,我们仅限于讨论过程模式。 方法论对软件开发而言意味着什么?我们如何看待软件开发中的方法论?方法论能够成为软件开发的救命稻草吗?在读过此文后,这些疑惑就会得到解答。
架构设计中的方法学(1)——方法源于恐惧
方法论
方法论的英文为Methodology,词典中的解释为:“A series of related methods or techniques”,我们可以把它定义为软件开发(针对软件开发)的一整套方法、过程、规则、实践、技术。关于方法论出现的问题,我很赞同Alistair Cockburn的一句话,“方法论源于恐惧。”出于对项目的超期、成本失控等等因素的恐惧,项目经理们从以前的经验出发,制定出了一些控制、监测项目的方法、技巧。这就是方法论产生的原因。
在Agile Software Development一书中,作者提到了方法论的十三个要素,基本能够函盖方法论的各个方面:
角色(Roles)、个性(Personality)、技能(Skills)、团队(Teams)、技术(Techniques)、活动(Activities)、过程(Process)、工件(Work products)、里程碑(Milestones)、标准(Standards)、质量(Quality)、工具(Tools)、团队价值(Team Values)。
它们之间的关系可以用一幅图来表示:
图 1. 方法论的十三个要素
很多的方法论,都涉及了上面列举的十三要素中的部分要素,因此,我们可以把方法论看作是一个抽象的、无穷的超集,而现实中的方法论都是指超集的一个有限的子集而已。它们之间的关系就好像有理数和1到100之间的整数的关系一样。不论是XP,还是UI设计经验之类,都属于方法论的一个子集,只是这两个子集之间有大小的差别而已。我们还应该看到,讨论一个完备的方法论是没有意义的,因此这种方法论铁定不存在,就好像你视图穷举出所有的有理数一样荒唐。因此,我们关于一个通用的方法论的说法也是无意义的。好的方法论,比如说XP、水晶系列,它们都有一个适合的范围,因为它们了解一点,自己并不是一个无所不能的方法论。
在现实中,我们其实不断的在接触方法论。比如说,为了控制项目的进度,项目经理要求所有的开发人员每周递交一份详细的进度报告,这就是一种方法、一种技巧。如果把开发过程中的这些技巧系统的组织起来,就能够成为一种方法论。你可能会说,那一种方法论的产生也太容易了吧。不,这样产生的方法论并没有太大的实用价值,没有实用价值的方法论根本就没有存在的必要。因此,一个成功的方法论是要能够为多个的项目所接受,并且能够成功实现软件的交付的方法论。
我和我的同事在实践中做了一些试验,希望能够把一些好的方法论应用于开发团队。试验的结果很无奈,方法论实施的效果并不理想,一开始我们认为是方法本身的原因,到后来,我们发现事情并不是这么简单。在试验的过程中,开发人员一致认同方法论的优势所在,但是在实施过程中,鲜有坚持的下来的。在Agile Software Development中,我发现作者遇到了和我们一样的问题。
Alistair Cockburn在和大量的项目团队的访谈之后,写成了Agile Software Development一书。在访谈之前,他笃定自己将会发现高度精确的过程控制是成功的关键所在,结果他发现事实并非如此,他把他的发现归结为7条定律。而我在实际中的发现也包含在这七条定律中,总结起来就只有两点:沟通和反馈。
只要能够保证良好的沟通和即时的反馈,那么开发团队即使并没有采用先进的方法论,一样可以成功。相反,那些“高质量”的团队却往往由于缺乏这两个因素而导致失败(我们这里指的失败是用户拒绝使用最终的软件)。最有效,而成本也最低的沟通方法就是面对面(face to face)的沟通,而随着项目团队的变大,或是另外一些影响因素的加入(比如地理位置的隔绝),面对面的沟通越来越难实现,这导致沟通的成本逐渐加大,质量也慢慢下降。但这并不是说非面对面的沟通不可,重要的是我们需要知道不同的沟通方式的成本和质量并不相同。XP方法尤为强调面对面的沟通,通过现场客户、站立会议、结对编程等方式来保证沟通的有效。在我的经验中,一个开发团队其实是需要多种沟通方式的结合的。完全的面对面的沟通对某些团队来说是很难实现的,那么问题的关键就在于你如何应用沟通的方式来达到你希望的效果。在前不久结束的欧莱雅创业计划大赛上,有一支团队特别引人注目,他们彼此间素未谋面,仅仅凭借Internet和电话完成了高效的合作。他们虽然没有使用面对面的沟通方式,但是仍然达成了既定的目标。软件开发也是一样的,面对面的沟通是非常有必要的,但其它的沟通方式也是需要的。
再看反馈,不论是控制进度,还是保证客户的满意度,这些活动都需要管理成本。软件开发中的管理成本的一个通性就是伴随有中间产出物(intermediate delivery)。比如说我们的需求规约、分析文档、设计文档、测试计划,这些都属于中间产出物。中间产出物的增加将会带来效率下降的问题,因为开发人员的时间都花在了完成中间产出物的工作上,花在给软件新功能上的时间就减少了。而中间产出物的主要目的是两个,一个是为了保证软件如客户所愿,例如需求规约;另一个是为了作为团队中的其他成员工作的输入,例如开发计划、测试计划等。因此,我们也可以针对这两点来商讨对策,一种是采用迭代的思想,提高软件发布的频率,以保证客户的需求被确实的满足,另一种就是缩小团队的沟通范围,保证成员能够从其他人那里得到新的思路,而不是撰写规范的内部文档(内部文档指那些仅为内部开发人员之间的沟通所需要的文档)。
因此,一个软件项目的成功和你采用的开发方法论并没有直接的关系。
重量
我们根据把拥有大量artifact(RUP官方翻译为工件,意思是软件开发过程中的中间产物,如需求规约、设计模型等)和复杂控制的软件开发方法称为重型(Heavy Weight)方法,相对的,我们称artifact较少的方法为轻型(Light Weight)方法。在传统的观念中,我们认为重型方法要比轻型安全许多。因为我们之所以想出重型方法,就是由于在中大型的项目中,项目经理往往远离代码,他无法有效的了解目前的工程的进度、质量、成本等因素。为了克服未知的恐惧感,项目经理制定了大量的中间管理方法,希望能够控制整个项目,最典型的莫过于要求开发人员频繁的递交各种表示项目目前状态的报告。
在Planning XP一书中有一段讨论轻重型方法论的精辟论述,它把重型方法论归结为一种防御性的姿态(defensive posture),而把轻型方法论归结为一种渴望成功(Plan to win)的心态。如果你是采用了防御性姿态,那么你的工作就集中在防止和跟踪错误上,大量的工作流程的制定,是为了保证项目不犯错误,而不是项目成功。而这种方法也不可谓不好,但前提是如果整个团队能够满足前面所提到的两个条件的话,项目也肯定会成功,但是重型方法论的一个弊端就在于,大家都在防止错误,都在惧怕错误,因此人和人之间的关系是很微妙的,要达到充分的沟通也是很难的。最终,连对人的评价也变成是以避免错误的多寡作为考评的依据,而不是成就。我们在做试验的时候,一位项目经理开玩笑说,“方法论源自项目经理的恐惧,这没错。但最糟糕的是整个团队只有项目经理一个人恐惧,如果能够做到人人的恐惧,那大家也就没有什么好恐惧的了。”这句话提醒了我们,如果一个团队的精神就是力求成功,那么这支团队的心态就和其它的团队不同了,尤其是对待错误的心态上。根本就没有必要花费大量的精力来预防错误,错误犯了就犯了,即时改正就可以了。这其实就是渴望成功的心态。
方法论的艺术
管理,被称为科学和艺术的融合体,而管理的艺术性部分很大程度的体现在人的管理上。我说,方法学,一样是科学和艺术的融合体。这是有依据的,其实方法论和管理学是近亲关系,管理学中有一门分支是项目管理,而在软件组织中,项目管理是非常重要的,方法学就是一种针对软件开发的一种特定的项目管理(或是项目管理的一个子集)。
重型方法最大的一个问题就在于他不清楚或忽略了艺术这个层次,忽视了人的因素,把人做为一个计量单位,一种资源,一种线性元素。而人的要素在软件开发中是非常重要的,软件开发实际上是一种知识、智力的转移过程,最终形成的产品是一种知识产品,它的成本取决于开发者的知识价值,因此,人是最重要的因素。而人这个要素是很难衡量的,每个人都有不同的个性、想法、经验、经历,这么多复杂的因素加在一起,就导致了人的不可预见性。因此,我们强调管人的艺术。
最简单的例子是,在重型方法中,我们的基本假设是对人的不信任。项目经理要控制项目。但不信任就会产生很多的问题,比如士气不高,计划赶不上变化,创新能力低下,跳槽率升高等等。人都是希望被尊重的,技术人员更看重这一点,而很多公司也口口声声说自己多么多么以人为本,可是采用的却是以不信任人为前提的开发方法,言行不一。我们说敏捷方法的出发点是相互信任,做到这一点是很难的,但是一旦做到了,那这个团队就是非常具有竞争力的。因此,这就产生了一个问题,在没有做到完全的相互信任之前,我们到底相不相信他人呢,这就是我提到的艺术性的问题,什么时候你要相信人?什么时候你不相信人,这些都是需要权衡的问题,也都是表现你艺术性的问题。
敏捷方法
敏捷代表着有效和灵活。我们称那些轻型的、有效的方法为敏捷方法。在重型方法中,我们在一些不必要、重复的中间环节上浪费了太多的精力,而敏捷则避免了这种浪费。我们的文章将会重点的讨论敏捷(Agile)方法论的思想,敏捷这个名字的前身就是轻型。目前已经有了一个敏捷联盟,他们制定了敏捷宣言:
Individuals and interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
而我对敏捷的理解包括了几个方面:
较低的管理成本和高质量的产出。软件开发存在两个极端:一个是没有任何的管理成本,所有的工作都是为了软件的产出,但是这种方式却往往导致软件开发过程的混沌,产品的低质量,团队士气的低落。另一个是大量管理活动的加入,评审、变更管理,缺陷跟踪,虽然管理活动的加入能够在一定程度上提高开发过程的有序性,但是成本却因此提高,更糟糕的是,很容易导致团队的低效率,降低创新能力。因此,敏捷方法试图寻找一个平衡点,用低成本的管理活动带来最大的产出,即软件的高质量。
尊重人性。敏捷方法尊重人性,强调效率。软件开发可以说是一种脑力的投入,如果不能保证开发人员的自愿投入,产品就肯定要打折扣。事实多次的证明,一个愿意投入的开发人员和一个不愿意投入的开发人员效率相差在三倍以上,对组织的贡献更是在十倍以上。
沟通和反馈是一切的基础。我们已经讨论过沟通的重要程度,而即时的反馈是拥抱变化的前提条件。
客户是上帝。没有客户就没有一切,客户的重要性可以用一句话来形容,就是以合理的成本建造合适的软件(build the right system at the right cost)。
敏捷其实也有轻重之分,关键在于是否能够做到有效和灵活。因此,敏捷方法论提倡的一个思想是“刚好够(barely sufficient)”。不过这个“刚好够”可不是那么容易判断的。一支8个人的团队采用XP方法,随着方法的熟练使用,团队的能力在不断的增强,能够处理的问题越越来越复杂,也许他们能够处理采用重型方法的20个人团队能够处理的问题。可是如果团队的人数突然增加到12人,这支团队肯定就会出问题,他的表现可能还不如那支20个人的团队了。人数增加的时候,原先的方法肯定还做适当的调整,比如说,在原先的敏捷方法上增加一些重型方法的技巧。我们不能够要求一支6个人的团队和一支20个人的团队用同样的方法,前者可能采用轻一些的敏捷方法,后者可能采用重一些的敏捷方法,关键的问题在于,两支团队都把重点放在沟通、反馈、频繁交付软件这些关键的因素上,也就是做到有效和灵活。
架构设计
架构(Architecture)(也有被称为体系结构的)是软件设计中非常重要的一个环节。软件开发的过程中只要需求和架构确定之后,这个软件就基本上可以定型了。这就好比骨骼确定了,这个人的体形就不会有很大的变化。因此我选择了架构设计来讨论敏捷软件开发(需求我已经写过了)。我们在前面讨论过超集和子集的概念,因此我们接下去要讨论的架构设计也是一个很小的子集。方法论如果没有经历过多个项目的检验是不能称为成功的方法论的,我也并不认为我的架构设计就是一个好的方法论,但引玉还需抛砖,他的主要目的是为了传播一种思想。因此,我采用了模式语言(PLOP)做为写作架构设计的形式,主要的原因就是模式是一种很好的组织思想的方法。
因此,在我们接下去的历程中,我们集中讨论的东西就围绕着架构、方法学、敏捷这三个要素展开。这篇文章并不是讨论如何编码实现软件架构的,也不要单纯的把它看作架构设计的指南,其实文中的很多思想来自于方法论,因此提到的很多架构设计的思想也适用于其它工作,如果能够了解这一点,看这篇文章的收获可能会更多一些。
架构设计中的方法学(3)——架构源自需求
从需求到架构
在需求阶段,我们可以得到一些代表需求调研成果的中间产物。比如说,CRC卡片、基本用例模型、用户素材、界面原型、界面原型流程图
、非功能需求、变化案例等。我们在架构设计阶段的主要工作就是要把这些需求阶段的中间产物转换为架构设计阶段的中间产物。
其实,架构设计就是要完成两项工作,一是分析,二是设计。分析是分析需求,设计则是设计软件的大致结构。很多的方法论把分析和设计两种活动分开来,但其实这两者是很难区分的,做分析的时候会想到如何设计,而思考如何设计反过来又会影响分析的效果。可以说,他们两者之间是相互联系和不断迭代的。这种形态我们将会在后面的迭代设计模式中详细的讨论。
在敏捷方法论中,需求最好是迭代进行的,也就是说一点一点的作需求。这种做法在那些需求变化快的项目中尤其适用。由于我们采用的流程是一种迭代式的流程,这里我们将会面临着如何对待上一次迭代的中间产物的问题。如果我们每一次迭代都需要修改已存在的中间产物,那么这种维护的成本未免过大。因此,敏捷方法论的基本做法是,扔掉那些已经没有用处的中间产物。还记得在第一章的时候,我们强调说软件要比文档重要。我们生成中间产物的目的都是为了生成最终的程序,对于这些已经完成作用的模型,没有必要付出额外的维护成本。
不要断章取义的采用抛弃模型的做法。因为,抛弃模型的做法需要一个适合环境的支持。后面会针对这个话题开展大范围的讨论。这里我们简单的做一个了解:
简单化:简单的模型和简单的程序。模型和程序越复杂,就需要更多的精力来处理它们。因此,我们尽可能的简化它们,为的是更容易的处理它们。
高效的沟通渠道:通过增强沟通的效果来减少对中间产物的需要。试想一下,如果我随时能够从客户那里得到需求的细节资料,那前期的需求调研就没有必要做的太细致。
角色的交叉轮换:开发人员之间建立起交换角色的机制,这样,能够尽量的避免各子系统诸侯割据的局面。
清晰的流程:或者我们可以称之为明确的过程。过程在方法论中向来都是一个重点,敏捷方法论也不例外。开发人员能够清楚的知道,今天做什么,明天做什么。过程不是给别人看的,而是给自己用的。
工具:好用的工具能够节省大量的时间,这里的工具并不仅仅指CASE工具,还包括了版本控制工具、自动化测试工具、画图工具、文档制作和管理工具。使用工具要注意成本和效益的问题。
标准和风格:语言不通是沟通的一个很大的障碍。语言从某个角度来看属于一种标准、一种风格。因此,一个团队如果采用同样的编码标准、文档标准、注释风格、制图风格,那么这个团队的沟通效率一定非常的高。
如果上述的环境你都不具备,或是欠缺好几项,那你的文档的模型还是留着的好。
仅针对需求设计架构
仅针对需求设计架构的含义就是说不要做未来才有用的事情。有时候,我们会把架构考虑的非常复杂,主要的原因就是我们把很多未来的因素放入到现在来考虑。或者,我们在开发第一个产品的时候就视图把它做成一个完美的框架。以上的这两种思路有没有错呢?没有错,这只是如何看待投入的问题,有人希望开始的时候多投入一些,这样后续的投入就会节省下来。但在现实中,由于需求的不确定性,希望通过增加开始阶段的投入来将降低未来的投入往往是难以做到的,框架的设计也绝对不是能够一蹴而就的,此这种做法并不是一个好的做法。所以我们在后头会着重论述架构设计的简单性和迭代过程,也就是因为这个理由。
模式
模式将可以帮助我们抓住重点。为了解决设计文档编辑器引出的七个问题,一共使用了8种不同的模式。这8种模式的组合其实就是架构,因为它们解决的,都是系统中最高层的问题。
在实践中,人们发现架构也是存在模式的。比如,对于系统结构设计,我们使用层模式;对于分布式系统,我们使用代理模式;对于交互系统,我们使用MVC(模型-视图-控制器)模式。模式本来就是针对特定问题的解,因此,针对需求的特点,我们也可以采用相应的模式来设计架构。
在sun网站上提供的宠物商店的范例中,就把MVC模式的思想扩展成为架构的思想,用于提供不同的界面视图:
我们可以了解到在图的背后隐藏着的需求:系统需要支持多种用户界面,包括为普通用户提供的HTML界面,为无线用户提供的WML界面,为管理员提供的Swing界面,以及为B2B业务设计的WebService界面。这是系统最重要的需求,因此,系统的设计者就需要确定一个稳定的架构,以解决多界面的问题。相对于多界面的问题,后端的业务处理逻辑都是一致的。比如HTML界面和WML界面的功能并没有太大的差别。把处理逻辑和界面分离开来还有额外的好处,可以在添加功能的同时,不涉及界面的改动,反之亦然。这就是我们在第二篇中提到的耦合度的问题。
MVC模式正可以适用于解决该问题。系统使用控制器来为业务逻辑选择不同的界面,这就完成了MVC架构的设计思路。在架构设计的工作中,我们手头上有模式这样一张好牌,有什么理由不去使用它呢?
抓住重点
在架构设计一开始,我们就说架构是一种抽象,那就是说,架构设计摒弃了具体的细节,仅仅抓住软件最高层的概念,也就是最上层、优先级最高、风险最大的那部分需求。
我们考虑、分析、解决一个问题,一定有一个渐进的过程。架构设计就是解决问题其中比较早期的一个阶段,我们不会在架构设计这个阶段投入过多的时间(具体的原因在下文会有讨论),因此关键点在于我们要能够在架构设计中把握住需求的重点。比如,我们在模式一节中提到了分布式系统和交互系统,分布和交互就是这两个系统的重点。那么,如果说我们面对的是一个分布式的交互系统,那么,我们就需要把这两种特性做为重点来考虑,并以此为基础,设计架构。而我们提到的宠物商店的范例也是类似的,除了MVC的架构,还有很多的设计问题需要解决,例如用于数据库访问的数据对象,用于视图管理的前端控制器,等等(具体使用到的架构模式可以访问sun的网站)。但是这些相对于MVC模式来说,属于局部的,优先级较低的部分,可以在架构确定后再来设计。
架构设计和领域专家
一个架构要设计的好,和对需求的理解是分不开的。因此在现实中,我们发现业务领域专家凭借着他对业务领域的了解,能够帮助开发人员设计出优秀的架构来。架构是需要抽象的,它是现实社会活动的一个基本模型,而业务领域的模型仅仅凭开发人员是很难设计出来的。在ERP的发展史上,我们看到MRP发展为MRPII,在发展到闭环MRP,直到发展成为现在的ERP,主要的因素是管理思想的演化,也就是说,对业务领域的理解进步了,架构才有可能进步。
因此,敏捷型架构设计的过程中,我们也非常强调领域专家的作用
架构设计中的方法学(4)——团队设计
团队设计是敏捷方法论中很重要的一项实践。我们这里说的团队,指的并不是复数的人。一群人就是一群人,并没有办法构成团队。要想成为团队,有很多的工作要做。
我们之所以考虑以团队
为单位来考虑架构设计,是因为软件开发本身就不是一件个人的事情,架构设计更是如此。单个人的思维不免有考虑欠妥之处,单个人的学识也不可能覆盖所有的学科。而组织有效的团队却能够弥补这些缺憾。
谁来负责架构的设计?
在我们的印象中,总认为架构设计是那些所谓架构设计师的专属工作,他们往往拥有丰富的设计经验和相关的技能,他们不用编写代码,就能够设计出理论上尽善尽美的架构,配有精美的图例。
问题1:理论上设计近乎完美的架构缺乏程序的证明,在实际应用中往往会出这样那样的问题。
问题2:设计师设计架构带有很大的主观性,往往会忽视客户的需求,导致架构无法满足需求。
问题3:实现的程序员对这种架构有抵触的情绪,或是因为不理解架构而导致架构实现的失败。
问题4:架构师设计架构主要是依据自己的大量经验,设计出的架构不能真实的反映目前的软件需要。
解决办法
团队设计的理论依据是群体决策。和个人决策相比,群体决策的最大好处就是其结论要更加的完整。而群体决策虽然有其优点,但其缺点也是很明显的:需要额外付出沟通成本、决策效率低、责任不明确、等等。但是群体决策如果能够组织得当的话,是能够在架构设计中发挥很大的优势的
避免象牙塔式的架构设计
对软件来说,架构设计是一项至关重要的工作。这样的工作交给某个人是非常危险的。即便这个人再怎么聪明,他也可能会遗漏部分的细节。组织有效的团队的力量是大大超过个人的力量的,因此团队的成果较之个人的成果,在稳定性和思考的周密程度上,都要更胜一筹。
Scott W. Ambler在其著作中给出了象牙塔式架构(ivory tower architecture)的概念:
An ivory tower architecture is one that is often developed by an architect or architectural team in relative isolation to the day-to-day development activities of your project team(s).
中国现在的软件开发行业中也逐渐出现了象牙塔式的架构设计师。这些架构师并不参与实际的程序编写,他的工作就是为项目制作出精美的架构模型,这种架构模型在理论上是相当完美的。
例1:在XP中,我们基本上看不到架构设计的影子。并不是说采用XP技术的团队就不需要架构设计。XP不存在专门的设计时期,它提倡使用一些简单的图例、比喻的方式来表达软件的架构,而这种的架构设计是无时无刻不在进行的。其实,XP中的设计采用的就是团队设计的方式,结队编程(Pair Programming)和代码的集体所有制(Collective Ownership)是团队设计的基础,也就是基于口述的沟通方式。通过采用这样的方式,XP几乎不需要文档来表达架构的设计。
优秀的架构师能够充分的利用现有框架,减少软件的投入,增强软件的稳定性。这些都没有错,但是问题在于“过犹不及”。象牙塔式架构师往往会出现文章开始指出的那些问题。架构设计其实并不是非常复杂的工作,但它要求开发人员具备相关的技能、经验以及对问题域有一定的了解。开发人员往往都具有相关的技术技能(编程、数据库设计、建模),而对问题域的理解可以从用户和行业专家那里获得帮助。因此,在理论上,我们要实现架构设计的团队化是完全可能的。
在上面的象牙塔式架构定义中,我们看到架构师和日常的开发工作是隔绝的。这样设计出的架构有很大的局限性。在现实中,我们还会发现另外一种角色,他来自于开发团队外部,为开发人员提供相关的技术或业务的培训。这种角色称为教练,在软件开发中是非常重要的角色,不能够和象牙塔式架构设计师之间画等号。
选择你的设计团队
软件的架构在软件的生命周期的全过程中都很重要,也就是说,软件开发团队中的所有人员都需要和架构打交道。因此,最好的团队组织方式是所有开发人员都参与架构的设计,我们称这种方式为全员参与。全员参与的方式保证了所有开发人员都能够对架构设计提出自己的见解,综合多方面的意见,在全体开发人员中达成一致。这种方式尤其适合于一些小的团队。
还是会有很多的团队由于种种的原因不适合采用全员参与的方式。那么,组织优秀的开发人员组成设计组也是比较好的方式。一般,我们选择那些在项目中比较重要的,有较多开发经验,或是理论扎实的那些人来组成设计组。当然,如果你考虑到为组织培养后续力量,你也可以让一些新手加入设计组,或是你觉得自己的开发力量不足,邀请外部的咨询力量介入,这完全取决于具体的情况。
设计组不同于我们之前提到的象牙塔式架构设计师。设计组设计出来的架构只能称为原始架构,它是需要不断的反馈和改进的。因此,在架构实现中,设计组的成员将会分布到开发团队的各个领域,把架构的思想带给所有开发人员,编写代码来检验架构,并获得具体的反馈,然后所有的成员再集中到设计组中讨论架构的演进。
团队设计中存在的问题
在团队设计的过程,我们会遇到各种各样的问题,首当其冲的就是沟通成本的问题。架构设计时,需求尚未被充分理解,软件的设计思路还处于萌发的状态。这样的情况下,团队的每位成员对软件都有独特的见解,这些可能有些是相同的,有些是互斥的。就好比盲人摸象一样,他们的观点都代表了软件的一部分或是一方面,但是没有办法代表软件的全部。
在敏捷方法论中,我们的每一个流程都是迅速进行、不断改进的。架构设计也是一样,我们不可能在一次架构设计上花费更多的时间。而团队决策总是倾向于较长的讨论和权衡。
例2中的问题在架构设计中时有发生,纯技术的讨论很容易上升称为争吵。这种情况几乎没有办法完全避免。团队型的决策必然会发生观念的冲突。控制一定程度内的观念的冲突对团队的决策是有益,但是如果超出了这个程度就意味着失控了,需要团队领导者的调节。而更重要的,我们需要注意沟通的技巧
团队沟通
团队进行架构设计的时候沟通是一个非常需要注意的问题,上述的情境在软件组织中是经常发生的,因为技术人员很自然认为自己的技术比别人的好,如果自己的技术受到质疑,那怕对方是抱着讨论的态度,也无异于自身的权威受到了挑战,面子是无论如何都需要捍卫的。而沟通如果带上了这样一层主观色彩,那么沟通信息的受众就会潜意识的拒绝接受信息。相反,他会找出对方话语中的漏洞,准备进行反击。因此,我们要注意培养一种良好的沟通氛围。
在实际的观察中,我发现团队沟通中存在两种角色,一种是建议者,他们经常能够提���建议。一种是质疑者,他们对建议提出否定性的看法。这两种角色是可能互换的,现在的建议者可能就是刚才的质疑者。质疑者的发言是很能打击建议者的积极性的,而在一个脑力激荡的会议中,最好是大家都能够扮演建议者的角色,这就要求沟通会议的主持者能够掌握好这一点,对建议给予肯定的评价,并鼓励大家提出新的建议。
例2:敏捷方法非常注重的就是团队的沟通。沟通是一个很有意思的话题,讲起来会花费大量的时间,我们这里只是针对架构设计中可能存在的沟通问题做一个简单的讨论。我们这里假设一个讨论情境,这个情境来源于真实的生活:项目主管徐辉、设计师李浩、设计师罗亦明正在讨论一个新的软件架构。 "李浩你认为这个软件数据库连接部分应该如何考虑?"徐辉问。李浩想了想,"我觉得方案A不错…" "方案A肯定有问题!这个软件和上一次的又不同。"罗亦明打断了李浩的发言。 "你懂什么!你到公司才多久,方案A是经过很长时间的证明的!"发言被打断,李浩有点恼火,罗亦明进入公司没有多久,但在一些事情上老是和他唱反调。 "我进公司多久和方案A的错误有什么关系!" 在这样一种氛围中,会议的结果可想而知。良好的沟通有助于架构设计工作的开展。一个成员的能力平平的团队,可以藉由良好的沟通,设计出优秀的架构,而一个拥有一个优秀成员的团队,如果缺乏沟通,最后可能连设计都出不来。这种例子现实中可以找到很多。
标准和风格
我们总是在不知不觉之中使用各种各样的标准和风格。在团队设计中,我们为了提高决策的效率,可以考虑使用统一的标准和风格。统一的标准和风格并不是一朝一夕形成的。因为每个人都有自己不同的习惯和经历,强制性的要求开发人员使用统一的标准(风格)容易引起开发人员的不满。因此在操作上需要注意技巧。对架构设计而言,比较重要的标准(风格)包括界面设计、流程设计、建模规范、编码规范、持久层设计、测试数据。
在我的经验中,有一些组织平时并不注意标准(风格)的积累,认为这种积累属于雕虫小技,但正是这些小技,能够非常有效的提高沟通的效率和降低开发人员的学习曲线。试想一下,如果一个团队中所有人写出的代码都是不同标准和风格的,那么理解起来肯定会困难许多。当然,我们没有必要自己开发一套标准(风格)出来,现实中有很多可以直接借用的资料。最好的标准是UML语言,我们可以从UML的官方网站下载到最新的规范,常用的编码标准更是随处可见。不过虽然有了统一的标准,如果风格不统一,同样会造成沟通的障碍。例如下图显示的类图,虽然它们表示的是同一个类,但是由于版型、可视性、详细程度的差别,看起来又很大的差别。而在其它的标准中,这种差别也是普遍存在的。因此,我们在使用了统一的标准之后,还应该使用同样的风格。Scott W. Ambler专门成立了一个网站讨论UML的建模风格的相关问题,有兴趣的读者可以做额外的阅读。
图 4. 两种风格的类图
在统一的风格的基础上更进一步的是使用术语。使用沟通双方都了解专门的术语,可以代表大量的信息。最好的术语的范例就是设计模式的模式名。如果沟通的双方都了解设计模式,那么一方只需要说这部分的设计可以使用工厂模式,另一方就能够理解,而不用再详细的解释设计的思路。这种的沟通方式是最高效的,但它所需要的学习曲线也会比较陡。
团队设计的四明确
为了最大程度的提高团队设计的高效性,可以从4个方面来考虑:
1、明确目标
泛泛的召开架构讨论会议是没有什么意义的,一个没有鲜明主题的会议也不会有什么结果。在源自需求的模式中,我们谈到说可以有非功能需求的架构,可以有功能需求的架构。因此,在进行团队设计之前,我们首先也需要确定,此次要解决什么问题,是讨论业务逻辑的架构,还是技术架构;是全局性的架构,还是各模块的架构。
2、明确分工
我们之所以重视团队,很重要的额一个原因就是不同的成员有不同的擅长的区域。有些成员可能擅长于业务逻辑的建模,有的擅长于原型设计,有的擅长于数据库设计,有的则擅长于Web编程。你能够想象一个软件没有界面吗?(有些软件可能是这种情况)你能够想象一个软件只有数据库,而没有处理逻辑吗?因此,架构设计就需要综合的考虑各个方面,充分利用成员的优势。这就要求团队的各个成员都能够明确自己的分工。
3、明确责权
除了明确自己的分工,每位成员都需要清楚自己的责任。没有责任,分工就不会有任何的效力。每位成员都需要明确自己要做些什么。当然,和责任相对的,没有成员还需要知道自己的权力是什么。这些清楚了,进行高效的沟通的前提就具备了。每次架构的讨论下来,每个人都清楚,自己要做些什么,自己需要要求其他人做些什么,自己该对谁负责。如果这些问题回答不了,那这次的讨论就白费了。
4、明确沟通方式
这里使用沟通方式可能有一点点不恰当,为了明确的表达意思,大家可以考虑信息流这个词。一个完整架构包括几个方面,分别都由那些人负责,如何产生,产生的整个过程应该是什么样的?这样的一个信息流程,囊括了上面提到的三个明确。如果团队的每一个人都能够为架构的产生而努力,并顺利的设计出架构,那么这样的流程是完美的。如果你发现其中的一些人不知道做些什么,那么,这就是流程出问题的现象了。完美的流程还会有一个额外的副产品,架构产生之后,团队对于软件的设计已经是非常的清晰了。因为我们提倡的是尽可能多的开发人员参与架构的设计。
不仅仅是架构 讨论到这里,其实有很多的内容已经脱离了架构设计了。也就是说,很多的原则和技巧都是可以用于软件开发的其它活动的。至于哪一些活动能够利用这些方法呢?大家可以结合自己的实际情况,来思考这个问题。提示一点,关键的入手处在于目前效率较低之处。
架构设计中的方法学(5)——简单设计
XP非常强调简单的设计原则:能够用数组实现的功能决不用链表。在其它Agile方法中,简单的原则也被反复的强调。在这篇文章,我们就对简单性做一个全面的了解。
架构应该设计到 什么程度?
