Medicine in Microecology:微生物所王军组发表Nanopore三代测序人类肠道病毒组的方法
文章目录
- 应用Nanopore三代测序技术解析人类肠道病毒组
- 摘要
- 引言
- 结果
- 1. 病毒组分离富集和测序
- 2. ONT测序揭示健康个体的病毒组成
- 3. 使用ONT序列进行病毒基因组组装
- 4. 使用ONT检测病毒表观遗传修饰
- 讨论
- 结论
- 材料与方法
- 1. 病毒样颗粒(VLPs)富集与纯化
- 2. 反转录与随机引物扩增
- 3. PromethION文库制备及测序
- 4. ONT序列组装与分析
- 5. 比对现有数据库
- 6. 噬菌体ORF鉴定及注释
- 7. 甲基化分析
- 8. 数据获取
- 作者简介
- Medicine in Microecology 杂志简介
- 猜你喜欢
- 写在后面

应用Nanopore三代测序技术解析人类肠道病毒组
Profiling of Human Gut Virome with Oxford Nanopore Technology
Medicine in Microecology [IF: 新杂志]
2020-05-08 Articles
https://doi.org/10.1016/j.medmic.2020.100012
全文可开放获取
https://www.sciencedirect.com/science/article/pii/S2590097820300094
第一作者:Jiabao Cao(曹佳宝)1, Yuqing Zhang(张雨青)1
通讯作者:Na Zhao(赵娜,[email protected])1 Jun Wang(王军,[email protected])1*
其它作者:Min Dai(戴敏)3, Jiayue Xu(徐嘉悦)1, Liang Chen(陈亮)1, Faming Zhang(张发明)3,4
作者单位:
1 中国科学院病原微生物与免疫学重点实验室,中国科学院微生物研究所(CAS Key Laboratory of Pathogenic Microbiology and Immunology, Institute of Microbiology, Chinese Academy of Sciences, Beijing, China)
2 中国科学院大学(University of Chinese Academy of Sciences, Beijing 100049, China)
3 南京医科大学附属第二医院消化内科(Medical Center for Digestive Diseases, the Second Affiliated Hospital of Nanjing Medical University, Nanjing 210011, China)
摘要
Abstract
人类病毒组在维持肠道微生物组成和功能以及宿主的生理和免疫中起着重要作用。然而,由于病毒(噬菌体和宿主病毒)富集和短读测序等方法的限制,导致这方面的研究还远远不足。至此,我们开发了一套完整的工作流程,用于病毒颗粒物理富集、逆转录、随机扩增,以及牛津纳米孔技术(ONT)单分子实时测序(SMRT)来分析人类肠道病毒。我们发现分别使用Nanopore测序病毒DNA和扩增后的病毒DNA/cDNA可获得更长读长的序列,提供有关病毒多样性的更多信息,并且许多病毒序列并不在当前数据库中。此外,使用Nanopore测序非扩增的病毒DNA可以对噬菌体的表观遗传修饰(甲基化)信号进行检测。我们的研究表明,测序技术的进步和生物信息学的改进将为病毒的组成、多样性以及潜在的重要功能带来更多的知识。
引言
Introduction
