语音数据集整理
语音数据集整理
目录
1.Mozilla Common Voice. 2
2.翻译和口语音频的大型数据库Tatoeba. 2
3.VOiCES Dataset 3
4. LibriSpeech. 4
5.2000 HUB5 English:... 4
6.VoxForge:... 4
7.人类语音的大规模视听数据集 (VoxCeleb)... 5
7.1 VoxCeleb1. 5
7.2 VoxCeleb2. 5
8.TIMIT:英语语音识别数据集... 6
9.CHIME:... 9
10.TED-LIUM:... 10
10.1 TED-LIUM 2. 10
10.2 TED-LIUM 3. 10
11.Google AudioSet 11
12.CCPE数据集... 12
13.Free ST American English Corpus. 13
14.CSTR VCTK. 13
15.LibriTTS corpus. 13
16. The AMI Corpus. 14
17.Free ST Chinese Mandarin Corpus. 14
18.Primewords Chinese Corpus Set 1. 15
19.爱数智慧中文手机录音音频语料库(Mandarin Chinese Read Speech )... 15
20.THCHS30. 16
21.ST-CMDS. 16
22.MAGICDATA Mandarin Chinese Read Speech Corpus. 17
23 AISHELL数据集... 17
23.1AISHELL开源版1. 17
23.2 AISHELL-2 开源中文语音数据库... 18
23.3 AISHELL-翻译机录制语音数据库... 18
23.4 AISHELL-家居环境近远讲同步语音数据库... 18
23.5 AISHELL-语音唤醒词数据库... 19
24.Aidatatang. 19
24.1 aidatatang_1505zh(完整的1505小时中文普通话语音数据集)... 19
24.2 Aidatatang_200zh. 20
25.其他... 21
【多种语言】
1.Mozilla Common Voice
1)基本信息
时长:1965小时(暂时)
最早2017年发布,持续更新,该基金会表示,通过 Common Voice 网站和移动应用,他们正在积极开展 70 种语言的数据收集工作。
Mozilla 宣称其拥有可供使用的最大的人类语音数据集,当前数据集有包括 29 种不同的语言,其中包括汉语,从 4万多名贡献者那里收集了近 2454 小时(其中1965小时已验证)的录音语音数据。并且做出了开放的承诺:向初创公司、研究人员以及对语音技术感兴趣的任何人公开我们收集到的高质量语音数据。
2)数据集特点
Common Voice数据集不仅在其大小和许可模型(https://github.com/JRMeyer/open-speech-corpora)方面是独一无二的,而且在其多样性上也是独一无二的。它代表了一个由语音贡献者组成的全球社区。贡献者可以选择提供诸如他们的年龄、性别和口音等统计元数据,这样他们的语音片段就会被标记上在训练语音引擎中有用的信息。这是一种不同于其他可公开获取的数据集的方法,这些数据集要么是手工制作的多样性数据集(即男性和女性数量相等),要么是语料库与“已发现”的数据集一样的多样性数据集(例如,TED演讲中的TEDLIUM语料库是男性和女性的3倍)。
3)链接
下载地址:https://voice.mozilla.org/data
参考:https://blog.csdn.net/vn9PLgZvnPs1522s82g/article/details/88266146
2.翻译和口语音频的大型数据库Tatoeba
1)基本信息
项目始于2006年
tatoeba是一个用于语言学习的句子、翻译和口语音频的大型数据库。,收集面向外语学习者的例句的网站,用户无须注册便可以搜索任何单词的例句。如果例句含有对应的真人发音,也可以点击收听。注册用户可以添加、翻译、接管、改进、讨论句子。还可以在留言板上和其他注册用户讨论。在留言板上,所有的语言都是平等的,注册用户可以使用自己喜欢的语言与其他用户交流。
3)链接
下载地址:
https://tatoeba.org/eng/downloads
【英语】
3.VOiCES Dataset
1)基本信息
发布时间:2018年
时长:总共15小时(3903个音频文件)
参与人数:300人
这个数据集是在复杂的环境设置(声音)语料库掩盖的声音呈现在声学挑战性条件下的音频记录。录音发生在不同大小的真实房间中,捕捉每个房间的不同背景和混响轮廓。各种类型的干扰器噪声(电视,音乐,或潺潺声)同时播放干净的讲话。在房间内精心布置的12个麦克风在远处录制音频,每个麦克风产生120小时的音频。为了模仿谈话中的人类行为,前景扬声器使用电动平台,在记录期间旋转一系列角度。
三百个不同的扬声器从LibriSpeech的“干净”的数据子集被选择作为源音频,确保50-50女性男性分组。在准备即将到来的数据挑战时,语音语料库的第一次发布将只包括200个发言者。剩下的100个发言者将被保留用于模型验证;一旦数据挑战赛被关闭,完整的语料库(300个发言者)将被释放。除了完整的数据集之外,我们还提供了一个DEV集合和一个迷你DEV集合。两者都保持了语音语料库的数据结构,但都包含了一小部分数据。DEV集包括四个随机选择的扬声器(50-50个女性男性分组)的音频文件,用于ROM-1中记录的数据。这包括所有12个麦克风的数据。迷你开发套件仅包括一个扬声器、一个房间(1号房间)和录音棚话筒。
2)语料库特点
本语料库的目的是促进声学研究,包括但不限于:
- 说话人识别,语音识别,说话人检测。
- 事件和背景分类,语音/非语音。
- 源分离和定位,降噪,一般增强,声学质量度量
其中音频包含:
- 男女声阅读的英语。
- 模拟的头部运动:使用电动旋转平台上的扬声器来模拟前景旋转。
- 杂散噪声包含大量的电视、音乐、噪音。
- 包括大、中、小多个房间的各种混响。