软件的架构都是非常的复杂的,带有大量的文档和图表。开发人员花在理解架构本身上的时间甚至超出了实现架构的时间。在前面的文章中,我们提到了一些反对象牙塔式架构的一个原因,而其中的一个原因就是象牙塔式架构的设计者往往在设计时参杂进过多的自身经验,而不是严格的按照需求来进行设计。
在软件开发领域,最为常见的设计就是"Code and Fix"方式的设计,设计随着软件开���过程而增长。或者,我们可以认为这种方式根本就不能算是设计,它抱着一种船到桥头自然直的态度,可是在设计不断改动之后,代码变得臃肿且难以理解,到处充满着重复的代码。这样的情形下,架构的设计也就无从谈起,软件就像是在风雨中的破屋,濒临倒塌。
针对于这种情形,新的设计方式又出现了,Martin Fowler称这种方式为"Planned Design"。和建筑的设计类似,它强调在编码之前进行严格的设计。这也就是我们在团队设计中谈到的架构设计师的典型做法。设计师们通常不会去编程,理由是在土木工程中,你不可能看到一位设计师还要砌砖头。
"Planned Design"较之"Code and Fix"进步了许多,但是还是会存在很多问题。除了在团队设计中我们谈的问题之外,需求变更将会导致更大的麻烦。因此,我们理所当然的想到进行"弹性设计":弹性的设计能够满足需求的变更。而弹性的设计所付出的代价就是复杂的设计。
题外话:
这里我们谈论"Planned Design"引出的一些问题,并没有任何排斥这种方式的意思。"Planned Design"还是有很多可取之处的,但也有很多需要改进的地方。事实上,本文中我们讨论的架构设计方式,本质上也是属于"Planned Design"方式。和"Planned Design"相对应的方式是XP所主张的"Evolutionary Design"方式,但是这种方式还有待于实践的检验,并不能简单的说他就一定要比"Planned Design"先进或落后。但可以肯定的一点是:"Evolutionary Design"方式中有很多的思想和技巧是值得"Planned Design"借鉴的。
解决方法:
XP中有两个非常响亮的口号:"Do The Simplest Thing that Could Possibly Work"和"You Aren't Going to Need It"(通常称之为YAGNI)。他们的核心思想就是不要为了考虑将来,把目前并不需要的功能加到软件中来。
粗看之下,会有很多开发人员认为这是不切实际的口号。我能理解这种想法,其实,在我热衷于模式、可重用组件技术的时候,我对XP提倡的简单的口号嗤之以鼻。但在实际中,我的一些软件因为复杂设计导致开发成本上升的时候,我重新思考这个问题,发现简单的设计是有道理的。
降低开发的成本
不论是模式,可重用组件,或是框架技术,目的都是为了降低开发的成本。但是他们的方式是先进行大量的投入,然后再节省后续的开发成本。因此,架构设计方面的很多思路都是围绕着这种想法展开的,这可能也是导致开发人员普遍认为架构设计高不可攀的原因。XP的方式恰恰相反,在处理第一个问题的时候,不必要也不可能就设计出具有弹性、近乎完美的架构来。这项工作应该是随着开发的演进,慢慢成熟起来的。我不敢说这种方式肯定正确,但是如果我们把生物的结构视同为架构,这种方式不是很类似于自然界中生物的进化方式吗?
在一开始就制作出完美的架构的设想并没有错,关键是很难做到这一点。总是会有很多的问题是你在做设计时没有考虑到的。这样,当一开始花费大量精力设计出的"完美无缺"的架构必然会遇到意想不到的问题,这时候,复杂的架构反而会影响到设计的改进,导致开发成本的上升。这就好比如果方向错了,交通工具再快,反而导致错误的快速扩大。Martin Fowler在他的论文中说,"Working on the wrong solution early is even more wasteful than working on the right solution early"(提前做一件错事要比提前做一件对的事更浪费时间),相信也是这个道理。
更有意思的是,通常我们更有可能做错。在我们进行架构设计的时候,我们不可能完全取得详细的需求。事实上,就算你已经取得了完整的需求,也有可能发生变化。这种情况下做出的架构设计是不可能不出错的。这样,浪费大量的时间在初始阶段设计不可能达到的"完美架构",倒不如把时间花在后续的改进上。
提升沟通的效率
我们在团队设计中已经谈过了团队设计的目标之一就是为了降低沟通的成本,以期让所有人都能够理解架构。但是如果架构如果过于复杂,将会重新导致沟通成本的上升,而且,这个成本并不会随着项目进行而降低,反而会因为上面我们提到的遇到新的问题导致沟通成本的持续上升。
简单的架构设计可以加快开发团队理解架构的速度。我们可以通过两种方式来理解简单的含义。首先,简单意味着问题的解不会非常的复杂,架构是解决需求的关键,无论需求再怎么复杂多变,总是可以找出简单稳定的部分,我们可以把这个简单稳定的部分做为基础,再根据需要进行改进扩展,以解决复杂的问题。在示例中,我们提到了measurement pattern,它就是按照这种想法来进行设计的。
其次,简单性还体现在表示的简单上。一份5页的文档就能够表达清楚的架构设计为什么要花费50页呢?同样的道理,能够用一副简单的图形就能够表示的架构设计也没有必要使用文档。毕竟,面对面的沟通才是最有效率的沟通,文档不论如何的复杂,都不能被完全理解,而且,复杂的文档,维护起来也需要花费大量的时间。只有在两种情况下,我们提倡使用复杂的文档:一是开发团队没有办法做到面对面沟通;二是开发成果要作为团队的知识积累起来,为下一次开发所用。
考虑未来
我们之所以考虑未来,主要的原因就是需求的不稳定。因此,我们如果考虑未来可能发生的需求变化,就会不知觉的在架构设计中增加复杂的成分。这违背的简单的精神。但是,如果你
不考虑可能出现的情况,那些和目前设计格格不入的改变,将会导致大量的返工。
还记得YAGNI吗?原则上,我们仍然坚持不要在现有的系统中为将来可能的情况进行设计。但是,我们必须思考,必须要为将来可能出现的情况做一些准备。其实,软件中了不起的接口的思想,不就是源于此吗?因此,思考未来,但等到需要时再实现。
变更案例有助于我们思考未来,变更案例就是你在将来可能要(或可能不要)满足的,但现在不需要满足的需求。当我们在做架构设计的时候,变更案例也将会成为设计的考虑因素之一,但它不可能成为进行决策的唯一考虑因素。很多的时候,我们沉迷于设计通用系统给我们带来的挑战之中,其实,我们所做的工作对用户而言是毫无意义的。
架构的稳定
架构简单化和架构的稳定性有什么关系吗?我们说,架构越简单,其稳定性就越好。理由很简单,1个拥有4个方法和3个属性的类,和1个拥有20个方法和30属性的类相比,哪一个更稳定?当然是前者。而架构最终都是要映射到代码级别上的,因此架构的简单将会带来架构的稳定。尽可能的让你的类小一些,尽可能的让你的方法短一些,尽可能的让类之间的关系少一些。这并不是我的忠告,很多的设计类的文章都是这么说的。在这个话题上,我们可以进一步的阅读同类的文章(关于 refactoring 的思考)。
辨正的简单
因此,对我们来说,简单的意义就是不要把未来的、或不需要实现的功能加入到目前的软件中,相应的架构设计也不需要考虑这些额外的需求,只要刚好能够满足当前的需求就好了。这就是简单的定义。可是在现实之中,总是有这样或者那样的原因,使得设计趋向复杂。一般来说,如果一个设计对团队而言是有价值的,那么,付出一定的成本来研究、验证、发展、文档化这个设计是有意义的。反之,如果一个设计没有很大的价值或是发展它的成本超过了其能够提供的价值,那就不需要去考虑这个设计。
价值对不同的团队来说具有不同的含义。有时候可能是时间,有时候可能是用户价值,有时候可能是为了团队的设计积累和代码重用,有时候是为了获得经验,有时候是为了研究出可重用的框架(FrameWork)。这些也可以称为目的,因此,你在设计架构时,请注意先确定好你的目的,对实现目的有帮助的事情才考虑。
Scott W.Ambler在他的文章中提到一个他亲身经历的故事,在软件开发的架构设计过程中,花了很多的时间来设计数据库到业务逻辑的映射架构,虽然这是一件任何开发人员都乐意专研的事情(因为它很酷)。但他不得不承认,对用户来说,这种设计先进的架构是没有太大的意义的,因为用户并不关心具体的技术。当看到这个故事的时候,我的触动很大。一个开发人员总是热衷于新奇的技术,但是如果这个新奇技术的成本由用户来承担,是不是合理呢?虽然新技术的采用能够为用户带来效益,但是没有人计算过效益背后的成本。就我开发过的项目而言,这个成本往往是大于效益的。这个问题可能并没有确定的答案,只能是见仁见智了。
简单并不等于实现简单
说到这里,如果大家有一个误解,认为一个简单的架构也一定是容易设计的,那就错了。简单的架构并不等于实现起来也简单。简单的架构需要设计者花费大量的心血,也要求设计者对技术有很深的造诣。在我们正在进行的一个项目中,一开始设计的基础架构在实现中被修改了几次,但每修改一次,代码量都减少一分,代码的可读性也就增强一分。从心理的角度上来说,对自己的架构进行不断的修改,确实是需要一定的勇气的。因为不论是设计还是代码,都是开发人员的心血。但跨出这一步是值得的。
下面的例子讨论了Java的IO设计,Java类库的设计应该来说是非常优秀的,但是仍然避免不了重新的修改。实际上,在软件开发领域,由于原先的设计失误而导致后来设计过于复杂的情况比比皆是(例如微软的OLE)。同样的,我们在设计软件的时候,也需要对设计进行不断的修改。能够实现复杂功能,同时自身又简单的设计并不是一件容易的事情。
例1. Java的IO系统
从Java的IO系统设计中,我们可以感受到简单设计的困难。
例2. IO系统设计的困难性向来是公认的。Java的IO设计的一个目的就是使IO的使用简单化。在Java的1.0中,Java的IO系统主要是把IO系统分为输入输出两个大部分,并分别定义了抽象类InputStream和OutputStream。从这两个的抽象类出发,实现了一系列不同功能的输入输出类,同时,Java的IO系统还在输入输出中实现了FilterInputStream和FilterOutputStream的抽象类以及相关的一系列实现,从而把不同的功能的输入输出函数连接在一起,实现复杂的功能。这个实现其实是Decorator模式(由于没有看过源码和相关的资料,这里仅仅是根据功能和使用技巧推测,如果大家有不同的意见,欢迎来信讨论)。
因此,我们可以把多个对象叠加在一起,提供复杂的功能:
DataInpuStream in =
new DataInputStream(
new BufferedInputStream(
new FileInputStream("test.txt");
上面的代码使用了两个FilterInputStream:DataInpuStream和BufferedInputStream,以实现读数据和缓冲的功能,同时使用了一个InputStream:FileInputStream,从文件中读取流数据。虽然使用起来不是很方便,但是应该还是非常清晰的设计。
令设计混乱的是既不属于InputStream,也不属于OutputStream的类,例如RandomAccessFile,这正表明,由于功能的复杂化,使得原先基于输入输出分类的设计变得混乱,根据我们的经验,我们说设计需要Refactoring了。因此,在Java1.1中,IO系统被重新设计,采用了Reader和Writer位基础的设计,并增加了新的特性。但是目前的设计似乎更加混乱了,因为我们需要同时使用1.0和1.1两种不同的IO设计
架构设计中的方法学(6)——迭代设计
迭代是一种软件开发的生命周期模型,在设计中应用迭代设计,我们可以得到很多的好处。
在软件生命周期中,我们如何对待架构设计的发展?
架构设计往往发生在细节需求尚未完成的时候进行的。因此,随着项目的进行,需求还可能细化,可能变更。原先的架构肯定会有不足或错误的地方。那么,我们应该如何对待原先的设计呢?
我们在简单设计模式中简单提到了"Planned Design"和"Evolutionary Design"的区别。XP社团的人们推崇使用"Evolutionary Design"的方式,在外人看来,似乎拥护者们从来不需要架构的设计,他们采用的方式是一开始就进入代码的编写,然后用Refactoring来改进代码的质量,解决未经设计导致的代码质量低下的功能。
从一定程度上来说,这个观点并没有错,它强调了代码对软件的重要性,并通过一些技巧(如Refactoring)来解决缺乏设计的问题。但我并不认同"Evolutionary Design"的方式,在我看来,一定程度上的"Planned Design"是必须的,至少在中国的软件行业中,"Planned Design"还没有成为主要的设计方向。借用一句明言,"凡事预则立,不预则废",在软件设计初期,投入精力进行架构的设计是很有必要的,这个架构是你在后续的设计、编码过程中依赖的基础。但是,一开始我们提到的设计改进的问题依然存在,我们如何解决它呢?
在简单设计模式中,我们提到了设计改进的必要性,但是,如果没有一种方法去控制设计的改进的话,那么设计改进本身就是一场噩梦。因此,何时改进,怎么改进,如何控制,这都是我们需要面对的问题。
解决方法
为了实现不断的改进,我们将在开发流程中引入迭代的概念。迭代的概念在《需求的实践》中已经提到,这里我们假设读者已经有了基本的迭代的概念。
软件编码之前的工作大致可以分为这样一个工作流程:
上图中的流程隐含着一个信息的损失的过程。来自于用户的需求经过整理之后,开发人员就会从中去掉一些信息,同样的事情发生在后面的过程中,信息丢失或变形的情况不断的发生。这里发生了什么问题?应该说,需求信息的失真是非常普遍的,我们缺少的是一种有效的办法来抑止失真,换句话说,就是缺少反馈。
如果把眼睛蒙上,那我们肯定没有办法走出一条很长的直线。我们走路的时候都是针对目标不断的调整自己的方向的。同样的,漫长的软件开发过程如果没有一种反馈机制来调整方向,那最后的软件真是难以想象。
所以我们引入了迭代周期。
初始设计和迭代设计
在团队设计中,我们一直在强调,设计组最开始得到的设计一定只是一个原始架构,然后把这个原始架构传播到每一位开发者的手中,从而在开发团队中形成共同的愿景。(愿景(Vision):源自于管理学,表示未来的愿望和景象。这里借用来表示软件在开发人员心中的样子。在后面的文章中我们会有一个章节专门的讨论架构愿景。)
迭代(Iterate)设计,或者我们称之为增量(Incremental)设计的思想和XP提倡的Evolutionary Design有异曲同工之妙。我们可以从XP、Crystal、RUP、ClearRoom等方法学中对比、体会迭代设计的精妙之处:每一次的迭代都是在上一次迭代的基础上进行的,迭代将致力于重用、修改、增强目前的架构,以使架构越来越强壮。在软件生命周期的最后,我们除了得到软件,还得到了一个非常稳定的架构。对于一个软件组织来说,这个架构很有可能就是下一个软件的投入或参考。
我们可以把早期的原始架构当作第一次迭代前的早期投入,也可以把它做为第一次迭代的重点,这些都是无所谓的。关键在于,原始架构对于后续的架构设计而言是非常重要的,我们讨论过架构是来源于需求的,但是原始架构应该来源于那些比较稳定的需求。
TIP:现实中迭代设计退化为"Code and Fix"的设计的情况屡见不鲜("Code and Fix"参见简单设计)。从表面上看,两者的做法并没有太大的差别,都是针对原有的设计进行改进。但是,二者效果的差别是明显的:"Code and Fix"是混沌的,毫无方向感可言,每一次的改进只是给原先就已摇摇欲坠的积木上再加一块积木而已。而迭代设计的每一次改进都朝着一个稳定的目标在前进,他给开发人员带来信心,而不是打击。在过程上,我们说迭代设计是在控制之下的。从实践的经验中,我们发现,把原该在目前就该解决的问题退后是造成这一问题的主要原因之一。因此,请严格的对待每一次的迭代,确保计划已经完成、确保软件的质量、确保用户的需求得到满足,这样才是正统的迭代之路。
单次的迭代
我们说,每一次的迭代其实是一个完整的小过程。也就是说,它同样要经历文章中讨论的这些过程模式。只不过,这些模式的工作量都不大,你甚至可以在很短的时间内做完所有的事情。因此,我们好像又回到了文章的开头,重新讨论架构设计的过程。
单次迭代最令我们兴奋的就是我们总是可以得到一个在当前迭代中相当稳定的结果,而不像普通的架构设计那样,我们深怕架构会出现问题,但又不得不依赖这个架构。从心理上来分析,我们是在持续的建设架构中,不需要回避需求的变更,因为我们相信,在需求相对应的迭代中,会继续对架构进行改进。大家不要认为这种心理的改变是无关紧要的,我起初并没有意识到这个问题,但是我很快发现新的架构设计过程仍然笼罩在原先的惧怕改变的阴影之下的时候,迭代设计很容易就退化为"Code and Fix"的情形。开发人员难以接受新方法的主要原因还是在心理上。因此,我不得不花了很多的时间来和开发人员进行沟通,这就是我现实的经验。
迭代的交错
基于我们对运筹学的一点经验,迭代设计之间肯定不是线性的关系。这样说的一个原因架构设计和后续的工作间还是时间差的。因此,我们不会傻到把时间浪费在等待其它工作上。一般而言,当下一次迭代的需求开始之后,详细需求开始之前,我们就已经可以开始下一次迭代的架构设计了。
各次迭代之间的时间距离要视项目的具体情况而定。比如,人员比较紧张的项目中,主要的架构设计人员可能也要担任编码人员的角色,下一次迭代的架构设计就可能要等到编码工作的高峰期过了之后。可是,多次的交错迭代就可能产生版本的问题。比如,本次的迭代的编码中发现了架构的一个问题,反馈给架构设计组,但是架构设计组已经根据伪修改的本次迭代的架构开始了下一次迭代的架构设计,这时候就会出现不同的设计之间的冲突问题。这种情况当然可以通过加强对设计模型的管理和引入版本控制机制来解决,但肯定会随之带来管理成本上升的问题,而这是不符合敏捷的思想的。这时候,团队设计就体现了他的威力了,这也是我们在团队设计中没有提到的一个原因。团队设计通过完全的沟通,可以解决架构设计中存在冲突的问题。
迭代频率
XP提倡迭代周期越短越好(XP建议为一到两周),这是个不错的提议。在这么短的一个迭代周期内,我们花在架构设计上的时间可能就只有一两个小时到半天的时间。这时候,会有一个很有意思的现象,你很难去区分架构设计和设计的概念了。因为在这么短的一个周期之内,完成的需求数量是很少的,可能就只有一两个用例或用户素材。因此,这几项需求的设计是不是属于架构设计呢?如果是的话,由于开发过程是由多次的迭代组成的,那么开发过程中的设计不都属于架构设计了吗?我们说,架构是一个相对的概念,是针对范围而言的,在传统的瀑布模型中,我们可以很容易的区分出架构设计和普通设计,如果我们把一次迭代看作是一个单独的生命周期,那么,普通的设计在这样一个范围之内也就是架构设计,他们并没有什么两样。但是,迭代周期中的架构设计是要遵循一定的原则的,这我们在下面还会提到。
我们希望迭代频率越快越好,但是这还要根据现实的情况而定。比如数据仓库项目,在项目的初期阶段,我们不得不花费大量的时间来进行数据建模的工作,这其实也是一项专门针对数据的架构设计,建立元数据,制定维,整理数据,这样子的过程很难分为多次的迭代周期来实现。
如何确定软件的迭代周期
可以说,如果一支开发团队没有相关迭代的概念,那么这支团队要立刻实现时隔两周迭代周期是非常困难的,,同时也是毫无意义的。就像我们在上面讨论的,影响迭代周期的因素很多,以至于我们那无法对迭代周期进行量化的定义。因此我们只能从定性的角度分析迭代周期的发展。
另一个了解迭代的方法是阅读XP的相关资料,我认为XP中关于迭代周期的使用是很不错的一种方法,只是他强调的如此短的迭代周期对于很多的软件团队而言都是难以实现的。
迭代周期的引入一定是一个从粗糙到精确的过程。迭代的本质其实是短周期的计划,因此这也是迭代周期越短对我们越有好处的一大原因,因为时间缩短了,计划的可预测性就增强了。我们知道,计划的制定是依赖于已往的经验,如果原先我们没有制定计划或细节计划的经验,那么我们的计划就一定是非常粗糙,最后的误差也一定很大。但是这没有关系,每一次的计划都会对下一次的计划产生正面的影响,等到经验足够的时候,计划将会非常的精确,最后的误差也会很小。
迭代周期的确定需要依赖于单位工作量。单位工作量指的是一定时间内你可以量化的最小的绩效。最简单的单位工作量是每位程序员一天的编码行数。可惜显示往往比较残酷,团队中不但有程序员的角色,还有设计师、测试人员、文档制作人员等角色的存在,单纯的编码行数是不能够作为唯一的统计依据的。同样,只强调编码行数,也会导致其它的问题,例如代码质量。为了保证统计的合理性,比较好的做法是一个团队实现某个功能所花费的天数作为单位工作量。这里讨论的内容实际是软件测量技术,如果有机会的话,再和大家探讨这个问题。
迭代周期和软件架构的改进
我们应用迭代方法的最大的目的就是为了稳步的改进软件架构。因此,我们需要了解架构是如何在软件开发的过程中不断演进的。在后面的文章中,我们会谈到用Refactoring的方法来改进软件架构,但是Refactoring的定义中强调,Refactoring必须在不修改代码的外部功能的情况下进行。对于架构来说,我们可以近乎等价的认为就是在外部接口不变的情况下对架构进行改进。而在实际的开发中,除非非常有经验,否则在软件开发全过程中保持所有的软件接口不变是一件非常困难的事情。因此,我们这里谈的架构的改进虽然和Refactoring有类似之处,但还是有区别的。
软件架构的改进在软件开发过程会经历一个振荡期,这个振荡期可能横跨了数个迭代周期,其间架构的设计将会经历剧烈的变化,但最后一定会取向于平稳。(如果项目后期没有出现设计平稳化的情况,那么很不幸,你的项目注定要失败了,要么是时间的问题,要么就是需求的问题)。关键的问题在于,我们有没有勇气,在架构需要改变的时候就毅然做出变化,而不是眼睁睁的看着问题变得越来越严重。最后的例子中,我们讨论三个迭代周期,假设我们在第二个周期的时候拒绝对架构进行改变,那么第三个周期一定是有如噩梦一般。变化,才有可能成功。
我们知道变化的重要性,但没有办法知道变化的确切时间。不过我们可以从开发过程中嗅到架构需要变化的气味:当程序中重复的代码逐渐变多的时候,当某些类变得格外的臃肿的时候,当编码人员的编码速度开始下降的时候,当需求出现大量的变动的时候。
实例
从这一周开始,我和我的小组将要负责对软件项目中的表示层的设计。在这个迭代周期中,我们的任务是要为客户端提供6到10个的视图。由于视图并不很多,表示层的架构设计非常的简单:
准确的说,这里谈不上设计,只是简单让客户端访问不同的视图而已。当然,在设计的示意图中,我们并没有必要画出所有的视图来,只要能够表达客户端和视图的关联性就可以了。
(架构设计需要和具体的实现绑定,但是在这个例子中,为了着重体现设计的演进,因此把不必要的信息都删掉。在实际的设计中,视图可能是JSP页面,也可能是一个窗口。)
第一个迭代周的任务很快的完成了,小组负责的表示层模块也很顺利的和其它小组完成了对接,一个简陋但能够运转的小系统顺利的发布。客户观看了这个系统的演示,对系统提出了修改和补充。
第二���迭代周中,模块要处理的视图增加到了30个,视图之间存在相同的部分,并且,负责数据层的小组对我们说,由于客户需求的改进,同一个视图中将会出现不同的数据源。由于我们的视图中直接使用了数据层小组提供给我们的数据源的函数,这意味着我们的设计需要进行较大的调整。
考虑到系统的视图的量大大的增加,我们有必要对视图进行集中的管理。前端控制器(Front Control)模式将会是一个不错的技巧。对于视图之间的普遍的重复部分,可以将视图划分为不同的子视图,再把子视图组合为各种各样的视图。这样我们就可以使用组合(Composite)模式:
客户的请求集中提交给控制器,控制器接受到客户的请求之后,根据一定的规则,来提供不同的视图来反馈给客户。控制器是一个具有扩展能力的设计,目前的视图数量并不多,因此仍然可以使用控制器来直接分配视图。如果视图的处理规则比较复杂,我们还可以使用创建工厂(Create Factory)模式来专门处理生成视图的问题。对于视图来说,使用组合模式,把多个不同数据源的视图组合为复杂的视图。例如,一个JSP的页面中,可能需要分为头页面和尾页面。
项目进入第三个迭代周期之后,表示层的需求进一步复杂化。我们需要处理权限信息、需要处理数据的合法性判断、还需要面对更多的视图带来的复杂程度上升的问题。
表示层的权限处理比较简单,我们可以从前端控制器中增加权限控制的模块。同时,为了解决合法性判断问题,我们又增加了一个数据过滤链模块,来完成数据的合法性判断和转换的工作。为了不使得控制器部分的功能过于复杂,我们把原先属于控制器的视图分发功能转移到新的分发器模块,而控制器专门负责用户请求、视图的控制。
我们来回顾这个例子,从迭代周期1中的需求最为简单,其实,现实中的项目刚开始的需求虽然未必会像例子中的那么简单,但一定不会过于复杂,因此迭代周期1的设计也非常的简单。到了迭代周期2的时候,需求开始变得复杂,按照原先的架构继续设计的话,必然会导致很多的问题,因此对架构进行改进是必要的。我们看到,新的设计能够满足新的需求。同样的,迭代周期3的需求更加的复杂,因此设计也随之演进。这就是我们在文章的开始提到的"Evolutionary Design"的演进的思想。
架构设计中的方法学(7)——组合使用模式
我们已经讨论了敏捷架构设计的4种过程模式,在本文中,我们对这四种过程模式做一个小结,并讨论4者间的关系以及体现在模式中的敏捷方法论特色。通过这一章的描述,大家能够对前面的内容有更进一步的了解。
四种模式的着重点 我把源自需求、团队设计、简单设计、迭代设计这4种过程模式归类为架构设计的第一层次,这4种模式能够确定架构设计过程的框架。这里需要对框架的含义进行澄清:架构设计的框架并不是说你要严格的按照文中介绍的内容来进行架构设计,在文章的一开始我们就指出,模式能够激发思考。因此,这一框架是需要结合实际,进行改造的。实际,我们在这一个部分中介绍的,比较偏向于原则,我们花了很大的时间来讨论原则的来龙去脉,而原则的度,则要大家自己去把握。为什么我们不讨论原则的度呢?这里有两个原因,一个是软件开发团队各有特色,很难定义出一个通用的度。第二个原因是我的水平不够,实践经验也不够丰富。 前面提到的四种模式其实是从四个侧面讨论了架构设计中的方法问题。源自需求提供了架构设计的基础。在软件过程中,架构设计是承接于需求分析的,如果没有良好的需求分析活动的支持,再好的架构设计也没有用。因此我们把这一模式放在首位,做为架构设计的目标。 有了确定的目标,还需有组织的保证,这也就是第二种模式――团队设计的由来。敏捷方法提倡优秀的沟通,因此团队设计是必要且有效的。而团队设计的另一个意图,是保证架构设计的下游活动得以顺利的进行,例如详细设计、编码、测试等。由于开发团队中的人大都加入了架构设计,因此最大程度的减小了不同的活动间的信息损耗和沟通效率低下的问题。如果说源自需求模式是起承上的作用,那么团队设计模式则是扮演了启下的角色。 在软件设计的过程中,沟通往往扮演着非常重要的角色。从团队设计开始的几种模式所要解决的都是沟通的问题。团队设计对沟通的贡献在于它能够把设计意图以最小的代价传播到开发团队的每个角落。这样,设计和下游的活动间由于沟通不畅产生的问题就能够得到缓解。一般而言,设计到编码会经历一个信息损失的过程,编码人员无法正确理解设计人员的意图,设计人员却往往无法考虑到一些编码的细节。虽然我们可以通过共通的设计符号来提高沟通的质量,例如UML。但是实践证明,只要能够保证畅通的沟通,即便没有优秀的开发方法,项目成功的概率依然很高。因此对于单个的项目来说,最关键的问题还是在于沟通。只要组织得当,团队设计是一个值得应用的模式。当然,配合以UML为代表的建模语言,更能够提高沟通的效果。
在设计中,我们发现,当设计信息转换为编码信息需要一定的时间,这个时间包括设计的组织时间,设计被理解的时间。如果设计比较复杂,或者说设计的文档比较复杂,编码人员花在理解上的时间就会大大增加。因此,权衡后的结果是,相对于详细的设计说明书而言,简单的设计说明书再配合一定程度的面对面沟通能够起到更好的效果。"简单要比复杂有效",这就是简单设计模式的基本思路。
同样,简单的思路还会用在软件开发的各个方面,例如文档、设计、流程。坚持简单的原则,并不断的加以改进,是降低软件开发成本的一种很有效的做法。
在有了以上的思路之后,我们还需要面对两个现实的问题。需求的变化将会导致设计的不稳定,而需求的复杂性又会导致简单架构设计的困难。为了解决这个问题,我们引入了迭代的方法,将问题分割为多个子问题(把一个复杂的问题分解为多个较简单的子问题是计算机领域最常见的处理方法)。这样,问题的范围和难度都大大降低了。而更关键的是,由于对用户需求理解不充分或用户表达需求有错导致的设计风险被降到最低点。迭代和前面几个模式都有关系。
需求和迭代
源自需求模式是架构设计中的起手式,没有这一模式的支持,架构设计只能是空中楼阁。其实,源自需求模式严格意义上并不能算是敏捷方法论的特色,而应该算是软件开发的天然特性。不幸的是,就是这么一个基本的原则,却没能够引起开发者足够的重视。