人类的肠道中居住着大量微生物。它们在肠道中栖息于不同的生态位,在它们之间以及与人类细胞之间形成复杂的相互作用网络,肠道微生物组与宿主之间的动态平衡是人类健康所必需的。对人类队列和小鼠模型的研究已经证实,肠道微生物群落与新陈代谢疾病和传染病相关,为今后的监测和治疗提供潜在靶标。
肠道微生物组包含细菌、古细菌、真菌、原生动物和病毒。微生物组中最丰富的成员是细菌和古细菌(占生物量的99%以上),这些年来在人类微生物组研究中受到广泛的关注。然而,二代测序(NGS)技术和生物信息学工具的进步也促进了人类病毒学研究的发展。宏基因组学分析表明,健康人的肠道中存在共生病毒,包括噬菌体,DNA病毒和RNA病毒。病毒(噬菌体和其他宿主病毒)在肠道生理,肠道免疫系统,宿主健康和疾病中起重要作用。病毒和肠道免疫系统之间的动态平衡受免疫细胞分泌的细胞因子精细调节。例如,炎症性肠病(IBD)(克罗恩病和溃疡性结肠炎)的病毒变化是疾病特异的。粘膜表面的噬菌体可通过提供非宿主来源的抗细菌感染的免疫力来影响宿主。通过诱导干扰素(IFN),共生病毒可以在组织损伤期间防止肠道炎症。但是,使用当前的短读测序技术(例如Illumina)只能提供有关肠道病毒有偏和零散的知识。
牛津纳米孔技术(ONT)作为新兴的单分子实时测序技术(SMRT)之一,具有快速制备文库,超长读取和实时数据采集等优势。对于病毒组,ONT测序有潜力通过产生覆盖单个病毒颗粒内所有突变的基因组长度读数来获得病毒基因组。此外,纳米孔测序不仅能够区分基因组,而且还能区分单碱基修饰,例如胞嘧啶的5-甲基化(DNA为5mC,RNA为m5C)和腺嘌呤的6-甲基化(DNA为6mA,RNA为m6A)。近年来,越来越多的证据表明DNA/RNA甲基化可以影响生物学功能,包括调节DNA/RNA复制和修复以及基因表达。最近,Oliveira等报道艰难梭菌中的DNA甲基转移酶能够介导孢子形成,艰难梭菌疾病的传播和致病性。薛等报道了病毒m6A可以上调人类呼吸道合胞病毒的复制和发病机制。这些发现表明表观遗传调控对于重要病原体的发病机制非常重要。
为了解析健康成年人的肠道病毒组,包括物种组成和潜在的表观遗传信息,我们开发了一种工作流程,该流程包括病毒粒子的物理富集,核酸的逆转录和扩增以及生物信息学分析,并首次使用ONT PromethION平台对五个健康的人类个体进行病毒组的表征。我们产生的长读序列可达到数十万个碱基,导致许多现有数据库中不存在的新的重叠群(contigs),并在许多病毒中检测到甲基化信号。这些发现将对人类肠道病毒基因组学、表观基因组学和潜在功能的研究具有重要的指导意义。
结果
result
1. 病毒组分离富集和测序
1. Virome separation, enrichment and sequencing
由于粪便样本的宏基因组测序通常仅包含很小一部分的病毒序列,而且大多数来源于细菌和古菌,病毒富集是非常必要的。因此,我们结合包括过滤、超速离心等一系列富集方法对粪便样本中的病毒样颗粒(VLPs)进行富集(图1)。VLPs分离后加DNase和RNase处理以去除非病毒来源的游离DNA/RNA。对处理后的核酸进行定量,一式两份,一份直接进行Nanopore建库测序以分析病毒丰度和甲基化;另一份经反转和随机扩增后测序。
我们对五名健康志愿者的粪便样本进行了分析,富集得到病毒样颗粒(VLP),并使用ONT PromthION平台对未扩增的原始DNA以及扩增后的cDNA/DNA进行了测序。ONT PromthION测序共计产生8.2 Gb的数据,其中,扩增组产生了中位数为1.7 Gb的数据,而原始DNA组总共产生452 Mb,中位数为67 Mb(补充表1)。
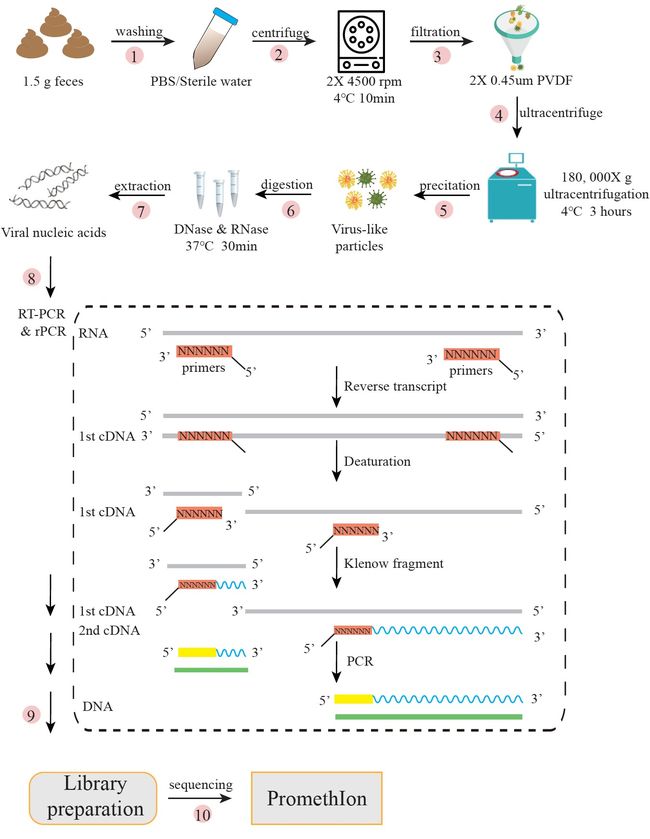
图1 病毒样颗粒富集,核酸提取及ONT测序工作流程
Figure 1. An integrated novel workflow for enrichment of virus-like particles (VLPs), extraction of nucleic acids and ONT sequencing.
