信贷违约风险评估模型(下篇):机器学习模型
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
机器学习模型
Logistic回归模型
作为一个基础模型,我们将使用scikit-learn库的LogisticRegression, 建立Logistic模型。为此,我们将使用所有的特征,我们也将填补缺失值,归一化特征。
from sklearn.preprocessing import MinMaxScaler, Imputer
# Drop the target from the training data
if 'TARGET' in app_train:
train = app_train.drop(columns = ['TARGET'])
else:
train = app_train.copy()
# Feature names
features = list(train.columns)
# Copy of the testing data
test = app_test.copy()
# Median imputation of missing values
imputer = Imputer(strategy = 'median')
# Scale each feature to 0-1
scaler = MinMaxScaler(feature_range = (0, 1))
# Fit on the training data
imputer.fit(train)
# Transform both training and testing data
train = imputer.transform(train)
test = imputer.transform(app_test)
# Repeat with the scaler
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
Training data shape: (307511, 240)
Testing data shape: (48744, 240)
我们只改变一个默认参数,正则参数C, 它用来控制过度拟合程度,降低它的值将减小过度拟合度。在这里,我们使用常见的scikit-learn建模语法规则:
-
产生模型
-
使用
.fit训练模型 -
使用
.predict_proba在检验集上预测客户不还款的概率
from sklearn.linear_model import LogisticRegression
# Make the model with the specified regularization parameter
log_reg = LogisticRegression(C = 0.0001)
# Train on the training data
log_reg.fit(train, train_labels)
# Make predictions
# Make sure to select the second column only
log_reg_pred = log_reg.predict_proba(test)[:, 1]
改善模型:随机森林
建立了基础模型后,我们考虑升级算法。让我们在相同的训练集上使用随机森林(Random Forest)算法,看看预测效果。实践证实,当使用几百棵树训练模型时,随机森林是一个更有力的模型。在这里,我们使用100棵树。
from sklearn.ensemble import RandomForestClassifier
# Make the random forest classifier
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
# Train on the training data
random_forest.fit(train, train_labels)
# Extract feature importances
feature_importance_values = random_forest.feature_importances_
feature_importances = pd.DataFrame({'feature': features, 'importance': feature_importance_values})
# Make predictions on the test data
predictions = random_forest.predict_proba(test)[:, 1]
特征工程预测
了解多项式特征和域知识特征是否改善模型的唯一方法,是在这些特征上训练一个检验模型,对比有无这些特征对预测准确率的影响。
poly_features_names = list(app_train_poly.columns)
# Impute the polynomial features
imputer = Imputer(strategy = 'median')
poly_features = imputer.fit_transform(app_train_poly)
poly_features_test = imputer.transform(app_test_poly)
# Scale the polynomial features
scaler = MinMaxScaler(feature_range = (0, 1))
poly_features = scaler.fit_transform(poly_features)
poly_features_test = scaler.transform(poly_features_test)
random_forest_poly = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
# Train on the training data
random_forest_poly.fit(poly_features, train_labels)
# Make predictions on the test data
predictions = random_forest_poly.predict_proba(poly_features_test)[:, 1]
poly_features_names = list(app_train_poly.columns)
# Impute the polynomial features
imputer = Imputer(strategy = 'median')
poly_features = imputer.fit_transform(app_train_poly)
poly_features_test = imputer.transform(app_test_poly)
# Scale the polynomial features
scaler = MinMaxScaler(feature_range = (0, 1))
poly_features = scaler.fit_transform(poly_features)
poly_features_test = scaler.transform(poly_features_test)
random_forest_poly = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
# Train on the training data
random_forest_poly.fit(poly_features, train_labels)
# Make predictions on the test data
predictions = random_forest_poly.predict_proba(poly_features_test)[:, 1]
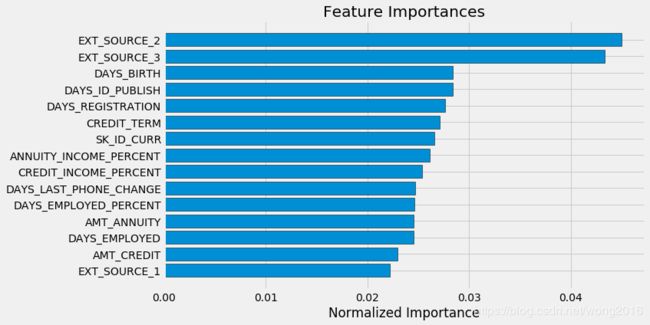
模型解释:特征重要性
我们通过查看随机森林模型的特征重要性,反映哪些变量是最相关的。
def plot_feature_importances(df):
"""
Plot importances returned by a model. This can work with any measure of
feature importance provided that higher importance is better.
Args:
df (dataframe): feature importances. Must have the features in a column
called `features` and the importances in a column called `importance
Returns:
shows a plot of the 15 most importance features
df (dataframe): feature importances sorted by importance (highest to lowest)
with a column for normalized importance
"""
# Sort features according to importance
df = df.sort_values('importance', ascending = False).reset_index()
# Normalize the feature importances to add up to one
df['importance_normalized'] = df['importance'] / df['importance'].sum()
# Make a horizontal bar chart of feature importances
plt.figure(figsize = (10, 6))
ax = plt.subplot()
# Need to reverse the index to plot most important on top
ax.barh(list(reversed(list(df.index[:15]))),
df['importance_normalized'].head(15),
align = 'center', edgecolor = 'k')
# Set the yticks and labels
ax.set_yticks(list(reversed(list(df.index[:15]))))
ax.set_yticklabels(df['feature'].head(15))
# Plot labeling
plt.xlabel('Normalized Importance'); plt.title('Feature Importances')
plt.show()
return df
# Show the feature importances for the default features
feature_importances_sorted = plot_feature_importances(feature_importances)

最重要的特征是我们在EDA阶段分析的EXT_SOURCE and DAYS_BIRTH. 我们还看到,仅仅有少数的特征对模型是重要的,这说明很多不重要的特征可以扔掉。特征重要性对于解释模型或降维来说,并不是一个特别复杂的方法,但是它提示我们在建模时应该考虑哪些因素。
feature_importances_domain_sorted = plot_feature_importances(feature_importances_domain)
结论
在这个案例里,我们首先要理解数据,理解任务,明确测度。然后,我们作探索性数据分析(EDA)尝试识别变量的关系、趋势、异常。在此过程中,我们要做必要的预处理,例如,编码类别变量、填补缺失值、归一化特征。然后,我们使用已有数据加工新特征,并在随后的模型里检验它们的作用。一旦完成了数据探索、数据准备和特征工程,我们先建立一个基准模型,该模型主要用于对比后续的改善模型,比较改善的效果。
我们总结出一个机器学习项目的任务流程:
-
理解问题和数据
-
数据清洗与格式化
-
探索性数据分析
-
基准模型
-
改善模型
-
模型解释