语料库包含源音频、重传音频、正字法转录和说话人标签,有转录和模拟记录的真实世界的噪音。该语料库的最终目标是通过提供对复杂声学数据的访问来推进声学研究。语料库将以开源的形式发布,免费供商业、学术和政府使用。
3)链接
下载地址:
https://voices18.github.io/downloads/
文献:
https://arxiv.org/abs/1804.05053
See more:
https://voices18.github.io/reading/
4. LibriSpeech
1)基本信息
发布时间:2015年
大小:60GB
时长:1000小时
采样:16Hz
LibriSpeech该数据集为包含文本和语音的有声读物数据集,由Vassil Panayotov编写的大约1000小时的16kHz读取英语演讲的语料库。数据来源于LibriVox项目的阅读有声读物,并经过细致的细分和一致。经过切割和整理成每条10秒左右的、经过文本标注的音频文件,非常适合入门使用。
2)数据集特点
推荐应用方向:自然语音理解和分析挖掘
3)链接
(内含镜像)地址:http://www.openslr.org/12/
5.2000 HUB5 English:
1)基本信息
发布时间:2002年
该数据集由NIST(国家标准与技术研究院)2000年发起的HUB5评估中使用的40个英语电话对话的成绩单组成,其仅包含英语的语音数据集。HUB5评估系列集中在电话上的会话语音,将会话语音转录成文本的特定任务。其目标是探索会话语音识别的新领域,开发融合这些思想的先进技术,并测量新技术的性能。
此版本包含评估中用到的40个源语音数据文件的.txt格式的脚本,即20个未发布的电话交谈,是招募的志愿者根据机器人操作员的每日主题进行对话,和20个来自CALLHOME美国英语演讲中的母语交流者之间的对话。
2)数据集特点
推荐应用方向:音乐、人声、车辆、乐器、室内等自然和人物声音识别
3)链接
地址:https://catalog.ldc.upenn.edu/LDC2002T43
6.VoxForge:
1)基本信息
带口音的清晰英语语音数据集。适用于提升不同口音或语调鲁棒性的案例。VoxForge创建的初衷是为免费和开源的语音识别引擎收集标注录音(在Linux/Unix,Windows以及Mac平台上)
2)特点
以GPL协议开放所有提交的录音文件,并且制作声学模型。以供开源语音识别引擎使用,如CMUSphinx,ISIP,Julias(github)和HTK(注意:HTK有分发限制)。
推荐应用方向:语音识别
3)链接
下载地址:
http://www.voxforge.org/home/downloads
7.人类语音的大规模视听数据集 (VoxCeleb)
1)基本信息
VoxCeleb是一个大型人声识别数据集。它包含来自 YouTube 视频的 1251 位名人的约 10 万段语音。数据基本上是性别平衡的(男性占 55%)。这些名人有不同的口音、职业和年龄。开发集和测试集之间没有重叠。
该数据集有2个子集:VoxCeleb1和VoxCeleb2
7.1 VoxCeleb1
VoxCeleb1包含超过10万个针对1,251个名人的话语,这些话语是从上传到YouTube的视频短片中提取的。
发音人数:1251
视频数量:21245
音频数量:145265
下载地址:
http://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html
7.2 VoxCeleb2
说话人深度识别数据集 VoxCeleb2包含超过100万个6,112个名人的话语,从上传到YouTube的视频中提取,VoxCeleb2已经与VoxCeleb1或SITW数据集没有重叠的说话人身份。
发音人数量:训练集:5994,测试集:118
视频数量:训练集:145569,测试集:4911
音频数量:训练集:1092009,测试集:36237
内容时长:2000小时以上
发布时间:2018年
下载地址:
http://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox2.html
2)数据集特点
1、音频全部采自YouTube,是从网上视频切除出对应的音轨,再再根据说话人进行切分;
2、属于完全真实的英文语音;
3、数据集是文本无关的;
4、说话人范围广泛,具有多样的种族,口音,职业和年龄;
5、每句平均时长8.2s,最大时长145s,最短时长4s,短语音较多;
6、每人平均持有句子116句,最大持有250句,最小持有45句;
7、数据集男女性别较均衡,男性有690人(55%),女性有561人;
8、采样率16kHz,16bit,单声道,PCM-WAV音频格式;
9、语音带有一定真实噪声,非人造白噪声,噪声出现时间点无规律,人声有大有小;
10、噪声包括:环境突发噪声、背景人声、笑声、回声、室内噪音、录音设备噪音;
11、视频场景包括:明星红地毯、名人讲台演讲、真人节目访谈、大型体育场解说;
12、音频无静音段,但不是VAD的效果,而是截取了一个人的完整无静音音频片段;
13、数据集自身以划分了开发集Dev和测试集Test,可直接用于Speaker Verification(V)
参考:
https://www.zhihu.com/question/265820133/answer/356203615
8.TIMIT:英语语音识别数据集
1)基本信息
发布时间:1993年
采样:16kHz 16bit
参与人数:630人
TIMIT(英语:The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus),是由德州仪器、麻省理工学院和坦福研究院SRI International合作构建的声学-音素连续语音语料库。TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子,由来自美国八个主要方言地区的630个人每人说出给定的10个句子,所有的句子都在音素级别(phone level)上进行了手动分割,标记。TIMIT语料库包括时间对齐的正字法,语音和单词转录以及每个话语的16位,16kHz语音波形文件。
在给定的10个句子,包括:
- 2个方言句子(SA, dialect sentences),对于每个人这2个方言句子都是相同的;