2. ONT测序揭示健康个体的病毒组成
2. Virome composition in healthy individuals revealed by ONT sequencing
我们将扩增后的cDNA/DNA测序结果与NCBI中的病毒基因组数据库进行比对,分析五个个体的病毒组成。与前人的研究结果一致,我们发现噬菌体是检测频率最高的病毒,占肠道病毒总数的绝大部分。具体包括了有尾噬菌体目(siphovirdae,podoviridae科),Inoviridae科和Microviridae科等。同时,还检测到了真核CRESS-DNA病毒(genomoviridae科)(图2;表S2)。特别值得注意的是,我们的结果中有RNA植物病毒的存在,包括Virgaviridae科和Alphaflexiviridae科,这与Shkoporov等人的发现相一致性。我们观察到个体特异性可能是粪便病毒群落的特征(图2),先前的一些研究已经证明了这一点。然而,在扩增的cDNA/DNA组五个个体中均发现了属于Inoviridae科的未培养噬菌体WW-nAnB strain 3的存在。
为了表征由扩增引起的关于病毒组成的潜在偏差,我们比较了扩增的cDNA / DNA和原始DNA的测序结果。 由于无法在ONT平台上混样测序(multiplex) RNA样品,我们无法比较原始RNA。 病毒的相对丰度根据每种病毒在其基因组上的覆盖度的相对比例来定义的,类似于宏基因组学研究中细菌丰度的定义。 正如预期的那样,除了个体2和个体5在病毒多样性方面保持相同外,在扩增的cDNA / DNA组中病毒数量更多。此外,原始DNA和扩增的cDNA/DNA之间常见病毒的丰度在五个个体中都发生很大变化,表明逆转录和随机扩增方法对病毒检测有一定偏差。

图2 病毒组成及相对丰度
**Figure 2. Composition and relative abundance of viruses in each individual. **
3. 使用ONT序列进行病毒基因组组装
3. Virome assembly using ONT sequences
使用Canu软件对原始DNA组和扩增的cDNA/DNA组的病毒序列进行组装,共计产生1564个contigs。原始DNA组的重叠群的长度要远大于扩增的cDNA/DNA组(补充图1)。此外,重叠群的长度很长,范围从1 kb到53 kb不等(补充图2)。随后,我们将这些重叠群与NCBI的病毒基因组数据库,人类肠道病毒数据库(GVD)和NCBI核酸数据库进行比对,却得到了非常低的匹配率,表明在我们的结果中存在大量的未知噬菌体基因组。因此,使用Seeker对原始DNA组中的噬菌体进行鉴定。 结果表明,每个样品中超过50%的从重叠群被鉴定为噬菌体。为了表征这些噬菌体,我们进行了ORF预测和功能注释,结果每个重叠群平均产生7个ORF,平均每kb长度产生3个ORF。 此外,通过映射到来自相同样品的宏基因组学Illumina Hiseq测序数据,我们验证了在两个或多个样品中重复出现的ORF。 我们发现一半以上的ORF(59.3%,35/59)可以被匹配,表明这些噬菌体稳定存在于我们的数据中(补充表4)。
为检验由牛津纳米孔测序技术产生的长读序列覆盖完整病毒基因组的潜力,我们将原始reads比对到了扩增的cDNA/DNA和原始DNA组装出来的重叠群上。我们分别统计了原始reads比对到这两个组中最长重叠群的覆盖度,并计算了原始reads占重叠群长度的比例(图3)。在扩增的cDNA/DNA组中,每个样品中reads长度的最大值都超过重叠群长度的15%,在样本4中最高达到了重叠群全长的40%(图S3)。在原始DNA组中比较高,原因可能是随机扩增无法达到基因组全长。另外,少数reads的长度超过了重叠群的全长(图3),这可能是在组装过程中Canu修剪了一些质量值较低的长读片段导致的结果。
