干货 | Elasticsearch 索引设计实战指南
题记
随着 Elastic 的上市,ELK Stack 不仅在 BAT 的大公司得到长足的发展,而且在各个中小公司都得到非常广泛的应用,甚至连“婚庆网站”都开始使用 Elasticsearch 了。随之而来的是 Elasticsearch 相关部署、框架、性能优化的文章早已铺天盖地。
初学者甚至会进入幻觉——“一键部署、导入数据、检索&聚合、动态扩展, So Easy,妈妈再也不用担心我的 Elastic 学习”!
但,实际上呢?仅就 Elasticsearch 索引设计,请回答如下几个问题:
每天几百 GB 增量实时数据的TB级甚至PB级别的大索引如何设计?
分片数和副本数大小如何设计,才能提升 ES 集群的性能?
ES 的 Mapping 该如何设计,才能保证检索的高效?
检索类型 term/match/matchphrase/querystring /match_phrase _prefix /fuzzy 那么多,设计阶段如何选型呢?
分词该如何设计,才能满足复杂业务场景需求?
传统数据库中的多表关联在 ES 中如何设计?......
这么看来,没有那么 Easy,坑还是得一步步的踩出来的。
正如携程架构师 WOOD 大叔所说“做搜索容易,做好搜索相当难!”,
VIVO 搜索引擎架构师所说“ 熟练使用 ES 离做好搜索还差很远!”。
本文主结合作者近千万级开发实战经验,和大家一起深入探讨一下Elasticsearch 索引设计......
索引设计的重要性
在美团写给工程师的十条精进原则中强调了“设计优先”。无数事实证明,忽略了前期设计,往往会带来很大的延期风险。并且未经评估的不当的设计会带来巨大的维护成本,后期不得不腾出时间,专门进行优化和重构。
而 Elasticsearch 日渐成为大家非结构数据库的首选方案,项目前期良好的设计和评审是必须的,能给整个项目带来收益。
索引层面的设计在 Elasticsearch 相关产品、项目的设计阶段的作用举重若轻。
好的索引设计在整个集群规划中占据举足轻重的作用,索引的设计直接影响集群设计的好坏和复杂度。
好的索引设计应该是充分结合业务场景的时间维度和空间维度,结合业务场景充分考量增、删、改、查等全维度设计的。
好的索引设计是完全基于“设计先行,编码在后”的原则,前期会花很长时间,为的是后期工作更加顺畅,避免不必要的返工。
1、PB 级别的大索引如何设计?
单纯的普通数据索引,如果不考虑增量数据,基本上普通索引就能够满足性能要求。
我们通常的操作就是:
步骤 1:创建索引;
步骤 2:导入或者写入数据;
步骤 3:提供查询请求访问或者查询服务。
1.1 大索引的缺陷
如果每天亿万+的实时增量数据呢,基于以下几点原因,单个索引是无法满足要求的。在 360 技术访谈中也提到了大索引的设计的困惑。
1.1.1 存储大小限制维度
单个分片(Shard)实际是 Lucene 的索引,单分片能存储的最大文档数是:2,147,483,519 (= Integer.MAX_VALUE - 128)。如下命令能查看全部索引的分隔分片的文档大小:
GET _cat/shards
app_index 2 p STARTED 9443 2.8mb 127.0.0.1 Hk9wFwU
app_index 2 r UNASSIGNED
app_index 3 p STARTED 9462 2.7mb 127.0.0.1 Hk9wFwU
app_index 3 r UNASSIGNED
app_index 4 p STARTED 9520 3.5mb 127.0.0.1 Hk9wFwU
app_index 4 r UNASSIGNED
app_index 1 p STARTED 9453 2.4mb 127.0.0.1 Hk9wFwU
app_index 1 r UNASSIGNED
app_index 0 p STARTED 9365 2.3mb 127.0.0.1 Hk9wFwU
app_index 0 r UNASSIGNED
1.1.2 性能维度
当然一个索引很大的话,数据写入和查询性能都会变差。
而高效检索体现在:基于日期的检索可以直接检索对应日期的索引,无形中缩减了很大的数据规模。
比如检索:“2019-02-01”号的数据,之前的检索会是在一个月甚至更大体量的索引中进行。
现在直接检索"index_2019-02-01"的索引,效率提升好几倍。
1.1.3 风险维度
一旦一个大索引出现故障,相关的数据都会受到影响。而分成滚动索引的话,相当于做了物理隔离。
1.2 PB 级索引设计实现