- 5个音素紧凑句子(SX, phonetically compact sentences),这5个是从MIT所给的450
个因素分布平衡的句子中选出,目的是为了尽可能的包含所有的音素对。
- 3个音素发散句子(SI, phonetically diverse sentences),这3个是由TI从已有的
Brown 语料库(the Brown Coupus)和剧作家对话集(the Playwrights Dialog)中随机选择的,目的是为了增加句子类型和音素文本的多样性,使之尽可能的包括所有的音位变体(allophonic contexts)。
TIMIT官方文档建议按照7:3的比例将数据集划分为训练集(70%)和测试集(30%) ,TIMIT的原始录音是基于61个音素的,如下所示:

由于在实际中61个音素考虑的情况太多,因而在训练时有些研究者整合为48个音素,当评估模型时,李开复在他的成名作(Lee & Hon, 1989)所提出的将61个音素合并为39个音素方法被广为使用。
2)特点
推荐应用方向:语音识别
70%的说话人是男性;大多数说话者是成年白人。
TIMIT语料库多年来已经成为语音识别社区的一个标准数据库,在今天仍被广为使用。其原因主要有两个方面:
1数据集中的每一个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息;
2数据集相对来说比较小,可以在较短的时间内完成整个实验;同时又足以展现系统的性能。
3)细节
1目录组织形式如下:
/<语料库>/<用处>/<方言种类>/<性别><说话者ID>/<句子ID>.<文件类型>
在这里:
语料库:timit
用法:train | test
方言种类:dr1 | dr2 | dr3 | dr4 | dr5 | dr6 | dr7 | dr8
性别:m | f
说话者ID:<说话者缩写><0-9任意数字>
句子ID:<文本类型><句子编号>,其中,文本类型:sa | si | sx
文件类型:wav | txt | wrd | phn
举例:
(1) /timit/train/dr1/fcjf0/sa1.wav
(2) /timit/test/df5/mbpm0/sx407.phn
2文件类型
TIMIT语料库包括一些与话语句子相关的文件,除了语音波形文件(.wav)外,还包括对应的句子内容(.txt),经过时间对齐(time-aligned)的单词内容(.wrd),经过时间对齐(time-aligned)的音素内容(.phn)三种类型的文件。这些文件的格式如下:
<采样起始点> <采样结束点> <文本内容>
… … …
… … …
… … …
<采样起始点> <采样结束点> <文本内容>
在这里:
采样起始点:语音段的开始位置(整数)。对于每一个文件,第一个起始位置总是0。
采样结束点:语音段的结束位置(整数)。由于翻译方法(transcription method)的使用,最后一个采样结束位置的值可能比对应的.wav文件。
文本内容:<完整句子> | <单词标签> | <音素标签>
举例:(/timit/test/dr5/fnlp0/sa1.wav):
.txt:
0 61748 She had your dark suit in greasy wash water all year.
.wrd:
7470 11362 she
11362 16000 had
15420 17503 your
17503 23360 dark
23360 28360 suit
28360 30960 in
30960 36971 greasy
36971 42290 wash
43120 47480 water
49021 52184 all
52184 58840 year
.phn:(开始和结束的静音区以h#标记,展示部分内容)
0 7470 h#
7470 9840 sh
9840 11362 iy
11362 12908 hv
12908 14760 ae
14760 15420 dcl
15420 16000 jh
16000 17503 axr
17503 18540 dcl
18540 18950 d
18950 21053 aa
21053 22200 r
22200 22740 kcl
22740 23360 k
参考:
https://catalog.ldc.upenn.edu/docs/LDC93S1/
https://blog.csdn.net/qfire/article/details/78711673
3)链接
下载地址:
https://catalog.ldc.upenn.edu/LDC93S1
9.CHIME:
1)基本信息

包含环境噪音的用于语音识别挑战赛(CHiME Speech Separation and Recognition Challenge)数据集。数据集包含真实、仿真和干净的录音。真实录音由 4 个speaker在 4 个嘈杂位置的近 9000 个录音构成,仿真录音由多个语音环境和清晰的无噪声录音结合而成。该数据集包含了训练集、验证集、测试集三部分,每份里面包括了多个speaker在不同噪音环境下的数据。
2)特点
推荐应用方向:语音识别
双麦克风录制的立体WAV文件包括左右声道,而阵列麦克风的录音被分解为每个单声通道的WAV文件。
转录以JSON格式提供。
3)链接
地址:
http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME5/
10.TED-LIUM:
1)基本信息
采样:16Hz
时长:118小时
TED-LIUM 语料库由音频讲座及其转录本组成,可在 TED 网站上查阅。
下载地址:
http://www.openslr.org/resources/7/TEDLIUM_release1.tar.gz
国内镜像:
http://cn-mirror.openslr.org/resources/7/TEDLIUM_release1.tar.gz
10.1 TED-LIUM 2
通道:1
采样:16Hz 16bit
比特率:256k