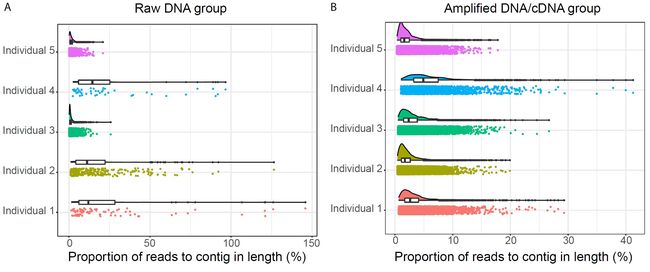
图3 原始数据占重叠群长度的百分比
Figure 3. Proportion of raw reads to contigs in length.
4. 使用ONT检测病毒表观遗传修饰
4. Viral epigenomic detection using ONT
此外,无需额外的实验室操作,就可通过牛津纳米孔测序法直接检测reads的DNA的甲基化。在这项研究中,我们分析了一些在原始DNA组中基因组覆盖度超过10X的重叠群甲基化状态。没有对扩增的cDNA/DNA样品进行甲基化检测,因为它们会丢失甲基化信号。其中,一个已知拼接的重叠群(contig00000015)(Uncultured crAssphage),在8kb基因组中总共检测到17个5mC和120 6mA甲基化位点(图4)。 对于5mC和6mA甲基化,分别鉴定了核苷酸基序YCHYTTACTWMRECT(e值 = 1.2 x 10-2)和基序MADWDTWANADYYWW(e值=2.5 x 10-4),甲基化的核苷酸高亮突出显示。

图4 噬菌体不同甲基化位点鉴定及基序模式识别
Figure 4. Different methylation sites identification and motif recognition of viral contig.
我们还发现了另外4个重叠群,其覆盖度大于10X,但是在已知数据库中没有找到对应物。它们可能是潜在的新型病毒,不太可能是细菌或古菌,因为在我们方法中已删除了大多数非VLP,并且细菌/古菌的contigs很可能会在数据库中找到匹配项。它们具有5mC甲基化位点,范围为0.3至1.8(基因组的百分比)和6mA甲基化位点,范围为0.7至2.5(基因组的百分比)。甲基化的基序也非常多样,包括5mC 的NHHYYKGCDHNNN,WDWADDWCDWYNDDW,MNNNNTRCGBNNNND和HDNBYDVCVVVVNNH,以及6mA的WHWHNYDAHNNYYHTT,VNWWDWHAYBYNNNT,DRNVRKKABBNDNNN和 NRNARNDASYAHHNH(补充图4)。 由于大多数甲基化研究是在真核生物中进行的,并且仅在可获得有限信息的细菌中有研究,因此很难比较甲基化谱图以理解其潜在机制。
讨论
Discussion
我们的研究结合了粪便样品中VLP的物理富集,核苷酸扩增和最新的测序技术,建立了完整的人体肠道病毒谱分析的工作流程。更长的读长和更多的表观遗传修饰信息以及测序技术的发展可能会给基因组和病毒组学研究带来新一轮的革命。更重要的是,尽管测序前的复杂步骤旨在最大程度地富集VLP,并去除非病毒来源的DNA/RNA,因此不可避免地耗费时间,但ONT可以进行测序并几乎同时产生reads,可以用五天的工作时间完成从样品中生成数据,如果PromethION运行时间较短,或者在生成过程中进行实时数据分析,则可能更短。相比之下,基于Illumina的平台通常需要更长的时间才能生成足够的reads用于下游分析。有几项研究已经利用此特性在传染病中快速检测病原体,有些病毒组分析案例也可能需要提高工作效率,我们的方法为病毒组研究提供了可行的方案,仅需较短的运行时间。