综上,结合实践经验,大索引设计建议:使用模板+Rollover+Curator动态创建索引。动态索引使用效果如下:
index_2019-01-01-000001
index_2019-01-02-000002
index_2019-01-03-000003
index_2019-01-04-000004
index_2019-01-05-000005
1.2.1 使用模板统一配置索引
目的:统一管理索引,相关索引字段完全一致。
1.2.2 使用 Rollver 增量管理索引
目的:按照日期、文档数、文档存储大小三个维度进行更新索引。使用举例:
POST /logs_write/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1000,
"max_size": "5gb"
}
}
1.2.3 索引增量更新原理
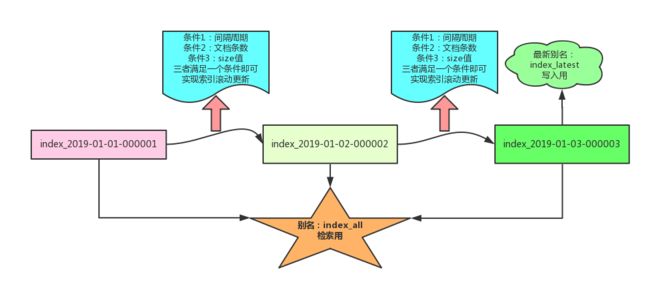
一图胜千言。
索引更新的时机是:当原始索引满足设置条件的三个中的一个的时候,就会更新为新的索引。为保证业务的全索引检索,一般采用别名机制。
在索引模板设计阶段,模板定义一个全局别名:用途是全局检索,如图所示的别名:indexall。每次更新到新的索引后,新索引指向一个用于实时新数据写入的别名,如图所示的别名:indexlatest。同时将旧索引的别名 index_latest 移除。
别名删除和新增操作举例:
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "index_2019-01-01-000001", "alias" : "index_latest" } },
{ "add" : { "index" : "index_2019-01-02-000002", "alias" : "index_latest" } }
]
}
经过如上步骤,即可完成索引的更新操作。
1.2.4 使用 curator 高效清理历史数据
目的:按照日期定期删除、归档历史数据。
一个大索引的数据删除方式只能使用 delete_by_query,由于 ES 中使用更新版本机制。删除索引后,由于没有物理删除,磁盘存储信息会不减反增。有同学就反馈 500GB+ 的索引 delete_by_query 导致负载增高的情况。
而按照日期划分索引后,不需要的历史数据可以做如下的处理。
删除——对应 delete 索引操作。
压缩——对应 shrink 操作。
段合并——对应 force_merge 操作。
而这一切,可以借助:curator 工具通过简单的配置文件结合定义任务 crontab 一键实现。
注意:7.X高版本借助iLM实现更为简单。
举例,一键删除 30 天前的历史数据:
[root@localhost .curator]# cat action.yml
actions:
1:
action: delete_indices
description: >-
Delete indices older than 30 days (based on index name), for logstash-
prefixed indices. Ignore the error if the filter does not result in an
actionable list of indices (ignore_empty_list) and exit cleanly.
options:
ignore_empty_list: True
disable_action: False
filters:
- filtertype: pattern
kind: prefix
value: logs_
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 30
2、分片数和副本数如何设计?
2.1 分片/副本认知
1、分片:分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
数据切分分片的主要目的:
(1)水平分割/缩放内容量 。
(2)跨分片(可能在多个节点上)分布和并行化操作,提高性能/吞吐量。
注意:分片一旦创建,不可以修改大小。
2、副本:它在分片/节点出现故障时提供高可用性。
副本的好处:因为可以在所有副本上并行执行搜索——因此扩展了搜索量/吞吐量。
注意:副本分片与主分片存储在集群中不同的节点。副本的大小可以通过:number_of_replicas动态修改。
2.2 分片和副本实战中设计
最常见问题答疑
2.2.1 问题 1:索引设置多少分片?