TED Talk 的音频数据集,包含1495个录音和音频会议、159848条发音词典和部分WMT12公开的语料库以及这些录音的文字转录。
下载:
http://www.openslr.org/resources/19/TEDLIUM_release2.tar.gz
国内镜像:
http://cn-mirror.openslr.org/resources/19/TEDLIUM_release2.tar.gz
10.2 TED-LIUM 3
通道:1
采样:16Hz 16bit
比特率:256k
新的TED-LIUM版本是由Ubiqus公司与LIUM(法国勒芒大学)合作制作的。包含2351条录音与对齐脚本,452小时的音频,159848条发音词典,从 WMT12 公开可用的 Corpora 中选择语言建模的单语言数据:这些文件来自 TED-LIUM 2 版本,但已修改以获得与英语更相关的标记化
下载:
http://www.openslr.org/resources/51/TEDLIUM_release-3.tgz
国内镜像:
http://cn-mirror.openslr.org/resources/51/TEDLIUM_release-3.tgz
11.Google AudioSet
1)基本信息
AudioSet是谷歌17年开放的大规模的音频数据集。该数据集包含了 632 类的音频类别以及 2084320 条人工标记的每段 10 秒长度的声音剪辑片段(包括 527 个标签,片段来自YouTube视频)。音频本体 (ontology) 被确定为事件类别的一张层级图,覆盖大范围的人类与动物声音、乐器与音乐流派声音、日常的环境声音。此项研究论文已发表于IEEE ICASSP 2017 大会上。音频本体类别如下图

2)特点
AudioSet提供了两种格式:
1csv文件,包括音频所在的YouTube视频的ID,开始时间,结束时间 以及标签(可能是多标签)
2128维的特征,采样率为1Hz,也就是把音频按秒提取为128维特征。特征是使用VGGish模型来提取的,VGGish下载地址为
https://github.com/tensorflow/models/tree/master/research/audioset 可以使用该模型提取我们自己的数据。VGGish也是用来提取YouTube-8M的。这些数据被存储为.tfrecord格式。
128维特征的下载地址(基于所在地)
storage.googleapis.com/us_audioset/youtube_corpus/v1/features/features.tar.gz
storage.googleapis.com/eu_audioset/youtube_corpus/v1/features/features.tar.gz
storage.googleapis.com/asia_audioset/youtube_corpus/v1/features/features.tar.gz
3)链接
下载地址:
https://github.com/audioset/ontology
参考:
https://baijiahao.baidu.com/s?id=1561283095072201&wfr=spider&for=pc
https://blog.csdn.net/qq_39437746/article/details/80793476(含国内镜像链接)
https://cloud.tencent.com/developer/article/1451556
12.CCPE数据集
1)基本信息
发布时间:2019年
CCPE 全称为 Coached Conversational Preference Elicitation,它是我们提出的一种在对话中获得用户偏好的新方法,即它允许收集自然但结构化的会话偏好。通过研究一个领域的对话,我们对人们如何描述电影偏好进行了简要的定量分析;并且向社区发布了 CCPE-M 数据集,该数据集中有超过 500 个电影偏好对话,表达了 10,000 多个偏好。具体而言,它由 502 个对话框组成的数据集,在用户和助理之间用自然语言讨论电影首选项时有 12,000 个带注释的发音。它通过两个付费人群工作者之间的对话收集,其中一个工作人员扮演「助手」的角色,而另一个工作人员扮演「用户」的角色。「助手」按照 CCPE 方法引出关于电影的「用户」偏好。助理提出的问题旨在尽量减少「用户」用来尽可能多地传达他或她的偏好的术语中的偏见,并以自然语言获得这些偏好。每个对话框都使用实体提及、关于实体表达的首选项、提供的实体描述以及实体的其他语句进行注释。
在面向电影的 CCPE 数据集中,冒充用户的个人对着麦克风讲话,并且音频直接播放给冒充数字助理的人。「助手」则输出他们的响应,然后通过文本到语音向用户播放。这些双人自然对话包括在使用合成对话难以复制的双方之间自发发生的不流畅和错误。这创建了一系列关于人们电影偏好的自然且有条理的对话。在对这个数据集的观察中,我们发现人们描述他们的偏好的方式非常丰富。该数据集是第一个大规模表征该丰富度的数据集。我们还发现,偏好也称为选项的特征,并不总是与智能助理的方式相匹配,或者与推荐网站的方式相匹配。换言之,你最喜爱的电影网站或服务上的过滤器,可能与你在寻求个人推荐时描述各种电影时使用的语言并不匹配。
有关 CCPE 数据集的详细信息,参阅具体研究论文https://ai.google/research/pubs/pub48414,该论文将在 2019 年话语与对话特别兴趣小组(https://www.aclweb.org/portal/content/sigdial-2019-annual-meeting-special-interest-group-discourse-and-dialogue-call-special)年会上发布。
2)链接
下载相关:
https://storage.googleapis.com/dialog-data-corpus/CCPE-M-2019/data.json
13.Free ST American English Corpus
1)基本信息:
参与人数:10人
该数据集源自(www.Surfay.ai)的一个自由的美式英语语料库,包含十个发言者的话语,每个说话者有350个左右的词句。该语料库是在室内环境下用手机录制的,每个词句都由专人仔细抄写与核对,保证转录的准确性。