敏捷方法论中把需求摆在一个非常重要的位置,我们把源自需求模式作为架构设计的第一个模式,主要的目的是承接架构设计的上游工作――需求。需求决定架构,因此,我们在经典的瀑布模型中可以看到需求到设计的严格的分界线,但是在实际的开发中,按照瀑布模型的理论往往会遇到很多的问题,所以,我们尝试着把需求和(架构)设计之间的界限打破,形成一个重叠的地带,从而提高软件开发的速度。因此,我们在源自需求模型中指出,架构设计是紧随着需求开始的。
需求对软件开发最具影响就是需求的不稳定性。我们都非常的清楚软件开发的曲线,越到软件开发的后期,修改软件的成本越高。因此,在软件开发上游的需求的变动将会对软件开发的下游产生天翻地覆的影响。为了协调这一矛盾,软工理论提出了螺旋开发模型,这就是我们在迭代开发模式中的讨论的理论基础。把软件开发过程分为多个的迭代周期,每一次的迭代周期最后都将生成一个可交付的软件,用户在每一次的迭代结束后,可以试用软件,提出下一步的需求或是改变原先的需求。通过这样的方式,把客户、开发商的风险降到一个可以接受的水平上。
请注意迭代的前提:需求的易变性。因此,对于那些需求容易发生变化的项目,我们就可以使用迭代式的开发过程,虽然我们会付出一些额外的成本(刚开始这个成本会比较大,但可以用较长的迭代周期来降低这种成本),但是风险减小了。而对于需求比较固定的项目,
是不是有必要使用迭代的方法,就要看具体的环境了。因此,我们是根据实际的情况选用开发方法,而不是因为先进或是流行的原因。
实际上,由于现代社会的特性,大部分的项目都是可以采用迭代方法。因此,我们的选择就变成了了迭代周期应该要多长。迭代周期在理论上应该是越短越好,但是并没有一个绝对的数值,时间的跨度一般从几周到几个月。一般来说,迭代周期会受到几个因素的影响:
各模块的关联程度。在软件开发中,我们有时候很难把一些模块分离开来,要开发模块A,就需要模块B,而模块B又需要模块C。各模块的关联程度越高,迭代周期越长。当然,也相应的解决方法,我们可以在各模块的功能中选取出一些关键点,作为里程碑,以里程碑作为迭代完成点。
人员技能、经验的平均程度。团队中成员的开发能力、开发经验良莠不齐,这也是造成迭代周期延长的一个原因。能力低、经验少的开发人员会拖后每一次迭代的时间。针对这种情况,做好统筹规划就显得非常的重要,可以通过一两次的迭代,找出队伍中的瓶颈人员,安排相应的对策。
工具的缺乏。迭代周期越短,就意味着build、发布的次数越多,客户也就有更多的机会来修改需求。这要求有相关的工具来帮助开发人员控制软件。最重要的工具是回归测试工具。每一次迭代都需要增加新的功能,或是对原先的功能进行改动,这就有可能引入新的bug,如果没有回归测试,开发人员就需要花费时间重新测试原先的功能。
计划、控制的能力。迭代周期越短,所需要的计划、控制的能力就越强。因为短时间内的计划制定和实施需要高度的细分,这就要求开发团队的管理者对开发能力、工作量、任务分配有很强的认识,才能做好这项工作。不过,迭代周期越短,同样开发时间的迭代次数就越多,而团队调整、改进计划控制的机会就越多。因此,后期的迭代一般都能够做到比较精确的控制。而这样的做法,要比问题堆积到软件交付日才爆发出来要好的多。没有突然落后的软件,只有每天都在落后的软件。
简单和迭代
简单和迭代关系是双向的。
在现实设计我们很难界定出简单设计的程度。怎样的架构设计才算是简单?按照我们在简单设计模式中的讨论,刚好满足目前的需求的架构设计就算是简单的设计。但是,从另外一个方面考虑,需求的易变性限制我们做出简单的设计,因为我们不能够肯定目前的需求将来会发生什么样的变化。因此,为了克服对未知的恐惧,我们花了很大的力气设计一些灵活的、能够适应变化的架构。这是源自需求模式对简单设计模式的影响。
源自需求和迭代设计的关系的讨论建议我们把需求分为多个迭代周期来实现。那么,相应的架构设计也被分在多个迭代周期中。这样的方法可以降低架构设计的复杂程度。因为设计人员不需要考虑软件的全部需求,而只需要考虑当前迭代周期的需求。复杂性的降低将会有助于架构设计的简单化,从而达到简单设计的一系列的好处(参见简单设计)。
我们从迭代设计中的最后一个例子可以清楚的看到迭代设计是如何把复杂的需求给简单化的。把握迭代设计有助于我们避免过分设计的毛病。这是个技术人员经常犯的毛病。我所在的团队很多时候也无法避免。例如,在很多的项目中,我们都会花费大量的时间来设计数据库到业务实体的映射。诸如此类的技术问题对开发人员的吸引程度是不言而喻的,但是必须看到,这种的设计会导致开发成本的大幅度上升。更为糟糕的是,除非有丰富的经验,这种类型的设计给开发工作带来的价值往往无法超过其成本。
因此,我们需要学会权衡利弊,是否有必要投入大量的资源来开发其实并没有那么有用的功能。因此,迭代设计和简单设计的结合有助于我们摆脱过度设计的困扰,把精力集中在真正重要的功能之上。
此外,简单的设计并不等同于较少的付出。简单的设计往往需要对现实世界的抽象,回忆我们在简单设计中讨论的测量模式的例子,它看似简单,但实现起来却需要大量的业务知识、很强的设计能力。因此,做到简单是程序员不断追寻的目标之一。
在很多的方法论中,一般并不过分注意代码重复的问题,要么是不关注,要么认为适当的代码重复是允许的。而XP却把代码重复视为良好代码的大敌。"只要存在重复代码,就说明代码仍有Refactoring的可能。"这种观点看起来非常的绝对,这可能也正是其名字中Extreme的来历(英文中的Extreme属于语气非常重的一个单词)。从实践的角度上来看,追求不重复的代码虽然很难做到,但是其过程却可以有效的提高开发团队代码的写作质量,因为它逼迫着你在每次迭代重对代码进行改进,不能有丝毫的怠惰。而这种迭代的特性,促进了简单的实现。
团队和简单
我们在简单设计中提过简单设计需要全面的设计师。除此之外,它还需要团队的配合。简单意味着不同活动间交付工件的简单化。也就是说,类似于需求说明书、设计文档之类的东西都将会比较简单。正因为如此,我们很难想象一个地理上分布在不同地点的开发团队或一个超过50人的大团队能够利用这种简单的文档完成开发任务。
因此,简单的设计是需要团队的组织结构来保证的。简单的设计要求团队的相互沟通能够快速的进行。架构设计完成后,架构的设计思路传达给所有的编码人员的速度要块,同样,编码中发现问题,回馈给设计者,设计者经过改进之后再传达给收到影响的编码人员的速度也要快。象这样高效率的传播我们可以称之为"Hot Channel"。
为了保证"Hot Channel"的高沟通效率,最好的组织单位是开发人员在3到6人之间,并处于同间工作室中。这样的结构可以保证讯息的交互速度达到最高,不需要付出额外的沟通成本,也不需要过于复杂的版本控制工具或权限分配。根据我的经验,一个共享式的小型版本控制工具、网络共享、再加上一个简单的网络数据库就能够解决大部分的问题了。
在理论上,我们说只要分配得当,大型的团队同样可以组织为金字塔式的子团队,以提高大型团队的工作效率。但是实际中,随着团队的人数的增加,任务的正确分配的���度也随之加大,沟通信息上传下达的效率开始下降,子团队间的隔阂开始出现,各种因素的累加导致敏捷方法并不一定适合于大型的团队,因此我们讨论的敏捷方法都将受到团队的特性的限制。
模式的源头
如果你对XP有一定的了解的话,那么你可能会感觉到我们讨论的模式中应用了XP的实践。确实如此,XP中有很多优秀的实践,如果组织得当的话,这些微小的实践将会组合成为一套了不起的开发方法。不过,目前的软件开发混乱的现状阻止了先进的软件方法的应用,对一个身体虚弱的病人施以补药只会适得其反。因此,在前面讨论的模式中,我们应用了一些容易应用、效果明显的实践方法。在实践中适当的应用这些方法,并不需要额外的投入,却能够有很好的效果,同时还会为你的团队打下一个良好的基础
架构设计中的方法学(8)——架构愿景(2)
我们从源自需求模式中,学习到架构的设计是来自于需求的,而应用于软件全局的架构则来自于最重要的需求。还记得我们在那个模式中提到的网上宠物店的例子吗?系统采用了MVC模式,sun的官方文档一开始说明了为什么采用MVC模式,MVC模式解决了什么
问题,然后开始分析MVC模式的几个组成部分:Model、View、和Controll。其实,MVC中的每一个部分,在真正的代码中,大都代表了一个子系统,但是在目前,我们就非常的清楚系统大致上会是一个什么样子,虽然这时候它还十分的朦胧。
不要视图在全局的架构愿景中就制定出非常细致的规划,更不要视图生成大量的实际代码。因为,你的架构愿景还没有稳定(我们在其后的稳定化的模式中将会讨论稳定的问题),还没有获得大家的同意,也没有经过证明。因此,从整个的开发周期来看,全局架构愿景是随着迭代周期的进行不断发展、修改、完善的。
我们如何确定全局架构愿景工作的完成?一般来说,你的架构设计团队取得了一致的意见就可以结束了,如果问题域是团队所熟悉的,一两个小时就能够解决问题。接下来设计团队把架构愿景传播到整个的开发团队,大家形成一致的认识,不同的意见将会被反馈会来,并在本次的迭代周期(如果时间比较紧迫)或下一次的迭代周期中(如果时间比较宽松)考虑。
子模块级、或是子问题级的架构愿景
这时候的架构愿景已经是比较明确的了,因为已经存在明确的问题域。例如界面的设计、领域模型的设计、持久层的设计等。这里的愿景制定本质上和全局的愿景制定差不多,具体的例子我们也不再举了。但是要注意一点,你不能够和全局愿景所违背。在操作上,全局愿景是设计团队共同制定出来的,而子模块级的架构愿景就可以分给设计子团队来负责,而其审核则还是要设计团队的共同参与。这有两个好处,一是确保各个子模块(子问题)间不至于相互冲突或出现空白地带,二是每个子设计团队可以从别人那里吸取设计经验。
在设计时,同样我们可以参考其它的资料,例如相关的模式、或规范(界面设计指南)。在一个有开发经验的团队,一般都会有开发技术的积累,这些也是可供参考的重要资料。
我们在这个层次的愿景中主要谈一谈子模块(子问题)间的耦合问题。一般来说,各个子模块间的耦合程度相对较小,例如一个MIS系统中,采购和销售模块的耦合度就比较小,而子问题间的耦合程度就比较大,例如权限设计、财务,这些功能将会被每个模块使用。那么,我们就需要为子模块(子问题)制定出合同接口(Contact Interface)。合同的意思就是说这个接口是正式的,不能够随意的修改,因为这个结构将会被其它的设计团队使用,如果修改,将会对其它的团队产生无法预计的影响。合同接口的制定、修改都需要设计团队的通过。此外,系统中的一些全局性的子问题最好是提到全局愿景中考虑,例如在源自需求模式中提到的信贷帐务的例子中,我们就把一个利息计算方式的子问题提到了全局愿景中。
代码级的愿景
严格的说这一层次的愿景已经不是真正的愿景,而是具体设计了。但是我们为了保证对架构设计理解的完整性,还是简单的讨论一下。这一个层次的愿景一般可以使用类图、接口来表示。但在类图中,你不需要标记出具体的属性、操作,你只需要规定出类的职责以及类之间的相互关系就可以了。该层次愿景的审核需要设计子团队的通过。
而设计细分到这个粒度上,执行愿景设计的开发人员可能就只有一两个左右。但是比较重要的工作在于问题如何分解和如何归并。分解主要是从两个维度来考虑,一个是问题大小维,一个是时间长短维。也就是说,你(设计子团队负责人)需要把问题按大小和解决时间的长短分解为更细的子问题,交给不同的开发人员。然后再把开发人员提出的解决方法组合起来。
架构愿景的形成过程
架构愿景的形成的源头是需求,需要特别指出的是,这里的需求主要是那些针对系统基本面的需求。比如说,系统的特点是一个交互式系统,还是一个分布式系统。这些需求将会影响到架构愿景的设计。在收集影响架构愿景的各项需求之后,按照需求的重要性来设计架构愿景。
架构愿景的设计并不需要很复杂的过程,也不需要花费很多的时间。我们已经提过,架构远景的主要目的就是为了能够在开发团队中传播设计思路,因此,架构愿景包括基本的设计思路和基本的设计原则。
值得注意的是,架构远景可能会有多种的视角,下文讨论了一种设计模式的视角。但是实际设计中还可能会基于数据库来设计架构愿景。但在企业信息系统的设计中,我推荐使用领域类的设计,也就是下文中讨论的例子。
架构愿景设计好之后,问题的焦点就转到如何传播架构愿景上来,为了达到在开发团队中取得统一设计意图的效果,可以考虑援引团队设计模式。除此之外,针对性的项目前期培训也会是一种有效的做法。
使用架构模式
架构模式也是一种很好的架构愿景设计思路的来源。随着对设计模式的研究的深入,人们发现其中的一些设计模式可以扩展、或变化为软件设计的基础。在这个基础上再实现更多的设计,这些模式就形成了架构模式。当然,不同的软件,它们的架构模式也是不一样的。在《Applying Pattern》一文中,有一个很典型的架构愿景的例子:
假设我们需要设计分布式的交互式系统。分布式系统和交互式系统都有特定的架构模式,前者为Broker模式,后者为MVC模式。首先我们先要根据系统的特点的重要程度来排列模式的顺序。这里假设需求中分布式特性更重要一些。那么我们首先选择Broker模式作为架构的基本模式:
再考虑交互式的特点,根据MVC模式的特点,我们需要从目前的基本架构中识别出Model、Controller、以及View。Model和View都很简单,分别分布在上图中的Server和Client中。而Controller则有两种的选择,假设这里的Controller部署在客户端,上图则演化为下图:
这样,基础的架构愿景就已经出现了。如果我们还有更多的需求,还可以继续改进。但是,记住一点,架构愿景不要过于复杂。正如我们在上一节中所讨论的,这里我们虽然是基于设计模式来讨论架构愿景,但是实际中还有很多从其它的视角来看待架构愿景的。至于要如何选择架构愿景的视角,关键的还是在于需求的理解。
需求分析的20条法��
我们讨论的过程仅限于面向对象的软件开发过程。我们称之为OOSP(object-oriented software process )。因为我们的过程需要面向对象特性的支持。当然,我们的很多做法一样可以用在非OO的开发过程中,但是为了达到最佳的效果,我建议您使用OO技术。对商业用户来说,他们后面是成百上千个供应商,前面是成千上万个消费顾客。怎样利用软件管理错综复杂的供应商和消费顾客,如何做好精细到一个小小调料包的进、销、调、存的商品流通工作,这些都是商业企业需要信息管理系统的理由。软件开发的意义也就在于此。而弄清商业用户如此复杂需求的真面目,正是软件开发成功的关键所在。
经理:“我们要建立一套完整的商业管理软件系统,包括商品的进、销、调、存管理,是总部-门店的连锁经营模式。通过通信手段门店自动订货,供应商自动结算,卖场通过扫条码实现销售,管理人员能够随时查询门店商品销售和库存情况。另外,我们也得为政府部门提供关于商品营运的报告。”
分析员:“我已经明白这个项目的大体结构框架,这非常重要,但在制定计划之前,我们必须收集一些需求。”
经理觉得奇怪:“我不是刚告诉你我的需求了吗?”
分析员:“实际上,您只说明了整个项目的概念和目标。这些高层次的业务需求不足以提供开发的内容和时间。我需要与实际将要使用系统的业务人员进行讨论,然后才能真正明白达到业务目标所需功能和用户要求,了解清楚后,才可以发现哪些是现有组件即可实现的,哪些是需要开发的,这样可节省很多时间。”
经理:“业务人员都在招商。他们非常忙,没有时间与你们详细讨论各种细节。你能不能说明一下你们现有的系统?”
分析员尽量解释从用户处收集需求的合理性:“如果我们只是凭空猜想用户的要求,结果不会令人满意。我们只是软件开发人员,而不是采购专家、营运专家或是财务专家,我们并不真正明白您这个企业内部运营需要做些什么。我曾经尝试过,未真正明白这些问题就开始编码,结果没有人对产品满意。”
经理坚持道:“行了,行了,我们没有那么多的时间。让我来告诉您我们的需求。实际上我也很忙。请马上开始开发,并随时将你们的进展情况告诉我。”
风险躲在需求的迷雾之后
以上我们看到的是某客户项目经理与系统开发小组的分析人员讨论业务需求。在项目开发中,所有的项目风险承担者都对需求分析阶段备感兴趣。这里所指的风险承担者包括客户方面的项目负责人和用户,开发方面的需求分析人员和项目管理者。这部分工作做得到位,能开发出很优秀的软件产品,同时也会令客户满意。若处理不好,则会导致误解、挫折、障碍以及潜在的质量和业务价值上的威胁。因此可见——需求分析奠定了软件工程和项目管理的基础。
拨开需求分析的迷雾
像这样的对话经常出现在软件开发的过程中。客户项目经理的需求对分析人员来讲,像“雾里看花”般模糊并令开发者感到困惑。那么,我们就拨开雾影,分析一下需求的具体内容:
·业务需求——反映了组织机构或客户对系统、产品高层次的目标要求,通常在项目定义与范围文档中予以说明。
·用户需求——描述了用户使用产品必须要完成的任务,这在使用实例或方案脚本中予以说明。
·功能需求——定义了开发人员必须实现的软件功能,使用户利用系统能够完成他们的任务,从而满足了业务需求。
·非功能性的需求——描述了系统展现给用户的行为和执行的操作等,它包括产品必须遵从的标准、规范和约束,操作界面的具体细节和构造上的限制。
·需求分析报告——报告所说明的功能需求充分描述了软件系统所应具有的外部行为。“需求分析报告”在开发、测试、质量保证、项目管理以及相关项目功能中起着重要作用。
前面提到的客户项目经理通常阐明产品的高层次概念和主要业务内容,为后继工作建立了一个指导性的框架。其他任何说明都应遵循“业务需求”的规定,然而“业务需求”并不能为开发人员提供开发所需的许多细节说明。
下一层次需求——用户需求,必须从使用产品的用户处收集。因此,这些用户构成了另一种软件客户,他们清楚要使用该产品完成什么任务和一些非功能性的特性需求。例如:程序的易用性、健壮性和可靠性,而这些特性将会使用户很好地接受具有该特点的软件产品。
经理层有时试图代替实际用户说话,但通常他们无法准确说明“用户需求”。用户需求来自产品的真正使用者,必须让实际用户参与到收集需求的过程中。如果不这样做,产品很可能会因缺乏足够的信息而遗留不少隐患。
在实际需求分析过程中,以上两种客户可能都觉得没有时间与需求分析人员讨论,有时客户还希望分析人员无须讨论和编写需求说明就能说出用户的需求。除非遇到的需求极为简单;否则不能这样做。如果您的组织希望软件成功,那么必须要花上数天时间来消除需求中模糊不清的地方和一些使开发者感到困惑的方面。
优秀的软件产品建立在优秀的需求基础之上,而优秀的需求源于客户与开发人员之间有效的交流和合作。只有双方参与者都明白自己需要什么、成功的合作需要什么时,才能建立起一种良好的合作关系。
由于项目的压力与日俱增,所有项目风险承担者有着一个共同目标,那就是大家都想开发出一个既能实现商业价值又能满足用户要求,还能使开发者感到满足的优秀软件产品。
客户的需求观
客户与开发人员交流需要好的方法。下面建议20条法则,客户和开发人员可以通过评审以下内容并达成共识。如果遇到分歧,将通过协商达成对各自义务的相互理解,以便减少以后的磨擦(如一方要求而另一方不愿意或不能够满足要求)。
1、 分析人员要使用符合客户语言习惯的表达
需求讨论集中于业务需求和任务,因此要使用术语。客户应将有关术语(例如:采价、印花商品等采购术语)教给分析人员,而客户不一定要懂得计算机行业的术语。
2、分析人员要了解客户的业务及目标
只有分析人员更好地了解客户的业务,才能使产品更好地满足需要。这将有助于开发人员设计出真正满足客户需要并达到期望的优秀软件。为帮助开发和分析人员,客户可以考虑邀请他们观察自己的工作流程。如果是切换新系统,那么开发和分析人员应使用一下目前的旧系统,有利于他们明白目前系统是怎样工作的,其流程情况以及可供改进之处。s 3、分析人员必须编写软件需求报告
分析人员应将从客户那里获得的所有信息进行整理,以区分业务需求及规范、功能需求、质量目标、解决方法和其他信息。通过这些分析,客户就能得到一份“需求分析报告”,此份报告使开发人员和客户之间针对要开发的产品内容达成协议。报告应以一种客户认为易于翻阅和理解的方式组织编写。客户要评审此报告,以确保报告内容准确完整地表达其需求。一份高质量的“需求分析报告”有助于开发人员开发出真正需要的产品。
4、 要求得到需求工作结果的解释说明
分析人员可能采用了多种图表作为文字性“需求分析报告”的补充说明,因为工作图表能很清晰地描述出系统行为的某些方面,所以报告中各种图表有着极高的价值;虽然它们不太难于理解,但是客户可能对此并不熟悉,因此客户可以要求分析人员解释说明每个图表的作用、符号的意义和需求开发工作的结果,以及怎样检查图表有无错误及不一致等。
5、 开发人员要尊重客户的意见
如果用户与开发人员之间不能相互理解,那关于需求的讨论将会有障碍。共同合作能使大家“兼听则明”。参与需求开发过程的客户有权要求开发人员尊重他们并珍惜他们为项目成功所付出的时间,同样,客户也应对开发人员为项目成功这一共同目标所做出的努力表示尊重。
6、 开发人员要对需求及产品实施提出建议和解决方案
通常客户所说的“需求”已经是一种实际可行的实施方案,分析人员应尽力从这些解决方法中了解真正的业务需求,同时还应找出已有系统与当前业务不符之处,以确保产品不会无效或低效;在彻底弄清业务领域内的事情后,分析人员就能提出相当好的改进方法,有经验且有创造力的分析人员还能提出增加一些用户没有发现的很有价值的系统特性。
7、 描述产品使用特性
客户可以要求分析人员在实现功能需求的同时还注意软件的易用性,因为这些易用特性或质量属性能使客户更准确、高效地完成任务。例如:客户有时要求产品要“界面友好”或“健壮”或“高效率”,但对于开发人员来讲,太主观了并无实用价值。正确的做法是,分析人员通过询问和调查了解客户所要的“友好、健壮、高效所包含的具体特性,具体分析哪些特性对哪些特性有负面影响,在性能代价和所提出解决方案的预期利益之间做出权衡,以确保做出合理的取舍。
8、 允许重用已有的软件组件
需求通常有一定灵活性,分析人员可能发现已有的某个软件组件与客户描述的需求很相符,在这种情况下,分析人员应提供一些修改需求的选择以便开发人员能够降低新系统的开发成本和节省时间,而不必严格按原有的需求说明开发。所以说,如果想在产品中使用一些已有的商业常用组件,而它们并不完全适合您所需的特性,这时一定程度上的需求灵活性就显得极为重要了。
9、 要求对变更的代价提供真实可靠的评估
有时,人们面临更好、也更昂贵的方案时,会做出不同的选择。而这时,对需求变更的影响进行评估从而对业务决策提供帮助,是十分必要的。所以,客户有权利要求开发人员通过分析给出一个真实可信的评估,包括影响、成本和得失等。开发人员不能由于不想实施变更而随意夸大评估成本。
10、 获得满足客户功能和质量要求的系统
每个人都希望项目成功,但这不仅要求客户要清晰地告知开发人员关于系统“做什么”所需的所有信息,而且还要求开发人员能通过交流了解清楚取舍与限制,一定要明确说明您的假设和潜在的期望,否则,开发人员开发出的产品很可能无法让您满意。
11、 给分析人员讲解您的业务
分析人员要依靠客户讲解业务概念及术语,但客户不能指望分析人员会成为该领域的专家,而只能让他们明白您的问题和目标;不要期望分析人员能把握客户业务的细微潜在之处,他们可能不知道那些对于客户来说理所当然的“常识”。
12、 抽出时间清楚地说明并完善需求
客户很忙,但无论如何客户有必要抽出时间参与“头脑高峰会议”的讨论,接受采访或其他获取需求的活动。有些分析人员可能先明白了您的观点,而过后发现还需要您的讲解,这时请耐心对待一些需求和需求的精化工作过程中的反复,因为它是人们交流中很自然的现象,何况这对软件产品的成功极为重要。
13、 准确而详细地说明需求
编写一份清晰、准确的需求文档是很困难的。由于处理细节问题不但烦人而且耗时,因此很容易留下模糊不清的需求。但是在开发过程中,必须解决这种模糊性和不准确性,而客户恰恰是为解决这些问题作出决定的最佳人选,否则,就只好靠开发人员去正确猜测了。
在需求分析中暂时加上“待定”标志是个方法。用该标志可指明哪些是需要进一步讨论、分析或增加信息的地方,有时也可能因为某个特殊需求难以解决或没有人愿意处理它而标注上“待定”。客户要尽量将每项需求的内容都阐述清楚,以便分析人员能准确地将它们写进“软件需求报告”中去。如果客户一时不能准确表达,通常就要求用原型技术,通过原型开发,客户可以同开发人员一起反复修改,不断完善需求定义。
14、 及时作出决定
分析人员会要求客户作出一些选择和决定,这些决定包括来自多个用户提出的处理方法或在质量特性冲突和信息准确度中选择折衷方案等。有权作出决定的客户必须积极地对待这一切,尽快做处理,做决定,因为开发人员通常只有等客户做出决定才能行动,而这种等待会延误项目的进展。
15、 尊重开发人员的需求可行性及成本评估
所有的软件功能都有其成本。客户所希望的某些产品特性可能在技术上行不通,或者实现它要付出极高的代价,而某些需求试图达到在操作环境中不可能达到的性能,或试图得到一些根本得不到的数据。开发人员会对此作出负面的评价,客户应该尊重他们的意见。
16、 划分需求的优先级
绝大多数项目没有足够的时间或资源实现功能性的每个细节。决定哪些特性是必要的,哪些是重要的,是需求开发的主要部分,这只能由客户负责设定需求优先级,因为开发者不可能按照客户的观点决定需求优先级;开发人员将为您确定优先级提供有关每个需求的花费和风险的信息。
在时间和资源限制下,关于所需特性能否完成或完成多少应尊重开发人员的意见。尽管没有人愿意看到自己所希望的需求在项目中未被实现,但毕竟是要面对现实,业务决策有时不得不依据优先级来缩小项目范围或延长工期,或增加资源,或在质量上寻找折衷。
17、 评审需求文档和原型
客户评审需求文档,是给分析人员带来反馈信息的一个机会。如果客户认为编写的“需求分析报告”不够准确,就有必要尽早告知分析人员并为改进提供建议。
更好的办法是先为产品开发一个原型。这样客户就能提供更有价值的反馈信息给开发人员,使他们更好地理解您的需求;原型并非是一个实际应用产品,但开发人员能将其转化、扩充成功能齐全的系统。
18、 需求变更要立即联系
不断的需求变更,会给在预定计划内完成的质量产品带来严重的不利影响。变更是不可避免的,但在开发周期中,变更越在晚期出现,其影响越大;变更不仅会导致代价极高的返工,而且工期将被延误,特别是在大体结构已完成后又需要增加新特性时。所以,一旦客户发现需要变更需求时,请立即通知分析人员。
19、 遵照开发小组处理需求变更的过程
为将变更带来的负面影响减少到最低限度,所有参与者必须遵照项目变更控制过程。这要求不放弃所有提出的变更,对每项要求的变更进行分析、综合考虑,最后做出合适的决策,以确定应将哪些变更引入项目中。
20、 尊重开发人员采用的需求分析过程
软件开发中最具挑战性的莫过于收集需求并确定其正确性,分析人员采用的方法有其合理性。也许客户认为收集需求的过程不太划算,但请相信花在需求开发上的时间是非常有价值的;如果您理解并支持分析人员为收集、编写需求文档和确保其质量所采用的技术,那么整个过程将会更为顺利。
“需求确认”意味着什么
在“需求分析报告”上签字确认,通常被认为是客户同意需求分析的标志行为,然而实际操作中,客户往往把“签字”看作是毫无意义的事情。“他们要我在需求文档的最后一行下面签名,于是我就签了,否则这些开发人员不开始编码。”
这种态度将带来麻烦,譬如客户想更改需求或对产品不满时就会说:“不错,我是在需求分析报告上签了字,但我并没有时间去读完所有的内容,我是相信你们的,是你们非让我签字的。”
同样问题也会发生在仅把“签字确认”看作是完成任务的分析人员身上,一旦有需求变更出现,他便指着“需求分析报告”说:“您已经在需求上签字了,所以这些就是我们所开发的,如果您想要别的什么,您应早些告诉我们。”
这两种态度都是不对的。因为不可能在项目的早期就了解所有的需求,而且毫无疑问地需求将会出现变更,在“需求分析报告”上签字确认是终止需求分析过程的正确方法,所以我们必须明白签字意味着什么。
对“需求分析报告”的签名是建立在一个需求协议的基线上,因此我们对签名应该这样理解:“我同意这份需求文档表述了我们对项目软件需求的了解,进一步的变更可在此基线上通过项目定义的变更过程来进行。我知道变更可能会使我们重新协商成本、资源和项目阶段任务等事宜。”对需求分析达成一定的共识会使双方易于忍受将来的摩擦,这些摩擦来源于项目的改进和需求的误差或市场和业务的新要求等。
需求确认将迷雾拨散,显现需求的真面目,给初步的需求开发工作画上了双方都明确的句号,并有助于形成一个持续良好的客户与开发人员的关系,为项目的成功奠定了坚实的基础。
专访架构师周爱民:谈企业软件架构设计
最近在网上读到了“杀不死的人狼——我读《人月神话》”系列文章。是周爱民关于《人月神化》的读书心得。《人月神化》在软件工程里一本很有分量的书,讲述了Brooks博士在IBM公司 System/360家族和OS/360中的项目管理经验。周爱民在他的这一系列文章中用自己架构师经历为基础,从他的视角重新品读了这本书。而这也使我有了采访下他的想法,从中我们也许可以了解到中国企业内软件架构设计这个环节的现状。目前周爱民是盛大网络架构师。在此特别感谢周爱民在百忙中抽出时间回复了这次访谈。
1, 您好,请先向我们的网友简单做一下自我介绍自己好吗?