我们还比较了反转录和后续扩增对ONT进行病毒分析的影响。使用这些步骤有几个原因。首先,尽管ONT能够直接对DNA或RNA进行测序,但仍然只能对DNA文库进行multiplex,对病毒组分析进行直接RNA测序尚不具有成本效益,而cDNA是更好的选择。同样,要利用ONT测序的能力,需要非常高浓度的DNA或RNA文库来产生足够的reads,但这对于病毒DNA/RNA也非常困难,因为在1.5克粪便样本中病毒DNA/RNA通常只能达到输入量的10%。正如我们的研究所揭示的,扩增确实会导致更高的输出量,并能够检测出低丰度的病毒。但是,由于随机引物的亲和力以及PCR产生的假阳性,导致产生了平均较短的reads并且对病毒丰度估计也存在偏差。最后,扩增的cDNA / DNA丢失了病毒核苷酸上的所有甲基化修饰,阻止了对此潜在重要的表观遗传信息的研究。因此,研究者需要平衡扩增过程的利弊,并且可以利用我们的方法,即同时使用原始DNA(和/或RNA)和扩增的cDNA / DNA进行测序,从而在同一测序过程中获得互补信息。
我们的研究表明病毒的多样性很高,但在这些个体中仅有少量共享的“核心”病毒。随着个体数量及病毒多样性的增加,这个核心病毒可能会进一步缩小,我们计划在将来进行研究。我们发现噬菌体是人类肠道病毒的主要组成部分,还有一些宿主病毒。尽管ONT数据再次显示了植物RNA病毒的存在,但许多reads的长度都超过1kb,无论它们是来自食物中残留的,还是来自植物相关病毒中具有最密切亲缘关系的人类病毒,仍然需要进行更多的研究,尤其是在功能实验中。我们的数据表明,由于我们组装的contigs在当前数据库中的匹配率非常低,因此人类肠道中可能存在大量未知的新型病毒。由于前期我们消耗了大量的时间去除非病毒的核酸,并且它们在NCBI数据库中也没有任何匹配,所以我们认为这些不太可能是污染物。
这也是我们第一次通过直接测序证明噬菌体基因组存在甲基化。已知RSV病毒和流感病毒在其RNA基因组中具有m6A甲基化,可以通过更复杂的方法以低通量检测到,但是DNA噬菌体(或其他DNA病毒)还没有被研究。在大肠杆菌和艰难梭菌中,表明6mA是DNA甲基化的主要形式,而真核生物通常缺乏这种形式,在我们的结果中,噬菌体也以6mA作为DNA甲基化的主要形式。由于DNA甲基化在细菌对噬菌体的防御中起着重要作用,因此,噬菌体基因组如何甲基化,其对噬菌体生命周期的影响以及与细菌宿主的相互作用仍有待于专门研究中进行探讨。此外,噬菌体和细菌之间甲基化的基序仍然可能是内在联系的,并提供了确定噬菌体宿主范围的其他信息。这将要求将来增加对细菌和噬菌体表观遗传学的了解。
结论
Conclusions
总而言之,我们使用ONT测序技术开发并验证了用于人类肠道病毒组分析的完整工作流程,并使用三代测序数据对肠道病毒的个性化和多样化进行了探究。我们的方法同样也可以应用于其他病毒学研究,包括动物肠道,土壤和水环境中的病毒等,并且累积的这些样品序列和表观遗传学信息,很有潜力在宏基因组学,微生物学和微生物学方面开辟新的研究方向。
材料与方法
Material and Methods
1. 病毒样颗粒(VLPs)富集与纯化
1. Enrichment and purification of virus-like particles (VLPs)
来自五个个体的冷冻粪便样品(大约1.5 g)在15 ml 无菌PBS中重悬并充分混匀。上清液于冷冻离心机(Beckman Coulter AllegraTM X-22R)以4℃ 4,500 rpm的参数离心10分钟去除食物残渣。转移上清液于新的离心管中以同样参数再次离心10分钟。用0.45 μm PVDF 滤膜对上清液进行过滤两次以去除真核和细菌颗粒,接下来用超速冷冻离心机(Beckman Coulter XP-100)在4℃以180,000 g 离心3个小时。沉淀用400 ul无菌PBS进行悬浮,然后用8U的TURBO DNase I 和20U 的RNase A在37℃下处理30分钟。病毒核酸(DNA和RNA)用Qiagen的QIAamp MinElute Virus Spin Kit试剂盒进行提取,并用RNase-free的水洗脱。
2. 反转录与随机引物扩增
2. Reverse transcription and random amplification