2)链接
下载地址:
http://www.openslr.org/45/
国内镜像:
http://cn-mirror.openslr.org/resources/45/ST-AEDS-20180100_1-OS.tgz
14.CSTR VCTK
1)基本信息
参与人数:109人
这个数据集包括109个以英语为母语、带有不同口音的英语使用者说出的语音数据。每位发言者宣读约400句词句,其中大部分来自报纸,加上rainbow passage和旨在识别说话者口音的引语段落。报纸文章取自《先驱报》(格拉斯哥),并经《先驱报》和《时代》集团许可。每位演讲者阅读一组不同的报纸句子,其中每组句子都是使用贪婪算法选择的,该算法旨在最大化上下文和语音覆盖。rainbow passage和引语段落对所有发言者都是一样的。
彩虹通道可以在英语档案国际方言中找到:http://web.ku.edu/~idea/readings/rainbow.htm
引出段落与用于语音重音存档 http://accent.gmu.edu的段落相同。语音重音存档的详细信息可查看http://www.ualberta.ca/~aacl2009/PDFs/WeinbergerKunath2009AACL.pdf
2)特点
Google Wavenet用到的数据库。
See more: http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html
下载:
https://datashare.is.ed.ac.uk/handle/10283/2651
15.LibriTTS corpus
1)基本信息
采样:24Hz
时长:585小时
LibriTTS 是一种多语言英语语种,以 24kHz 采样率阅读英语语音约 585 小时,由 Heiga Zen 在 Google 语音和 Google 大脑团队成员的协助下编写。LibriTTS 语料库专为 TTS 研究而设计。它派生自LibriSpeech语料库的原始材料(来自LibriVox的MP3音频文件和古腾堡项目的文本文件)。
2)特点
以下是 LibriSpeech 语料库的主要区别:
1音频文件的采样速率为 24kHz。
2演讲在句子中断时被分割。
3包含原始文本和规范化文本。
4可以提取上下文信息(例如相邻的句子)。
5排除了具有显著背景噪声的透口。
3)链接(镜像)
http://www.openslr.org/60/
16. The AMI Corpus
这是最初托管在http://groups.inf.ed.ac.uk/ami/corpus/上的 AMI Corpus 声学数据的镜像。AMI 会议会议记录包含 100 小时的会议录音。录像使用与公共时间线同步的信号范围。其中包括近距离麦克风和远场麦克风、独立和房间视图摄像机,以及从幻灯机和电子白板输出。在会议期间,与会者还可以使用不同步的笔来记录所写内容。会议以英语录制,使用三个不同的房间,具有不同的声学属性,并且包括大多数非母语人士。
下载:
http://www.openslr.org/16/
【中文】
17.Free ST Chinese Mandarin Corpus
1)基本信息:
参与者:855人
这个语料库是用手机在室内安静的环境中录制的。它有855个speakers。每个演讲者有120个话语。所有的话语都经过人仔细的转录和核对。保证转录精度
语料库包含:
1音频文件;
2转录;
3元数据;
2)链接
下载:(8.2G)
http://www.openslr.org/resources/38/ST-CMDS-20170001_1-OS.tar.gz
国内镜像:
http://cn-mirror.openslr.org/resources/38/ST-CMDS-20170001_1-OS.tar.gz
18.Primewords Chinese Corpus Set 1
1)基本信息
参与人数:296人
时长:178小时
这个免费的中文普通话语料库由上海普力信息技术有限公司发布。(www.primewords.cn)包含178个小时的数据。该语料由296名以中文为母语的人的智能手机录制。转录精度大于 98%,置信度为 95%。免费用于学术用途。转述和词句之间的映射以 JSON 格式提供。
2)链接
下载:(9.0G)
http://www.openslr.org/resources/47/primewords_md_2018_set1.tar.gz
国内镜像:
http://cn-mirror.openslr.org/resources/47/primewords_md_2018_set1.tar.gz
19.爱数智慧中文手机录音音频语料库(Mandarin Chinese Read Speech )
1)基本信息
时长:755小时
参与人数:1000人
音频格式:PCM
MagicData中文手机录音音频语料库包含755小时的中文普通话朗读语音数据,其中分为训练集712.09小时、开发集14.84小时和测试集28.08小时。本语料库的录制文本覆盖多样化的使用场景,包括互动问答、音乐搜索、口语短信信息、家居命令控制等。采集方式为手机录音,涵盖多种类型的安卓手机;录音输出为PCM格式。1000名来自中国不同口音区域的发言人参与采集。MagicData中文手机录音音频语料库由MagicData有限公司开发,免费发布供非商业使用。
2)链接
数据包:
https://freedata.oss-cn-beijing.aliyuncs.com/MAGICDATA_Mandarin_Chinese_Speech.zip
下载地址
http://www.imagicdatatech.com/index.php/home/dataopensource/data_info/id/101
20.THCHS30
1)基本信息
时长:40余小时