我94年开始学习电脑,基本上从一开始就学编程。从96年开始涉及商业软件开发,到现在约十一年了。其间我在郑州的一家软件公司呆了7年,历经了一家软件公司的中兴到消亡,因而也意识到工程、管理在软件企业——当然也包括其它类型的企业——中的价值。后来,从03年开始的一年多时间,我在郑州的另一家公司任软件部经理,也开始实践自己的工程和管理思想。很好,到现在我离开这家公司一年多了,公司状况依然很不错。我认为,团队或公司并没有因为你的缺席而变得糟糕,那便已经是良性管理的表现了。关于“Borland Delphi产品专家”,其实更多的是一个圈子的认可,而非行业的认可。我在“大富翁论坛(delphibbs.com)”活动了很长的时间,得到了一些朋友们的认可,后来Borland要评选这个专家的时候,大家推举了我,于是就得了这个称号。其实在我看来,优秀的人才、专家很多,我大约是人缘好点,运气好点罢。
我05年9月开始到盛大网络,任架构师一职。当时Borland China也有offer,但在顾问、软件工程师与架构师之间,我选择了架构师这个职务,因为我对这个角色更加感兴趣。我目前的工作,主要是盛大的软件平台方面的架构、设计和一些实施方面的事务。虽然很多人认为盛大是做游戏的公司,但我基本不涉及游戏产品的开发。
在开发技术方面,我03年出版过一本《Delphi源代码分析》。在工程方面,《大道至简——软件工程实践者的思想》一书在下月初就应出版了,它的第一版是以电子版的形式发布的。我在写的第三本书则是讲计算机语言的,题材是“动态函数式语言”。
2,您做为盛大网络的架构师,请介绍一下在软件项目中平台架构师是一份怎样的角色?主要处理哪些工作?
架构师有很多种。很多人把体系架构师与架构师等同,其实不对。各类架构师基本素质要求大抵一致,例如分析能力、设计的技术方法,以及对设计目标的前瞻性。但是他们的专业素质会有一些差别。举个实例来说,如果让我设计游戏引擎的架构,我就会做不好。但是,如果这个游戏引擎要设计成一个独立的平台层次,具有语言无关性、平台整合能力,或是对不同类型游戏的统一支撑,那么就是平台架构师的职责了。
具体来说,平台架构师会决策某个部分与其它部分的相互关系、界面的规约和检测评估它们的方法。如果一个游戏引擎只为某个游戏而设计,那么是用不到平台架构师的。但如果A游戏中的引擎要移植到B游戏,或者更多的游戏,甚至只是抽离它的部分,以作为某种体系中的一个数据交互层,那么就需要平台架构师来考量技术上的可行性、稳定性以及它对于更大范围内的平台建设的价值——当然,如果没有价值,架构师也会否定它。
平台是长期建设的。平台架构师的重要职责之一,就是长期的规划和持续的推进。所以平台架构师的工作总是伴随客户的战略决策的。如果一个设计只是解决短期的技术问题,那么也并不需要平台架构师,但如果是几年或十几年要在上面持续经营的一个整体方向,那么平台架构师就需要围绕战略来设计架构的蓝图,并决定规划的实施步骤。在这些方面,他可能需要协调很多团队一些来工作。不过,这可不是跟项目经理抢饭碗。因为项目经理重在实施,而架构师重在规划。
当然,事实上我也做一些其它类型的架构设计工作。例如设计一个小的模块,或者一个业务工件。好的架构师不会拒绝这些工作,而是从更多的、细节的工作中发现整体与局部的关系。也只有触及到具体工作的细节,架构师才可能更早地发觉设计上的隐患或者与目标的偏差。
3,《人月神话》这本书30多年来一直被认为是项目管理者的必读书,最近也看到您的blog里写了一系列相关的书评。您是怎么看到书中“项目实施法则“和实际项目工作之间的关系。
这几个问题我基本上都在《杀不死的人狼》一文中讲过了。概括来说,我认为有以下三点:
一、讨论“有或没有”银弹这样的话题没有意义,因为《人月神话》所述的人狼根本杀不死,而且Brooks所设想的银弹也过于学术。
二、《人月神话》从广义工程的角度设定了这个命题,这个命题的根本目标与次要目标正好与具体工程(狭义工程)相反。
三、我承认《人月神话》神话所述的答案以及建议在如今的软件工程中得到了体现。但我们应该更清醒地辨析出现象、答案与本质,并分析哪些是本质的自然延伸,而哪些只是《人月神话》所带来的影响——Brooks预言了未来,也就改变了未来,即使未来未必应该如此。
与大多数人不一样的是,我更多的是从与Brooks的预言不一致的那些现象是去发现一些东西。我所看到的是,正是在改变了Brooks的命题,或者认识到他所述的“本质”未必正确的时候,我们才找到了一些“不一样的成功”。我提醒大家关注这些事例,以及它们与传统工程、广义工程的本质差异。
我并不反对《人月神话》中的大多数工程观点,以及我们现在的软件业中的工程实践经验。但是狭义工程没有必要去追寻银弹或那些看起来看银弹的东西,我们应该更加灵活。
4企业在进行项目的软件架构设计时,需要考虑哪些关键的问题?
企业实施过程中的架构问题,可以分成两个部分来考虑。一个是软件企业自身,一个是工程的目标客户(有些时候它与前者一则)。基本上来说,架构设计首先是面向客户的,甚至在整个工程的绝大多数时候都面向客户。因为理解决定设计,所以让架构师尽可能早地、深入地了解工程目标、应用环境、战略决策和发展方向,是至关重要的。否则,架构师是不可能做出有效的设计来的。
架构设计关注于三个方面:稳定、持续和代价。
稳定性由架构师的设计能力决定。架构的好坏是很难评判的,但基本的法则是“适用”。如果一个架构不适用,那么再小或者再大都不可能稳定。所因此进一步推论是“架构必须以工程的主体目标为设计象”。看起来这是个简单的事,但事实上很多架构设计中只是在做边角功夫,例如为一两处所谓的“精彩的局部”而叫好,全然不顾架构是否为相应的目标而做。
持续性由架构师的地位决定。如果不能认识“设计的一致性”,以及架构师对这种一致性的权威,那么再好的架构也会面临解体,再长远的架构也会在短期内被废弃。架构的实施是要以牺牲
自由性为代价的,架构师没有足够的地位(或权威),则不可能对抗实施者对自由的渴望。通常的失败,并在于架构的好或坏,而是架构被架空,形同虚设。
代价的问题上面有过一点讨论,但方向不同。这里说明的是,如果架构师没有充分的经验,不能准确评估所设计的架构的资源消耗,那么可能在项目初起便存在设计失误;也可能在项目中困于枝节,或疏离关键,从而徒耗了资源。这些都是架构师应该预见、预估的。
对于企业设计来说,上面三个方面没有得到关注的结果就是:迟迟无法上线的工程、半拉子工程和不停追加投资的工程项目。我不否认项目经理对这些问题的影响,但事实上可能从设计就开始出了问题,而项目经理只是回天乏术罢了。
最后说明一下,我认为目前大多数的企业项目都缺乏架构上的考量。大多数软件公司只是出于自身的需要(例如组件化和规模开发)而进行架构设计。这样的设计不是面向客户的,事实上这增加了客户投资,而未能给客户项目产生价值。这也是我强调架构面向客户的原因之一。
5 目前,你的团队在使用什么样的产品或者方法来进行软件架构设计?
架构设计的主要输出是文档,因而并没有什么特别的工具来帮助你做架构设计。很多工具是辅助分析的,例如MindMananger;另外一些则可能辅助你表述,例如Together和Rose。
大多数技术出身的架构师会仅把“软件编写的东西”才称为工具。其实不然,会议室里的那面白板也是我的工具之一。放开思路,市场规划图、技术架构路标图、特性/收益规划图等等这些图表也是我们的工具。除开这些之外,模式语言和建模语言也是主要的、形式化的工具。
我经常按RUP的规范写文档,也偶尔放弃其中的某些具体格式。这些既有的文档模板也是工具。当然,毋庸置疑的是这样的工具也包括WORD和PowerPoint——很多人并不知道,我有1/4的设计是先用PowerPoint/Visio来完成的。
具体到方法,则非常多了,但应用哪一种则与场景有关。不过最先做的则是分层,这与自顶向下的结构分析很象——事实上在分析和设计的最初阶段,这种方法几乎是必须的。
6,您觉得国内外软件架构设计这个环节的主要不同在哪里?
正如你这个问题所表现出来的一样:我们太注重于工程环节的某个局部。
国外软件行业在工程实践经验上已丰富得多,因此大多数程序员、项目经理或测试人员等等对工程的理解也深刻得多。他们并不自恃于当前的环节,也不否认其它环节。这意味着在整体实施
中大家更容易达成一致。然而国内的软件工程则很少强调这种合作,项目经理强调管理,程序员强调技术,架构师强调一致性和持续性,测试人员则很开心的看到每一个错误并以及数量作为评核依据。
显然这里出了问题:我们的合作环节在各自为战。大家都在强调自己的重要性,于是工程就没法做了。解决的法子,还是让大家都意识到对方工作的目标与职责,而不仅仅是了解自己的那个小圈子。
7,可以介绍一下你目前的Qomo项目吗?我们的网友该如何参与?
Qomo(Qomolangma OpenProject)是一个JavaScript上的开源项目。目前Qomo 1.0正式版已经发布了。Qomo V1以语言补实为基本思想,在JavaScript上扩展了AOP、OOP、IOP和GP等编程方法,基于它自身的完备的实现,Qomo也提供了Builder和Profiler工具和相关的库。
Qomo V1只是整个Qomolangma OpenProject构想中的一很小一部分——尽管它重要。Qomo项目提出的整体目标是:
-Qomo内核是足够强大的能应用在不同的JavaScript宿主环境下的通用扩展。
-Qomo有能力提供胶合不同的应用环境下功能需求的中间代码。
-Qomo可以作为定制的宿主应用的代码包的一个部分以提升应用的体验或局部性能。
所以Qomo V1并不完备。即便是我们正在展开的Qomo V2,也并不完备。V2计划提供组件库、数据库存取层和图形表现层。此外,Qomo V2也打算启用数个实践项目,一方面作为Qomo的范例,另一方面也验证Qomo的设计。
Qomo已经在sourceforge上注册过,但在那里表现并不活跃。你可以总是从我的blog上得到Qomo的最新消息,包括Qomo的计划与每个版本发布。至于参与这个项目,请发mail给我。
C++之设计模式实现代码
----------------------- Page 1-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
设计模式精解-GoF 23 种设计模式解析附 C++实现源码
目 录
0 引言..............................................................................................................................................2
0.1 设计模式解析(总序).....................................................................................................2
0.2 设计模式解析后记.............................................................................................................2
0.3 与作者联系........................................................................................................................5
1 创建型模式...................................................................................................................................5
1.1 Factory模式 ........................................................................................................................5
1.2 AbstactFactory模式 .......................................................................................................... 11
1.3 Singleton模式...................................................................................................................16
1.4 Builder模式.......................................................................................................................18
1.5 Prototype模式...................................................................................................................23
2 结构型模式.................................................................................................................................26
2.1 Bridge模式........................................................................................................................26
2.2 Adapter模式......................................................................................................................31
2.3 Decorator模式...................................................................................................................35
2.4 Composite模式.................................................................................................................40
2.5 Flyweight模式 ..................................................................................................................44
2.6 Facade模式.......................................................................................................................49
2.7 Proxy模式.........................................................................................................................52
3 行为模式.....................................................................................................................................55
3.1 Template模式....................................................................................................................55
3.2 Strategy模式 .....................................................................................................................59
3.3 State模式...........................................................................................................................63
3.4 Observer模式....................................................................................................................68
3.5 Memento模式...................................................................................................................73
3.6 Mediator模式....................................................................................................................76
3.7 Command模式..................................................................................................................81
3.8 Visitor模式........................................................................................................................87
3.9 Chain of Responsibility模式.............................................................................................92
3.10 Iterator模式.....................................................................................................................96
3.11 Interpreter模式..............................................................................................................100
4 说明 ..........................................................................................................................................105
第 1 页 共 105 页 k_eckel
----------------------- Page 2-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
0 引言
0.1 设计模式解析(总序)
“Next to My Life, Software Is My Passion”——Robert C.Martin.
懂了设计模式,你就懂了面向对象分析和设计(OOA/D )的精要。反之好像也可能成
立。道可道,非常道。道不远人,设计模式亦然如此。
一直想把自己的学习经验以及在项目中的应用经历拿出来和大家共享,却总是下不了这
个决心:GoF 的23 种模式研读、总结也总需要些时日,然而时间对于我来说总是不可预计
的。
之所以下了这个决心,有两个原因:一是Robert 的箴言,二是因为我是一个感恩的人,
就像常说的:长怀感恩之心,人生便无遗憾。想想当时读 GoF 的那本圣经时候的苦闷、实
现23 个模式时候的探索、悟道后的欣悦,我觉得还是有这个意义。
0.2 设计模式解析后记
写完了Interpreter模式之后,我习惯性的看看下一天的安排,却陡然发现GoF的 23个
设计模式的解析已经在我不经意间写完了。就像在一年前看GoF的《设计模式》一书,和半
年前用C++模拟、实现 23种经典的设计模式一般,透过这个写解析的过程,我又看到了另外
一个境界。一直认为学习的过程很多时候可以这样划分:自己学会一门知识(技术)、表达
出来、教会别人、记录下来,虽然这个排序未必对每个人都合适 (因为可能不同人有着不同
的特点能力)。学一门知识,经过努力、加以时日,总是可以达到的,把自己学的用自己的
话表达出来就必须要将学到的知识加以消化、理解,而教会一个不懂这门知识的人则比表达
出来要难,因为别人可能并不是适应你的表述方式,记录下来则需要经过沉淀、积累、思考,
最后厚积薄发,方可小成。
设计模式之于面向对象系统的设计和开发的作用就有如数据结构之于面向过程开发的
作用一般,其重要性和必要性自然不需要我赘述。然而学习设计模式的过程却是痛苦的,从
阅读设计模式的圣经——GoF 的《设计模式:可复用面向对象软件的基础》时的枯燥、苦闷、
茫无头绪,到有一天突然有一种顿悟;自己去实现GoF 的23 中模式时候的知其然不知其所
以然,并且有一天在自己设计的系统种由于设计的原因让自己苦不堪言,突然悟到了设计模
第 2 页 共 105 页 k_eckel
----------------------- Page 3-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
式种的某一个正好可以很好的解决问题,到自己设计的 elegant 的系统时候的喜悦与思考;
一直到最后向别人去讲解设计模式,别人向你咨询设计模式,和别人讨论设计模式。就如
GoF 在其前言中说到:一旦你理解了设计并且有了一种 “Aha!” (而不是 “Huh?”)的应
用经验和体验后,你将用一种非同寻常的方式思考面向对象设计。这个过程我认为是漫长的,
painful,但是是非常必要的。经过了的才是自己的,Scott Mayer 在其巨著《Effective C++》
就曾经说过:C++老手和C++新手的区别就是前者手背上有很多伤疤。是的在软件开发和设
计的过程中,失败、错误是最好的老师,当然在系统开发中,失败和错误则是噩梦的开端和
结束,因为你很难有改正错误的机会。因此,尽量让自己多几道疤痕是对的。
面向对象系统的分析和设计实际上追求的就是两点,一是高内聚 (Cohesion),而是低
耦合 (Coupling)。这也是我们软件设计所准求的,因此无论是OO 中的封装、继承、多态,
还是我们的设计模式的原则和实例都是在为了这两个目标努力着、贡献着。
道不远人,设计模式也是这般,正如我在 《设计模式探索(总序)》中提到的。设计模
式并不是空的理论,并不是脱离实际的教条。就如我们在进行软件开发的过程会很自然用到
很多的算法和结构来解决实际的问题,那些其实也就是数据结构中的重要概念和内容。在面
向对象系统的设计和开发中,我们已经积累了很多的原则,比如面向对象中的封装、继承和
多态、面向接口编程、优先使用组合而不是继承、将抽象和实现分离的思想等等,在设计模
式中你总是能看到他们的影子,特别是组合 (委托)和继承的差异带来系统在耦合性上的差
别,更是在设计模式多次涉及到。而一些设计模式的思想在我们做系统的设计和开发中则是
经常要用到的,比如说Template、Strategy模式的思想,Singleton模式的思想,Factory
模式的思想等等,还有很多的模式已经在我们的开发平台中扎根了,比如说Observer (其实
例为Model-Control-View模式)是MFC和Struts中的基本框架,Iterator模式则在C++的STL
中有实现等。或许有的人会说,我们不需要设计模式,我们的系统很小,设计模式会束缚我
们的实现。我想说的是,设计模式体现的是一种思想,而思想则是指导行为的一切,理解和
掌握了设计模式,并不是说记住了23种(或更多)设计场景和解决策略(实际上这也是很
重要的一笔财富),实际接受的是一种思想的熏陶和洗礼,等这种思想融入到了你的思想中
后,你就会不自觉地使用这种思想去进行你的设计和开发,这一切才是最重要的。
之于学习设计模式的过程我想应该是一个迭代的过程,我向来学东西的时候不追求一遍
就掌握、理解透彻 (很多情况也是不可能的),我喜欢用一种迭代的思想来指导我的学习过
程。看书看不懂、思想没有理解,可以反复去读、去思考,我认为这样一个过程是适合向我
们不是有一个很统一的时间去学习一种技术和知识(可能那样有时候反而有些枯燥和郁闷)。
第 3 页 共 105 页 k_eckel
----------------------- Page 4-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
GoF 在 《设计模式》一书中也提到,如果不是一个有经验的面向对象设计人员,建议从最简
单最常用的设计模式入门,比如AbstractFactory 模式、Adapater模式、Composite 模式、
Decorator 模式、Factory模式、Observer模式、Strategy 模式、Template 模式等。我的
感触是确实是这样,至少GoF 列出的模式我都在开发和设计有用到,如果需要我这里再加上
几个我觉得在开发中会很有用的模式:Singleton模式、Façade模式和Bridge 模式。
写设计模式解析的目的其实是想把GoF 的《设计模式》进行简化,变得容易理解和接受。
GoF 的 《设计模式》是圣经,但是同时因为 《设计模式》一书是4 位博士的作品,并且主要
是基于Erich 的博士论文,博士的特色我觉得最大的就是抽象,将一个具体的问题抽象到一
般,形成理论。因此GoF 的这本圣经在很多地方用语都比较精简和抽象,读过的可能都有一
种确实是博士写出来的东西的感觉。抽象的好处是能够提供指导性的意见和建议,其瑕疵就
是不容易为新手所理解和掌握。我的本意是想为抽象描述和具体的实现提供一个桥接 (尽管
GoF 在书中给出了很多的代码和实例,但是我觉得有两个不足:一是不完整,结果是不好直
接看到演示,因此我给出的代码都是完整的、可编译运行的;二是给出的都是一些比较大的
系统中一部分简单实现,我想GoF 的原意可能是想说明这些模式确实很管用,但是却同时带
来一个更大的不好的地方就是不容易为新手理解和掌握),然而这个过程是痛苦的,也可能
是不成功的 (可能会是这样)。这里面就有一个取舍的问题,一方面我想尽量去简化GoF
的描述,然而思考后的东西却在很多的时候和GoF 的描述很相似,并且觉得将这些内容再抽
象一下,书中的很多表达则是最为经典的。当然这里面也有些许的例外,Bruce Eckel 在其
大作《Thinking in Patterns》一书中提到:Bridge 模式是GoF 在描述其 23 中设计模式中
描述得最为糟糕得模式,于我心有戚戚焉!具体的内容请参看我写的《设计模式解析——
Bridge 模式》一文。另外一方面,我又要尽量去避免走到了GoF 一起,因为那样就失去了
我写这个解析的本意了。这两个方面的权衡是很痛苦,并且结果可能也还是没有达到我的本
意要求。
4 月份是我最不忙的时候,也是我非常忙的时候。论文的查阅、思考、撰写,几个项目
的前期准备 (文档、Demo等),俱乐部的诸多事宜,挑战杯的准备,学习 (课业、专业等各
个方面)等等,更加重要的是Visual CMCS (Visual C_minus Compiler System)的设
计和开发(Visual CMCS是笔者设计和开发的C_minus语言(C的子集)的编译系统,系统操
作界面类似VC,并且准备代码分发和共享,详细信息请参考Visual CMCS的网站和Blog中的
相关信息的发布), Visual CMCS1.0(Beta)终于在4 月底发布了,也在别人的帮助下构建
http://cs.whu.edu.cn/cmcs )。之所以提及这个,一方面是在Visual CMCS
了Visual CMCS的网站(
第 4 页 共 105 页 k_eckel
----------------------- Page 5-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
的设计和开发体验了很多的设计模式,比如Factoty模式、Singleton模式、Strategy模式、
State模式等等(我有一篇Blog中有关于这个的不完全的描述);另外一方面是这个设计模
式解析实际上在这些工作的间隙中完成的,我一般会要求自己每天写一个模式,但是特殊的
时候可能没有写或者一天写了不止一个。写这些文章,本身没有任何功利的杂念,只是一个
原生态的冲动,反而很轻松的完成了。有心栽花未必发,无心之事可成功,世间的事情可能
在很多的时候恰恰就是那样了。
最后想用自己在阅读、学习、理解、实现、应用、思考设计模式后的一个感悟结束这个
后记:只有真正理解了设计模式,才知道什么叫面向对象分析和设计。
k_eckel 写毕于2005-05-04 (五四青年节) 1 :01
0.3 与作者联系
Author K_Eckel
State Candidate for Master’s Degree School of Computer Wuhan University
E_mail [email protected]
1 创建型模式
1.1 Factory 模式
问题
在面向对象系统设计中经常可以遇到以下的两类问题:
1 )为了提高内聚(Cohesion)和松耦合(Coupling ),我们经常会抽象出一些类的公共
接口以形成抽象基类或者接口。这样我们可以通过声明一个指向基类的指针来指向实际的子
类实现,达到了多态的目的。这里很容易出现的一个问题n 多的子类继承自抽象基类,我们
不得不在每次要用到子类的地方就编写诸如 new ×××;的代码。这里带来两个问题 1)客
户程序员必须知道实际子类的名称 (当系统复杂后,命名将是一个很不好处理的问题,为了
处理可能的名字冲突,有的命名可能并不是具有很好的可读性和可记忆性,就姑且不论不同
程序员千奇百怪的个人偏好了。),2)程序的扩展性和维护变得越来越困难。
第 5 页 共 105 页 k_eckel
----------------------- Page 6-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
2 )还有一种情况就是在父类中并不知道具体要实例化哪一个具体的子类。这里的意思
为:假设我们在类A 中要使用到类B,B 是一个抽象父类,在 A 中并不知道具体要实例化
那一个B 的子类,但是在类A 的子类D 中是可以知道的。在A 中我们没有办法直接使用类
似于new ×××的语句,因为根本就不知道×××是什么。
以上两个问题也就引出了Factory 模式的两个最重要的功能:
1 )定义创建对象的接口,封装了对象的创建;
2 )使得具体化类的工作延迟到了子类中。
模式选择
我们通常使用Factory 模式来解决上面给出的两个问题。在第一个问题中,我们经常就
是声明一个创建对象的接口,并封装了对象的创建过程。Factory 这里类似于一个真正意义
上的工厂(生产对象)。在第二个问题中,我们需要提供一个对象创建对象的接口,并在子
类中提供其具体实现(因为只有在子类中可以决定到底实例化哪一个类)。
第一中情况的Factory 的结构示意图为:
图1:Factory 模式结构示意图 1
图 1 所以的Factory 模式经常在系统开发中用到,但是这并不是 Factory 模式的最大威
力所在 (因为这可以通过其他方式解决这个问题)。Factory 模式不单是提供了创建对象的接
口,其最重要的是延迟了子类的实例化(第二个问题),以下是这种情况的一个 Factory 的
结构示意图:
第 6 页 共 105 页 k_eckel
----------------------- Page 7-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2:Factory 模式结构示意图 1
图2 中关键中Factory 模式的应用并不是只是为了封装对象的创建,而是要把对象的创
建放到子类中实现:Factory 中只是提供了对象创建的接口,其实现将放在 Factory 的子类
ConcreteFactory 中进行。这是图2 和图 1 的区别所在。
实现
完整代码示例(code)
Factory 模式的实现比较简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 7 页 共 105 页 k_eckel
----------------------- Page 8-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Product.h 代码片断2:Product.cpp
//Product.h //Product.cpp
#ifndef _PRODUCT_H_ #include "Product.h"
#define _PRODUCT_H_
#include
class Product using namespace std;
{
public: Product::Product()
virtual ~Product() = 0; {
protected: }
Product();
Product::~Product()
private: {
}; }
class ConcreteProduct:public Product ConcreteProduct::ConcreteProduct()
{ {
public: cout<<"ConcreteProduct...."<
~ConcreteProduct(); }
ConcreteProduct(); ConcreteProduct::~ConcreteProduct()
{
protected:
}
private:
};
#endif //~_PRODUCT_H_
第 8 页 共 105 页 k_eckel
----------------------- Page 9-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Factory.h 代码片断4: Factory.cpp
//Factory.h //Factory.cpp
#ifndef _FACTORY_H_ #include "Factory.h"
#define _FACTORY_H_ #include "Product.h"
class Product; #include
using namespace std;
class Factory
{ Factory::Factory()
public: {
virtual ~Factory() = 0;
}
virtual Product* CreateProduct() = 0;
Factory::~Factory()
protected: {
Factory();
}
private:
ConcreteFactory::ConcreteFactory()
}; {
cout<<"ConcreteFactory....."<
class ConcreteFactory:public Factory }
{
public: ConcreteFactory::~ConcreteFactory()
{
~ConcreteFactory();
}
ConcreteFactory();
Product* ConcreteFactory::CreateProduct()
Product* CreateProduct(); {
return new ConcreteProduct();
protected: }
private:
};
#endif //~_FACTORY_H_
第 9 页 共 105 页 k_eckel
----------------------- Page 10-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Factory.h"
#include "Product.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Factory* fac = new ConcreteFactory();
Product* p = fac->CreateProduct();
return 0;
}
代码说明
示例代码中给出的是Factory 模式解决父类中并不知道具体要实例化哪一个具体的子类
的问题,至于为创建对象提供接口问题,可以由 Factory 中附加相应的创建操作例如
Create***Product ()即可。具体请参加讨论内容。
讨论
Factory 模式在实际开发中应用非常广泛,面向对象的系统经常面临着对象创建问题:
要创建的类实在是太多了。而 Factory 提供的创建对象的接口封装(第一个功能),以及其
将类的实例化推迟到子类 (第二个功能)都部分地解决了实际问题。一个简单的例子就是笔
者开开发VisualCMCS 系统的语义分析过程中,由于要为文法中的每个非终结符构造一个类
处理,因此这个过程中对象的创建非常多,采用Factory 模式后系统可读性性和维护都变得
elegant 许多。
Factory 模式也带来至少以下两个问题:
1)如果为每一个具体的ConcreteProduct 类的实例化提供一个函数体,那么我们可能不
得不在系统中添加了一个方法来处理这个新建的 ConcreteProduct,这样Factory 的接口永远
就不肯能封闭 (Close)。当然我们可以通过创建一个Factory 的子类来通过多态实现这一点,
但是这也是以新建一个类作为代价的。
2 )在实现中我们可以通过参数化工厂方法,即给 FactoryMethod ()传递一个参数用以
第 10 页 共 105 页 k_eckel
----------------------- Page 11-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
决定是创建具体哪一个具体的Product (实际上笔者在VisualCMCS 中也正是这样做的)。当
然也可以通过模板化避免 1)中的子类创建子类,其方法就是将具体 Product 类作为模板参
数,实现起来也很简单。
可以看出,Factory 模式对于对象的创建给予开发人员提供了很好的实现策略,但是
Factory 模式仅仅局限于一类类(就是说 Product 是一类,有一个共同的基类),如果我们要
为不同类的类提供一个对象创建的接口,那就要用AbstractFactory 了。
1.2 AbstactFactory 模式
问题
假设我们要开发一款游戏,当然为了吸引更多的人玩,游戏难度不能太大 (让大家都没
有信心了,估计游戏也就没有前途了),但是也不能太简单 (没有挑战性也不符合玩家的心
理)。于是我们就可以采用这样一种处理策略:为游戏设立等级,初级、中级、高级甚至有
BT 级。假设也是过关的游戏,每个关卡都有一些怪物 (monster)守着,玩家要把这些怪物
干掉才可以过关。作为开发者,我们就不得不创建怪物的类,然后初级怪物、中级怪物等都
继承自怪物类(当然不同种类的则需要另创建类,但是模式相同)。在每个关卡,我们都要
创建怪物的实例,例如初级就创建初级怪物(有很多种类)、中级创建中级怪物等。可以想
象在这个系统中,将会有成千上万的怪物实例要创建,问题是还要保证创建的时候不会出错:
初级不能创建 BT 级的怪物(玩家就郁闷了,玩家一郁闷,游戏也就挂挂了),反之也不可
以。
AbstractFactory 模式就是用来解决这类问题的:要创建一组相关或者相互依赖的对象。
模式选择
AbstractFactory 模式典型的结构图为:
第 11 页 共 105 页 k_eckel
----------------------- Page 12-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:AbstractFactory Pattern 结构图
AbstractFactory 模式关键就是将这一组对象的创建封装到一个用于创建对象的类
(ConcreteFactory)中,维护这样一个创建类总比维护n 多相关对象的创建过程要简单的多。
实现
完整代码示例(code)
AbstractFactory 模式的实现比较简单,这里为了方便初学者的学习和参考,将给出完整
的实现代码(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 12 页 共 105 页 k_eckel
----------------------- Page 13-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Product.h 代码片断2:Product.cpp
//Product.h //Product.cpp
#ifndef _PRODUCT_H_ #include "Product.h"
#define _PRODUCT_H_ #include
class AbstractProductA using namespace std;
{ AbstractProductA::AbstractProductA()
public: { }
virtual ~AbstractProductA(); AbstractProductA::~AbstractProductA()
protected: { }
AbstractProductA(); AbstractProductB::AbstractProductB()
private: {
}; }
class AbstractProductB AbstractProductB::~AbstractProductB()
{ {
public: }
virtual ~AbstractProductB(); ProductA1::ProductA1()
protected: {
AbstractProductB(); private: cout<<"ProductA1..."<
}; }
class ProductA1:public AbstractProductA ProductA1::~ProductA1()
{ {
public: }
ProductA1(); ProductA2::ProductA2()
~ProductA1(); {
protected: private: cout<<"ProductA2..."<
}; }
class ProductA2:public AbstractProductA ProductA2::~ProductA2()
{ {
public: }
ProductA2(); ProductB1::ProductB1()
~ProductA2(); {
protected: private: cout<<"ProductB1..."<
}; }
class ProductB1:public AbstractProductB ProductB1::~ProductB1()
{ {
public: }
ProductB1(); ProductB2::ProductB2()
~ProductB1(); {
protected: cout<<"ProductB2..."<
private: }
}; ProductB2::~ProductB2()
class ProductB2:public AbstractProductB {
{ }
public:
ProductB2();
~ProductB2(); 第 13 页 共 105 页 k_eckel
protected: private:
};
#endif //~_PRODUCT_H_ECT_H_
----------------------- Page 14-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:AbstractFactory.h 代码片断4:AbstractFactory.cpp
//AbstractFactory.h //AbstractFactory.cpp
#ifndef _ABSTRACTFACTORY_H_ #include "AbstractFactory.h"
#define _ABSTRACTFACTORY_H_ #include "Product.h"
class AbstractProductA; #include
class AbstractProductB; using namespace std;
class AbstractFactory AbstractFactory::AbstractFactory()
{ {
public:
virtual ~AbstractFactory(); }
virtual AbstractProductA* AbstractFactory::~AbstractFactory()
CreateProductA() = 0; {
virtual AbstractProductB* }
CreateProductB() = 0; ConcreteFactory1::ConcreteFactory1()
protected: {
AbstractFactory(); }
private: ConcreteFactory1::~ConcreteFactory1()
}; {
class ConcreteFactory1:public AbstractFactory }
{ AbstractProductA*
public: ConcreteFactory1::CreateProductA()
ConcreteFactory1(); {
~ConcreteFactory1(); return new ProductA1();
AbstractProductA* CreateProductA(); }
AbstractProductB* CreateProductB(); AbstractProductB*
protected: ConcreteFactory1::CreateProductB()
private: {
}; return new ProductB1();
class ConcreteFactory2:public AbstractFactory }
{ ConcreteFactory2::ConcreteFactory2()
public: {
ConcreteFactory2(); }
~ConcreteFactory2(); ConcreteFactory2::~ConcreteFactory2()
AbstractProductA* CreateProductA(); {
AbstractProductB* CreateProductB(); }
protected: AbstractProductA*
private: ConcreteFactory2::CreateProductA()
}; {
#endif //~_ABSTRACTFACTORY_H_ return new ProductA2();
}
AbstractProductB*
ConcreteFactory2::CreateProductB()
{