参考先前的研究,在20 μl反应混合物中合成病毒的第一链cDNA,其中含有来自每个样品的13 μl纯化的病毒核酸和100 pmol引物Rrm(5’-GACCATCTAGCGACCTCCAC-NNNNNN-3’)。 对于双链cDNA合成,添加了100 pmol引物Rrm和Klenow片段(3.5 U /μl; Takara)。 用8μl的双链cDNA模板进行随机扩增,最终反应体积为200μl,其中包含4 μM引物Rm(5’-GCCGGAGCTCTGCAGAATTC-3’),每个90 μM dNTP,80 μM Mg2+,10x缓冲液和1 U KOD-Plus DNA聚合酶(Toyobo)的产品。通过琼脂糖凝胶电泳和QIAquick凝胶提取试剂盒(Qiagen)纯化扩增产物。
3. PromethION文库制备及测序
3. PromethION library preparation and sequencing
PromethION文库的制备是根据制造商提供的说明(SQK-LSK109和EXP-NBD104)对cDNA/DNA和原始DNA加barcode。Multiplexing时,所有样本都汇集在一起。使用ONT MinKNOW软件(v.19.10.1)收集原始测序数据,并使用Guppy(v.3.2.4)在测序运行完成后对原始数据进行base-calling。PromethION运行了96小时。
4. ONT序列组装与分析
4. ONT sequence analysis and assembly
使用Qcat软件对来自FASTQ文件的ONT reads进行demultiplexing,并去除接头及barcode序列。使用Canu v1.9以默认参数对病毒基因组进行从头装配,其中包括reads校正,reads修整和重叠群构建。
5. 比对现有数据库
5. Matching to current database
使用mimimap2将qcat过滤好的原始reads序列与NCBI病毒基因组数据进行比对,以鉴定肠道病毒组成。为了提高病毒鉴定的准确性,采用了以下两个标准:(1)参考病毒基因组的覆盖深度大于等于5X;(2)参考病毒基因组的覆盖度大于等于50%。
为识别Canu组装好的重叠群的类别,应用了两种软件minimap2和blastn对三个数据库包括NCBI病毒基因组数据库、人肠道病毒数据库(GVD)和NCBI核苷酸数据库进行搜索。minimap2对contigs的比对结果的筛选标准同上,而blast的筛选标准为contig匹配长度大于等于1000 bp,核酸相似度大于等于98%,e值小于等于10-5。
6. 噬菌体ORF鉴定及注释
6. Identification and annotation of bacteriophage ORFs
使用Seeker软件(应用深度学习框架提供的一种新的噬菌体预测工具)对原始DNA组的contigs进行噬菌体的鉴定。根据multiPhATE分析流程,使用PHANOTATE (一种注释噬菌体基因组的工具)对噬菌体的ORF进行识别。然后,使用blastp将ORF的氨基酸序列与Phantome(http://www.phantome.org)和pVOGs 数据库进行比对,参数为“相似度大于等 60,e值小于等0.01”,并使用jackhmmer对pVOG数据库使用默认参数进行hmm搜索。使用usearch [49]对两个或两个以上样本中重复出现的ORF(相似度大于等于99)进行聚类。为了验证这些ORF,使用Bowtie2对相同样本的illumina数据进行maping。 ORF的覆盖度使用weeSAM(https://github.com/centre-for-virus-research/weeSAM)进行计算,并且仅对映射的reads数大于等于10的ORF进行计数。
7. 甲基化分析
7. Methylation analysis