Shard 大小官方推荐值为 20-40GB, 具体原理呢?Elasticsearch 员工 Medcl 曾经讨论如下:
Lucene 底层没有这个大小的限制,20-40GB 的这个区间范围本身就比较大,经验值有时候就是拍脑袋,不一定都好使。
Elasticsearch 对数据的隔离和迁移是以分片为单位进行的,分片太大,会加大迁移成本。
一个分片就是一个 Lucene 的库,一个 Lucene 目录里面包含很多 Segment,每个 Segment 有文档数的上限,Segment 内部的文档 ID 目前使用的是 Java 的整型,也就是 2 的 31 次方,所以能够表示的总的文档数为Integer.MAXVALUE - 128 = 2^31 - 128 = 2147483647 - 1 = 2,147,483,519,也就是21.4亿条。
同样,如果你不 forcemerge 成一个 Segment,单个 shard 的文档数能超过这个数。
单个 Lucene 越大,索引会越大,查询的操作成本自然要越高,IO 压力越大,自然会影响查询体验。
具体一个分片多少数据合适,还是需要结合实际的业务数据和实际的查询来进行测试以进行评估。
综合实战+网上各种经验分享,梳理如下:
第一步:预估一下数据量的规模。一共要存储多久的数据,每天新增多少数据?两者的乘积就是总数据量。
第二步:预估分多少个索引存储。索引的划分可以根据业务需要。
第三步:考虑和衡量可扩展性,预估需要搭建几台机器的集群。存储主要看磁盘空间,假设每台机器2TB,可用:2TB0.85(磁盘实际利用率)0.85(ES 警戒水位线)。
第四步:单分片的大小建议最大设置为 30GB。此处如果是增量索引,可以结合大索引的设计部分的实现一起规划。
前三步能得出一个索引的大小。分片数考虑维度:
1)分片数 = 索引大小/分片大小经验值 30GB 。
2)分片数建议和节点数一致。设计的时候1)、2)两者权衡考虑+rollover 动态更新索引结合。
每个 shard 大小是按照经验值 30G 到 50G,因为在这个范围内查询和写入性能较好。
经验值的探推荐阅读:
Elasticsearch究竟要设置多少分片数?
探究 | Elasticsearch集群规模和容量规划的底层逻辑
2.2.2 问题 2:索引设置多少副本?
结合集群的规模,对于集群数据节点 >=2 的场景:建议副本至少设置为 1。
之前有同学出现过:副本设置为 0,长久以后会出现——数据写入向指定机器倾斜的情况。
注意:
单节点的机器设置了副本也不会生效的。副本数的设计结合数据的安全需要。对于数据安全性要求非常高的业务场景,建议做好:增强备份(结合 ES 官方备份方案)。
3、Mapping 如何设计?
3.1 Mapping 认知
Mapping 是定义文档及其包含的字段的存储和索引方式的过程。例如,使用映射来定义:
应将哪些字符串字段定义为全文检索字段;
哪些字段包含数字,日期或地理位置;
定义日期值的格式(时间戳还是日期类型等);
用于控制动态添加字段的映射的自定义规则。
3.2 设计 Mapping 的注意事项
ES 支持增加字段 //新增字段
PUT new_index
{
"mappings": {
"_doc": {
"properties": {
"status_code": {
"type": "keyword"
}
}
}
}
}
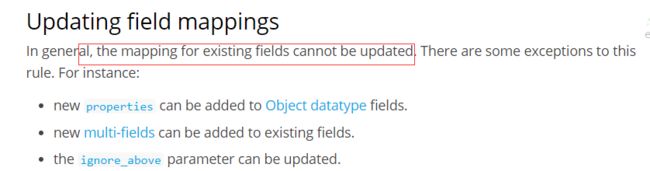
ES 不支持直接删除字段
ES 不支持直接修改字段
ES 不支持直接修改字段类型 如果非要做灵活设计,ES 有其他方案可以替换,借助reindex。但是数据量大会有性能问题,建议设计阶段综合权衡考虑。
3.3 Mapping 字段的设置流程
索引分为静态 Mapping(自定义字段)+动态 Mapping(ES 自动根据导入数据适配)。