THCHS30是一个经典的中文语音数据集,包含了1万余条语音文件,通过单个碳粒麦克风录取,大约40小时的中文语音数据,内容以文章诗句为主,全部为女声。它是由清华大学语音与语言技术中心(CSLT)出版的开放式中文语音数据库。原创录音于2002年由朱晓燕教授在清华大学计算机科学系智能与系统重点实验室监督下进行,原名“TCMSD”,代表“清华连续”普通话语音数据库’。13年后的出版由王东博士发起,并得到了朱晓燕教授的支持。他们希望为语音识别领域的新入门的研究人员提供玩具级别的数据库,因此,数据库对学术用户完全免费。
2)链接
国内镜像:
https://link.ailemon.me/?target=http://cn-mirror.openslr.org/resources/18/data_thchs30.tgz
国外镜像:
https://link.ailemon.me/?target=http://www.openslr.org/resources/18/data_thchs30.tgz
21.ST-CMDS
1)基本信息:
时长:100余小时
参与人数:855人
ST-CMDS是由一个AI数据公司发布的中文语音数据集,包含10万余条语音文件,大约100余小时的语音数据。数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声,适合多种场景下使用。
2)链接
下载地址:
国内镜像:
https://link.ailemon.me/?target=http://cn-mirror.openslr.org/resources/38/ST-CMDS-20170001_1-OS.tar.gz
国外镜像:
https://link.ailemon.me/?target=http://www.openslr.org/resources/38/ST-CMDS-20170001_1-OS.tar.gz
22.MAGICDATA Mandarin Chinese Read Speech Corpus
1)基本信息
时长:755小时
参与人数:1080人
应用:语音识别,机器翻译,说话人识别和其他语音相关领域
Magic Data技术有限公司的语料库,语料库包含755小时的语音数据,其主要是移动终端的录音数据。邀请来自中国不同重点区域的1080名演讲者参与录制。句子转录准确率高于98%。录音在安静的室内环境中进行。数据库分为训练集,验证集和测试集,比例为51:1:2。诸如语音数据编码和说话者信息的细节信息被保存在元数据文件中。录音文本领域多样化,包括互动问答,音乐搜索,SNS信息,家庭指挥和控制等。还提供了分段的成绩单。该语料库旨在支持语音识别,机器翻译,说话人识别和其他语音相关领域的研究人员。因此,语料库完全免费用于学术用途。
2)链接
下载地址见参考:
https://blog.ailemon.me/2018/11/21/free-open-source-chinese-speech-datasets/
镜像:
http://www.openslr.org/68/
23 AISHELL数据集
23.1AISHELL开源版1
1)基本信息
时长:178小时
参与人数:400人
采样:44.1kHz & 16kHz 16bit
AISHELL是由北京希尔公司发布的一个中文语音数据集,其中包含约178小时的开源版数据。该数据集包含400个来自中国不同地区、具有不同的口音的人的声音。录音是在安静的室内环境中同时使用3种不同设备: 高保真麦克风(44.1kHz,16-bit);Android系统手机(16kHz,16-bit);iOS系统手机(16kHz,16-bit)。进行录音,并采样降至16kHz,用于制作AISHELL-ASR0009-OS1。通过专业的语音注释和严格的质量检查,手动转录准确率达到95%以上。该数据免费供学术使用。他们希望为语音识别领域的新研究人员提供适量的数据。
2)链接
下载地址:
http://www.aishelltech.com/kysjcp
23.2 AISHELL-2 开源中文语音数据库
1)基本信息
时长:1000小时
参与人数:1991人
希尔贝壳中文普通话语音数据库AISHELL-2的语音时长为1000小时,其中718小时来自AISHELL-ASR0009-[ZH-CN],282小时来自AISHELL-ASR0010-[ZH-CN]。录音文本涉及唤醒词、语音控制词、智能家居、无人驾驶、工业生产等12个领域。录制过程在安静室内环境中, 同时使用3种不同设备: 高保真麦克风(44.1kHz,16bit);Android系统手机(16kHz,16bit);iOS系统手机(16kHz,16bit)。AISHELL-2采用iOS系统手机录制的语音数据。1991名来自中国不同口音区域的发言人参与录制。经过专业语音校对人员转写标注,并通过严格质量检验,此数据库文本正确率在96%以上。(支持学术研究,未经允许禁止商用。)
2)链接
下载地址:
http://www.aishelltech.com/aishell_2
23.3 AISHELL-翻译机录制语音数据库
1)基本信息
时长:31.2小时
参与人数:12人
采样: 44.1kHz & 16kHz 16bit
文件:wav
来自AISHELL的开源语音数据产品:翻译机录制语音数据库
2)链接
下载地址:
http://www.aishelltech.com/aishell_2019C_eval
23.4 AISHELL-家居环境近远讲同步语音数据库
1)基本信息
时长:24.3小时
参与人数:50人
采样: 44.1kHz & 16kHz 16bit
文件:wav
AISHELL-2019A-EVAL 随机抽取 50 个发音人。每人从位置 A(高保真 44.1kHz,16bit)与位置 F(Android 系统手机 16kHz,16bit)中,各选取 232 句到 237 句。
此数据库经过专业语音校对人员转写标注,并通过严格质量检验,文本正确率 100%。
AISHELL-2019A-EVAL 是 AISHELL-ASR0010 的子库,共 24.3 小时。
2)链接
下载地址:
http://www.aishelltech.com/aishell_2019A_eval
23.5 AISHELL-语音唤醒词数据库
1)基本信息
时长:437.67小时
参与人数:86人
采样: 44.1kHz & 16kHz 16bit
文件:wav