return new ProductB2();
}
第 14 页 共 105 页 k_eckel
----------------------- Page 15-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "AbstractFactory.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
AbstractFactory* cf1 = new
ConcreteFactory1();
cf1->CreateProductA();
cf1->CreateProductB();
AbstractFactory* cf2 = new
ConcreteFactory2();
cf2->CreateProductA();
cf2->CreateProductB();
return 0;
}
代码说明
AbstractFactory 模式的实现代码很简单,在测试程序中可以看到,当我们要创建一组对
象(ProductA1,ProductA2 )的时候我们只用维护一个创建对象(ConcreteFactory1),大大
简化了维护的成本和工作。
讨论
AbstractFactory 模式和 Factory 模式的区别是初学(使用)设计模式时候的一个容易引
起困惑的地方。实际上,AbstractFactory 模式是为创建一组 (有多类)相关或依赖的对象提
供创建接口,而Factory 模式正如我在相应的文档中分析的是为一类对象提供创建接口或延
迟对象的创建到子类中实现。并且可以看到,AbstractFactory 模式通常都是使用 Factory 模
式实现(ConcreteFactory1 )。
第 15 页 共 105 页 k_eckel
----------------------- Page 16-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
1.3 Singleton 模式
问题
个人认为 Singleton 模式是设计模式中最为简单、最为常见、最容易实现,也是最应该
熟悉和掌握的模式。且不说公司企业在招聘的时候为了考察员工对设计的了解和把握,考的
最多的就是 Singleton 模式。
Singleton 模式解决问题十分常见,我们怎样去创建一个唯一的变量(对象)?在基于
对象的设计中我们可以通过创建一个全局变量 (对象)来实现,在面向对象和面向过程结合
的设计范式 (如C++中)中,我们也还是可以通过一个全局变量实现这一点。但是当我们遇
到了纯粹的面向对象范式中,这一点可能就只能是通过 Singleton 模式来实现了,可能这也
正是很多公司在招聘Java 开发人员时候经常考察 Singleton 模式的缘故吧。
Singleton 模式在开发中非常有用,具体使用在讨论给出。
模式选择
Singleton 模式典型的结构图为:
图2-1:Singleton Pattern 结构图
在 Singleton 模式的结构图中可以看到,我们通过维护一个static 的成员变量来记录这
个唯一的对象实例。通过提供一个 staitc 的接口instance 来获得这个唯一的实例。
实现
完整代码示例(code)
Singleton 模式的实很简单,这里为了方便初学者的学习和参考,将给出完整的实现代
码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 16 页 共 105 页 k_eckel
----------------------- Page 17-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Singleton.h 代码片断2:Singleton.cpp
//Singleton.h //Singleton.cpp
#ifndef _SINGLETON_H_ #include "Singleton.h"
#define _SINGLETON_H_
#include
#include using namespace std;
using namespace std;
Singleton* Singleton::_instance = 0;
class Singleton
{ Singleton::Singleton()
public: {
static Singleton* Instance(); cout<<"Singleton...."<
}
protected:
Singleton(); Singleton* Singleton::Instance()
{
private: if (_instance == 0)
static Singleton* _instance; {
_instance = new Singleton();
}; }
#endif //~_SINGLETON_H_ return _instance;
}
代码片断 3:main.cpp
//main.cpp
#include "Singleton.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Singleton* sgn = Singleton::Instance();
return 0;
}
第 17 页 共 105 页 k_eckel
----------------------- Page 18-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Singleton 模式的实现无须补充解释,需要说明的是,Singleton 不可以被实例化,因此
我们将其构造函数声明为protected 或者直接声明为private。
讨论
Singleton 模式在开发中经常用到,且不说我们开发过程中一些变量必须是唯一的,比
如说打印机的实例等等。
Singleton 模式经常和Factory (AbstractFactory)模式在一起使用,因为系统中工厂对象
一般来说只要一个,笔者在开发 Visual CMCS 的时候,语义分析过程(以及其他过程)中
都用到工厂模式来创建对象(对象实在是太多了),这里的工厂对象实现就是同时是一个
Singleton 模式的实例,因为系统我们就只要一个工厂来创建对象就可以了。
1.4 Builder 模式
问题
生活中有着很多的Builder 的例子,个人觉得大学生活就是一个Builder 模式的最好体验:
要完成大学教育,一般将大学教育过程分成4 个学期进行,因此没有学习可以看作是构建完
整大学教育的一个部分构建过程,每个人经过这4 年的 (4 个阶段)构建过程得到的最后的
结果不一样,因为可能在四个阶段的构建中引入了很多的参数(每个人的机会和际遇不完全
相同)。
Builder 模式要解决的也正是这样的问题:当我们要创建的对象很复杂的时候(通常是
由很多其他的对象组合而成),我们要要复杂对象的创建过程和这个对象的表示(展示)分
离开来,这样做的好处就是通过一步步的进行复杂对象的构建,由于在每一步的构造过程中
可以引入参数,使得经过相同的步骤创建最后得到的对象的展示不一样。
模式选择
Builder 模式的典型结构图为:
第 18 页 共 105 页 k_eckel
----------------------- Page 19-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Builder Pattern 结构图
Builder 模式的关键是其中的Director 对象并不直接返回对象,而是通过一步步
(BuildPartA,BuildPartB,BuildPartC)来一步步进行对象的创建。当然这里Director 可以
提供一个默认的返回对象的接口 (即返回通用的复杂对象的创建,即不指定或者特定唯一指
定BuildPart 中的参数)。
实现
完整代码示例(code)
Builder 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代
码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 19 页 共 105 页 k_eckel
----------------------- Page 20-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Product.h 代码片断2:Product.cpp
//Product.h //Component.cpp
#ifndef _PRODUCT_H_ #include "Component.h"
#define _PRODUCT_H_
Component::Component()
class Product {
{
public: }
Product();
Component::~Component()
~Product(); {
void ProducePart(); }
protected: void Component::Add(const Component&
com)
private: {
}; }
class ProductPart Component* Component::GetChild(int index)
{ {
public: return 0;
ProductPart(); }
~ProductPart(); void Component::Remove(const Component&
com)
ProductPart* BuildPart(); {
protected: }
private:
};
#endif //~_PRODUCT_H_
第 20 页 共 105 页 k_eckel
----------------------- Page 21-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Builder.h 代码片断4:Builder.cpp
//Builder.h //Builder.cpp
#ifndef _BUILDER_H_ #include "Builder.h"
#define _BUILDER_H_ #include "Product.h"
#include #include
using namespace std; using namespace std;
class Product; Builder::Builder()
class Builder {
{ }
public: Builder::~Builder()
virtual ~Builder(); {
virtual void BuildPartA(const string& }
buildPara) = 0; ConcreteBuilder::ConcreteBuilder()
virtual void BuildPartB(const string& {
buildPara) = 0; }
virtual void BuildPartC(const string& ConcreteBuilder::~ConcreteBuilder()
buildPara) = 0; {
virtual Product* GetProduct() = 0; }
protected: void ConcreteBuilder::BuildPartA(const
Builder(); string& buildPara)
private: {
}; cout<<"Step1:Build
class ConcreteBuilder:public Builder PartA..."<
{ }
public: void ConcreteBuilder::BuildPartB(const
ConcreteBuilder(); string& buildPara)
~ConcreteBuilder(); {
void BuildPartA(const string& cout<<"Step1:Build
buildPara); PartB..."<
void BuildPartB(const string& buildPara); }
void BuildPartC(const string& buildPara); void ConcreteBuilder::BuildPartC(const
Product* GetProduct(); string& buildPara)
protected: {
private: cout<<"Step1:Build
}; PartC..."<
}
#endif //~_BUILDER_H_ Product* ConcreteBuilder::GetProduct()
{
BuildPartA("pre-defined");
BuildPartB("pre-defined");
BuildPartC("pre-defined");
return new Product();
}
第 21 页 共 105 页 k_eckel
----------------------- Page 22-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:Director.h 代码片断 6:Director.cpp
//Director.h //Director.cpp
#ifndef _DIRECTOR_H_
#define _DIRECTOR_H_ #include "director.h"
class Builder; #include "Builder.h"
class Director
{ Director::Director(Builder* bld)
public: {
Director(Builder* bld); _bld = bld;
~Director();
void Construct(); }
protected:
private: Director::~Director()
Builder* _bld; {
}; }
#endif //~_DIRECTOR_H_ void Director::Construct()
{
_bld->BuildPartA("user-defined");
代码片断7:main.cpp _bld->BuildPartB("user-defined");
//main.cpp _bld->BuildPartC("user-defined");
#include "Builder.h" }
#include "Product.h"
#include "Director.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Director* d = new Director(new
ConcreteBuilder());
d->Construct();
return 0;
}
第 22 页 共 105 页 k_eckel
----------------------- Page 23-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Builder 模式的示例代码中,BuildPart 的参数是通过客户程序员传入的,这里为了简单
说明问题,使用“user-defined”代替,实际的可能是在Construct 方法中传入这 3 个参数,
这样就可以得到不同的细微差别的复杂对象了。
讨论
GoF 在《设计模式》一书中给出的关于Builder 模式的意图是非常容易理解、间接的:
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示 (在示例
代码中可以通过传入不同的参数实现这一点)。
Builder 模式和 AbstractFactory 模式在功能上很相似,因为都是用来创建大的复杂的对
象,它们的区别是:Builder 模式强调的是一步步创建对象,并通过相同的创建过程可以获
得不同的结果对象,一般来说 Builder 模式中对象不是直接返回的。而在AbstractFactory 模
式中对象是直接返回的,AbstractFactory 模式强调的是为创建多个相互依赖的对象提供一个
同一的接口。
1.5 Prototype 模式
问题
关于这个模式,突然想到了小时候看的《西游记》,齐天大圣孙悟空再发飙的时候可以
通过自己头上的 3 根毛立马复制出来成千上万的孙悟空,对付小妖怪很管用 (数量最重要)。
Prototype 模式也正是提供了自我复制的功能,就是说新对象的创建可以通过已有对象进行
创建。在 C++中拷贝构造函数(Copy Constructor )曾经是很对程序员的噩梦,浅层拷贝和
深层拷贝的魔魇也是很多程序员在面试时候的快餐和系统崩溃时候的根源之一。
模式选择
Prototype 模式典型的结构图为:
第 23 页 共 105 页 k_eckel
----------------------- Page 24-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Prototype Pattern 结构图
Prototype 模式提供了一个通过已存在对象进行新对象创建的接口(Clone),Clone ()
实现和具体的实现语言相关,在C++中我们将通过拷贝构造函数实现之。
实现
完整代码示例(code)
Prototype 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 24 页 共 105 页 k_eckel
----------------------- Page 25-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Prototype.h 代码片断2:Prototype.cpp
//Prototype.h //Prototype.cpp
#include "Prototype.h"
#ifndef _PROTOTYPE_H_ #include
#define _PROTOTYPE_H_ using namespace std;
Prototype::Prototype()
class Prototype {
{ }
public: Prototype::~Prototype()
virtual ~Prototype(); {
}
virtual Prototype* Clone() const = 0; Prototype* Prototype::Clone() const
{
protected: return 0;
Prototype(); }
ConcretePrototype::ConcretePrototype()
private: {
}
}; ConcretePrototype::~ConcretePrototype()
{
class ConcretePrototype:public Prototype }
{ ConcretePrototype::ConcretePrototype(const
public: ConcretePrototype& cp)
ConcretePrototype(); {
cout<<"ConcretePrototype
ConcretePrototype(const copy ..."<
ConcretePrototype& cp); }
Prototype* ConcretePrototype::Clone() const
~ConcretePrototype(); {
return new ConcretePrototype(*this);
Prototype* Clone() const; }
protected:
private:
};
#endif //~_PROTOTYPE_H_
第 25 页 共 105 页 k_eckel
----------------------- Page 26-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp
//main.cpp
#include "Prototype.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Prototype* p = new ConcretePrototype();
Prototype* p1 = p->Clone();
return 0;
}
代码说明
Prototype 模式的结构和实现都很简单,其关键就是(C++中)拷贝构造函数的实现方
式,这也是C++实现技术层面上的事情。由于在示例代码中不涉及到深层拷贝(主要指有指
针、复合对象的情况),因此我们通过编译器提供的默认的拷贝构造函数(按位拷贝)的方
式进行实现。说明的是这一切只是为了实现简单起见,也因为本文档的重点不在拷贝构造函
数的实现技术,而在Prototype 模式本身的思想。
讨论
Prototype 模式通过复制原型(Prototype)而获得新对象创建的功能,这里Prototype 本
身就是 “对象工厂”(因为能够生产对象),实际上 Prototype 模式和 Builder 模式、
AbstractFactory 模式都是通过一个类 (对象实例)来专门负责对象的创建工作 (工厂对象),
它们之间的区别是:Builder 模式重在复杂对象的一步步创建(并不直接返回对象),
AbstractFactory 模式重在产生多个相互依赖类的对象,而 Prototype 模式重在从自身复制自
己创建新类。
2 结构型模式
2.1 Bridge 模式
问题
第 26 页 共 105 页 k_eckel
----------------------- Page 27-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
总结面向对象实际上就两句话:一是松耦合(Coupling ),二是高内聚(Cohesion)。面
向对象系统追求的目标就是尽可能地提高系统模块内部的内聚(Cohesion)、尽可能降低模
块间的耦合 (Coupling)。然而这也是面向对象设计过程中最为难把握的部分,大家肯定在
OO 系统的开发过程中遇到这样的问题:
1)客户给了你一个需求,于是使用一个类来实现(A );
2 )客户需求变化,有两个算法实现功能,于是改变设计,我们通过一个抽象的基类,
再定义两个具体类实现两个不同的算法(A1 和A2 );
3)客户又告诉我们说对于不同的操作系统,于是再抽象一个层次,作为一个抽象基类
A0,在分别为每个操作系统派生具体类(A00 和 A01,其中A00 表示原来的类 A )实现不
同操作系统上的客户需求,这样我们就有了一共4 个类。
4 )可能用户的需求又有变化,比如说又有了一种新的算法……..
5)我们陷入了一个需求变化的郁闷当中,也因此带来了类的迅速膨胀。
Bridge 模式则正是解决了这类问题。
模式选择
Bridge 模式典型的结构图为:
图2-1:Bridge Pattern 结构图
在Bridge 模式的结构图中可以看到,系统被分为两个相对独立的部分,左边是抽象部
分,右边是实现部分,这两个部分可以互相独立地进行修改:例如上面问题中的客户需求
变化,当用户需求需要从Abstraction 派生一个具体子类时候,并不需要像上面通过继承
方式实现时候需要添加子类A1 和A2 了。另外当上面问题中由于算法添加也只用改变右
边实现(添加一个具体化子类),而右边不用在变化,也不用添加具体子类了。
一切都变得elegant !
第 27 页 共 105 页 k_eckel
----------------------- Page 28-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
实现
完整代码示例(code)
Bridge 模式的实现起来并不是特别困难,这里为了方便初学者的学习和参考,将给出完
整的实现代码(所有代码采用C++实现,并在VC 6.0 下测试运行)。
代码片断 1:Abstraction.h 代码片断2:Abstraction.cpp
//Abstraction.h //Abstraction.cpp
#ifndef _ABSTRACTION_H_ #include "Abstraction.h"
#define _ABSTRACTION_H_ #include "AbstractionImp.h"
class AbstractionImp; #include
using namespace std;
class Abstraction
{ Abstraction::Abstraction()
public: {
virtual ~Abstraction();
}
virtual void Operation() = 0;
Abstraction::~Abstraction()
protected: {
Abstraction();
}
private:
RefinedAbstraction::RefinedAbstraction(Abstra
}; ctionImp* imp)
{
class RefinedAbstraction:public Abstraction _imp = imp;
{ }
public:
RefinedAbstraction(AbstractionImp* RefinedAbstraction::~RefinedAbstraction()
imp); {
~RefinedAbstraction(); }
void Operation(); void RefinedAbstraction::Operation()
{
protected: _imp->Operation();
}
private:
AbstractionImp* _imp;
};
第 28 页 共 105 页 k_eckel
#endif //~_ABSTRACTION_H_
----------------------- Page 29-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:AbstractionImp.h 代码片断4:AbstractionImp.cpp
//AbstractionImp.h //AbstractionImp.cpp
#ifndef _ABSTRACTIONIMP_H_ #include "AbstractionImp.h"
#define _ABSTRACTIONIMP_H_ #include
class AbstractionImp using namespace std;
{ AbstractionImp::AbstractionImp()
public: {
virtual ~AbstractionImp(); }
virtual void Operation() = 0; AbstractionImp::~AbstractionImp()
protected: {
AbstractionImp(); }
private: void AbstractionImp::Operation()
}; {
class ConcreteAbstractionImpA:public cout<<"AbstractionImp....imp..."<
AbstractionImp }
{ ConcreteAbstractionImpA::ConcreteAbstractio
public: nImpA()
ConcreteAbstractionImpA(); {
~ConcreteAbstractionImpA(); }
virtual void Operation(); ConcreteAbstractionImpA::~ConcreteAbstracti
protected: onImpA()
private: {
}; }
class ConcreteAbstractionImpB:public void ConcreteAbstractionImpA::Operation()
AbstractionImp {
{ cout<<"ConcreteAbstractionImpA...."<
public: ndl;
ConcreteAbstractionImpB(); }
~ConcreteAbstractionImpB(); ConcreteAbstractionImpB::ConcreteAbstractio
virtual void Operation(); nImpB()
protected: {
private: }
}; ConcreteAbstractionImpB::~ConcreteAbstracti
onImpB()
#endif //~_ABSTRACTIONIMP_H_ {
}
void ConcreteAbstractionImpB::Operation()
{
cout<<"ConcreteAbstractionImpB...."<
ndl;
}
第 29 页 共 105 页 k_eckel
----------------------- Page 30-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Abstraction.h"
#include "AbstractionImp.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
AbstractionImp* imp = new
ConcreteAbstractionImpA();
Abstraction* abs = new
RefinedAbstraction(imp);
abs->Operation();
return 0;
}
代码说明
Bridge 模式将抽象和实现分别独立实现,在代码中就是Abstraction 类和AbstractionImp
类。
讨论
Bridge 是设计模式中比较复杂和难理解的模式之一,也是OO 开发与设计中经常会用到
的模式之一。使用组合 (委托)的方式将抽象和实现彻底地解耦,这样的好处是抽象和实现
可以分别独立地变化,系统的耦合性也得到了很好的降低。
GoF 在说明Bridge 模式时,在意图中指出Bridge 模式“将抽象部分与它的实现部分分
离,使得它们可以独立地变化”。这句话很简单,但是也很复杂,连Bruce Eckel 在他的大作
《Thinking in Patterns》中说“Bridge 模式是 GoF 所讲述得最不好 (Poorly-described)的模
式”,个人觉得也正是如此。原因就在于GoF 的那句话中的 “实现”该怎么去理解:“实现”
特别是和 “抽象”放在一起的时候我们 “默认”的理解是 “实现”就是 “抽象”的具体子类
的实现,但是这里 GoF 所谓的“实现”的含义不是指抽象基类的具体子类对抽象基类中虚
函数 (接口)的实现,是和继承结合在一起的。而这里的 “实现”的含义指的是怎么去实现
第 30 页 共 105 页 k_eckel
----------------------- Page 31-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
用户的需求,并且指的是通过组合 (委托)的方式实现的,因此这里的实现不是指的继承基
类、实现基类接口,而是指的是通过对象组合实现用户的需求。理解了这一点也就理解了
Bridge 模式,理解了Bridge 模式,你的设计就会更加Elegant 了。
实际上上面使用 Bridge 模式和使用带来问题方式的解决方案的根本区别在于是通过继
承还是通过组合的方式去实现一个功能需求。因此面向对象分析和设计中有一个原则就是:
Favor Composition Over Inheritance。其原因也正在这里。
2.2 Adapter 模式
问题
Adapter 模式解决的问题在生活中经常会遇到:比如我们有一个 Team 为外界提供 S 类
服务,但是我们 Team 里面没有能够完成此项人物的member,然后我们得知有A 可以完成
这项服务 (他把这项人物重新取了个名字叫S’,并且他不对外公布他的具体实现)。为了保
证我们对外的服务类别的一致性(提供 S 服务),我们有以下两种方式解决这个问题:
1 )把B 君直接招安到我们Team 为我们工作,提供 S 服务的时候让B 君去办就是了;
2 )B 君可能在别的地方有工作,并且不准备接受我们的招安,于是我们 Team 可以想
这样一种方式解决问题:我们安排 C 君去完成这项任务,并做好工作(Money:))让A 君
工作的时候可以向B 君请教,因此 C 君就是一个复合体(提供 S 服务,但是是B 君的继承
弟子)。
实际上在软件系统设计和开发中,这种问题也会经常遇到:我们为了完成某项工作购买
了一个第三方的库来加快开发。这就带来了一个问题:我们在应用程序中已经设计好了接口,
与这个第三方提供的接口不一致,为了使得这些接口不兼容的类 (不能在一起工作)可以在
一起工作了,Adapter 模式提供了将一个类(第三方库)的接口转化为客户(购买使用者)
希望的接口。
在上面生活中问题的解决方式也就正好对应了Adapter 模式的两种类别:类模式和对象
模式。
模式选择
Adapter 模式典型的结构图为:
第 31 页 共 105 页 k_eckel
----------------------- Page 32-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Adapter Pattern (类模式)结构图
图2-2:Adapter Pattern (对象模式)结构图
在 Adapter 模式的结构图中可以看到,类模式的 Adapter 采用继承的方式复用 Adaptee
的接口,而在对象模式的Adapter 中我们则采用组合的方式实现Adaptee 的复用。有关这些
具体的实现和分析将在代码说明和讨论中给出。
实现
完整代码示例(code)
Adapter 模式的实很简单,这里为了方便初学者的学习和参考,将给出完整的实现代码
(所有代码采用C++实现,并在VC 6.0 下测试运行)。
类模式的Adapter 实现:
第 32 页 共 105 页 k_eckel
----------------------- Page 33-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Adapter.h 代码片断2:Adapter.cpp
//Adapter.h //Adapter.cpp
#ifndef _ADAPTER_H_ #include "Adapter.h"
#define _ADAPTER_H_ #include
class Target Target::Target()
{ {
public: }
Target(); Target::~Target()
virtual ~Target(); {
virtual void Request(); }
protected: void Target::Request()
private: {
}; std::cout<<"Target::Request"<
class Adaptee }
{ Adaptee::Adaptee()
public: {
Adaptee();
~Adaptee(); }
void SpecificRequest();
protected: Adaptee::~Adaptee()
private: {
}; }
class Adapter:public Target,private Adaptee void Adaptee::SpecificRequest()
{ {
public: std::cout<<"Adaptee::SpecificRequest"<<
Adapter(); std::endl;
~Adapter(); }
void Request(); Adapter::Adapter()
protected: {
private: }
}; Adapter::~Adapter()
#endif //~_ADAPTER_H_ {
}
void Adapter::Request()
{
this->SpecificRequest();
}
第 33 页 共 105 页 k_eckel
----------------------- Page 34-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Adapter.h 代码片断2:Adapter.cpp
//Adapter.h //Adapter.cpp
#ifndef _ADAPTER_H_ #include "Adapter.h"
#define _ADAPTER_H_ #include
class Target Target::Target()
{ {
public: }
Target(); Target::~Target()
virtual ~Target(); {
virtual void Request(); }
protected: void Target::Request()
private: {
}; std::cout<<"Target::Request"<
class Adaptee }
{ Adaptee::Adaptee()
public: {
Adaptee(); }
~Adaptee(); Adaptee::~Adaptee()
void SpecificRequest(); {
protected: }
private: void Adaptee::SpecificRequest()
}; {
class Adapter:public Target std::cout<<"Adaptee::SpecificRequest"<<
{ std::endl;
public: }
Adapter(Adaptee* ade); Adapter::Adapter(Adaptee* ade)
~Adapter(); {
void Request(); this->_ade = ade;
protected: }
private: Adapter::~Adapter()
Adaptee* _ade; {
}; }
#endif //~_ADAPTER_H_ void Adapter::Request()
{
_ade->SpecificRequest();
}
第 34 页 共 105 页 k_eckel
----------------------- Page 35-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp
//main.cpp
#include "Adapter.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Adaptee* ade = new Adaptee;
Target* adt = new Adapter(ade);
adt->Request();
return 0;
}
代码说明
Adapter 模式实现上比较简单,要说明的是在类模式Adapter 中,我们通过private 继承
Adaptee 获得实现继承的效果,而通过public 继承Target 获得接口继承的效果 (有关实现继
承和接口继承参见讨论部分)。
讨论
在Adapter 模式的两种模式中,有一个很重要的概念就是接口继承和实现继承的区别和
联系。接口继承和实现继承是面向对象领域的两个重要的概念,接口继承指的是通过继承,
子类获得了父类的接口,而实现继承指的是通过继承子类获得了父类的实现 (并不统共接
口)。在C++中的public 继承既是接口继承又是实现继承,因为子类在继承了父类后既可以
对外提供父类中的接口操作,又可以获得父类的接口实现。当然我们可以通过一定的方式和
技术模拟单独的接口继承和实现继承,例如我们可以通过 private 继承获得实现继承的效果
(private 继承后,父类中的接口都变为 private,当然只能是实现继承了。),通过纯抽象基
类模拟接口继承的效果,但是在 C++中pure virtual function 也可以提供默认实现,因此这是
不纯正的接口继承,但是在Java 中我们可以interface 来获得真正的接口继承了。
2.3 Decorator 模式
问题
第 35 页 共 105 页 k_eckel
----------------------- Page 36-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
在OO 设计和开发过程,可能会经常遇到以下的情况:我们需要为一个已经定义好的类
添加新的职责(操作),通常的情况我们会给定义一个新类继承自定义好的类,这样会带来
一个问题(将在本模式的讨论中给出)。通过继承的方式解决这样的情况还带来了系统的复
杂性,因为继承的深度会变得很深。
而 Decorator 提供了一种给类增加职责的方法,不是通过继承实现的,而是通过组合。
有关这些内容在讨论中进一步阐述。
模式选择
Decorator 模式典型的结构图为:
图2-1:Decorator Pattern 结构图
在 结 构 图 中 ,ConcreteComponent 和 Decorator 需 要 有 同 样 的 接 口 , 因 此
ConcreteComponent 和Decorator 有着一个共同的父类。这里有人会问,让Decorator 直接维
护一个指向ConcreteComponent 引用 (指针)不就可以达到同样的效果,答案是肯定并且是
否定的。肯定的是你可以通过这种方式实现,否定的是你不要用这种方式实现,因为通过这
种方式你就只能为这个特定的 ConcreteComponent 提供修饰操作了,当有了一个新的
ConcreteComponent 你又要去新建一个 Decorator 来实现。但是通过结构图中的
ConcreteComponent 和Decorator 有一个公共基类,就可以利用OO 中多态的思想来实现只要
是 Component 型别的对象都可以提供修饰操作的类,这种情况下你就算新建了 100 个
第 36 页 共 105 页 k_eckel
----------------------- Page 37-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
Component 型别的类 ConcreteComponent ,也都可以由 Decorator 一个类搞定。这也正是
Decorator 模式的关键和威力所在了。
当然如果你只用给Component 型别类添加一种修饰,则Decorator 这个基类就不是很必
要了。
实现
完整代码示例(code)
Decorator 模式的实现起来并不是特别困难,这里为了方便初学者的学习和参考,将给
出完整的实现代码(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 37 页 共 105 页 k_eckel
----------------------- Page 38-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Decorator.h 代码片断2:Decorator.cpp
//Decorator.h //Decorator.cpp
#ifndef _DECORATOR_H_ #include "Decorator.h"
#define _DECORATOR_H_ #include
class Component Component::Component()
{ {
public: }
virtual ~Component(); Component::~Component()
virtual void Operation(); { }
protected: void Component::Operation()
Component(); { }
private: ConcreteComponent::ConcreteComponent()
}; { }
class ConcreteComponent:public Component ConcreteComponent::~ConcreteComponent()
{ { }
public: void ConcreteComponent::Operation()
ConcreteComponent(); {
~ConcreteComponent(); std::cout<<"ConcreteComponent
void Operation(); operation..."<
protected: }
private: Decorator::Decorator(Component* com)
}; {
class Decorator:public Component this->_com = com;
{ }
public: Decorator::~Decorator()
Decorator(Component* com); {
virtual ~Decorator(); delete _com;
void Operation(); }
protected: void Decorator::Operation()
Component* _com; { }
private: ConcreteDecorator::ConcreteDecorator(Compo
}; nent* com):Decorator(com)
class ConcreteDecorator:public Decorator { }
{ ConcreteDecorator::~ConcreteDecorator()
public: { }
ConcreteDecorator(Component* com); void ConcreteDecorator::AddedBehavior()
~ConcreteDecorator(); {
void Operation(); std::cout<<"ConcreteDecorator::AddedBe
void AddedBehavior(); hacior...."<
protected: }
private: void ConcreteDecorator::Operation()
}; {
#endif //~_DECORATOR_H_ _com->Operation();
this->AddedBehavior();
}
第 38 页 共 105 页 k_eckel
----------------------- Page 39-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp
//main.cpp
#include "Decorator.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Component* com = new
ConcreteComponent();
Decorator* dec = new
ConcreteDecorator(com);
dec->Operation();
delete dec;
return 0;
}
代码说明
Decorator 模式很简单,代码本身没有什么好说明的。运行示例代码可以看到,
ConcreteDecorator 给ConcreteComponent 类添加了动作AddedBehavior 。
讨论
Decorator 模式和Composite 模式有相似的结构图,其区别在 Composite 模式已经详细讨
论过了,请参看相应文档。另外GoF 在 《设计模式》中也讨论到Decorator 和Proxy 模式有
很大程度上的相似,初学设计模式可能实在看不出这之间的一个联系和相似,并且它们在结
构图上也很不相似。实际上,在本文档 2.2 节模式选择中分析到,让 Decorator 直接拥有一
个ConcreteComponent 的引用 (指针)也可以达到修饰的功能,大家再把这种方式的结构图
画出来,就和Proxy 很相似了!