实战业务场景建议:选用静态 Mapping,根据业务类型自己定义字段类型。
好处:
可控;
节省存储空间(默认 string 是 text+keyword,实际业务不一定需要)。
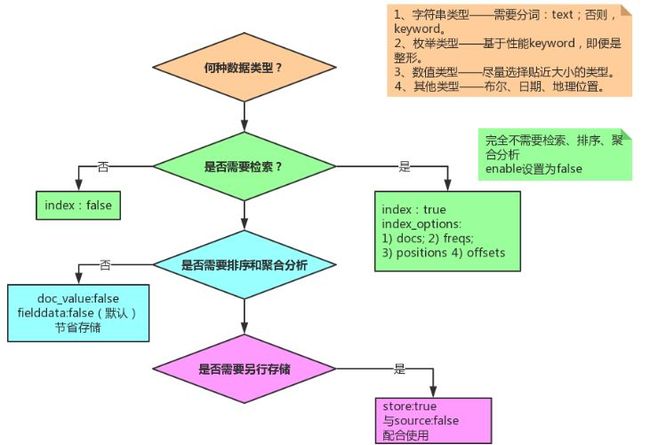
设置字段的时候,务必过一下如下图示的流程。根据实际业务需要,主要关注点:
数据类型选型;
是否需要检索;
是否需要排序+聚合分析;
是否需要另行存储。
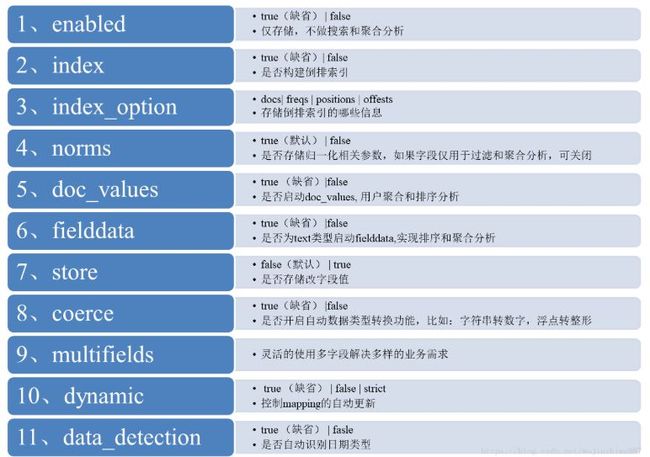
核心参数的含义,梳理如下:
3.4 Mapping 建议结合模板定义
索引 Templates——索引模板允许您定义在创建新索引时自动应用的模板。模板包括settings和Mappings以及控制是否应将模板应用于新索引。
注意:模板仅在索引创建时应用。更改模板不会对现有索引产生影响。
第1部分也有说明,针对大索引,使用模板是必须的。核心需要设置的setting(仅列举了实战中最常用、可以动态修改的)如下:
index.numberofreplicas 每个主分片具有的副本数。默认为 1(7.X 版本,低于 7.X 为 5)。
index.maxresultwindow 深度分页 rom + size 的最大值—— 默认为 10000。
index.refresh_interval 默认 1s:代表最快 1s 搜索可见;
写入时候建议设置为 -1,提高写入性能;
实战业务如果对实时性要求不高,建议设置为 30s 或者更高。
3.5 包含 Mapping 的 template 设计万能模板
以下模板已经在 7.2 验证 ok,可以直接拷贝修改后实战项目中使用。
PUT _template/test_template
{
"index_patterns": [
"test_index_*",
"test_*"
],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"max_result_window": 100000,
"refresh_interval": "30s"
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "keyword"
},
"content": {
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"available": {
"type": "boolean"
},
"review": {
"type": "nested",
"properties": {
"nickname": {
"type": "text"
},
"text": {
"type": "text"
},
"stars": {
"type": "integer"
}
}
},
"publish_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"expected_attendees": {
"type": "integer_range"
},
"ip_addr": {
"type": "ip"
},
"suggest": {
"type": "completion"
}
}
}
}
4、分词的选型
主要以 ik 来说明,最新版本的ik支持两种类型。ik_maxword 细粒度匹配,适用切分非常细的场景。ik_smart 粗粒度匹配,适用切分粗的场景。
4.1 坑 1:分词选型
实际业务中:建议适用ik_max_word分词 + match_phrase短语检索。
原因:ik_smart有覆盖不全的情况,数据量大了以后,即便 reindex 能满足要求,但面对极大的索引的情况,reindex 的耗时我们承担不起。建议ik_max_word一步到位。
4.2 坑 2:ik 要装集群的所有机器吗?