使用Tombo v1.5对原始DNA样品中核酸的甲基化状态进行检测。选取对数似然性阈值等于2.5对甲基化进行鉴定,使用estimated fraction of significantly modified reads >= 0.7 and coverage depth >= 10X对甲基化位点进行过滤。使用Integrative Genomics Viewer(IGV版本2.5.3)对5-甲基胞嘧啶(5mC)和N6-甲基腺嘌呤DNA修饰(6mA)的不同甲基化位点进行可视化,并使用MEME(Version)和webLogo(https://weblogo.berkeley.edu/logo.cgi)分别去识别可能的甲基转移酶识别基序及绘制基序的徽标。
8. 数据获取
8. Accession number
测序数据已上传至GSA数据库中的序列号为PRJCA002499的BioProject。工作流程示意图可参考GitHub(https://github.com/caojiabao/VirPipeline)。
作者简介

王军 研究员,博士生导师
主要研究方向: 生物信息学和计算生物学分析;微生物大数据的比较和挖掘;新测序方法和人工智能方法的应用。
2014年获得德国马普进化生物所博士学位,然后在比利时鲁汶大学医学院/弗拉芒生物研究所进行博士后研究工作,2017年回国,同时获得德国马普学会合作伙伴计划支持。长期从事微生物组的技术和方法研究,涉及生物信息学,进化生物学,基因组学和基础医学等方向,成果以第一或共同通讯发表在Science,Nature Genetics,Cell Host Microbe, PNAS, Nature Communications, Microbiome, Protein Cell, GBP等期刊上,与其他合作文章共计40余篇。回国以来开展了多项合作,获得国家自然科学基金面上,重大和新冠病毒应急专项支持,承担科技部重点研发课题,自然资源调查项目子课题,中科院重点部署项目课题以及先导项目子课题等,课题组已经发表/接收文章8篇,申请专利两项。此外,在新冠疫情期间作为病原室代表赴武汉开展了科研攻关项目。
Medicine in Microecology 杂志简介
《Medicine in Microecology》为南方医科大学官方杂志,由著名科学期刊出版商爱思唯尔出版。旨在推动人体微生物组学在医学领域的研究与转化,内容涵盖微生物组人群数据的积累、方法学的优化与创新、宿主与菌群的交互作用机制以及临床转化研究,为临床医生和研究人员发表和追踪医学人体微生物组学研究提供优质平台。
猜你喜欢
- 10000+: 菌群分析
宝宝与猫狗 提DNA发Nature 实验分析谁对结果影响大 Cell微生物专刊 肠道指挥大脑 - 系列教程:微生物组入门 Biostar 微生物组 宏基因组
- 专业技能:生信宝典 学术图表 高分文章 不可或缺的人
- 一文读懂:宏基因组 寄生虫益处 进化树
- 必备技能:提问 搜索 Endnote
- 文献阅读 热心肠 SemanticScholar Geenmedical
- 扩增子分析:图表解读 分析流程 统计绘图
- 16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
- 在线工具:16S预测培养基 生信绘图
- 科研经验:云笔记 云协作 公众号
- 编程模板: Shell R Perl
- 生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外5000+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍末解决群内讨论,问题不私聊,帮助同行。

学习扩增子、宏基因组科研思路和分析实战,关注“宏基因组”


点击阅读原文,跳转最新文章目录阅读
https://mp.weixin.qq.com/s/5jQspEvH5_4Xmart22gjMA