[NLP]使用TensorFlow实现Seq2Seq神经机器翻译(翻译)
原文链接:http://androidkt.com/nmt-seq2seq-model-in-tensorflow/
本教程将使用TensorFlow构建seq2seq(编码器 - 解码器)机器翻译模型。这个seq2seq模型的可以将英语句子翻译成德语句子。
训练模型后,输入英文句子,例如“I am a student”可以得到其德语翻译:“Ich bin ein Student”。
文章目录
- 准备翻译数据集
- 数据输入管道
- Estimator传递数据函数
- 构建NMTSeq2Seq模型
- 编码器
- 解码器
- 注意力机制
- 解码器输入
- 损失
- 推理期间
- 训练模型
- 构建Estimators
- 训练模型
- 已训练模型预测(推理)
准备翻译数据集
本教程将使用来自http://www.manythings.org/anki/ 网站的英语到德语数据集。下载数据集文件deu-eng.zip并压缩,将得到包含英语到德语短语对的deu.txt,每行一对,使用tab分隔符分割两种语言。
I won! Ich habe gewonnen!
Smile. Lächeln!
Cheers! Zum Wohl!
Freeze! Keine Bewegung!
Freeze! Stehenbleiben!
Got it? Verstanden?
Got it? Einverstanden?
He ran. Er rannte.
下载数据集后,以下是准备数据的过程:
- 首先,以保留Unicode德语字符的方式加载数据。
- 逐行分割加载的文本,然后按短语分割。
- 删除特殊字符来清理句子。
- 创建单词索引和反向单词索引(从单词→id和id→单词映射的字典)。
- 数据集清理后,删除少于2个单词或超过30个单词的文本。
在英语或德语中至少使用一次的任何单词都会添加到词汇表中。新的英语和德语文本仅使用创建的词汇表中的单词创建。两个文件词汇表中没有的单词都使用在替换。这个集合作为训练集合。单词的词汇表使用整数别名映射来进行识别。
随后数据集根据英文文件中的单词数排序,以减少用于训练的同一批次问题所需填充的影响。请访问 GitHub 获取详细实现和代码。
数据输入管道
Estimator input_fn函数创建并返回与构建模型相关的TF占位符。
def input_fn():
source = tf.placeholder(tf.int64, shape=[None, None], name='input')
target = tf.placeholder(tf.int64, shape=[None, None], name='output')
tf.identity(source[0], 'input_0')
tf.identity(target[0], 'output_0')
return {
'input': source,
'output': target,
}, None
源占位符将输入英文句子数据,其大小为 [None, None]。第一个None代表批次大小,用户设置之前批次大小是未知的。第二个None代表句子长度。每个批次的最大句子长度不同,因此不能设置为确切的数字。目标占位符同理,不过其输入时德语句子数据。
Estimator传递数据函数
def sampler():
while True:
with open(input_filename) as finput:
with open(output_filename) as foutput:
for in_line in finput:
out_line = foutput.readline()
yield {
'input': input_process(in_line, vocab)[:input_max_length - 1] + [END_TOKEN],
'output': output_process(out_line, vocab)[:output_max_length - 1] + [END_TOKEN]
}
sample_me = sampler()
def feed_fn():
inputs, outputs = [], []
input_length, output_length = 0, 0
for i in range(batch_size):
rec = next(sample_me)
inputs.append(rec['input'])
outputs.append(rec['output'])
input_length = max(input_length, len(inputs[-1]))
output_length = max(output_length, len(outputs[-1]))