建议:安装在集群的所有节点上。
4.3 坑 3:ik 匹配不到怎么办?
方案1:扩充 ik 开源自带的词库+动态更新词库;原生的词库分词数量级很小,基础词库尽量更大更全,网上搜索一下“搜狗词库“。
动态更新词库:可以结合 mysql+ik 自带的更新词库的方式动态更新词库。
更新词库仅对新创建的索引生效,部分老数据索引建议使用 reindex 升级处理。
方案2:采用字词混合索引的方式,避免“明明存在,但是检索不到的”场景。
探究 | 明明存在,怎么搜索不出来呢?
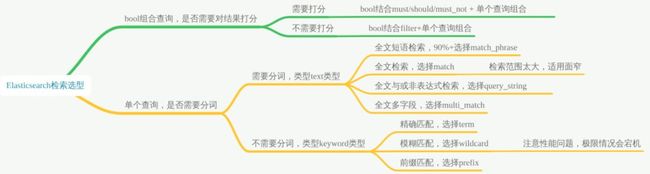
5、检索类型如何选型呢?
前提:5.X 版本之后,string 类型不再存在,取代的是text和keyword类型。
text 类型作用:分词,将大段的文字根据分词器切分成独立的词或者词组,以便全文检索。
适用于:email 内容、某产品的描述等需要分词全文检索的字段;
不适用:排序或聚合(Significant Terms 聚合例外)
keyword 类型:无需分词、整段完整精确匹配。
适用于:email 地址、住址、状态码、分类 tags。
以一个实战例子说明:
PUT zz_test
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"analyzer":"ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
GET zz_test/_mapping
PUT zz_test/doc/1
{
"title":"锤子加湿器官方致歉,难产后临时推迟一个月发货遭diss耍流氓"
}
POST zz_test/_analyze
{
"text": "锤子加湿器官方致歉,难产后临时推迟一个月发货遭diss耍流氓",
"analyzer": "ik_max_word"
}
ik_max_word的分词结果如下:
锤子、锤、子、加湿器、湿、器官、官方、方、致歉、致、歉、难产、产后、后、临时、临、时、推迟、迟、一个、 一个、 一、个月、 个、 月、 发货、发、货、遭、diss、耍流氓、耍、流氓、氓。
5.1 term 精确匹配
核心功能:不受到分词器的影响,属于完整的精确匹配。
应用场景:精确、精准匹配。
适用类型:keyword。
举例:term 最适合匹配的类型是 keyword,如下所示的精确完整匹配:
POST zz_test/_search
{
"query": {
"term": {
"title.keyword": "锤子加湿器官方致歉,难产后临时推迟一个月发货遭diss耍流氓"
}
}
}
注意:如下是匹配不到结果的。
POST zz_test/_search
{
"query": {
"term": {
"title": "锤子加湿器"
}
}
}
原因:对于 title 中的锤子加湿器,term 不会做分词拆分匹配的。且 ik_max_word 分词也是没有“锤子加湿器”这组关键词的。
5.2 prefix 前缀匹配
核心功能:前缀匹配。
应用场景:前缀自动补全的业务场景。
适用类型:keyword。
如下能匹配到文档 id 为 1 的文章。
POST zz_test/_search
{
"query": {
"prefix": {
"title.keyword": "锤子加湿器"
}
}
}
5.3 wildcard 模糊匹配
核心功能:匹配具有匹配通配符表达式 keyword 类型的文档。支持的通配符:*,它匹配任何字符序列(包括空字符序列);?,它匹配任何单个字符。
应用场景:请注意,选型务必要慎重!此查询可能很慢多组关键次的情况下可能会导致宕机,因为它需要遍历多个术语。为了防止非常慢的通配符查询,通配符不能以任何一个通配符*或?开头。
适用类型:keyword。
如下匹配,类似 MySQL 中的通配符匹配,能匹配所有包含加湿器的文章。
POST zz_test/_search
{
"query": {
"wildcard": {
"title.keyword": "*加湿器*"