来自希尔贝壳的语音唤醒词数据库
2)链接
下载地址:
http://www.aishelltech.com/aishell_2019B_eval
24.Aidatatang
24.1 aidatatang_1505zh(完整的1505小时中文普通话语音数据集)
1)基本信息
参与人数:6408人
时长:1505小时
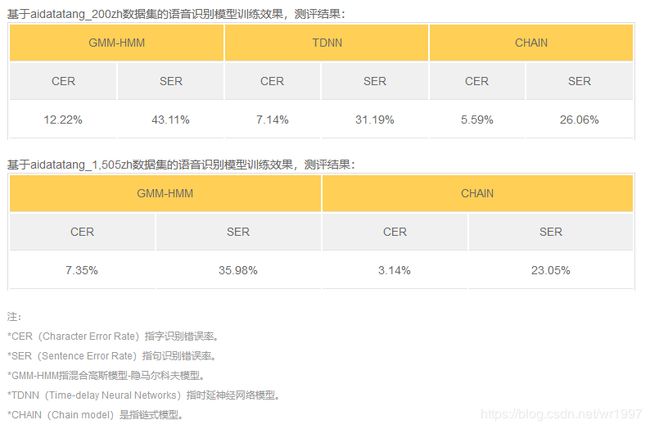
包含6408位来自中国不同地区的说话人、总计1505小时时长共3万条语音、经过人工精心标注的中文普通话语料集可以对中文语音识别研究提供良好的数据支持。采集区域覆盖全国34个省级行政区域。经过专业语音校对人员转写标注,并通过严格质量检验,句标注准确率达98%以上,是行业内句准确率的最高标准。
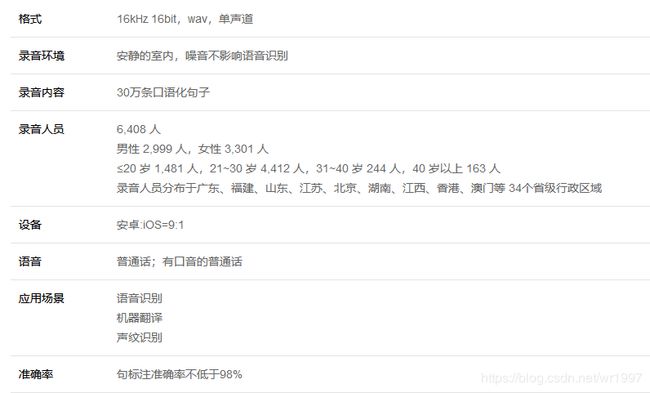
2)使用效果:
3)链接
数据申请:
https://www.datatang.com/webfront/opensource.html
24.2 Aidatatang_200zh(基于完整数据集精选的200小时中文普通话语音数据集)
时长:200小时
参与人数:600人
采样: 16kHz 16bit
Aidatatang_200zh是由北京数据科技有限公司(数据堂)提供的开放式中文普通话电话语音库。语料库长达200小时,由Android系统手机(16kHz,16位)和iOS系统手机(16kHz,16位)记录。邀请来自中国不同重点区域的600名演讲者参加录音,录音是在安静的室内环境或环境中进行,其中包含不影响语音识别的背景噪音。参与者的性别和年龄均匀分布。语料库的语言材料是设计为音素均衡的口语句子。每个句子的手动转录准确率大于98%。数据库按7:1:2的比例分为训练集、验证集和测试集。在元数据文件中保存诸如语音数据编码和扬声器信息等详细信息。还提供分段转录本。
2)特点
该语料库旨在为语音识别、机器翻译、声纹识别等语音相关领域的研究人员提供支持。因此,该语料库完全免费供学术使用。
数据堂精选了200小时中文普通话语音数据在OpenSLR发布,并在Kaldi平台提供了训练代码,对应的训练方法也在github平台发布。
3)链接
训练:
https://github.com/datatang-ailab/aidatatang_200zh/blob/master/README.md
国内镜像:
https://link.ailemon.me/?target=http://cn-mirror.openslr.org/resources/62/aidatatang_200zh.tgz
国外镜像:https://link.ailemon.me/?target=http://www.openslr.org/resources/62/aidatatang_200zh.tgz
【其他语言】
25.其他
Vystadial
这些数据是转录的以英语和捷克语交流的电话数据。
地址:
http://www.openslr.org/resources/6/data_voip_cs.tgz( Czech speech and transcripts )
http://www.openslr.org/resources/6/data_voip_en.tgz( English speech and transcripts )
ALFFA (African Languages in the Field: speech Fundamentals and Automation)
这些数据是转录的以阿姆哈拉语和斯瓦希里语和沃洛夫语交流的语音数据。
地址:
http://www.openslr.org/resources/25/data_readspeech_am.tar.bz2( Amharic speech and transcripts )
http://www.openslr.org/resources/25/data_broadcastnews_sw.tar.bz2( Swahili speech and transcripts )
http://www.openslr.org/resources/25/data_readspeech_wo.tar.bz2 ( Wolof speech and transcripts )
Heroico
Heroico 语料库 (LDC2006S37) 最初是为了训练西班牙语学习应用中的发音建模声学模型而收集的。
链接
http://www.openslr.org/39/
Tunisian_MSA
突尼斯语-MSA 语料库最初是为训练阿拉伯语学习应用中的发音建模声学模型而收集的。数据收集工作于2003年在突尼斯共和国首都突尼斯附近进行。突尼斯语-MSA语料库分为背诵和提示语音子库。背诵的语音存储在录音目录下。提示语音存储在答案目录下。118名线人中的每一个都通过背诵句子和回答提示的问题,为两个子公司做出了贡献。突尼斯语-MSA语种有11.2小时的演讲时间。2017 年收集了一个小语料库进行测试。演讲由4名speaker:3名利比亚男性和1名来自突尼斯的女性组成。
链接:
http://www.openslr.org/46/
African Accented French
此语料库包含大约 22 小时的非洲口音法语的语音录音。为所有录音提供成绩单。
链接:
http://www.openslr.org/57/
Pansori-TEDxKR
- 基本信息
是一种韩语语音识别 (ASR) 语种,由 2010 年至 2014 年在韩国举行的韩语 TEDx 会谈产生。它包含来自 41 个扬声器的大约 3 小时的语音音频脚本对。此语料库是使用称为 Pansori 的新语料库数据引入和处理系统生成的。语料库中包括的语音音频是 16 位 FLAC 文件,采样率为 16 KHz。
- 特点
只包括由社区翻译人员转录的TEDx讲座。
语种片段在字幕边界处被分割。
通过手动(工具辅助)语音文本对齐微调分段。
由最先进的语音识别器(Google 云语音到文本)进行最终验证。
- 链接
https://github.com/yc9701/pansori-tedxkr-corpus
下载:
http://www.openslr.org/58/