# Pad me right with token.
for i in range(batch_size):
inputs[i] += [END_TOKEN] * (input_length - len(inputs[i]))
outputs[i] += [END_TOKEN] * (output_length - len(outputs[i]))
return {
'input:0': inputs,
'output:0': outputs
}
将每个批次的句子长度全设为本批次最大的长度。需要填充特殊字符。
构建NMTSeq2Seq模型
![[NLP]使用TensorFlow实现Seq2Seq神经机器翻译(翻译)_第1张图片](http://img.e-com-net.com/image/info8/7d7dd2e92be447489669c07afb273494.jpg)
编码器将源句子转换为“含义”向量,并传递给解码器以生成翻译。有两个可以背对背标记的循环神经网络,编码器和解码器。将英文句子输入编码器,然后将编码器的输出状态输入解码器,解码器将生成德语句子。
编码器
首先使用嵌入层查找单词,然后使用一个GRU单元作为编码器,并展示了使用不同的正则化技术如dropout包装GRU。然后,使用动态RNN展开编码器单元。
def seq2seq_model(features, labels, mode, params):
vocab_size = params['vocab_size']
embed_dim = params['embed_dim']
num_units = params['num_units']
output_max_length = params['output_max_length']
dropout = params['dropout']
beam_width = params['beam_width']
inp = features['input']
batch_size = tf.shape(inp)[0]
start_tokens = tf.zeros([batch_size], dtype=tf.int64)
input_lengths = tf.reduce_sum(tf.to_int32(tf.not_equal(inp, 1)), 1)
input_embed = layers.embed_sequence(
inp, vocab_size=vocab_size, embed_dim=embed_dim, scope='embed')
with tf.variable_scope('embed', reuse=True):
embeddings = tf.get_variable('embeddings')
fw_cell = tf.contrib.rnn.GRUCell(num_units=num_units)
bw_cell = tf.contrib.rnn.GRUCell(num_units=num_units)
if dropout > 0.0:
print(" %s, dropout=%g " % (type(fw_cell).__name__, dropout))
fw_cell = tf.contrib.rnn.DropoutWrapper(
cell=fw_cell, input_keep_prob=(1.0 - dropout))
bw_cell = tf.contrib.rnn.DropoutWrapper(
cell=bw_cell, input_keep_prob=(1.0 - dropout))
bd_encoder_outputs, bd_encoder_final_state = \
tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_cell, cell_bw=bw_cell,
inputs=input_embed, dtype=tf.float32)
encoder_outputs = tf.concat(bd_encoder_outputs, -1)
encoder_final_state = tf.concat(bd_encoder_final_state, -1)
...
双向编码器提供了更好的性能。这里,展示了使用单个双向层构建编码器。encoder_outputs是大小为[max_len,batch_size,num_units]的所有源隐藏状态的集合。
解码器
解码器也是GRU单元。本文使用集束搜索技术从展开的解码器生成最可能的单词序列,而不是最可能的单词。seq2seq API还有个动态解码器函数,将定义的解码器单元输入后,其将展开序列并构建解码器。
def setting_decoder(helper, scope, num_units, encoder_outputs, encoder_final_state, input_lengths,
vocab_size, batch_size, output_max_length, embeddings, start_tokens, END_TOKEN, beam_width,
reuse=None):
num_units = num_units * 2
with tf.variable_scope(scope, reuse=reuse):
if beam_width > 0:
encoder_outputs = tf.contrib.seq2seq.tile_batch(encoder_outputs, multiplier=beam_width)
encoder_final_state = tf.contrib.seq2seq.tile_batch(encoder_final_state, multiplier=beam_width)
input_lengths = tf.contrib.seq2seq.tile_batch(input_lengths, multiplier=beam_width)
# Selecting the Attention Mechanism
attention_mechanism = tf.contrib.seq2seq.LuongAttention(
num_units=num_units, memory=encoder_outputs,