}
}
}
5.4 match 分词匹配
核心功能:全文检索,分词词项匹配。
应用场景:实际业务中较少使用,原因:匹配范围太宽泛,不够准确。
适用类型:text。
如下示例,title 包含"锤子"和“加湿器”的都会被检索到。
POST zz_test/_search
{
"profile": true,
"query": {
"match": {
"title": "锤子加湿器"
}
}
}
5.5 match_phrase 短语匹配
核心功能:match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索; 只保留那些包含 全部 搜索词项,且 位置"position" 与搜索词项相同的文档。
应用场景:业务开发中 90%+ 的全文检索都会使用 match_phrase 或者 query_string 类型,而不是 match。
适用类型:text。
注意:
POST zz_test/_analyze
{
"text": "锤子加湿器",
"analyzer": "ik_max_word"
}
分词结果:
锤子, 锤,子, 加湿器, 湿,器。而:id为1的文档的分词结果:锤子, 锤, 子, 加湿器, 湿, 器官。所以,如下的检索是匹配不到结果的。
POST zz_test/_search
{
"query": {
"match_phrase": {
"title": "锤子加湿器"
}
}
}
如果想匹配到,怎么办呢?这里可以字词组合索引的形式。
推荐阅读:
探究 | 明明存在,怎么搜索不出来呢?
5.6 multi_match 多组匹配
核心功能:match query 针对多字段的升级版本。
应用场景:多字段检索。
适用类型:text。
举例:
POST zz_test/_search
{
"query": {
"multi_match": {
"query": "加湿器",
"fields": [
"title",
"content"
]
}
}
}
5.7 query_string 类型
核心功能:支持与或非表达式+其他N多配置参数。
应用场景:业务系统需要支持自定义表达式检索。
适用类型:text。
POST zz_test/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "(锤子 AND 加湿器) OR (官方 AND 道歉)"
}
}
}
5.8 bool 组合匹配
核心功能:多条件组合综合查询。
应用场景:支持多条件组合查询的场景。
适用类型:text 或者 keyword。一个 bool 过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
"filter": []
}
}
must ——所有的语句都 必须(must) 匹配,与 AND 等价。
must_not ——所有的语句都 不能(must not) 匹配,与 NOT 等价。
should ——至少有一个语句要匹配,与 OR 等价。
filter——必须匹配,运行在非评分&过滤模式。
小结:
6、多表关联如何设计?
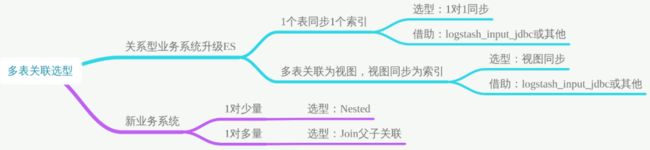
6.1 为什么会有多表关联
多表关联是被问的最多的问题之一。几乎每周都会被问到。
主要原因:常规基于关系型数据库开发,多多少少都会遇到关联查询。而关系型数据库设计的思维很容易带到 ES 的设计中。
6.2 多表关联如何实现
方案一:多表关联视图,视图同步 ES
MySQL 宽表导入 ES,使用 ES 查询+检索。适用场景:基础业务都在 MySQL,存在几十张甚至几百张表,准备同步到 ES,使用 ES 做全文检索。
将数据整合成一个宽表后写到 ES,宽表的实现可以借助关系型数据库的视图实现。
宽表处理在处理一对多、多对多关系时,会有字段冗余问题,如果借助:logstash_input_jdbc,关系型数据库如 MySQL 中的每一个字段都会自动帮你转成 ES 中对应索引下的对应 document 下的某个相同字段下的数据。