ParlamentParla
这是加泰罗尼亚语的演讲文,由工人合作社Col_lectivaT出版。音频片段摘自加泰罗尼亚议会加泰罗尼亚议会全体会议的录音。录音与他们的记录一致,并提取了320小时最干净的片段。内容属于加泰罗尼亚议会,发布的数据符合其使用条款。音频文件是PCM 16位单声道,小尾音与采样率16 kHz。自版本 1.0 起,语料库分为 90 小时清洁和 230 小时的其他质量段加泰罗尼亚自治政府文化部支持编写这一语料库。
下载:
http://www.openslr.org/59/
TEDx Spanish Corpus
这是一个性别不平衡的西班牙语语料库,期限为 24 小时。它包含 TEDx 事件中多个讲解者的自发语音;他们大多数是男性。转录以小写字母显示,没有标点符号.
地址:
http://www.openslr.org/resources/67/tedx_spanish_corpus.tgz
以下数据集包含相关语言的转录音频数据,由波形文件和 TSV 文件(line_index.tsv)组成。文件行_index.tsv 包含匿名的 FileID 和文件中的音频转录。数据集已手动检查质量,但可能仍有错误。
High quality TTS data for Bengali languages
http://www.openslr.org/37/孟加拉国孟加拉语和印度孟加拉语
High quality TTS data for Javanese
http://www.openslr.org/41/爪 哇
High quality TTS data for Khmer.
http://www.openslr.org/42/高棉
High quality TTS data for Nepali.
http://www.openslr.org/43/尼泊尔
High quality TTS data for Sundanese.
http://www.openslr.org/44/桑达尼斯
Large Sinhala ASR training data set
http://www.openslr.org/52/僧伽罗
Large Bengali ASR training data set
http://www.openslr.org/53/孟加拉语
Large Nepali ASR training data set
http://www.openslr.org/54/尼泊尔文
Crowdsourced high-quality Argentinian Spanish speech data set.
http://www.openslr.org/61/西班牙语(阿根廷布宜诺斯艾利斯)
Crowdsourced high-quality Malayalam multi-speaker speech data set.
http://www.openslr.org/63/马拉雅拉姆语(母语)
Crowdsourced high-quality Marathi multi-speaker speech data set.
http://www.openslr.org/64/马拉地语(母语)
Crowdsourced high-quality Tamil multi-speaker speech data set.
http://www.openslr.org/65/泰米尔语(母语)
Crowdsourced high-quality Telugu multi-speaker speech data set.
http://www.openslr.org/66/泰卢固语(母语)
Crowdsourced high-quality Catalan speech data set.
http://www.openslr.org/69/ 加泰隆语。
Crowdsourced high-quality Nigerian English speech data set.
http://www.openslr.org/70/尼日利亚英语
Crowdsourced high-quality Chilean Spanish speech data set.
http://www.openslr.org/71/智利西班牙语
Crowdsourced high-quality Columbian Spanish speech data set.
http://www.openslr.org/72/哥伦比亚西班牙语
Crowdsourced high-quality Peruvian Spanish speech data set.
http://www.openslr.org/73/秘鲁西班牙语
Crowdsourced high-quality Puerto Rico Spanish speech data set.
http://www.openslr.org/74/波多黎各西班牙语
Crowdsourced high-quality Venezuelan Spanish speech data set.
http://www.openslr.org/75/委内瑞拉西班牙语
Crowdsourced high-quality Basque speech data set.
http://www.openslr.org/76/巴士克语
Crowdsourced high-quality Galician speech data set.
http://www.openslr.org/77/加利西亚语
Crowdsourced high-quality Gujarati multi-speaker speech data set.
http://www.openslr.org/78/古吉拉特语(母语)
Crowdsourced high-quality Kannada multi-speaker speech data set.
http://www.openslr.org/79/缅甸
Crowdsourced high-quality Burmese speech data set.
http://www.openslr.org/80/卡纳达