Decorator 模式和Proxy 模式的相似的地方在于它们都拥有一个指向其他对象的引用(指
针),即通过组合的方式来为对象提供更多操作(或者Decorator 模式)间接性 (Proxy 模式)。
第 39 页 共 105 页 k_eckel
----------------------- Page 40-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
但是他们的区别是,Proxy 模式会提供使用其作为代理的对象一样接口,使用代理类将其操
作都委托给Proxy 直接进行。这里可以简单理解为组合和委托之间的微妙的区别了。
Decorator 模式除了采用组合的方式取得了比采用继承方式更好的效果,Decorator 模式
还给设计带来一种“即用即付”的方式来添加职责。在OO 设计和分析经常有这样一种情况:
为了多态,通过父类指针指向其具体子类,但是这就带来另外一个问题,当具体子类要添加
新的职责,就必须向其父类添加一个这个职责的抽象接口,否则是通过父类指针是调用不到
这个方法了。这样处于高层的父类就承载了太多的特征(方法),并且继承自这个父类的所
有子类都不可避免继承了父类的这些接口,但是可能这并不是这个具体子类所需要的。而在
Decorator 模式提供了一种较好的解决方法,当需要添加一个操作的时候就可以通过
Decorator 模式来解决,你可以一步步添加新的职责。
2.4 Composite 模式
问题
在开发中,我们经常可能要递归构建树状的组合结构,Composite 模式则提供了很好的
解决方案。
模式选择
Composite 模式的典型结构图为:
第 40 页 共 105 页 k_eckel
----------------------- Page 41-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Composite Pattern 结构图
实现
完整代码示例(code)
Composite 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
代码片断 1:Component.h 代码片断2:Component.cpp
//Component.h //Component.cpp
#ifndef _COMPONENT_H_ #include "Component.h"
#define _COMPONENT_H_
Component::Component()
class Component {
{
public: }
Component();
Component::~Component()
virtual ~Component(); {
public: }
virtual void Operation() = 0;
void Component::Add(const Component&
virtual void Add(const Component& ); com)
{
virtual void Remove(const
Component& ); }
virtual Component* GetChild(int ); Component* Component::GetChild(int index)
{
protected: return 0;
}
private:
void Component::Remove(const Component&
}; com)
{
#endif //~_COMPONENT_H_
}
第 41 页 共 105 页 k_eckel
----------------------- Page 42-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Composite.h 代码片断4:Composite.cpp
//Composite.h //Composite.cpp
#include "Composite.h"
#ifndef _COMPOSITE_H_ #include "Component.h"
#define _COMPOSITE_H_ #define NULL 0 //define NULL POINTOR
Composite::Composite()
#include "Component.h" {
#include //vector::iterator itend =
using namespace std; comVec.begin();
}
class Composite:public Component Composite::~Composite()
{ {
public: }
Composite(); void Composite::Operation()
{
~Composite(); vector::iterator comIter =
comVec.begin();
public:
void Operation(); for (;comIter != comVec.end();comIter++)
{
void Add(Component* com); (*comIter)->Operation();
}
void Remove(Component* com); }
void Composite::Add(Component* com)
Component* GetChild(int index); {
comVec.push_back(com);
protected: }
void Composite::Remove(Component* com)
private: {
vector comVec; comVec.erase(&com);
}
}; Component* Composite::GetChild(int index)
{
#endif //~_COMPOSITE_H_ return comVec[index];
}
第 42 页 共 105 页 k_eckel
----------------------- Page 43-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:leaf.h 代码片断 6:Leaf.cpp
//Leaf.h //Leaf.cpp
#ifndef _LEAF_H_
#define _LEAF_H_ #include "Leaf.h"
#include
#include "Component.h" using namespace std;
class Leaf:public Component Leaf::Leaf()
{ {
public:
Leaf(); }
~Leaf(); Leaf::~Leaf()
{
void Operation();
}
protected:
void Leaf::Operation()
private: {
cout<<"Leaf operation....."<
}; }
#endif //~_LEAF_H_
代码片断7:main.cpp
//main.cpp
#include "Component.h"
#include "Composite.h"
#include "Leaf.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Leaf* l = new Leaf();
l->Operation();
Composite* com = new Composite();
com->Add(l);
com->Operation();
Component* ll = com->GetChild(0);
ll->Operation();
return 0;
}
第 43 页 共 105 页 k_eckel
----------------------- Page 44-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Composite 模式在实现中有一个问题就是要提供对于子节点(Leaf)的管理策略,这里
使用的是 STL 中的vector,可以提供其他的实现方式,如数组、链表、Hash 表等。
讨论
Composite 模式通过和Decorator 模式有着类似的结构图,但是 Composite 模式旨在构造
类,而 Decorator 模式重在不生成子类即可给对象添加职责。Decorator 模式重在修饰,而
Composite 模式重在表示。
2.5 Flyweight 模式
问题
在面向对象系统的设计何实现中,创建对象是最为常见的操作。这里面就有一个问题:
如果一个应用程序使用了太多的对象,就会造成很大的存储开销。特别是对于大量轻量级(细
粒度)的对象,比如在文档编辑器的设计过程中,我们如果为没有字母创建一个对象的话,
系统可能会因为大量的对象而造成存储开销的浪费。例如一个字母“a ”在文档中出现了
100000 次,而实际上我们可以让这一万个字母 “a”共享一个对象,当然因为在不同的位置
可能字母 “a”有不同的显示效果 (例如字体和大小等设置不同),在这种情况我们可以为将
对象的状态分为“外部状态”和“内部状态”,将可以被共享(不会变化)的状态作为内部
状态存储在对象中,而外部对象 (例如上面提到的字体、大小等)我们可以在适当的时候将
外部对象最为参数传递给对象(例如在显示的时候,将字体、大小等信息传递给对象)。
模式选择
上面解决问题的方式被称作Flyweight 模式解决上面的问题,其典型的结构图为:
第 44 页 共 105 页 k_eckel
----------------------- Page 45-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Flyweight Pattern 结构图
可以从图 2-1 中看出,Flyweight 模式中有一个类似 Factory 模式的对象构造工厂
FlyweightFactory,当客户程序员(Client )需要一个对象时候就会向 FlyweightFactory 发出
请求对象的消息 GetFlyweight ()消息,FlyweightFactory 拥有一个管理、存储对象的“仓
库”(或者叫对象池,vector 实现),GetFlyweight ()消息会遍历对象池中的对象,如果已
经存在则直接返回给 Client,否则创建一个新的对象返回给 Client 。当然可能也有不想被共
享的对象 (例如结构图中的UnshareConcreteFlyweight),但不在本模式的讲解范围,故在实
现中不给出。
实现
完整代码示例(code)
Flyweight 模式完整的实现代码(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 45 页 共 105 页 k_eckel
----------------------- Page 46-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Flyweight.h 代码片断2:Flyweight.cpp
//Flyweight.h //Flyweight.cpp
#include "Flyweight.h"
#ifndef _FLYWEIGHT_H_ #include
#define _FLYWEIGHT_H_ using namespace std;
Flyweight::Flyweight(string intrinsicState)
#include {
using namespace std; this->_intrinsicState = intrinsicState;
}
class Flyweight Flyweight::~Flyweight()
{ {
public: }
virtual ~Flyweight(); void Flyweight::Operation(const string&
extrinsicState)
virtual void Operation(const string& {
extrinsicState); }
string Flyweight::GetIntrinsicState()
string GetIntrinsicState(); {
return this->_intrinsicState;
protected: }
Flyweight(string intrinsicState); ConcreteFlyweight::ConcreteFlyweight(string
intrinsicState):Flyweight(intrinsicState)
private: {
string _intrinsicState; cout<<"ConcreteFlyweight
Build....."<
}; }
ConcreteFlyweight::~ConcreteFlyweight()
class ConcreteFlyweight:public Flyweight {
{ }
public: void ConcreteFlyweight::Operation(const
ConcreteFlyweight(string intrinsicState); string& extrinsicState)
{
~ConcreteFlyweight(); cout<<"ConcreteFlyweight: 内 蕴
["<GetIntrinsicState()<<"] 外 蕴
void Operation(const string& ["<
extrinsicState); }
protected:
private:
};
#endif //~_FLYWEIGHT_H_
第 46 页 共 105 页 k_eckel
----------------------- Page 47-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:FlyweightFactory.h 代码片断4:FlyweightFactory.cpp
//FlyweightFactory.h //FlyweightFactory.cpp
#ifndef _FLYWEIGHTFACTORY_H_ #include "FlyweightFactory.h"
#define _FLYWEIGHTFACTORY_H_ #include
#include
#include "Flyweight.h" #include
#include using namespace std;
#include
using namespace std; using namespace std;
class FlyweightFactory FlyweightFactory::FlyweightFactory()
{ {
public: }
FlyweightFactory(); FlyweightFactory::~FlyweightFactory()
{
~FlyweightFactory(); }
Flyweight*
Flyweight* GetFlyweight(const string& FlyweightFactory::GetFlyweight(const string&
key); key)
{
protected: vector::iterator it =
_fly.begin();
private:
vector _fly; for (; it != _fly.end();it++)
{
}; //找到了,就一起用,^_^
if ((*it)->GetIntrinsicState() == key)
{
#endif //~_FLYWEIGHTFACTORY_H_ cout<<"already created by
users...."<
return *it;
}
}
Flyweight* fn = new
ConcreteFlyweight(key);
_fly.push_back(fn);
return fn;
}
第 47 页 共 105 页 k_eckel
----------------------- Page 48-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Flyweight.h"
#include "FlyweightFactory.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
FlyweightFactory* fc = new
FlyweightFactory();
Flyweight* fw1 =
fc->GetFlyweight("hello");
Flyweight* fw2 =
fc->GetFlyweight("world!");
Flyweight* fw3 =
fc->GetFlyweight("hello");
return 0;
}
代码说明
Flyweight 模式在实现过程中主要是要为共享对象提供一个存放的“仓库”(对象池),
这里是通过C++ STL 中Vector 容器,当然就牵涉到STL 编程的一些问题 (Iterator 使用等)。
另外应该注意的就是对对象 “仓库”(对象池)的管理策略 (查找、插入等),这里是通过直
接的顺序遍历实现的,当然我们可以使用其他更加有效的索引策略,例如Hash 表的管理策
略,当时这些细节已经不是Flyweight 模式本身要处理的了。
讨论
我们在 State 模式和 Strategy 模式中会产生很多的对象,因此我们可以通过 Flyweight
模式来解决这个问题。
第 48 页 共 105 页 k_eckel
----------------------- Page 49-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
2.6 Facade 模式
问题
举一个生活中的小例子,大凡开过学或者毕过业的都会体会到这样一种郁闷:你要去n
个地方办理n 个手续(现在大学合并后就更加麻烦,因为可能那n 个地方都隔的比较远)。
但是实际上我们需要的就是一个最后一道手续的证明而已,对于前面的手续是怎么办的、到
什么地方去办理我们都不感兴趣。
实际上在软件系统开发中也经常回会遇到这样的情况,可能你实现了一些接口 (模块),
而这些接口 (模块)都分布在几个类中 (比如A 和B、C、D ):A 中实现了一些接口,B 中
实现一些接口 (或者A 代表一个独立模块,B、C、D 代表另一些独立模块)。然后你的客户
程序员(使用你设计的开发人员)只有很少的要知道你的不同接口到底是在那个类中实现的,
绝大多数只是想简单的组合你的A-D 的类的接口,他并不想知道这些接口在哪里实现的。
这里的客户程序员就是上面生活中想办理手续的郁闷的人!在现实生活中我们可能可以
很快想到找一个人代理所有的事情就可以解决你的问题(你只要维护和他的简单的一个接口
而已了!),在软件系统设计开发中我们可以通过一个叫做Façade 的模式来解决上面的问题。
模式选择
我们通过Facade 模式解决上面的问题,其典型的结构图为:
图2-1:Facade Pattern 结构图
Façade 模式的想法、思路和实现都非常简单,但是其思想却是非常有意义的。并且Façade
设计模式在实际的开发设计中也是应用最广、最多的模式之一。
第 49 页 共 105 页 k_eckel
----------------------- Page 50-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
一个简单的例子就是,我在开发Visual CMCS 项目 【注释1】时候,在Visual CMCS 中
我们将允许用户独立访问我们的编译子系统 (词法、语法、语义、代码生成模块),这些都
是通过特定的类实现的,我们通过使用Façade 模式给用户提供一个高层的接口,供用户在
不想了解编译器实现的情况下去使用或重用我们的设计和实现。我们将提供一个 Compile
类作为Façade 对象。
【注释1】:Visual CMCS 是笔者主要设计和完成的一个C_minus 语言 (C 语言的一个子集)
的编译系统,该系统可以生成源C-minus 程序的汇编代码(并且可以获得编译中间阶段的
各个输出,如:词法、语法、语义中间代码等。),并可执行。Visual CMCS 将作为一个对
教学、学习、研究开源的项目,它更加重要的特性是提供了一个框架(framework ),感兴
趣的开发人员可以实现、测试自己感兴趣的模块,而无需实现整个的编译系统。Visual
CMCS 采用VC++ 6.0 的界面风格,更多内容请参见Visual CMCS 网站。
实现
完整代码示例(code)
Facade 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代
码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 50 页 共 105 页 k_eckel
----------------------- Page 51-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Façade.h 代码片断2:Façade.cpp
//Facade.h //Facade.cpp
#ifndef _FACADE_H_ #include "Facade.h"
#define _FACADE_H_ #include
class Subsystem1 using namespace std;
{ Subsystem1::Subsystem1()
public: {
Subsystem1(); }
~Subsystem1(); Subsystem1::~Subsystem1()
void Operation(); {
protected: }
private: void Subsystem1::Operation()
}; {
class Subsystem2 cout<<"Subsystem1 operation.."<
{ }
public: Subsystem2::Subsystem2()
Subsystem2(); {
~Subsystem2(); }
void Operation(); Subsystem2::~Subsystem2()
protected: {
private: }
}; void Subsystem2::Operation()
class Facade {
{ cout<<"Subsystem2 operation.."<
public: }
Facade(); Facade::Facade()
~Facade(); {
void OperationWrapper(); this->_subs1 = new Subsystem1();
protected: this->_subs2 = new Subsystem2();
private: }
Subsystem1* _subs1; Facade::~Facade()
Subsystem2* _subs2; {
}; delete _subs1;
#endif //~_FACADE_H_ delete _subs2;
}
void Facade::OperationWrapper()
{
this->_subs1->Operation();
this->_subs2->Operation();
}
第 51 页 共 105 页 k_eckel
----------------------- Page 52-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp
//main.cpp
#include "Facade.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Facade* f = new Facade();
f->OperationWrapper();
return 0;
}
代码说明
Façade 模式的实现很简单,多余的解释完全是没有必要。
讨论
Façade 模式在高层提供了一个统一的接口,解耦了系统。设计模式中还有另一种模式
Mediator 也和Façade 有类似的地方。但是 Mediator 主要目的是对象间的访问的解耦(通讯
时候的协议),具体请参见Mediator 文档。
2.7 Proxy 模式
问题
至少在以下集中情况下可以用Proxy 模式解决问题:
1)创建开销大的对象时候,比如显示一幅大的图片,我们将这个创建的过程交给代理
去完成,GoF 称之为虚代理(Virtual Proxy);
2 )为网络上的对象创建一个局部的本地代理,比如要操作一个网络上的一个对象 (网
络性能不好的时候,问题尤其突出),我们将这个操纵的过程交给一个代理去完成,GoF 称
之为远程代理(Remote Proxy );
3)对对象进行控制访问的时候,比如在Jive 论坛中不同权限的用户 (如管理员、普通
用户等)将获得不同层次的操作权限,我们将这个工作交给一个代理去完成,GoF 称之为保
护代理(Protection Proxy )。
4 )智能指针 (Smart Pointer ),关于这个方面的内容,建议参看Andrew Koenig 的《C++
第 52 页 共 105 页 k_eckel
----------------------- Page 53-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
沉思录》中的第 5 章。
模式选择
Proxy 模式典型的结构图为:
图2-1:Proxy Pattern 结构图
实际上,Proxy 模式的想法非常简单,
实现
完整代码示例(code)
Proxy 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代码
(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 53 页 共 105 页 k_eckel
----------------------- Page 54-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Proxy.h 代码片断2:Proxy.cpp
//Proxy.h //Proxy.cpp
#ifndef _PROXY_H_ #include "Proxy.h"
#define _PROXY_H_ #include
class Subject using namespace std;
{ Subject::Subject()
public: {
virtual ~Subject(); }
virtual void Request() = 0; Subject::~Subject()
protected: {
Subject(); }
private: ConcreteSubject::ConcreteSubject()
}; {
class ConcreteSubject:public Subject }
{ ConcreteSubject::~ConcreteSubject()
public: {
ConcreteSubject(); }
~ConcreteSubject(); void ConcreteSubject::Request()
void Request(); {
protected: cout<<"ConcreteSubject......request...."<<
private: endl;
}; }
class Proxy Proxy::Proxy()
{ {
public: }
Proxy(); Proxy::Proxy(Subject* sub)
Proxy(Subject* sub); {
~Proxy(); _sub = sub;
void Request(); }
protected: Proxy::~Proxy()
private: {
Subject* _sub; delete _sub;
}; }
#endif //~_PROXY_H_ void Proxy::Request()
{
cout<<"Proxy request...."<
_sub->Request();
}
第 54 页 共 105 页 k_eckel
----------------------- Page 55-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp
//main.cpp
#include "Proxy.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Subject* sub = new ConcreteSubject();
Proxy* p = new Proxy(sub);
p->Request();
return 0;
}
代码说明
Proxy 模式的实现很简单,这里不做多余解释。
可以看到,示例代码运行后,p 的Request 请求实际上是交给了sub 来实际执行。
讨论
Proxy 模式最大的好处就是实现了逻辑和实现的彻底解耦。
3 行为模式
3.1 Template 模式
问题
在面向对象系统的分析与设计过程中经常会遇到这样一种情况:对于某一个业务逻辑
(算法实现)在不同的对象中有不同的细节实现,但是逻辑 (算法)的框架 (或通用的应用
算法)是相同的。Template 提供了这种情况的一个实现框架。
Template 模式是采用继承的方式实现这一点:将逻辑 (算法)框架放在抽象基类中,并
定义好细节的接口,子类中实现细节。【注释1】
【注释1】:Strategy 模式解决的是和Template 模式类似的问题,但是 Strategy 模式是将逻辑
(算法)封装到一个类中,并采取组合(委托)的方式解决这个问题。
模式选择
第 55 页 共 105 页 k_eckel
----------------------- Page 56-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
解决2.1 中问题可以采取两种模式来解决,一是Template 模式,二是 Strategy 模式。本
文当给出的是Template 模式。一个通用的Template 模式的结构图为:
图2-1:Template 模式结构图
Template 模式实际上就是利用面向对象中多态的概念实现算法实现细节和高层接口的
松耦合。可以看到 Template 模式采取的是继承方式实现这一点的,由于继承是一种强约束
性的条件,因此也给 Template 模式带来一些许多不方便的地方(有关这一点将在讨论中展
开)。
实现
完整代码示例(code)
Template 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代
码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 56 页 共 105 页 k_eckel
----------------------- Page 57-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Template.h 代码片断2:Template.cpp
//Template.h #include "Template.h"
#ifndef _TEMPLATE_H_ #include
#define _TEMPLATE_H_ using namespace std;
class AbstractClass AbstractClass::AbstractClass()
{ {
public: }
virtual ~AbstractClass(); AbstractClass::~AbstractClass()
void TemplateMethod(); {
protected: }
virtual void PrimitiveOperation1() = 0; void AbstractClass::TemplateMethod()
virtual void PrimitiveOperation2() = 0; {
AbstractClass(); this->PrimitiveOperation1();
private: this->PrimitiveOperation2();
}; }
class ConcreteClass1:public AbstractClass ConcreteClass1::ConcreteClass1()
{ {
public: }
ConcreteClass1(); ConcreteClass1::~ConcreteClass1()
~ConcreteClass1(); {
protected: }
void PrimitiveOperation1(); void ConcreteClass1::PrimitiveOperation1()
void PrimitiveOperation2(); {
private: cout<<"ConcreteClass1...PrimitiveOperat
}; ion1"<
class ConcreteClass2:public AbstractClass }
{ void ConcreteClass1::PrimitiveOperation2()
public: {
ConcreteClass2(); cout<<"ConcreteClass1...PrimitiveOperat
~ConcreteClass2(); ion2"<
protected: }
void PrimitiveOperation1(); ConcreteClass2::ConcreteClass2()
void PrimitiveOperation2(); {
private: }
}; ConcreteClass2::~ConcreteClass2()
#endif //~ TEMPLATE H {
}
void ConcreteClass2::PrimitiveOperation1()
{
cout<<"ConcreteClass2...PrimitiveOperat
ion1"<
}
void ConcreteClass2::PrimitiveOperation2()
{
cout<<"ConcreteClass2...PrimitiveOperat
第 57 页 共 105 页 ion2"<
}
----------------------- Page 58-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp//测试程序
#include "Template.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
AbstractClass* p1 = new ConcreteClass1();
AbstractClass* p2 = new ConcreteClass2();
p1->TemplateMethod();
p2->TemplateMethod();
return 0;
}
代码说明
由于 Template 模式的实现代码很简单,因此解释是多余的。其关键是将通用算法(逻
辑)封装起来,而将算法细节让子类实现(多态)。
唯一注意的是我们将原语操作 (细节算法)定义未保护 (Protected)成员,只供模板方
法调用(子类可以)。
讨论
Template 模式是很简单模式,但是也应用很广的模式。如上面的分析和实现中阐明的
Template 是采用继承的方式实现算法的异构,其关键点就是将通用算法封装在抽象基类中,
并将不同的算法细节放到子类中实现。
Template 模式获得一种反向控制结构效果,这也是面向对象系统的分析和设计中一个原
则DIP (依赖倒置:Dependency Inversion Principles )。其含义就是父类调用子类的操作 (高
层模块调用低层模块的操作),低层模块实现高层模块声明的接口。这样控制权在父类(高
层模块),低层模块反而要依赖高层模块。
继承的强制性约束关系也让 Template 模式有不足的地方,我们可以看到对于
ConcreteClass 类中的实现的原语方法 Primitive1(),是不能被别的类复用。假设我们要创建
一个 AbstractClass 的变体 AnotherAbstractClass,并且两者只是通用算法不一样,其原语操
作想复用 AbstractClass 的子类的实现。但是这是不可能实现的,因为ConcreteClass 继承自
AbstractClass,也就继承了 AbstractClass 的通用算法,AnotherAbstractClass 是复用不了
ConcreteClass 的实现,因为后者不是继承自前者。
Template 模式暴露的问题也正是继承所固有的问题,Strategy 模式则通过组合(委托)
第 58 页 共 105 页 k_eckel
----------------------- Page 59-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
来达到和Template 模式类似的效果,其代价就是空间和时间上的代价,关于 Strategy 模式的
详细讨论请参考 Strategy 模式解析。
3.2 Strategy 模式
问题
Strategy 模式和Template 模式要解决的问题是相同(类似)的,都是为了给业务逻辑(算
法)具体实现和抽象接口之间的解耦。Strategy 模式将逻辑 (算法)封装到一个类 (Context )
里面,通过组合的方式将具体算法的实现在组合对象中实现,再通过委托的方式将抽象接口
的实现委托给组合对象实现。State 模式也有类似的功能,他们之间的区别将在讨论中给出。
模式选择
Strategy 模式典型的结构图为:
图2-1:Strategy Pattern 结构图
这里的关键就是将算法的逻辑抽象接口(DoAction )封装到一个类中(Context ),再
通过委托的方式将具体的算法实现委托给具体的 Strategy 类来实现(ConcreteStrategeA
类)。
实现
完整代码示例(code)
Strategy 模式实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代码
(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 59 页 共 105 页 k_eckel
----------------------- Page 60-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:strategy.h 代码片断2:strategy.cpp
//strategy.h //Strategy.cpp
#ifndef _STRATEGY_H_ #include "Strategy.h"
#define _STRATEGY_H_ #include
class Strategy using namespace std;
{ Strategy::Strategy()
public: {
Strategy(); }
virtual ~Strategy(); Strategy::~Strategy()
virtual void AlgrithmInterface() = 0; {
protected: cout<<"~Strategy....."<
private: }
}; void Strategy::AlgrithmInterface()
class ConcreteStrategyA:public Strategy {
{ }
public: ConcreteStrategyA::ConcreteStrategyA()
ConcreteStrategyA(); {
virtual ~ConcreteStrategyA(); }
void AlgrithmInterface(); ConcreteStrategyA::~ConcreteStrategyA()
protected: {
private: cout<<"~ConcreteStrategyA....."<
}; }
class ConcreteStrategyB:public Strategy void ConcreteStrategyA::AlgrithmInterface()
{ {
public: cout<<"test
ConcreteStrategyB(); ConcreteStrategyA....."<
virtual ~ConcreteStrategyB(); }
void AlgrithmInterface(); ConcreteStrategyB::ConcreteStrategyB()
protected: {
private: }
}; ConcreteStrategyB::~ConcreteStrategyB()
#endif //~_STRATEGY_H_ {
cout<<"~ConcreteStrategyB....."<
}
void ConcreteStrategyB::AlgrithmInterface()
{
cout<<"test
ConcreteStrategyB....."<
}
第 60 页 共 105 页 k_eckel
----------------------- Page 61-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Context.h 代码片断4:Context.cpp
//Context.h //Context.cpp
#ifndef _CONTEXT_H_ #include "Context.h"
#define _CONTEXT_H_ #include "Strategy.h"
#include
class Strategy; using namespace std;
/**
*这个类是Strategy 模式的关键,也是Strategy Context::Context(Strategy* stg)
模式和Template 模式的根本区别所在。 {
*Strategy 通过 “组合”(委托)方式实现算法 _stg = stg;
(实现)的异构,而Template 模式则采取的 }
是继承的方式
*这两个模式的区别也是继承和组合两种实 Context::~Context()
现接口重用的方式的区别 {
*/ if (!_stg)
class Context delete _stg;
{ }
public:
Context(Strategy* stg); void Context::DoAction()
{
~Context(); _stg->AlgrithmInterface();
}
void DoAction();
protected:
private:
Strategy* _stg;
};
#endif //~_CONTEXT_H_
第 61 页 共 105 页 k_eckel
----------------------- Page 62-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Context.h"
#include "Strategy.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Strategy* ps;
ps = new ConcreteStrategyA();
Context* pc = new Context(ps);
pc->DoAction();
if (NULL != pc)
delete pc;
return 0;
}
代码说明
Strategy 模式的代码很直观,关键是将算法的逻辑封装到一个类中。
讨论
可以看到 Strategy 模式和 Template 模式解决了类似的问题,也正如在 Template 模式中
分析的,Strategy 模式和Template 模式实际是实现一个抽象接口的两种方式:继承和组合之
间的区别。要实现一个抽象接口,继承是一种方式:我们将抽象接口声明在基类中,将具体
的实现放在具体子类中。组合 (委托)是另外一种方式:我们将接口的实现放在被组合对象
中,将抽象接口放在组合类中。这两种方式各有优缺点,先列出来:
1)继承:
优点
1)易于修改和扩展那些被复用的实现。
缺点
1)破坏了封装性,继承中父类的实现细节暴露给子类了;
2 )“白盒”复用,原因在 1)中;
3)当父类的实现更改时,其所有子类将不得不随之改变
4 )从父类继承而来的实现在运行期间不能改变(编译期间就已经确定了)。
第 62 页 共 105 页 k_eckel
----------------------- Page 63-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
2 )组合
优点
1)“黑盒”复用,因为被包含对象的内部细节对外是不可见的;
2 )封装性好,原因为 1);
3)实现和抽象的依赖性很小(组合对象和被组合对象之间的依赖性小);
4 )可以在运行期间动态定义实现(通过一个指向相同类型的指针,典型的是抽象
基类的指针)。
缺点
1)系统中对象过多。
从上面对比中我们可以看出,组合相比继承可以取得更好的效果,因此在面向对象
的设计中的有一条很重要的原则就是:优先使用 (对象)组合,而非 (类)继承 (Favor
Composition Over Inheritance)。
实际上,继承是一种强制性很强的方式,因此也使得基类和具体子类之间的耦合
性很强。例如在Template 模式中在 ConcreteClass1 中定义的原语操作别的类是不能够直
接复用 (除非你继承自AbstractClass,具体分析请参看Template 模式文档)。而组合 (委
托)的方式则有很小的耦合性,实现 (具体实现)和接口 (抽象接口)之间的依赖性很
小,例如在本实现中,ConcreteStrategyA 的具体实现操作很容易被别的类复用,例如我
们要定义另一个 Context 类 AnotherContext,只要组合一个指向 Strategy 的指针就可以
很容易地复用ConcreteStrategyA 的实现了。
我们在Bridge 模式的问题和Bridge 模式的分析中,正是说明了继承和组合之间的
区别。请参看相应模式解析。
另外Strategy 模式很 State 模式也有相似之处,但是 State 模式注重的对象在不同的
状态下不同的操作。两者之间的区别就是 State 模式中具体实现类中有一个指向Context
的引用,而Strategy 模式则没有。具体分析请参看相应的 State 模式分析中。
3.3 State 模式
问题
每个人、事物在不同的状态下会有不同表现(动作),而一个状态又会在不同的表现下
第 63 页 共 105 页 k_eckel
----------------------- Page 64-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
转移到下一个不同的状态 (State)。最简单的一个生活中的例子就是:地铁入口处,如果你
放入正确的地铁票,门就会打开让你通过。在出口处也是验票,如果正确你就可以 ok,否
则就不让你通过(如果你动作野蛮,或许会有报警(Alarm ),:))。
有限状态自动机 (FSM )也是一个典型的状态不同,对输入有不同的响应 (状态转移)。