步骤 1:提前关联好数据,将关联的表建立好视图,一个索引对应你的一个视图,并确认视图中数据的正确性。
步骤 2:ES 中针对每个视图定义好索引名称及 Mapping。
步骤 3:以视图为单位通过 logstash_input_jdbc 同步到 ES 中。
方案二:1 对 1 同步 ES
MySQL+ES 结合,各取所长。适用场景:关系型数据库全量同步到 ES 存储,没有做冗余视图关联。
ES 擅长的是检索,而 MySQL 才擅长关系管理。
所以可以考虑二者结合,使用 ES 多索引建立相同的别名,针对别名检索到对应 ID 后再回 MySQL 通过关联 ID join 出需要的数据。
方案三:使用 Nested 做好关联
适用场景:1 对少量的场景。
举例:有一个文档描述了一个帖子和一个包含帖子上所有评论的内部对象评论。可以借助 Nested 实现。
Nested 类型选型——如果需要索引对象数组并保持数组中每个对象的独立性,则应使用嵌套 Nested 数据类型而不是对象 Oject 数据类型。
当使用嵌套文档时,使用通用的查询方式是无法访问到的,必须使用合适的查询方式(nested query、nested filter、nested facet等),很多场景下,使用嵌套文档的复杂度在于索引阶段对关联关系的组织拼装。
方案四:使用 ES6.X+ 父子关系 Join 做关联
适用场景:1 对多量的场景。
举例:1 个产品和供应商之间是1对N的关联关系。
Join 类型:join 数据类型是一个特殊字段,用于在同一索引的文档中创建父/子关系。关系部分定义文档中的一组可能关系,每个关系是父名称和子名称。
当使用父子文档时,使用has_child 或者has_parent做父子关联查询。
方案三、方案四选型对比:
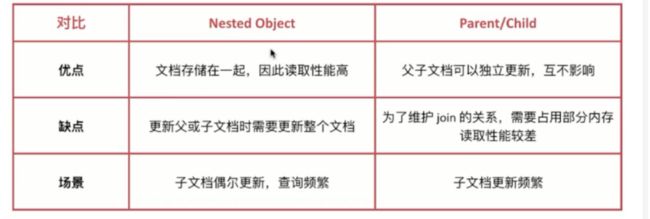
注意:方案三&方案四选型必须考虑性能问题。文档应该尽量通过合理的建模来提升检索效率。
Join 类型应该尽量避免使用。nested 类型检索使得检索效率慢几倍,父子Join 类型检索会使得检索效率慢几百倍。
尽量将业务转化为没有关联关系的文档形式,在文档建模处多下功夫,以提升检索效率。
干货 | 论Elasticsearch数据建模的重要性
干货 | Elasticsearch多表关联设计指南
小结
7、实战中遇到过的坑
如果能重来,我会如何设计 Elasticsearch 系统?
来自累计近千万实战项目设计的思考。
坑1: 数据清洗一定发生在写入 es 之前!而不是请求数据后处理,拿势必会降低请求速度和效率。
坑2:高亮不要重复造轮子,用原生就可以。
坑3:让 es 做他擅长的事,检索+不复杂的聚合,否则数据量+复杂的业务逻辑大会有性能问题。
坑4:设计的工作必须不要省!快了就是慢了,否则无休止的因设计缺陷引发的 bug 会增加团队的戳败感!
坑5:在给定时间的前提下,永远不会有完美的设计,必须相对合理的设计+重构结合,才会有相对靠谱的系统。
坑6:SSD 能提升性能,但如果系统业务逻辑非常负责,换了 SSD 未必达到预期。
坑7:由于 Elasticsearch 不支持事务 ACID 特性,数据库作为实时数据补充,对于实时数据要求严格的场景,必须同时采取双写或者同步的方式。这样,一旦实时数据出现不一致,可以通过数据库进行同步递增更新。
8、小结
本文从选题和撰写历时2周+的时间,期间反复梳理了开发过程中遇到的问题、社区/QQ 群/知识星球等中大家提问的问题。
将TOP N 大家最关注的问题也是实战中得得确确容易混淆的问题梳理出来,目的是:让更多的后来人看到,不要再走一遍弯路。
相信经过几天梳理的实战文档,能给你带来帮助!感谢您的反馈和交流。
推荐阅读:
1、百亿级日志系统架构设计及优化 http://t.cn/RsGCUGs
2.探讨理想的Elasticsearch索引设计原则。http://t.cn/Rusfb0U
公众号:铭毅天下
博客:elastic.blog.csdn.net

更短时间更快习得更多干货!