memory_sequence_length=input_lengths)
# Selecting the Cell Type to use
cell = tf.contrib.rnn.GRUCell(num_units=num_units)
# Wrapping attention to the cell
attn_cell = tf.contrib.seq2seq.AttentionWrapper(
cell, attention_mechanism, attention_layer_size=num_units)
out_cell = tf.contrib.rnn.OutputProjectionWrapper(
attn_cell, vocab_size, reuse=reuse
)
if (beam_width > 0):
encoder_state = out_cell.zero_state(dtype=tf.float32,
batch_size=batch_size * beam_width).clone(
cell_state=encoder_final_state)
decoder = tf.contrib.seq2seq.BeamSearchDecoder(
cell=out_cell, embedding=embeddings,
start_tokens=tf.to_int32(start_tokens), end_token=END_TOKEN,
initial_state=encoder_state,
beam_width=beam_width,
length_penalty_weight=0.0)
outputs = tf.contrib.seq2seq.dynamic_decode(
decoder=decoder, output_time_major=False,
impute_finished=False, maximum_iterations=output_max_length
)
return outputs[0]
else:
decoder = tf.contrib.seq2seq.BasicDecoder(cell=out_cell, helper=helper,
initial_state=out_cell.zero_state(dtype=tf.float32,
batch_size=batch_size).clone(
cell_state=encoder_final_state))
outputs = tf.contrib.seq2seq.dynamic_decode(
decoder=decoder, output_time_major=False,
impute_finished=True, maximum_iterations=output_max_length
)
return outputs[0]我们将使用光束搜索技巧从展开的解码器**产生最可能的单词序列,**而不仅仅是最可能的单词。seq2seq API还有一个动态解码器功能,我向解码器单元供电,这将展开序列并构建我的解码器。
注意力机制
在编码器中,encoder_outputs是顶层的全部源隐藏状态的集合,其形状为[max_len,batch_size,num_units]。对于注意力机制,需要确保传入的“记忆”以批次数量为主轴,因此需要将attention_states转置。将source_sequence_length传递给注意力机制,以确保注意力权重被正确归一化。
解码器输入
一个显而易见的问题给解码器神经网络输入什么内容。在训练期间的处理非常简单,跟语言模型中有一点像。解码器中的每个单元产生一个字并产生输入到下一个单元的输出状态。还应该将生成的单词作为下一个单元的输入,至少训练是这样。
if mode == tf.estimator.ModeKeys.TRAIN:
# Specific For Training
output = features['output']
train_output = tf.concat([tf.expand_dims(start_tokens, 1), output], 1)
output_lengths = tf.reduce_sum(tf.to_int32(tf.not_equal(train_output, 1)), 1)
output_embed = layers.embed_sequence(
train_output, vocab_size=vocab_size, embed_dim=embed_dim, scope='embed', reuse=True)
train_helper = tf.contrib.seq2seq.TrainingHelper(output_embed, output_lengths)
train_outputs = decoder.setting_decoder(train_helper, 'decode', num_units, encoder_outputs,
encoder_final_state, input_lengths,
vocab_size, batch_size, output_max_length, embeddings,
start_tokens, END_TOKEN, beam_width, reuse=None)
pred_outputs = decoder.setting_decoder(pred_helper, 'decode', num_units, encoder_outputs,
encoder_final_state, input_lengths,
vocab_size, batch_size, output_max_length, embeddings,
start_tokens, END_TOKEN, beam_width, reuse=True)
tf.identity(train_outputs.sample_id[0], name='train_pred')
weights = tf.to_float(tf.not_equal(train_output[:, :-1], 1))
logits = tf.identity(train_outputs.rnn_output, 'logits')
...