通常我们在实现这类系统会使用到很多的 Switch/Case 语句,Case 某种状态,发生什么动作,
Case 另外一种状态,则发生另外一种状态。但是这种实现方式至少有以下两个问题:
1)当状态数目不是很多的时候,Switch/Case 可能可以搞定。但是当状态数目很多的时
候 (实际系统中也正是如此),维护一大组的 Switch/Case 语句将是一件异常困难并且容易出
错的事情。
2 )状态逻辑和动作实现没有分离。在很多的系统实现中,动作的实现代码直接写在状
态的逻辑当中。这带来的后果就是系统的扩展性和维护得不到保证。
模式选择
State 模式就是被用来解决上面列出的两个问题的,在 State 模式中我们将状态逻辑和动
作实现进行分离。当一个操作中要维护大量的 case 分支语句,并且这些分支依赖于对象的
状态。State 模式将每一个分支都封装到独立的类中。State 模式典型的结构图为:
图2-1:State Pattern 结构图
实现
完整代码示例(code)
State 模式实现上还是有些特点,这里为了方便初学者的学习和参考,将给出完整的实
第 64 页 共 105 页 k_eckel
----------------------- Page 65-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
现代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
代码片断 1:State.h 代码片断2:State.cpp
//state.h //State.cpp
#ifndef _STATE_H_ #include "State.h"
#define _STATE_H_ #include "Context.h"
class Context; //前置声明 #include
class State using namespace std;
{ State::State()
public: {
State(); }
virtual ~State(); State::~State()
virtual void {
OperationInterface(Context* ) = 0; }
virtual void void State::OperationInterface(Context* con)
OperationChangeState(Context*) = 0; {
protected: cout<<"State::.."<
bool ChangeState(Context* con,State* }
st); bool State::ChangeState(Context* con,State* st)
{
private: con->ChangeState(st);
//bool ChangeState(Context* con,State* return true;
st); }
void State::OperationChangeState(Context*
}; con)
{
class ConcreteStateA:public State }
{ ConcreteStateA::ConcreteStateA()
public: {
ConcreteStateA(); }
ConcreteStateA::~ConcreteStateA()
virtual ~ConcreteStateA(); {
}
virtual void void
OperationInterface(Context* ); ConcreteStateA::OperationInterface(Context*
con)
virtual void {
OperationChangeState(Context*); cout<<"ConcreteStateA::OperationInterfa
ce......"<
protected: }
private:
};
第 65 页 共 105 页 k_eckel
----------------------- Page 66-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:State.h 代码片断2:State.cpp
class ConcreteStateB:public State void
{ ConcreteStateA::OperationChangeState(Contex
public: t* con)
ConcreteStateB(); {
virtual ~ConcreteStateB(); OperationInterface(con);
virtual void this->ChangeState(con,new
OperationInterface(Context* ); ConcreteStateB());
virtual void }
OperationChangeState(Context*);
protected: ConcreteStateB::ConcreteStateB()
private: {
}; }
#endif //~_STATE_H_ ConcreteStateB::~ConcreteStateB()
{
}
代码片断 3:Context.h void
//context.h ConcreteStateB::OperationInterface(Context*
#ifndef _CONTEXT_H_ con)
#define _CONTEXT_H_ {
class State; cout<<"ConcreteStateB::OperationInterfa
class Context ce......"<
{ }
public: void
Context(); ConcreteStateB::OperationChangeState(Contex
Context(State* state); t* con)
~Context(); {
void OprationInterface(); OperationInterface(con);
void OperationChangState(); this->ChangeState(con,new
protected: ConcreteStateA());
private: }
friend class State; //表明在 State 类中可
以访问Context 类的private 字段
bool ChangeState(State* state);
private:
State* _state;
};
#endif //~_CONTEXT_H_
第 66 页 共 105 页 k_eckel
----------------------- Page 67-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断4:Context.cpp
//context.cpp
#include "Context.h"
#include "State.h"
Context::Context()
{
}
Context::Context(State* state)
{
代码片断 5:main.cpp
this->_state = state;
//main.cpp
}
#include "Context.h"
Context::~Context()
#include "State.h"
{
#include
delete _state;
using namespace std;
}
int main(int argc,char* argv[])
void Context::OprationInterface()
{
{
State* st = new ConcreteStateA();
_state->OperationInterface(this);
Context* con = new Context(st);
}
con->OprationInterface();
bool Context::ChangeState(State* state)
con-> OprationInterface ();
{
con->OprationInterface();
this->_state = state;
if (con != NULL)
return true;
delete con;
}
if (st != NULL)
st = NULL;
void Context::OperationChangState()
return 0;
{
}
_state->OperationChangeState(this);
}
代码说明
State 模式在实现中,有两个关键点:
1 )将State 声明为Context 的友元类 (friend class),其作用是让 State 模式访问 Context
的protected 接口 ChangeSate ()。
2 )State 及其子类中的操作都将 Context*传入作为参数,其主要目的是 State 类可以通
过这个指针调用Context 中的方法(在本示例代码中没有体现)。这也是 State 模式和 Strategy
模式的最大区别所在。
运行了示例代码后可以获得以下的结果:连续 3 次调用了Context 的OprationInterface ()
因为每次调用后状态都会改变(A-B-A ),因此该动作随着Context 的状态的转变而获得了不同的结果。
第 67 页 共 105 页 k_eckel
----------------------- Page 68-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
讨论
State 模式的应用也非常广泛,从最高层逻辑用户接口 GUI 到最底层的通讯协议(例如
GoF 在《设计模式》中就利用 State 模式模拟实现一个TCP 连接的类。)都有其用武之地。
State 模式和 Strategy 模式又很大程度上的相似:它们都有一个Context 类,都是通过委
托 (组合)给一个具有多个派生类的多态基类实现Context 的算法逻辑。两者最大的差别就
是State 模式中派生类持有指向Context 对象的引用,并通过这个引用调用Context 中的方法,
但在 Strategy 模式中就没有这种情况。因此可以说一个 State 实例同样是 Strategy 模式的一
个实例,反之却不成立。实际上 State 模式和 Strategy 模式的区别还在于它们所关注的点不
尽相同:State 模式主要是要适应对象对于状态改变时的不同处理策略的实现,而 Strategy
则主要是具体算法和实现接口的解耦 (coupling ),Strategy 模式中并没有状态的概念 (虽然
很多时候有可以被看作是状态的概念),并且更加不关心状态的改变了。
State 模式很好地实现了对象的状态逻辑和动作实现的分离,状态逻辑分布在 State 的派
生类中实现,而动作实现则可以放在 Context 类中实现(这也是为什么 State 派生类需要拥
有一个指向Context 的指针)。这使得两者的变化相互独立,改变State 的状态逻辑可以很容
易复用Context 的动作,也可以在不影响 State 派生类的前提下创建 Context 的子类来更改或
替换动作实现。
State 模式问题主要是逻辑分散化,状态逻辑分布到了很多的 State 的子类中,很难看到
整个的状态逻辑图,这也带来了代码的维护问题。
3.4 Observer 模式
问题
Observer 模式应该可以说是应用最多、影响最广的模式之一,因为 Observer 的一个实
例Model/View/Control (MVC )结构在系统开发架构设计中有着很重要的地位和意义,MVC
实现了业务逻辑和表示层的解耦。个人也认为Observer 模式是软件开发过程中必须要掌握
和使用的模式之一。在MFC 中,Doc/View (文档视图结构)提供了实现MVC 的框架结构
(有一个从设计模式(Observer 模式)的角度分析分析Doc/View 的文章正在进一步的撰写
当中,遗憾的是时间:))。在Java 阵容中,Struts 则提供和MFC 中Doc/View 结构类似的实
第 68 页 共 105 页 k_eckel
----------------------- Page 69-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
现 MVC 的框架。另外 Java 语言本身就提供了 Observer 模式的实现接口,这将在讨论中给
出。
当然,MVC 只是Observer 模式的一个实例。Observer 模式要解决的问题为:建立一个
一(Subject )对多(Observer)的依赖关系,并且做到当 “一”变化的时候,依赖这个 “一”
的多也能够同步改变。最常见的一个例子就是:对同一组数据进行统计分析时候,我们希望
能够提供多种形式的表示(例如以表格进行统计显示、柱状图统计显示、百分比统计显示等)。
这些表示都依赖于同一组数据,我们当然需要当数据改变的时候,所有的统计的显示都能够
同时改变。Observer 模式就是解决了这一个问题。
模式选择
Observer 模式典型的结构图为:
图2-1:Observer Pattern 结构图
这里的目标 Subject 提供依赖于它的观察者 Observer 的注册 (Attach)和注销 (Detach )
操作,并且提供了使得依赖于它的所有观察者同步的操作(Notify )。观察者 Observer 则提
供一个Update 操作,注意这里的Observer 的Update 操作并不在Observer 改变了Subject 目
标状态的时候就对自己进行更新,这个更新操作要延迟到 Subject 对象发出Notify 通知所有
Observer 进行修改(调用Update )。
实现
完整代码示例(code)
Observer 模式的实现有些特点,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 69 页 共 105 页 k_eckel
----------------------- Page 70-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Subject.h 代码片断2:Subject.cpp
//Subject.h #include "Subject.h"
#ifndef _SUBJECT_H_ #include "Observer.h"
#define _SUBJECT_H_ #include
#include #include
#include using namespace std;
using namespace std; typedef string state;
typedef string State; Subject::Subject()
class Observer; { //在模板的使用之前一定要new,创建
class Subject _obvs = new list;
{ }
public: Subject::~Subject()
virtual ~Subject(); { }
virtual void Attach(Observer* obv); void Subject::Attach(Observer* obv)
virtual void Detach(Observer* obv); {
virtual void Notify(); _obvs->push_front(obv);
virtual void SetState(const State& st) = 0; }
virtual State GetState() = 0; void Subject::Detach(Observer* obv)
protected: {
Subject(); if (obv != NULL)
private: _obvs->remove(obv);
list* _obvs; }
}; void Subject::Notify()
class ConcreteSubject:public Subject {
{ list::iterator it;
public: it = _obvs->begin();
ConcreteSubject(); for (;it != _obvs->end();it++)
~ConcreteSubject(); { //关于模板和iterator 的用法
State GetState(); (*it)->Update(this);
void SetState(const State& st); }
protected: }
private: ConcreteSubject::ConcreteSubject()
State _st; {
}; _st = '/0';
}
#endif //~_SUBJECT_H_ ConcreteSubject::~ConcreteSubject()
{ }
State ConcreteSubject::GetState()
{
return _st;
}
void ConcreteSubject::SetState(const State& st)
{ _st = st;
}
第 70 页 共 105 页 k_eckel
----------------------- Page 71-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Observer.h 代码片断4:Observer.cpp
//Observer.h //Observer.cpp
#ifndef _OBSERVER_H_ #include "Observer.h"
#define _OBSERVER_H_ #include "Subject.h"
#include "Subject.h" #include
#include #include
using namespace std; using namespace std;
typedef string State; Observer::Observer()
class Observer {
{ _st = '/0';
public: }
virtual ~Observer();
virtual void Update(Subject* sub) = 0; Observer::~Observer()
virtual void PrintInfo() = 0; {
protected: }
Observer(); ConcreteObserverA::ConcreteObserverA(Subje
State _st; ct* sub)
private: {
}; _sub = sub;
class ConcreteObserverA:public Observer _sub->Attach(this);
{ }
public: ConcreteObserverA::~ConcreteObserverA()
virtual Subject* GetSubject(); {
ConcreteObserverA(Subject* sub); _sub->Detach(this);
virtual ~ConcreteObserverA(); if (_sub != 0)
//传入 Subject 作为参数,这样可以让一个 delete _sub;
View 属于多个的 Subject。 }
void Update(Subject* sub); Subject* ConcreteObserverA::GetSubject()
void PrintInfo(); {
protected: return _sub;
private: }
Subject* _sub; void ConcreteObserverA::PrintInfo()
}; {
class ConcreteObserverB:public Observer cout<<"ConcreteObserverA observer....
{ "<<_sub->GetState()<
public: }
virtual Subject* GetSubject(); void ConcreteObserverA::Update(Subject* sub)
ConcreteObserverB(Subject* sub); {
virtual ~ConcreteObserverB(); _st = sub->GetState();
//传入 Subject 作为参数,这样可以让一个 PrintInfo();
View 属于多个的 Subject。 }
void Update(Subject* sub); ConcreteObserverB::ConcreteObserverB(Subje
void PrintInfo(); ct* sub)
protected: {
private: _sub = sub;
Subject* _sub; _sub->Attach(this);
第 71 页 共 105 页 k_eckel
}; }
#endif //~_OBSERVER_H_
----------------------- Page 72-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp 代码片断4:Observer.cpp
//main.cpp ConcreteObserverB::~ConcreteObserverB()
{
#include "Subject.h" _sub->Detach(this);
#include "Observer.h" if (_sub != 0)
{
#include delete _sub;
using namespace std; }
Subject* ConcreteObserverB::GetSubject()
int main(int argc,char* argv[]) {
{ return _sub;
ConcreteSubject* sub = new }
ConcreteSubject(); void ConcreteObserverB::PrintInfo()
Observer* o1 = new {
ConcreteObserverA(sub); cout<<"ConcreteObserverB observer....
Observer* o2 = new "<<_sub->GetState()<
ConcreteObserverB(sub); }
sub->SetState("old"); void ConcreteObserverB::Update(Subject* sub)
sub->Notify(); {
sub->SetState("new"); // 也 可 以 由 _st = sub->GetState();
Observer 调用 PrintInfo();
sub->Notify(); }
return 0;
}
代码说明
在Observer 模式的实现中,Subject 维护一个list 作为存储其所有观察者的容器。每当
调用Notify 操作就遍历list 中的Observer 对象,并广播通知改变状态(调用Observer 的Update
操作)。目标的状态state 可以由 Subject 自己改变(示例),也可以由Observer 的某个操作引
起 state 的改变(可调用 Subject 的SetState 操作)。Notify 操作可以由 Subject 目标主动广播
(示例),也可以由Observer 观察者来调用(因为Observer 维护一个指向 Subject 的指针)。
运行示例程序,可以看到当 Subject 处于状态 “old”时候,依赖于它的两个观察者都显
示“old”,当目标状态改变为“new ”的时候,依赖于它的两个观察者也都改变为“new ”。
讨论
Observer 是影响极为深远的模式之一,也是在大型系统开发过程中要用到的模式之一。
除了MFC、Struts 提供了MVC 的实现框架,在Java 语言中还提供了专门的接口实现Observer
模式:通过专门的类 Observable 及 Observer 接口来实现MVC 编程模式,其UML 图可以表
第 72 页 共 105 页 k_eckel
----------------------- Page 73-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
示为:
Java 中实现MVC 的UML 图。
这里的Observer 就是观察者,Observable 则充当目标 Subject 的角色。
Observer 模式也称为发布-订阅(publish-subscribe),目标就是通知的发布者,观察者
则是通知的订阅者(接受通知)。
3.5 Memento 模式
问题
没有人想犯错误,但是没有人能够不犯错误。犯了错误一般只能改过,却很难改正 (恢
复)。世界上没有后悔药,但是我们在进行软件系统的设计时候是要给用户后悔的权利(实
际上可能也是用户要求的权利:)),我们对一些关键性的操作肯定需要提供诸如撤销(Undo )
的操作。那这个后悔药就是Memento 模式提供的。
模式选择
Memento 模式的关键就是要在不破坏封装行的前提下,捕获并保存一个类的内部
状态,这样就可以利用该保存的状态实施恢复操作。为了达到这个目标,可以在后面的实现
中看到我们采取了一定语言支持的技术。Memento 模式的典型结构图为:
第 73 页 共 105 页 k_eckel
----------------------- Page 74-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Memento Pattern 结构图
实现
完整代码示例(code)
Memento 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
代码片断 1:Memento.h 代码片断2:Memento.cpp
//Memento.h //Memento.cpp
#ifndef _MEMENTO_H_ #include "Memento.h"
#define _MEMENTO_H_ #include
#include using namespace std;
using namespace std; typedef string State;
class Memento; Originator::Originator()
class Originator {
{ _sdt = "";
public: _mt = 0;
typedef string State; }
Originator(); Originator::Originator(const State& sdt)
Originator(const State& sdt); {
~Originator(); _sdt = sdt;
Memento* CreateMemento(); _mt = 0;
void SetMemento(Memento* men); }
void RestoreToMemento(Memento* mt); Originator::~Originator()
State GetState(); {
void SetState(const State& sdt); }
void PrintState(); Memento* Originator::CreateMemento()
protected: {
private: return new Memento(_sdt);
State _sdt; }
Memento* _mt;
};
第 74 页 共 105 页 k_eckel
----------------------- Page 75-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Memento.h 代码片断2:Memento.cpp
class Memento State Originator::GetState()
{ {
public: return _sdt;
protected: }
private: void Originator::SetState(const State& sdt)
//这是最关键的地方,将 Originator 为 {
friend 类,可以访问内部信息,但是其他类不 _sdt = sdt;
能访问 }
friend class Originator; void Originator::PrintState()
typedef string State; {
Memento(); cout<_sdt<<"....."<
Memento(const State& sdt); }
~Memento(); void Originator::SetMemento(Memento* men)
void SetState(const State& sdt); {
State GetState(); }
private: void
State _sdt; Originator::RestoreToMemento(Memento* mt)
}; {
#endif //~_MEMENTO_H_ this->_sdt = mt->GetState();
}
//class Memento
代码片断 3:main.cpp Memento::Memento()
//main.cpp {
#include "Memento.h" }
#include Memento::Memento(const State& sdt)
using namespace std; {
int main(int argc,char* argv[]) _sdt = sdt;
{ }
Originator* o = new Originator(); State Memento::GetState()
o->SetState("old"); //备忘前状态 {
o->PrintState(); return _sdt;
Memento* m = o->CreateMemento(); // }
将状态备忘 void Memento::SetState(const State& sdt)
o->SetState("new"); //修改状态 {
o->PrintState(); _sdt = sdt;
o->RestoreToMemento(m); // }
恢复修改前状态
o->PrintState();
return 0;
}
第 75 页 共 105 页 k_eckel
----------------------- Page 76-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Memento 模式的关键就是friend class Originator;我们可以看到,Memento 的接口都声明
为 private,而将 Originator 声明为 Memento 的友元类。我们将 Originator 的状态保存在
Memento 类中,而将Memento 接口private 起来,也就达到了封装的功效。
在 Originator 类中我们提供了方法让用户后悔:RestoreToMemento(Memento* mt);我们可以
通过这个接口让用户后悔。在测试程序中,我们演示了这一点:Originator 的状态由old 变为 new 最
后又回到了old。
讨论
在Command 模式中,Memento 模式经常被用来维护可以撤销 (Undo )操作的状态。这
一点将在Command 模式具体说明。
3.6 Mediator 模式
问题
在面向对象系统的设计和开发过程中,对象之间的交互和通信是最为常见的情况,因为
对象间的交互本身就是一种通信。在系统比较小的时候,可能对象间的通信不是很多、对象
也比较少,我们可以直接硬编码到各个对象的方法中。但是当系统规模变大,对象的量变引
起系统复杂度的急剧增加,对象间的通信也变得越来越复杂,这时候我们就要提供一个专门
处理对象间交互和通信的类,这个中介者就是 Mediator 模式。Mediator 模式提供将对象间
的交互和通讯封装在一个类中,各个对象间的通信不必显势去声明和引用,大大降低了系统
的复杂性能 (了解一个对象总比深入熟悉n 个对象要好)。另外Mediator 模式还带来了系统
对象间的松耦合,这些将在讨论中详细给出。
模式选择
Mediator 模式典型的结构图为:
第 76 页 共 105 页 k_eckel
----------------------- Page 77-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Mediator Pattern 结构图
Mediator 模式中,每个 Colleague 维护一个 Mediator ,当要进行交互,例如图中
ConcreteColleagueA 和 ConcreteColleagueB 之间的交互就可以通过 ConcreteMediator 提供的
DoActionFromAtoB 来处理,ConcreteColleagueA 和ConcreteColleagueB 不必维护对各自的引
用,甚至它们也不知道各个的存在。Mediator 通过这种方式将多对多的通信简化为了一
(Mediator)对多(Colleague)的通信。
实现
完整代码示例(code)
Mediator 模式实现不是很困难,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 77 页 共 105 页 k_eckel
----------------------- Page 78-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Colleage.h 代码片断2:Colleage.cpp
#ifndef _COLLEAGE_H_ //Colleage.cpp
#define _COLLEAGE_H_ #include "Mediator.h"
#include #include "Colleage.h"
using namespace std; #include
class Mediator; using namespace std;
class Colleage Colleage::Colleage()
{ { }
public: Colleage::Colleage(Mediator* mdt)
virtual ~Colleage(); { this->_mdt = mdt; }
virtual void Aciton() = 0; Colleage::~Colleage()
virtual void SetState(const string& sdt) = 0; { }
virtual string GetState() = 0; ConcreteColleageA::ConcreteColleageA()
protected: { }
Colleage(); ConcreteColleageA::~ConcreteColleageA()
Colleage(Mediator* mdt); { }
Mediator* _mdt; ConcreteColleageA::ConcreteColleageA(Media
private: tor* mdt):Colleage(mdt) { }
}; string ConcreteColleageA::GetState()
class ConcreteColleageA:public Colleage { return_sdt; }
{ void ConcreteColleageA::SetState(const
public: string& sdt)
ConcreteColleageA(); { _sdt = sdt;
ConcreteColleageA(Mediator* mdt); }
~ConcreteColleageA(); void ConcreteColleageA::Aciton()
void Aciton(); {
void SetState(const string& sdt); _mdt->DoActionFromAtoB();
string GetState(); cout<<"State of ConcreteColleageB:"<<"
protected: "<GetState()<
private: }
string _sdt; ConcreteColleageB::ConcreteColleageB()
}; { }
class ConcreteColleageB:public Colleage ConcreteColleageB::~ConcreteColleageB()
{ { }
public: ConcreteColleageB::ConcreteColleageB(Media
ConcreteColleageB(); tor* mdt):Colleage(mdt)
ConcreteColleageB(Mediator* mdt); { }
~ConcreteColleageB(); void ConcreteColleageB::Aciton()
void Aciton(); {_mdt->DoActionFromBtoA();
void SetState(const string& sdt); cout<<"State of ConcreteColleageB:"<<"
string GetState(); "<GetState()<
protected: }
private: string ConcreteColleageB::GetState()
string _sdt; { return_sdt; }
}; void ConcreteColleageB::SetState(const
第 78 页 共 105 页 k_eckel
#endif //~_COLLEAGE_H_ string& sdt)
{ _sdt = sdt; }
----------------------- Page 79-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Mediator.h 代码片断4:Mediator.cpp
//Mediator.h //Mediator.cpp
#ifndef _MEDIATOR_H_ #include "Mediator.h"
#define _MEDIATOR_H_ #include "Colleage.h"
class Colleage; Mediator::Mediator()
{ }
class Mediator Mediator::~Mediator()
{ { }
public: ConcreteMediator::ConcreteMediator()
virtual ~Mediator(); { }
virtual void DoActionFromAtoB() = 0; ConcreteMediator::~ConcreteMediator()
virtual void DoActionFromBtoA() = 0; { }
protected: ConcreteMediator::ConcreteMediator(Colleage
Mediator(); * clgA,Colleage* clgB)
private: { this->_clgA = clgA;
}; this->_clgB = clgB;
class ConcreteMediator:public Mediator }
{ void ConcreteMediator::DoActionFromAtoB()
public: { _clgB->SetState(_clgA->GetState()); }
ConcreteMediator(); void
ConcreteMediator(Colleage* ConcreteMediator::SetConcreteColleageA(Coll
clgA,Colleage* clgB); eage* clgA)
~ConcreteMediator(); { this->_clgA = clgA; }
void SetConcreteColleageA(Colleage* void
clgA); ConcreteMediator::SetConcreteColleageB(Coll
void SetConcreteColleageB(Colleage* eage* clgB)
clgB); { this->_clgB = clgB; }
Colleage* GetConcreteColleageA(); Colleage*
Colleage* GetConcreteColleageB(); ConcreteMediator::GetConcreteColleageA()
void IntroColleage(Colleage* { return_clgA; }
clgA,Colleage* clgB); Colleage*
void DoActionFromAtoB(); ConcreteMediator::GetConcreteColleageB()
void DoActionFromBtoA(); { return_clgB; }
protected: void
private: ConcreteMediator::IntroColleage(Colleage*
Colleage* _clgA; clgA,Colleage* clgB)
{ this->_clgA = clgA;
Colleage* _clgB; this->_clgB = clgB;
}
}; void ConcreteMediator::DoActionFromBtoA()
#endif //~_MEDIATOR_H {
_clgA->SetState(_clgB->GetState());
}
第 79 页 共 105 页 k_eckel
----------------------- Page 80-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Mediator.h"
#include "Colleage.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
ConcreteMediator* m = new
ConcreteMediator();
ConcreteColleageA* c1 = new
ConcreteColleageA(m);
ConcreteColleageB* c2 = new
ConcreteColleageB(m);
m->IntroColleage(c1,c2);
c1->SetState("old");
c2->SetState("old");
c1->Aciton();
c2->Aciton();
cout<
c1->SetState("new");
c1->Aciton();
c2->Aciton();
cout<
c2->SetState("old");
c2->Aciton();
c1->Aciton();
return 0;
}
代码说明
Mediator 模式的实现关键就是将对象 Colleague 之间的通信封装到一个类种单独处理,
为了模拟Mediator 模式的功能,这里给每个 Colleague 对象一个 string 型别以记录其状态,
并通过状态改变来演示对象之间的交互和通信。这里主要就 Mediator 的示例运行结果给出
分析:
1 )将ConcreteColleageA 对象设置状态“old”,ConcreteColleageB 也设置状态“old”;
2 )ConcreteColleageA 对象改变状态,并在 Action 中和 ConcreteColleageB 对象进行通信,并改变
第 80 页 共 105 页 k_eckel
----------------------- Page 81-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
ConcreteColleageB 对象的状态为“new ”;
3 )ConcreteColleageB 对象改变状态,并在 Action 中和 ConcreteColleageA 对象进行通信,并改变
ConcreteColleageA 对象的状态为“new ”;
注意到,两个 Colleague 对象并不知道它交互的对象,并且也不是显示地处理交互过程,这一切都是
通过Mediator 对象完成的,示例程序运行的结果也正是证明了这一点。
讨论
Mediator 模式是一种很有用并且很常用的模式,它通过将对象间的通信封装到一个类
中,将多对多的通信转化为一对多的通信,降低了系统的复杂性。Mediator 还获得系统解耦
的特性,通过Mediator,各个Colleague 就不必维护各自通信的对象和通信协议,降低了系
统的耦合性,Mediator 和各个Colleague 就可以相互独立地修改了。
Mediator 模式还有一个很显著额特点就是将控制集中,集中的优点就是便于管理,也正
式符合了OO 设计中的每个类的职责要单一和集中的原则。
3.7 Command 模式
问题
Command 模式通过将请求封装到一个对象 (Command)中,并将请求的接受者存放到
具体的ConcreteCommand 类中 (Receiver)中,从而实现调用操作的对象和操作的具体实现
者之间的解耦。
模式选择
Command 模式的典型结构图为:
第 81 页 共 105 页 k_eckel
----------------------- Page 82-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Command Pattern 结构图
Command 模式结构图中,将请求的接收者(处理者)放到 Command 的具体子类
ConcreteCommand 中,当请求到来时 (Invoker 发出 Invoke 消息激活 Command 对象),
ConcreteCommand 将处理请求交给Receiver 对象进行处理。
实现
完整代码示例(code)
Command 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
代码片断 1:Reciever.h 代码片断2:Reciever.cpp
//Reciever.h //Reciever.cpp
#ifndef _RECIEVER_H_
#define _RECIEVER_H_ #include "Reciever.h"
class Reciever
{ #include
public:
Reciever(); Reciever::Reciever()
~Reciever(); {
void Action();
protected: }
private:
}; Reciever::~Reciever()
#endif //~_RECIEVER_H_ {
}
void Reciever::Action()
{
第 82 页 共 105 页 std::cout<<"Reciever k_eckel
action......."<
}
----------------------- Page 83-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Command.h 代码片断4:Command.cpp