损失
给定上述模型,就可以计算训练损失了。
loss = tf.contrib.seq2seq.sequence_loss(
logits, output, weights=weights)
train_op = layers.optimize_loss(
loss, tf.train.get_global_step(),
optimizer=params.get('optimizer', 'Adam'),
learning_rate=params.get('learning_rate', 0.001),
summaries=['loss', 'learning_rate'])
tf.identity(pred_outputs.sample_id[0], name='predictions')
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=pred_outputs.sample_id,
loss=loss,
train_op=train_op
)
weights 是与decoder_outputs大小相同的0-1矩阵 。它屏蔽目标序列长度之外的填充位置,值为0。
推理期间
实际预测时,情况更复杂点。当网络训练完成实际翻译句子时,将“I am student”输入编码器并得到输出向量,将向量载入第一个解码器单元,该单元同时需要输入单词,因此需要使用嵌入层查询,并使用动态RNN单元运行整个过程。
if mode == tf.estimator.ModeKeys.PREDICT:
# Specific for Prediction
pred_outputs = decoder.setting_decoder(pred_helper, 'decode', num_units, encoder_outputs,
encoder_final_state, input_lengths,
vocab_size, batch_size, output_max_length,
embeddings, start_tokens, END_TOKEN, beam_width,
reuse=False)
if beam_width > 0:
tf.identity(pred_outputs.predicted_ids, name='predictions')
return tf.estimator.EstimatorSpec(mode=mode, predictions=pred_outputs.predicted_ids)
else:
tf.identity(pred_outputs.sample_id[0], name='predictions')
return tf.estimator.EstimatorSpec(mode=mode, predictions=pred_outputs.sample_id)
训练模型
构建Estimators
Estimator是TensorFlow完整模型的高级表示。它完成初始化、日志、保存、恢复以及其他功能的具体过程,使用户可以专注于模型。
vocab = input_helper.load_vocab(vocab_file)
params = {
'vocab_size': len(vocab),
'batch_size': 64,
'input_max_length': 20,
'output_max_length': 20,
'embed_dim': 100,
'num_units': 256,
'dropout': 0.2,
'beam_width': 0
}
input_fn, feed_fn = input_helper.make_input_fn(
params['batch_size'],
input_file,
output_file,
vocab, params['input_max_length'], params['output_max_length'])
run_config = tf.estimator.RunConfig(
model_dir="model/seq2seq",
keep_checkpoint_max=5,
save_checkpoints_steps=500,
log_step_count_steps=10)
seq2seq_esti = tf.estimator.Estimator(
model_fn=seq2seq_model,
config=run_config,
params=params)
TensorFlow已经编写了大量毫无乐趣的样板代码,例如定期输出检查点。如果训练在24小时后崩溃,可以从崩溃的位置重新启动,最后导出模型,以便您可以将某些内容部署到服务基础架构或分布式训练。分布式训练的分布式算法也融入了estimator中。
训练模型
调用Estimator的训练方法来训练模型如下所示:
seq2seq_esti.train(
input_fn=input_fn,
hooks=[tf.train.FeedFnHook(feed_fn)],
steps=5000)

![[NLP]使用TensorFlow实现Seq2Seq神经机器翻译(翻译)_第2张图片](http://img.e-com-net.com/image/info8/30c04df0039a4781821fab1d72314829.jpg)
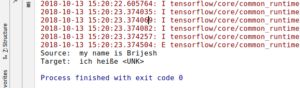
已训练模型预测(推理)
模型训练好,现在可以使用模型来翻译英文句子了。与训练时一样,使用一个函数调用进行推理。
def predict_input_fn(input_filename, vocab, input_process=tokenize_and_map):
max_len = 0.
with open(input_filename) as finput:
for in_line in finput:
max_len = max(len(in_line.split(" ")), max_len)
predict_lines = np.empty(max_len + 1, int)
with open(input_filename) as finput:
for in_line in finput:
in_line = in_line.lower()
new_line_tmp = np.array(input_process(in_line, vocab), dtype=int)
new_line = np.append(new_line_tmp, np.array([UNK_TOKEN for _ in range(max_len - len(new_line_tmp))] +
[int(END_TOKEN)], dtype=int))
predict_lines = np.vstack((predict_lines, new_line))
pred_line_tmp = np.delete(predict_lines, 0, 0)
pred_lines = np.array(pred_line_tmp)
return {'input': pred_lines}
pred_input_fn = tf.estimator.inputs.numpy_input_fn(x=inputs_with_tokens,
shuffle=False,
num_epochs=1)
predictions_obj = model.predict(input_fn=pred_input_fn)
if params['beam_width'] > 0:
final_answer = p_helper.get_out_put_from_tokens_beam_search(predictions_obj, vocab)
else:
final_answer = p_helper.get_out_put_from_tokens(predictions_obj, vocab)
with open(input_file) as finput:
for each_answer in final_answer:
question = finput.readline()
print('Source: ', question.replace('\n', '').replace('' , ''))
print('Target: ', str(each_answer).replace('' , '').replace('' , ''))
请访问GitHub以获取更多详细信息和实际代码。它将涵盖更多主题,如如何预处理数据集,如何定义输入,如何训练和进行预测。