//Command.h //Composite.cpp
#include "Composite.h"
#ifndef _COMMAND_H_ #include "Component.h"
#define _COMMAND_H_ #define NULL 0 //define NULL POINTOR
Composite::Composite()
class Reciever; {
//vector::iterator itend =
class Command comVec.begin();
{ }
public: Composite::~Composite()
virtual ~Command(); {
}
virtual void Excute() = 0; void Composite::Operation()
{
protected: vector::iterator comIter =
Command(); comVec.begin();
private: for (;comIter != comVec.end();comIter++)
{
}; (*comIter)->Operation();
}
class ConcreteCommand:public Command }
{ void Composite::Add(Component* com)
public: {
ConcreteCommand(Reciever* rev); comVec.push_back(com);
}
~ConcreteCommand(); void Composite::Remove(Component* com)
{
void Excute(); comVec.erase(&com);
}
protected: Component* Composite::GetChild(int index)
{
private: return comVec[index];
Reciever* _rev; }
};
#endif //~_COMMAND_H_
第 83 页 共 105 页 k_eckel
----------------------- Page 84-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:Invoker.h 代码片断 6:Invoker.cpp
//Invoker.h //Leaf.cpp
#ifndef _INVOKER_H_ #include "Leaf.h"
#define _INVOKER_H_ #include
using namespace std;
class Command;
Leaf::Leaf()
class Invoker {
{
public: }
Invoker(Command* cmd);
Leaf::~Leaf()
~Invoker(); {
void Invoke(); }
protected: void Leaf::Operation()
{
private: cout<<"Leaf operation....."<
Command* _cmd; }
};
#endif //~_INVOKER_H_
代码片断7:main.cpp
//main.cpp
#include "Command.h"
#include "Invoker.h"
#include "Reciever.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Reciever* rev = new Reciever();
Command* cmd = new
ConcreteCommand(rev);
Invoker* inv = new Invoker(cmd);
inv->Invoke();
return 0;
}
第 84 页 共 105 页 k_eckel
----------------------- Page 85-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Command 模式在实现的实现和思想都很简单,其关键就是将一个请求封装到一个类中
(Command),再提供处理对象 (Receiver ),最后Command 命令由Invoker 激活。另外,我
们可以将请求接收者的处理抽象出来作为参数传给Command 对象,实际也就是回调的机制
(Callback)来实现这一点,也就是说将处理操作方法地址(在对象内部)通过参数传递给
Command 对象,Command 对象在适当的时候 (Invoke 激活的时候)再调用该函数。这里就
要用到C++中的类成员函数指针的概念,为了方便学习,这里给出一个简单的实现源代码供
参考:
代码片断 1:Reciever.h 代码片断2:Reciever.cpp
//Reciever.h //Reciever.cpp
#ifndef _RECIEVER_H_ #include "Reciever.h"
#define _RECIEVER_H_
#include
class Reciever
{ Reciever::Reciever()
public: {
Reciever();
}
~Reciever();
Reciever::~Reciever()
void Action(); {
protected: }
private: void Reciever::Action()
{
}; std::cout<<"Reciever
action......."<
}
#endif //~_RECIEVER_H_
第 85 页 共 105 页 k_eckel
----------------------- Page 86-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Command.h 代码片断4:main.cpp
template //main.cpp
class SimpleCommand:public Command #include "Command.h"
{ #include "Reciever.h"
public: #include
typedef void (Reciever::* Action)(); using namespace std;
SimpleCommand(Reciever* rev,Action act) int main(int arc,char* argv[])
{ {
_rev = rev; Reciever* rev = new Reciever();
_act = act; Command* cmd = new
} SimpleCommand(rev,&Reciever::A
virtual void Excute() ction);
{ cmd->Excute();
(_rev->* _act)(); return 0;
} }
~SimpleCommand()
{
delete _rev;
}
protected:
private:
Reciever* _rev;
Action _act;
};
#endif //~_COMMAND_H_
注意到上面通过模板的方式来参数化请求的接收者,当然是为了简单演示。在复杂的情
况下我们会提供一个抽象Command 对象,然后创建Command 的子类以支持更复杂的处理。
讨论
Command 模式的思想非常简单,但是 Command 模式也十分常见,并且威力不小。实
际上,Command 模式关键就是提供一个抽象的Command 类,并将执行操作封装到Command
类接口中,Command 类中一般就是只是一些接口的集合,并不包含任何的数据属性(当然
在示例代码中,我们的Command 类有一个处理操作的Receiver 类的引用,但是其作用也仅
仅就是为了实现这个 Command 的Excute 接口)。这种方式在是纯正的面向对象设计者最为
鄙视的设计方式,就像OO 设计新手做系统设计的时候,仅仅将Class 作为一个关键字,将
C 种的全局函数找一个类封装起来就以为是完成了面向对象的设计。
但是世界上的事情不是绝对的,上面提到的方式在OO 设计种绝大部分的时候可能是一
第 86 页 共 105 页 k_eckel
----------------------- Page 87-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
个不成熟的体现,但是在Command 模式中却是起到了很好的效果。主要体现在:
1)Command 模式将调用操作的对象和知道如何实现该操作的对象解耦。在上面
Command 的结构图中,Invoker 对象根本就不知道具体的是那个对象在处理Excute
操作(当然要知道是 Command 类别的对象,也仅此而已)。
2 )在 Command 要增加新的处理操作对象很容易,我们可以通过创建新的继承 自
Command 的子类来实现这一点。
3)Command 模式可以和Memento 模式结合起来,支持取消的操作。
3.8 Visitor 模式
问题
在面向对象系统的开发和设计过程,经常会遇到一种情况就是需求变更(Requirement
Changing),经常我们做好的一个设计、实现了一个系统原型,咱们的客户又会有了新的需
求。我们又因此不得不去修改已有的设计,最常见就是解决方案就是给已经设计、实现好的
类添加新的方法去实现客户新的需求,这样就陷入了设计变更的梦魇:不停地打补丁,其带
来的后果就是设计根本就不可能封闭、编译永远都是整个系统代码。
Visitor 模式则提供了一种解决方案:将更新(变更)封装到一个类中(访问操作),并
由待更改类提供一个接收接口,则可达到效果。
模式选择
我们通过Visitor 模式解决上面的问题,其典型的结构图为:
第 87 页 共 105 页 k_eckel
----------------------- Page 88-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Visitor Pattern 结构图
Visitor 模式在不破坏类的前提下,为类提供增加新的新操作。Visitor 模式的关键是双分
派(Double-Dispatch )的技术 【注释1】。C++语言支持的是单分派。
在 Visitor 模式中 Accept ()操作是一个双分派的操作。具体调用哪一个具体的Accept
()操作,有两个决定因素:1)Element 的类型。因为 Accept ()是多态的操作,需要具
体的 Element 类型的子类才可以决定到底调用哪一个 Accept ()实现;2)Visitor 的类型。
Accept ()操作有一个参数(Visitor* vis),要决定了实际传进来的Visitor 的实际类别才可
以决定具体是调用哪个VisitConcrete ()实现。
实现
完整代码示例(code)
Visitor 模式的实现很简单,这里为了方便初学者的学习和参考,将给出完整的实现代码
(所有代码采用C++实现,并在VC 6.0 下测试运行)。
【注释1】:双分派意味着执行的操作将取决于请求的种类和接收者的类型。更多资料请参
考资料。
第 88 页 共 105 页 k_eckel
----------------------- Page 89-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Visitor.h 代码片断 3:Template.cpp
//Visitor.h //Element.h
#ifndef _VISITOR_H_ #ifndef _ELEMENT_H_
#define _VISITOR_H_ #define _ELEMENT_H_
class ConcreteElementA; class Visitor;
class ConcreteElementB; class Element
class Element; {
class Visitor public:
{ virtual ~Element();
public: virtual void Accept(Visitor* vis) = 0;
virtual ~Visitor(); protected:
virtual void Element();
VisitConcreteElementA(Element* elm) = 0; private:
virtual void };
VisitConcreteElementB(Element* elm) = 0; class ConcreteElementA:public Element
protected: {
Visitor(); public:
private: ConcreteElementA();
}; ~ConcreteElementA();
class ConcreteVisitorA:public Visitor void Accept(Visitor* vis);
{ protected:
public: private:
ConcreteVisitorA(); };
virtual ~ConcreteVisitorA(); class ConcreteElementB:public Element
virtual void {
VisitConcreteElementA(Element* elm); public:
virtual void ConcreteElementB();
VisitConcreteElementB(Element* elm); ~ConcreteElementB();
protected: void Accept(Visitor* vis);
private: protected:
}; private:
class ConcreteVisitorB:public Visitor };
{ #endif //~_ELEMENT_H_
public:
ConcreteVisitorB();
virtual ~ConcreteVisitorB();
virtual void
VisitConcreteElementA(Element* elm);
virtual void
VisitConcreteElementB(Element* elm);
protected:
private:
};
#endif //~_VISITOR_H_
第 89 页 共 105 页 k_eckel
----------------------- Page 90-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断2:Visitor.cpp 代码片断4:Element.cpp
//Visitor.cpp //Element.cpp
#include "Visitor.h" #include "Element.h"
#include "Element.h" #include "Visitor.h"
#include #include
using namespace std; using namespace std;
Visitor::Visitor() Element::Element()
{ {
} }
Visitor::~Visitor()
{
}
ConcreteVisitorA::ConcreteVisitorA()
{
} 代码片断4:Element.cpp
ConcreteVisitorA::~ConcreteVisitorA() Element::~Element()
{ {
} }
void void Element::Accept(Visitor* vis)
ConcreteVisitorA::VisitConcreteElementA(Ele {
ment* elm) }
{ ConcreteElementA::ConcreteElementA()
cout<<"i will visit {
ConcreteElementA..."<
} ConcreteElementA::~ConcreteElementA()
void {
ConcreteVisitorA::VisitConcreteElementB(Ele }
ment* elm) void ConcreteElementA::Accept(Visitor* vis)
{ {
cout<<"i will visit vis->VisitConcreteElementA(this);
ConcreteElementB..."<
} ConcreteElementA..."<
ConcreteVisitorB::ConcreteVisitorB() }
{ ConcreteElementB::ConcreteElementB()
} {
ConcreteVisitorB::~ConcreteVisitorB() }
{ ConcreteElementB::~ConcreteElementB()
} {
void }
ConcreteVisitorB::VisitConcreteElementA(Ele void ConcreteElementB::Accept(Visitor* vis)
ment* elm) {
{ cout<<"visiting
cout<<"i will visit ConcreteElementB..."<
ConcreteElementA..."<VisitConcreteElementB(this);
} }
第 90 页 共 105 页 k_eckel
----------------------- Page 91-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断2:Visitor.cpp 代码片断 5:main.cpp
void #include "Element.h"
ConcreteVisitorB::VisitConcreteElementB(El #include "Visitor.h"
ement* elm) #include
{ using namespace std;
cout<<"i will visit int main(int argc,char* argv[])
ConcreteElementB..."<
} Visitor* vis = new ConcreteVisitorA();
Element* elm = new
ConcreteElementA();
elm->Accept(vis);
return 0;
}
代码说明
Visitor 模式的实现过程中有以下的地方要注意:
1 )Visitor 类中的Visit ()操作的实现。
这里我们可以向Element 类仅仅提供一个接口Visit (),而在Accept ()实现中具
体调用哪一个Visit ()操作则通过函数重载 (overload)的方式实现:我们提供Visit
()的两个重载版本a)Visit(ConcreteElementA* elmA ),b )Visit(ConcreteElementB*
elmB )。
在C++中我们还可以通过RTTI (运行时类型识别:Runtime type identification )来
实现,即我们只提供一个Visit ()函数体,传入的参数为Element*型别参数 ,然
后用 RTTI 决定具体是哪一类的 ConcreteElement 参数,再决定具体要对哪个具体
类施加什么样的具体操作。【注释2】RTTI 给接口带来了简单一致性,但是付出的
代价是时间(RTTI 的实现)和代码的Hard 编码 (要进行强制转换)。
讨论
有时候我们需要为Element 提供更多的修改,这样我们就可以通过为Element 提供一系
列的
Visitor 模式可以使得Element 在不修改自己的同时增加新的操作,但是这也带来了至少
以下的两个显著问题:
1)破坏了封装性。Visitor 模式要求Visitor 可以从外部修改Element 对象的状态,这一
般通过两个方式来实现:a)Element 提供足够的public 接口,使得Visitor 可以通过
第 91 页 共 105 页 k_eckel
----------------------- Page 92-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
调用这些接口达到修改Element 状态的目的;b )Element 暴露更多的细节给Visitor,
或者让Element 提供public 的实现给Visitor (当然也给了系统中其他的对象),或者
将Visitor 声明为Element 的friend 类,仅将细节暴露给Visitor。但是无论那种情况,
特别是后者都将是破坏了封装性原则 (实际上就是C++的friend 机制得到了很多的
面向对象专家的诟病)。
2 )ConcreteElement 的扩展很困难:每增加一个Element 的子类,就要修改Visitor 的
接口,使得可以提供给这个新增加的子类的访问机制。从上面我们可以看到,或者
增加一个用于处理新增类的Visit ()接口,或者重载一个处理新增类的Visit ()操
作,或者要修改RTTI 方式实现的Visit ()实现。无论那种方式都给扩展新的Element
子类带来了困难。
3.9 Chain of Responsibility 模式
问题
熟悉VC/MFC 的都知道,VC 是“基于消息,事件驱动”,消息在VC 开发中起着举足
轻重的作用。在 MFC 中,消息是通过一个向上递交的方式进行处理,例如一个
WM_COMMAND 消息的处理流程可能为:
1) MDI 主窗口 (CMDIFrameWnd)收到命令消息WM_COMMAND,其ID 位ID_
×××;
2 ) MDI 主窗口将消息传给当前活动的MDI 子窗口(CMDIChildWnd);
3) MDI 子窗口给自己的子窗口(View )一个处理机会,将消息交给View;
4 ) View 检查自己Message Map;
5) 如果View 没有发现处理该消息的程序,则将该消息传给其对应的Document 对
象;否则View 处理,消息流程结束。
6) Document 检查自己Message Map,如果没有该消息的处理程序,则将该消息传
给其对象的DocumentTemplate 处理;否则自己处理,消息流程结束;
7) 如果在6)中消息没有得到处理,则将消息返回给View;
8) View 再传回给MDI 子窗口;
9) MDI 子窗口将该消息传给 CwinApp 对象,CwinApp 为所有无主的消息提供了
第 92 页 共 105 页 k_eckel
----------------------- Page 93-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
处理。
注明:有关MFC 消息处理更加详细信息,请参考候捷先生的《深入浅出MFC》。
MFC 提供了消息的处理的链式处理策略,处理消息的请求将沿着预先定义好的路径依
次进行处理。消息的发送者并不知道该消息最后是由那个具体对象处理的,当然它也无须也
不想知道,但是结构是该消息被某个对象处理了,或者一直到一个终极的对象进行处理了。
Chain of Responsibility 模式描述其实就是这样一类问题将可能处理一个请求的对象链
接成一个链,并将请求在这个链上传递,直到有对象处理该请求 (可能需要提供一个默认处
理所有请求的类,例如MFC 中的CwinApp 类)。
模式选择
Chain of Responsibility 模式典型的结构图为:
图2-1:Chain of Responsibility Pattern 结构图
Chain of Responsibility 模式中ConcreteHandler 将自己的后继对象(向下传递消息的对
象)记录在自己的后继表中,当一个请求到来时,ConcreteHandler 会先检查看自己有没有
匹配的处理程序,如果有就自己处理,否则传递给它的后继。当然这里示例程序中为了简化,
ConcreteHandler 只是简单的检查看自己有没有后继,有的话将请求传递给后继进行处理,
没有的话就自己处理。
实现
完整代码示例(code)
Chain of Responsibility 模式的实现比较简单,这里为了方便初学者的学习和参考,将给
出完整的实现代码(所有代码采用C++实现,并在VC 6.0 下测试运行)。
第 93 页 共 105 页 k_eckel
----------------------- Page 94-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Handle.h 代码片断2:Handle.cpp
//Handle.h //Handle.cpp
#ifndef _HANDLE_H_ #include "Handle.h"
#define _HANDLE_H_ #include
class Handle using namespace std;
{ Handle::Handle()
public: {
virtual ~Handle(); _succ = 0;
virtual void HandleRequest() = 0; }
void SetSuccessor(Handle* succ); Handle::~Handle()
Handle* GetSuccessor(); {
protected: delete _succ;
Handle(); }
Handle(Handle* succ); Handle::Handle(Handle* succ)
private: {
Handle* _succ; this->_succ = succ;
}; }
class ConcreteHandleA:public Handle void Handle::SetSuccessor(Handle* succ)
{ {
public: _succ = succ;
ConcreteHandleA(); }
~ConcreteHandleA(); Handle* Handle::GetSuccessor()
ConcreteHandleA(Handle* succ); {
void HandleRequest(); return _succ;
protected: }
private: void Handle::HandleRequest()
}; {
class ConcreteHandleB:public Handle }
{ ConcreteHandleA::ConcreteHandleA()
public: {
ConcreteHandleB(); }
~ConcreteHandleB(); ConcreteHandleA::ConcreteHandleA(Handle*
ConcreteHandleB(Handle* succ); succ):Handle(succ)
void HandleRequest(); {
protected: }
private: ConcreteHandleA::~ConcreteHandleA()
}; {
#endif //~_HANDLE_H_ }
第 94 页 共 105 页 k_eckel
----------------------- Page 95-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:main.cpp 代码片断2:Handle.cpp
//main.cpp void ConcreteHandleA::HandleRequest()
{
#include "Handle.h" if (this->GetSuccessor() != 0)
{
#include cout<<"ConcreteHandleA 我把处
理权给后继节点....."<
using namespace std;
this->GetSuccessor()->HandleRequest();
int main(int argc,char* argv[]) }
{ else
Handle* h1 = new ConcreteHandleA(); {
cout<<"ConcreteHandleA 没有后
Handle* h2 = new ConcreteHandleB(); 继了,我必须自己处理...."<
}
h1->SetSuccessor(h2); }
ConcreteHandleB::ConcreteHandleB()
h1->HandleRequest(); {
return 0; }
} ConcreteHandleB::ConcreteHandleB(Handle*
succ):Handle(succ)
{
}
ConcreteHandleB::~ConcreteHandleB()
{
}
void ConcreteHandleB::HandleRequest()
{
if (this->GetSuccessor() != 0)
{
cout<<"ConcreteHandleB 我把处
理权给后继节点....."<
this->GetSuccessor()->HandleRequest();
}
else
{
cout<<"ConcreteHandleB 没有后
继了,我必须自己处理...."<
}
}
第 95 页 共 105 页 k_eckel
----------------------- Page 96-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码说明
Chain of Responsibility 模式的示例代码实现很简单,这里就其测试结果给出说明:
ConcreteHandleA 的对象和h1 拥有一个后继 ConcreteHandleB 的对象h2,当一个请求到来时
候,h1 检查看自己有后继,于是h1 直接将请求传递给其后继h2 进行处理,h2 因为没有后
继,当请求到来时候,就只有自己提供响应了。于是程序的输出为:
1)ConcreteHandleA 我把处理权给后继节点.....;
2 )ConcreteHandleB 没有后继了,我必须自己处理....。
讨论
Chain of Responsibility 模式的最大的一个有点就是给系统降低了耦合性,请求的发送者
完全不必知道该请求会被哪个应答对象处理,极大地降低了系统的耦合性。
3.10 Iterator 模式
问题
Iterator 模式应该是最为熟悉的模式了,最简单的证明就是我在实现 Composite 模式、
Flyweight 模式、Observer 模式中就直接用到了 STL 提供的 Iterator 来遍历 Vector 或者 List
数据结构。
Iterator 模式也正是用来解决对一个聚合对象的遍历问题,将对聚合的遍历封装到一个
类中进行,这样就避免了暴露这个聚合对象的内部表示的可能。
模式选择
Iterator 模式典型的结构图为:
第 96 页 共 105 页 k_eckel
----------------------- Page 97-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
图2-1:Iterator Pattern 结构图
Iterator 模式中定义的对外接口可以视客户成员的便捷定义,但是基本的接口在图中的
Iterator 中已经给出了(参考 STL 的Iterator 就知道了)。
实现
完整代码示例(code)
Iterator 模式的实现比较简单,这里为了方便初学者的学习和参考,将给出完整的实现
代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 97 页 共 105 页 k_eckel
----------------------- Page 98-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Aggregate.h 代码片断2:Aggregate.cpp
//Aggregate.h //Aggregate.cpp
#ifndef _AGGREGATE_H_ #include "Aggregate.h"
#define _AGGREGATE_H_ #include "Iterator.h"
class Iterator; #include
typedef int Object; using namespace std;
class Interator; Aggregate::Aggregate()
class Aggregate {
{ }
public: Aggregate::~Aggregate()
virtual ~Aggregate(); {
virtual Iterator* CreateIterator() = 0; }
virtual Object GetItem(int idx) = 0; ConcreteAggregate::ConcreteAggregate()
virtual int GetSize() = 0; {
protected: for (int i = 0; i < SIZE; i++)
Aggregate(); _objs[i] = i;
private: }
}; ConcreteAggregate::~ConcreteAggregate()
class ConcreteAggregate:public Aggregate {
{ }
public: Iterator* ConcreteAggregate::CreateIterator()
enum {SIZE = 3}; {
ConcreteAggregate(); return new ConcreteIterator(this);
~ConcreteAggregate(); }
Iterator* CreateIterator(); Object ConcreteAggregate::GetItem(int idx)
Object GetItem(int idx); {
int GetSize(); if (idx < this->GetSize())
protected: return _objs[idx] ;
private: else
Object _objs[SIZE]; return -1;
}; }
#endif //~_AGGREGATE_H_ int ConcreteAggregate::GetSize()
{
return SIZE;
}
第 98 页 共 105 页 k_eckel
----------------------- Page 99-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Iterator.h 代码片断4:Iterator.cpp
//Iterator.h //Iterator.cpp
#ifndef _ITERATOR_H_ #include "Iterator.h"
#define _ITERATOR_H_ #include "Aggregate.h"
class Aggregate; #include
typedef int Object; using namespace std;
class Iterator Iterator::Iterator()
{ {
public: }
virtual ~Iterator(); Iterator::~Iterator()
virtual void First() = 0; {
virtual void Next() = 0; }
virtual bool IsDone() = 0; ConcreteIterator::ConcreteIterator(Aggregate*
virtual Object CurrentItem() = 0; ag , int idx)
protected: {
Iterator(); this->_ag = ag;
private: this->_idx = idx;
}
}; ConcreteIterator::~ConcreteIterator()
class ConcreteIterator:public Iterator {
{ }
public: Object ConcreteIterator::CurrentItem()
ConcreteIterator(Aggregate* ag , int idx = {
0); return _ag->GetItem(_idx);
~ConcreteIterator(); }
void First(); void ConcreteIterator::First()
void Next(); {
bool IsDone(); _idx = 0;
Object CurrentItem(); }
protected: void ConcreteIterator::Next()
private: {
Aggregate* _ag; if (_idx < _ag->GetSize())
_idx++;
int _idx; }
bool ConcreteIterator::IsDone()
}; {
return (_idx == _ag->GetSize());
#endif //~_ITERATOR_H_ }
第 99 页 共 105 页 k_eckel
----------------------- Page 100-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Iterator.h"
#include "Aggregate.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Aggregate* ag = new
ConcreteAggregate();
Iterator* it = new ConcreteIterator(ag);
for (; !(it->IsDone()) ; it->Next())
{
cout<CurrentItem()<
}
return 0;
}
代码说明
Iterator 模式的实现代码很简单,实际上为了更好地保护Aggregate 的状态,我们可以尽
量减小Aggregate 的public 接口,而通过将Iterator 对象声明位Aggregate 的友元来给予Iterator
一些特权,获得访问Aggregate 私有数据和方法的机会。
讨论
Iterator 模式的应用很常见,我们在开发中就经常会用到 STL 中预定义好的Iterator 来对
STL 类进行遍历(Vector、Set 等)。
3.11 Interpreter 模式
问题
第 100 页 共 105 页 k_eckel
----------------------- Page 101-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
一些应用提供了内建(Build-In )的脚本或者宏语言来让用户可以定义他们能够在系统
中进行的操作。Interpreter 模式的目的就是使用一个解释器为用户提供一个一门定义语言的
语法表示的解释器,然后通过这个解释器来解释语言中的句子。
Interpreter 模式提供了这样的一个实现语法解释器的框架,笔者曾经也正在构建一个编
译系统Visual CMCS,现在已经发布了Visual CMCS1.0 (Beta),请大家访问Visual CMCS 网
站获取详细信息。
模式选择
Interpreter 模式典型的结构图为:
图2-1:Interpreter Pattern 结构图
Interpreter 模式中,提供了TerminalExpression 和NonterminalExpression 两种表达式的解
释方式,Context 类用于为解释过程提供一些附加的信息(例如全局的信息)。
实现
完整代码示例(code)
Interpreter 模式的实现比较简单,这里为了方便初学者的学习和参考,将给出完整的实
现代码(所有代码采用 C++实现,并在VC 6.0 下测试运行)。
第 101 页 共 105 页 k_eckel
----------------------- Page 102-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 1:Context.h 代码片断2:Context.cpp
//Context.h //Context.cpp
#ifndef _CONTEXT_H_ #include "Context.h"
#define _CONTEXT_H_
Context::Context()
class Context {
{
public: }
Context();
Context::~Context()
~Context(); {
protected: }
private:
};
#endif //~_CONTEXT_H_
第 102 页 共 105 页 k_eckel
----------------------- Page 103-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 3:Interpret.h 代码片断4:Interpret.cpp
//Interpret.h //interpret.cpp
#ifndef _INTERPRET_H_ #include "Interpret.h"
#define _INTERPRET_H_ #include
#include "Context.h" using namespace std;
#include AbstractExpression::AbstractExpression()
using namespace std; {
class AbstractExpression }
{ AbstractExpression::~AbstractExpression()
public: {
virtual ~AbstractExpression(); }
virtual void Interpret(const Context& c); void AbstractExpression::Interpret(const
protected: Context& c)
AbstractExpression(); {
private: }
}; TerminalExpression::TerminalExpression(const
class TerminalExpression:public string& statement)
AbstractExpression {
{ this->_statement = statement;
public: }
TerminalExpression(const string& TerminalExpression::~TerminalExpression()
statement); {
~ TerminalExpression(); }
void Interpret(const Context& c); void TerminalExpression::Interpret(const
protected: Context& c)
private: {
string _statement; cout<_statement<<"
}; TerminalExpression"<
class NonterminalExpression:public }
AbstractExpression NonterminalExpression::NonterminalExpressio
{ n(AbstractExpression* expression,int times)
public: {
NonterminalExpression(AbstractExpressi this->_expression = expression;
on* expression,int times); this->_times = times;
~ NonterminalExpression(); }
void Interpret(const Context& c); NonterminalExpression::~NonterminalExpressi
protected: on()
private: {
AbstractExpression* _expression; }
int _times; void NonterminalExpression::Interpret(const
}; Context& c)
#endif //~_INTERPRET_H_ {
for (int i = 0; i < _times ; i++)
{
第 103 页 共 105 页 this->_expression->Interpret(c); k_eckel
}
}
----------------------- Page 104-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
代码片断 5:main.cpp
//main.cpp
#include "Context.h"
#include "Interpret.h"
#include
using namespace std;
int main(int argc,char* argv[])
{
Context* c = new Context();
AbstractExpression* te = new
TerminalExpression("hello");
AbstractExpression* nte = new
NonterminalExpression(te,2);
nte->Interpret(*c);
return 0;
}
代码说明
Interpreter 模式的示例代码很简单,只是为了说明模式的组织和使用,实际的解释
Interpret 逻辑没有实际提供。
讨论
XML 格式的数据解析是一个在应用开发中很常见并且有时候是很难处理的事情,虽然
目前很多的开发平台、语言都提供了对XML 格式数据的解析,但是例如到了移动终端设备
上,由于处理速度、计算能力、存储容量的原因解析XML 格式的数据却是很复杂的一件事
情,最近也提出了很多的移动设备的XML 格式解析器,但是总体上在项目开发时候还是需
要自己去设计和实现这一个过程(笔者就有过这个方面的痛苦经历)。
Interpreter 模式则提供了一种很好的组织和设计这种解析器的架构。
Interpreter 模式中使用类来表示文法规则,因此可以很容易实现文法的扩展。另外对于
终结符我们可以使用Flyweight 模式来实现终结符的共享。
第 104 页 共 105 页 k_eckel
----------------------- Page 105-----------------------
设计模式精解-GoF 23 种设计模式解析附C++实现源码 http://www.mscenter.edu.cn/blog/k_eckel
4 说明
Project Design Pattern Explanation with C++ Implementation (By K_Eckel)
Authorization Free Distributed but Ownership Reserved
Date 2005-04-05 (Cherry blossom is Beautiful)——2005-05-04
Test Bed MS Visual C++ 6.0
第 105 页 共 105 页 k_eckel